Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: SDK de Azure Machine Learning v1 para Python
SDK de Azure Machine Learning v1 para Python
Importante
En este artículo se proporciona información sobre el uso del SDK de Azure Machine Learning v1. El SDK v1 está en desuso a partir del 31 de marzo de 2025 y la compatibilidad con él finalizará el 30 de junio de 2026. Puede instalar y usar el SDK v1 hasta esa fecha.
Se recomienda realizar la transición al SDK v2 antes del 30 de junio de 2026. Para más información sobre el SDK v2, consulte ¿Qué es el SDK de Python de Azure Machine Learning v2 y la referencia del SDK v2?
El desfase de datos (versión preliminar) se retirará al 09/01/2025 y puede empezar a usar Monitor de modelos para las tareas de desfase de datos. Consulte el contenido siguiente para comprender los pasos de reemplazo, brechas de características y cambios manuales.
Obtenga información sobre cómo supervisar el desfase de datos y establecer alertas cuando el desfase es alto.
Nota:
La supervisión de modelos de Azure Machine Learning (v2) proporciona funcionalidades mejoradas para el desfase de datos junto con funcionalidades adicionales para supervisar señales y métricas. Para más información sobre las funcionalidades de supervisión de modelos en Azure Machine Learning (v2), consulte Supervisión de modelos con Azure Machine Learning.
Con los monitores del conjunto de datos de Azure Machine Learning (versión preliminar), puede:
- Analizar el desfase de los datos para comprender cómo cambian con el tiempo.
- Supervisar los datos del modelo para conocer las diferencias entre los conjuntos de datos de entrenamiento y de servicio. Comience por recopilar datos de modelo de los modelos implementados.
- Supervisar los datos nuevos para conocer las diferencias entre los conjuntos de datos de destino y los de referencia.
- Perfilar características en los datos para realizar un seguimiento de cómo cambian las propiedades estadísticas con el tiempo.
- Configurar alertas sobre el desfase de datos para tener advertencias tempranas de posibles problemas.
- Crear una nueva versión del conjunto de datos al determinar que los datos se han desfasado demasiado.
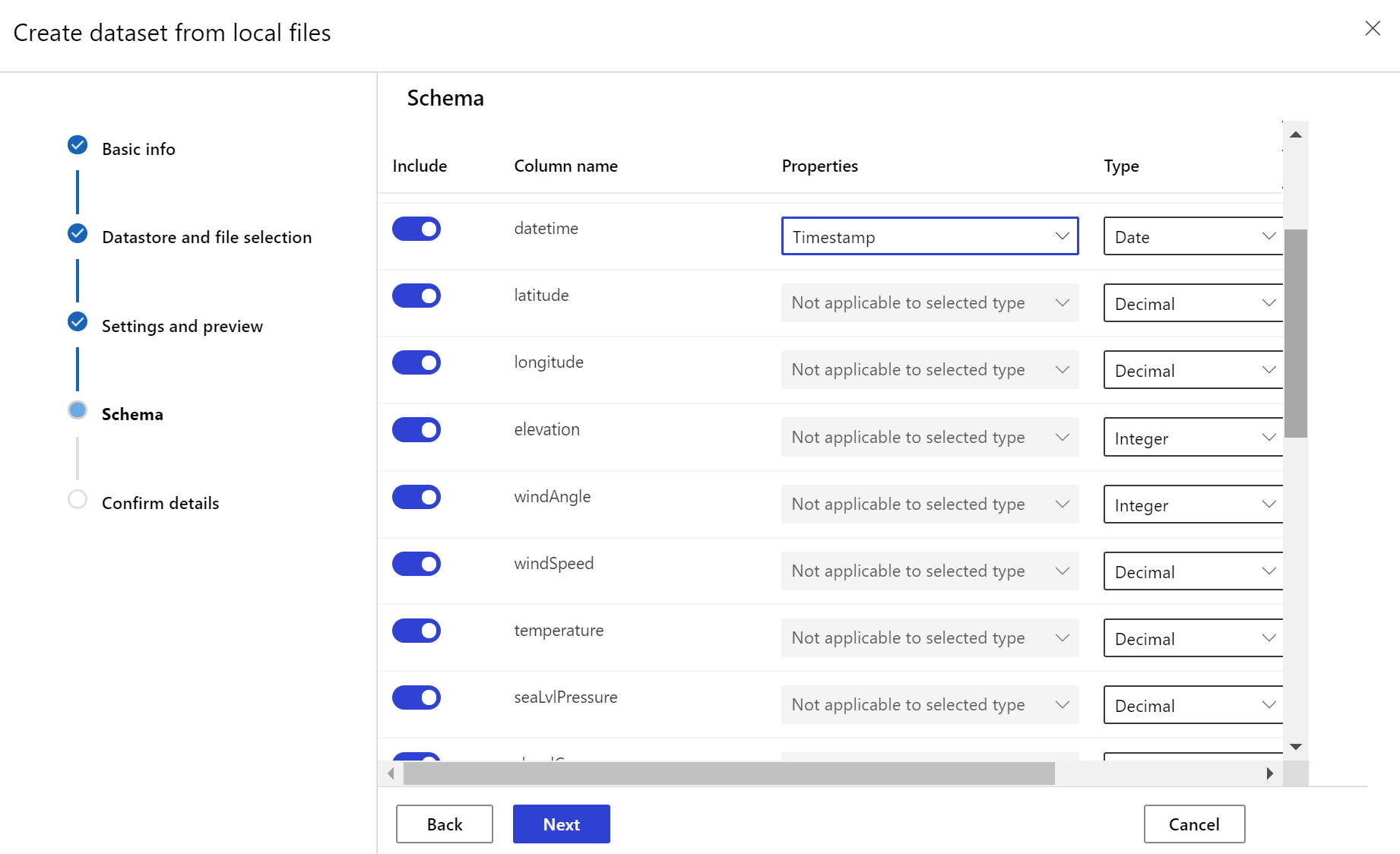
Para crear el monitor, se usa un conjunto de datos de Azure Machine Learning. El conjunto de datos debe incluir una columna de marca de tiempo.
Puede ver las métricas de desfase de datos con el SDK de Python o en Azure Machine Learning Studio. Se pueden encontrar otras métricas e información detallada a través del recurso de Azure Aplicación Insights asociado al área de trabajo de Azure Machine Learning.
Importante
La detección de un desfase de datos en conjuntos de datos se encuentra actualmente en versión preliminar pública. Se ofrece la versión preliminar sin Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no se admitan o que tengan funcionalidades restringidas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Requisitos previos
Para crear y trabajar con conjuntos de datos, necesita:
- Una suscripción de Azure. Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe hoy mismo la versión gratuita o de pago de Azure Machine Learning.
- Un área de trabajo de Azure Machine Learning.
- El SDK de Azure Machine Learning para Python instalado, que incluye el paquete azureml-datasets.
- Datos estructurados (tabulares) con una marca de tiempo especificada en la ruta de acceso del archivo, el nombre de archivo o la columna de los datos.
Requisitos previos (Migración al Monitor de modelos)
Al migrar a Model Monitor, compruebe los requisitos previos como se mencionó en este artículo Requisitos previos de la supervisión de modelos de Azure Machine Learning.
¿Qué es el desfase de datos?
La precisión del modelo se degrada con el tiempo, en gran medida debido al desfase de datos. Para los modelos de Machine Learning, el desfase de datos es el cambio en los datos de entrada del modelo que conduce a la degradación del rendimiento del modelo. La supervisión del desfase de datos ayuda a detectar estos problemas de rendimiento del modelo.
Entre las causas del desfase de datos se incluyen:
- Cambios del proceso ascendente, como un sensor que se reemplaza que cambia las unidades de medida de pulgadas a centímetros.
- Los problemas de calidad de los datos, como un sensor roto que siempre lee 0.
- Desfase natural en los datos, como el cambio medio de temperatura con las estaciones.
- Cambio en relación entre las características o el turno covariable.
Azure Machine Learning simplifica la detección de desfases al calcular una sola métrica que abstrae la complejidad de los conjuntos de datos que se comparan. Estos conjuntos de datos pueden tener cientos de características y decenas de miles de filas. Una vez que se detecta el desfase, se exploran las características que lo causan. A continuación, inspeccione las métricas a nivel de característica para depurar y aislar la causa principal del desfase.
Este enfoque de arriba abajo facilita el seguimiento de los datos en mayor medida que las técnicas tradicionales basadas en reglas. Las técnicas basadas en reglas, como el intervalo de datos permitidos o los valores únicos permitidos, pueden consumir mucho tiempo y ser propensos a errores.
En Azure Machine Learning, se usan monitores de conjunto de datos para detectar y alertar sobre el desfase de datos.
Monitores de conjuntos de datos
Con un monitor de conjunto de datos puede:
- Detectar y avisar sobre el desfase de datos en los nuevos datos de un conjunto de datos.
- Analizar el desfase en datos históricos.
- Generar perfiles de datos nuevos a lo largo del tiempo.
El algoritmo de desfase de datos proporciona una medida global del cambio en los datos y la indicación de qué características son responsables de una investigación más detallada. Los monitores de conjunto de datos generan muchas otras métricas mediante la generación de perfiles de nuevos datos en el conjunto de datos de timeseries.
Las alertas personalizadas se pueden configurar en todas las métricas generadas por el monitor a través de Azure Application Insights. Los monitores de conjuntos de datos se pueden usar para detectar rápidamente problemas de datos y reducir el tiempo necesario para depurar el problema mediante la identificación de las causas probables.
Conceptualmente, hay tres escenarios principales para configurar los monitores de conjunto de datos en Azure Machine Learning.
| Escenario | Descripción |
|---|---|
| Supervisión de los datos de servicio de un modelo para el desfase de los datos de entrenamiento | Los resultados de este escenario se pueden interpretar como la supervisión de un proxy para la precisión del modelo, dado que la precisión del modelo se degrada si los datos de servicio se desfasan de los datos de entrenamiento. |
| Supervisión de un conjunto de datos de una serie temporal para el desfase desde un período de tiempo anterior | Este escenario es más general y se puede usar para supervisar los conjuntos de datos implicados en el flujo ascendente o descendente de la creación del modelo. El conjunto de datos de destino debe tener una columna de marca de tiempo. El conjunto de datos de referencia puede ser cualquier conjunto de datos tabular que tenga características en común con el conjunto de datos de destino. |
| Análisis sobre datos pasados | Este escenario se puede usar para comprender los datos históricos e informar de las decisiones en la configuración de los monitores de conjuntos de datos. |
Los monitores del conjunto de datos dependen de los siguientes servicios de Azure.
| Servicio de Azure | Descripción |
|---|---|
| Dataset | El desfase usa conjuntos de datos de Machine Learning para recuperar datos de entrenamiento y comparar datos para el entrenamiento del modelo. La generación de un perfil de datos se usa para generar algunas de las métricas que se han comunicado, como min, max, distinct values, distinct values count. |
| Canalización y proceso de Azure Machine Learning | El trabajo de cálculo de desfase se hospeda en una canalización de Azure Machine Learning. El trabajo se desencadena a petición o programa para ejecutarse en un proceso configurado en el tiempo de creación del monitor de desfase. |
| Application Insights | El desfase emite métricas a Application Insights que pertenecen al área de trabajo de Machine Learning. |
| Azure Blob Storage | El desfase emite métricas en formato json a Azure Blob Storage. |
Conjunto de datos de destino y de referencia
Puede supervisar conjuntos de datos de Azure Machine Learning para el desfase de datos. Al crear un monitor de conjunto de datos, haga referencia a lo siguiente:
- Conjunto de datos de referencia: normalmente, el conjunto de datos de entrenamiento para un modelo.
- Conjunto de datos de destino: normalmente, datos de entrada del modelo. Con el tiempo se compara con el conjunto de datos de referencia. Esta comparación significa que el conjunto de datos de destino debe tener especificada una columna de marca de tiempo.
El monitor compara los conjuntos de datos de línea base y de destino.
Migración al Monitor de modelos
En El Monitor de modelos, puede encontrar los conceptos correspondientes como se indica a continuación y puede encontrar más detalles en este artículo Configuración de la supervisión de modelos mediante la incorporación de los datos de producción a Azure Machine Learning:
- Conjunto de datos de referencia: similar al conjunto de datos de línea base para la detección de desfase de datos, se establece como el conjunto de datos de inferencia de producción anterior reciente.
- Datos de inferencia de producción: similares al conjunto de datos de destino en la detección de desfase de datos, los datos de inferencia de producción se pueden recopilar automáticamente de los modelos implementados en producción. También puede ser datos de inferencia que almacene.
Creación de un conjunto de datos de destino
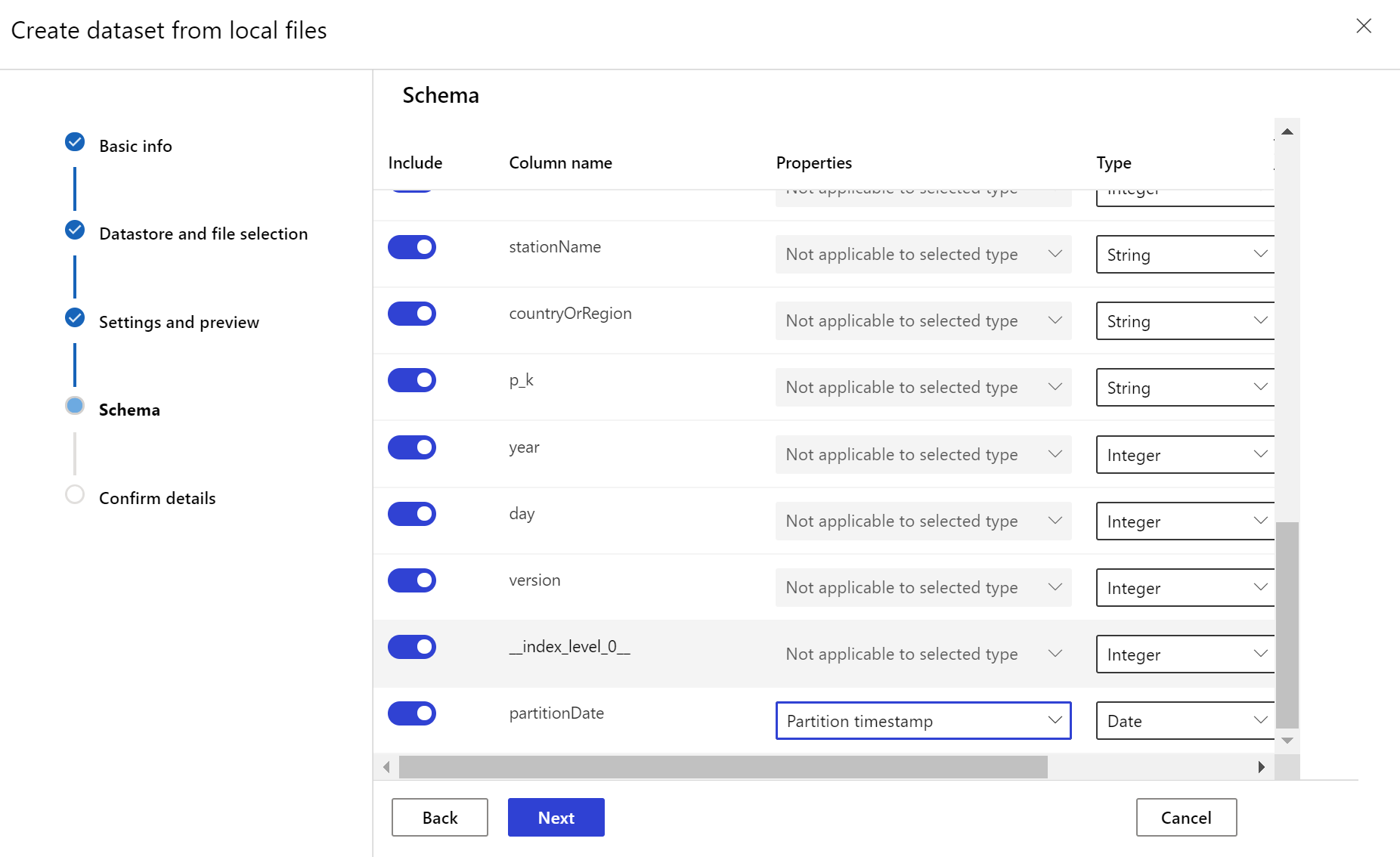
El conjunto de datos de destino debe tener configurado el rasgo timeseries especificando la columna de marca de tiempo de una columna de los datos o en una columna virtual derivada del patrón de ruta de los archivos. Cree el conjunto de datos con una marca de tiempo a través del SDK de Python o Azure Machine Learning Studio. Tiene que especificarse una columna que represente una "marca de tiempo" para poder agregar el rasgo timeseries al conjunto de datos. Si los datos se dividen en una estructura de carpetas con información de hora, como '{aaaa/MM/dd}', cree una columna virtual a través de la configuración del patrón de ruta de acceso y establézcalos como la "marca de tiempo de partición" para habilitar la funcionalidad de api de serie temporal.
SE APLICA A:SDK de Azure Machine Learning v1 para Python
El método Dataset clase with_timestamp_columns() define la columna de marca de tiempo del conjunto de datos.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Sugerencia
Para obtener un ejemplo completo de cómo usar el rasgo de timeseries de conjuntos de datos, vea el cuaderno de ejemplo o la documentación del SDK de conjuntos de datos.

Creación de un monitor de conjunto de datos
Cree un monitor de conjunto de datos para detectar y alertar sobre el desfase de datos en un nuevo conjunto de datos. Use el SDK de Python o Estudio de Azure Machine Learning.
Como se describe más adelante, un monitor de conjunto de datos se ejecuta con una frecuencia establecida (diaria, semanal, mensual). Analiza los nuevos datos disponibles en el conjunto de datos de destino desde su última ejecución. En algunos casos, este análisis de los datos más recientes puede no ser suficiente:
- Los nuevos datos del origen ascendente se retrasaron debido a una canalización de datos rota y estos nuevos datos no están disponibles cuando se ejecutó el monitor del conjunto de datos.
- Un conjunto de datos de serie temporal solo tenía datos históricos y quiere analizar patrones de desfase en el conjunto de datos a lo largo del tiempo. Por ejemplo: compare el tráfico que fluye a un sitio web, tanto en invierno como en temporadas de verano, para identificar patrones estacionales.
- No está familiarizado con los monitores de conjunto de datos. Quiere evaluar cómo funciona la característica con los datos existentes antes de configurarla para supervisar los días futuros. En estos escenarios, puede enviar una ejecución a petición, con un intervalo de fechas específico del conjunto de datos de destino, para compararlo con el conjunto de datos de línea base.
La función de reposición ejecuta un trabajo de reposición para un intervalo de fechas de inicio y finalización especificados. Un trabajo de reposición rellena los puntos de datos que faltan esperados en un conjunto de datos, como una manera de garantizar la precisión e integridad de los datos.
Nota:
La supervisión del modelo de Azure Machine Learning no admite la función manual de backfill. Si desea volver a realizar la monitorización del modelo para un intervalo de tiempo específico, puede crear otro monitor de modelo para ese intervalo de tiempo específico.
SE APLICA A:SDK de Azure Machine Learning v1 para Python
Consulte la Documentación de referencia de Python SDK sobre el desfase de datos para obtener información completa.
En el ejemplo siguiente se muestra cómo crear un monitor de conjunto de datos mediante el SDK de Python:
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Sugerencia
Para ver un ejemplo completo de cómo configurar un conjunto de datos de timeseries y el detector de desfase de datos, consulte nuestro cuaderno de ejemplos.
Crear monitor de modelos (migrar al Monitor de modelos)
Al migrar a Model Monitor, si ha implementado el modelo en producción en un punto de conexión en línea de Azure Machine Learning y habilitado recopilación de datos en tiempo de implementación, Azure Machine Learning recopila datos de inferencia de producción y los almacena automáticamente en Microsoft Azure Blob Storage. Después, puede usar la supervisión de modelos de Azure Machine Learning para supervisar continuamente estos datos de inferencia de producción y puede elegir directamente el modelo para crear el conjunto de datos de destino (datos de inferencia de producción en el Monitor de modelos).
Al migrar a Model Monitor, si no implementó el modelo en producción en un punto de conexión en línea de Azure Machine Learning o no quiere usar recopilación de datos, también puede configurar la supervisión de modelos con señales y métricas personalizadas.
Las secciones siguientes contienen más detalles sobre cómo migrar al Monitor de modelos.
Crear monitor de modelos a través de datos de producción recopilados automáticamente (Migrar al Monitor de modelos)
Si ha implementado el modelo en producción en un punto de conexión en línea de Azure Machine Learning y habilitado recopilación de datos en tiempo de implementación.
Puede usar el código siguiente para configurar la supervisión de modelos integrada:
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
AlertNotification,
MonitoringTarget,
MonitorDefinition,
MonitorSchedule,
RecurrencePattern,
RecurrenceTrigger,
ServerlessSparkCompute
)
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="subscription_id",
resource_group_name="resource_group_name",
workspace_name="workspace_name",
)
# create the compute
spark_compute = ServerlessSparkCompute(
instance_type="standard_e4s_v3",
runtime_version="3.3"
)
# specify your online endpoint deployment
monitoring_target = MonitoringTarget(
ml_task="classification",
endpoint_deployment_id="azureml:credit-default:main"
)
# create alert notification object
alert_notification = AlertNotification(
emails=['abc@example.com', 'def@example.com']
)
# create the monitor definition
monitor_definition = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
alert_notification=alert_notification
)
# specify the schedule frequency
recurrence_trigger = RecurrenceTrigger(
frequency="day",
interval=1,
schedule=RecurrencePattern(hours=3, minutes=15)
)
# create the monitor
model_monitor = MonitorSchedule(
name="credit_default_monitor_basic",
trigger=recurrence_trigger,
create_monitor=monitor_definition
)
poller = ml_client.schedules.begin_create_or_update(model_monitor)
created_monitor = poller.result()


Crear monitor de modelos mediante el componente de preprocesamiento de datos personalizado (Migrar al Monitor de modelos)
Al migrar a Model Monitor, si no implementó el modelo en producción en un punto de conexión en línea de Azure Machine Learning o no quiere usar recopilación de datos, también puede configurar la supervisión de modelos con señales y métricas personalizadas.
Si no tiene una implementación, pero tiene datos de producción, puede usar los datos para realizar la supervisión continua del modelo. Para supervisar estos modelos, debe poder:
- Recopilar datos de inferencia de producción de modelos implementados en producción.
- Registrar los datos de inferencia de producción como un recurso de datos de Azure Machine Learning y asegurarse de las actualizaciones continuas de los datos.
- Proporcionar un componente de preprocesamiento de datos personalizado y registrarlo como un componente de Azure Machine Learning.
Debe proporcionar un componente de preprocesamiento de datos personalizado si los datos no se recopilan con el recopilador de datos. Sin este componente de preprocesamiento de datos personalizado, el sistema de supervisión de modelos de Azure Machine Learning no sabrá cómo procesar los datos en formato tabular con compatibilidad con la ventana de tiempo.
El componente de preprocesamiento personalizado debe tener estas firmas de entrada y salida:
| Entrada/salida | Nombre de firma | Tipo | Descripción | Valor de ejemplo |
|---|---|---|---|---|
| entrada | data_window_start |
literal, cadena | hora de inicio del periodo de datos en formato ISO8601. | 2023-05-01T04:31:57.012Z |
| entrada | data_window_end |
literal, cadena | hora de finalización del periodo de datos en formato ISO8601. | 2023-05-01T04:31:57.012Z |
| entrada | input_data |
uri_folder | Los datos de inferencia de producción recopilados, que se registran como recurso de datos de Azure Machine Learning. | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | Un conjunto de datos tabular, que coincide con un subconjunto del esquema de datos de referencia. |
Para obtener un ejemplo de un componente de preprocesamiento de datos personalizado, consulte custom_preprocessing en el repositorio de GitHub azuremml-examples.
Descripción de los resultados del desfase de datos
En esta sección se muestran los resultados de la supervisión de un conjunto de datos, que se encuentra en la página Conjuntos de datos / Monitores de conjuntos de datos en Azure Studio. Puede actualizar la configuración y analizar los datos existentes durante un período de tiempo específico en esta página.
Comience con la información de nivel superior sobre la magnitud del desfase de datos y un resaltado de las características que se van a investigar aún más.
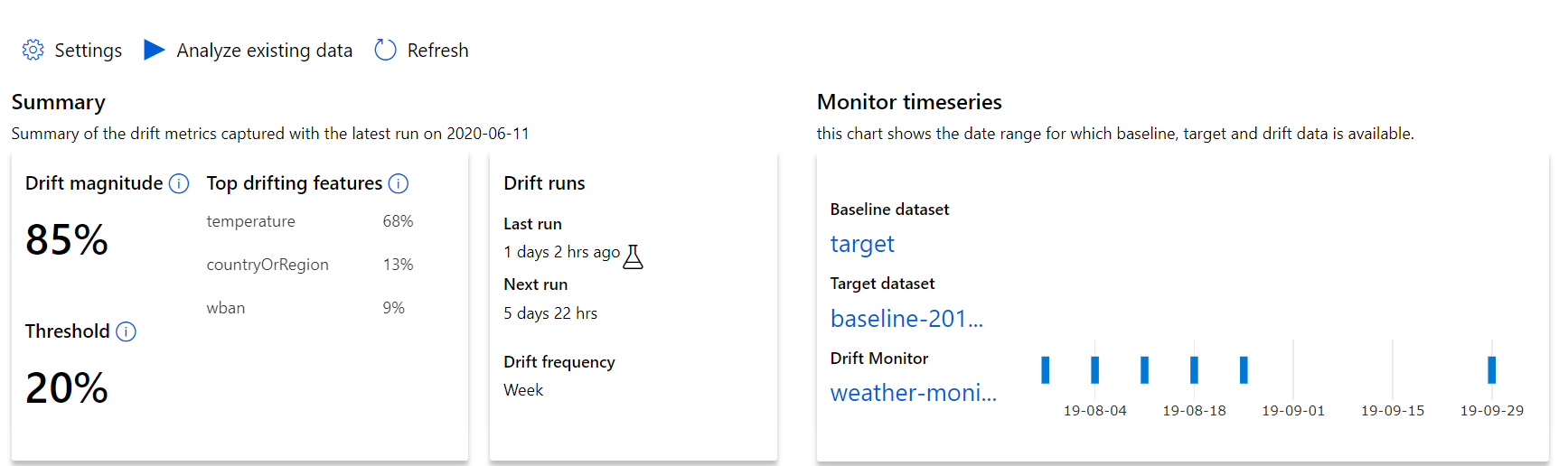
| Métrica | Descripción |
|---|---|
| Magnitud del desfase de datos | Porcentaje de desfase entre la línea base y el conjunto de datos de destino a lo largo del tiempo. Este porcentaje oscila entre 0 y 100, 0 indica conjuntos de datos idénticos y 100 indica que el modelo de desfase de datos de Azure Machine Learning puede indicar completamente los dos conjuntos de datos. Se espera un ruido en el porcentaje exacto medido debido a las técnicas de aprendizaje automático que se usan para generar esta magnitud. |
| Principales características de desfase | Muestra las características del conjunto de datos que presentan un desfase más importante y, en consecuencia, contribuyen en mayor medida a la métrica Magnitud del desfase. Debido al cambio de covariante, la distribución subyacente de una característica no necesariamente necesita cambiar para tener una importancia de característica relativamente alta. |
| Umbral | La magnitud de desfase de datos más allá del umbral establecido desencadena alertas. Configure el valor de umbral en la configuración del monitor. |
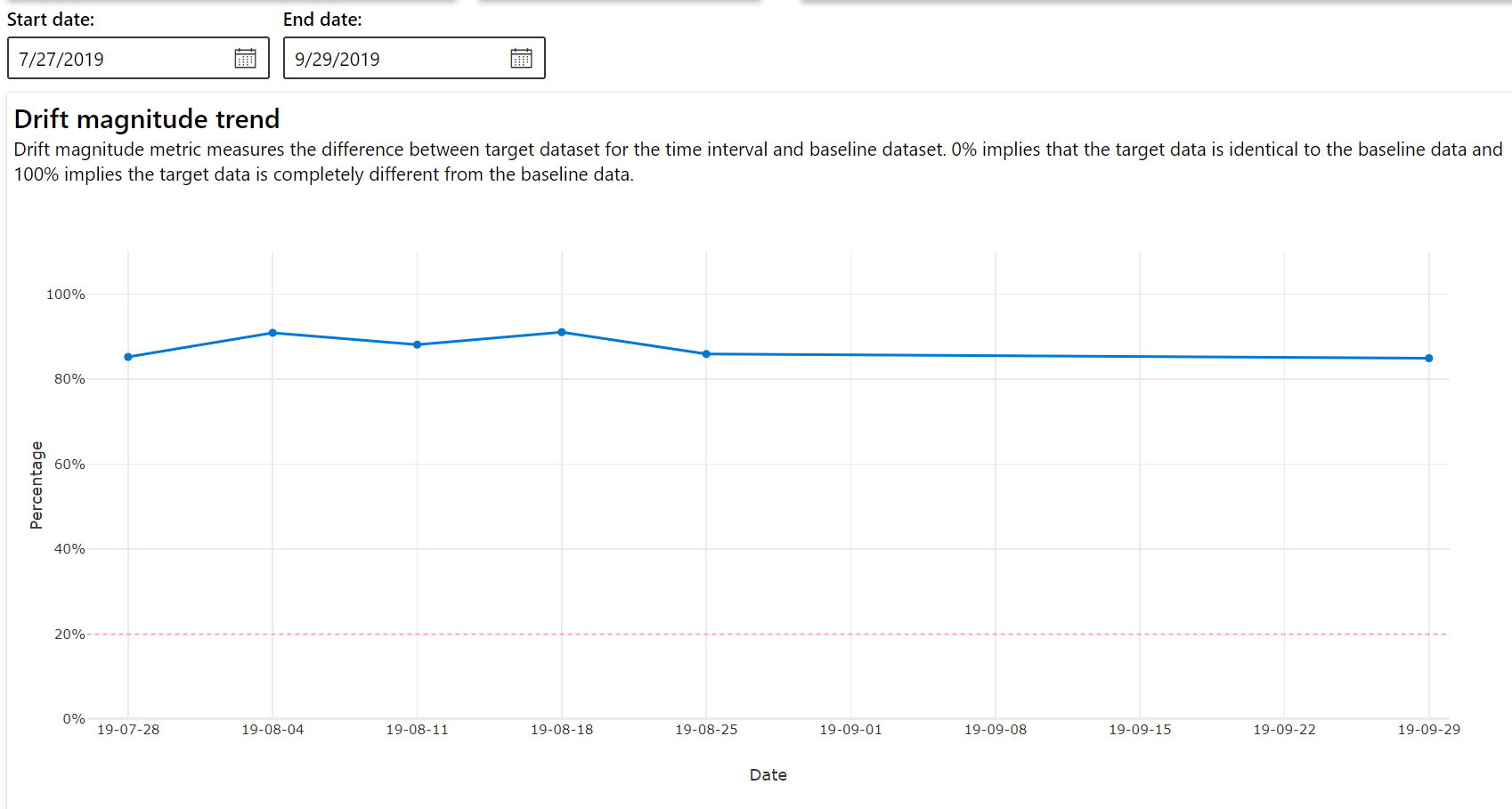
Tendencia de magnitud de desfase
Vea cómo el conjunto de datos difiere del conjunto de datos de destino en el período de tiempo especificado. Cuanto más cerca del 100 %, más difieren los dos conjuntos de datos.
Magnitud de desfase por características
Esta sección contiene información de nivel de característica sobre el cambio en la distribución de la característica seleccionada y otras estadísticas, con el tiempo.
El conjunto de datos de destino también se genera un perfil a lo largo del tiempo. La distancia estadística entre la distribución de línea base de cada característica se compara con el conjunto de datos de destino a lo largo del tiempo. Conceptualmente, esto se parece a la magnitud del desfase de datos. Sin embargo, esta distancia estadística es para una característica individual en lugar de para todas las características. También están disponibles min, max y mean.
En Estudio de Azure Machine Learning, seleccione una barra en el gráfico para ver los detalles de nivel de característica de esa fecha. De forma predeterminada, verá la distribución del conjunto de datos de línea base y la distribución del trabajo más reciente de la misma característica.
Estas métricas también se pueden recuperar en el SDK de Python mediante el método get_metrics() en un objeto DataDriftDetector.
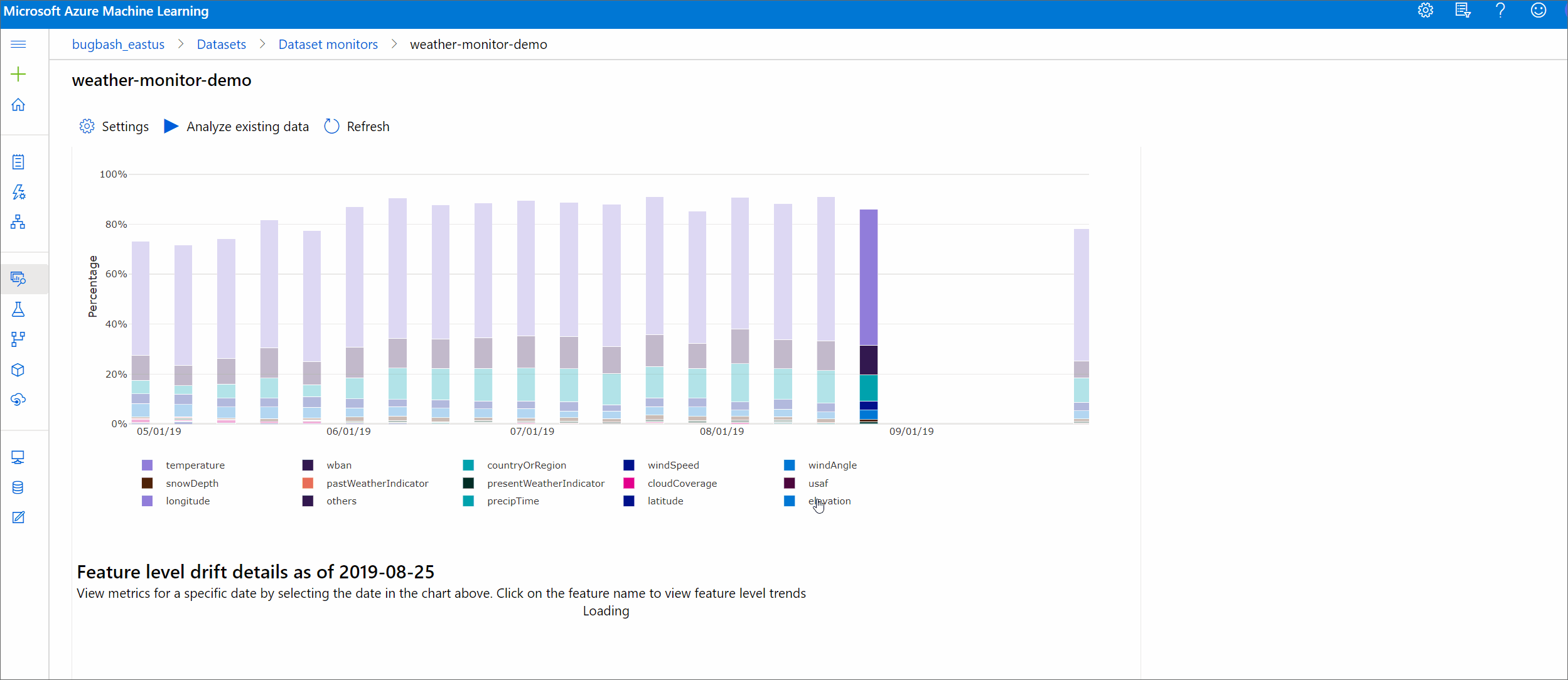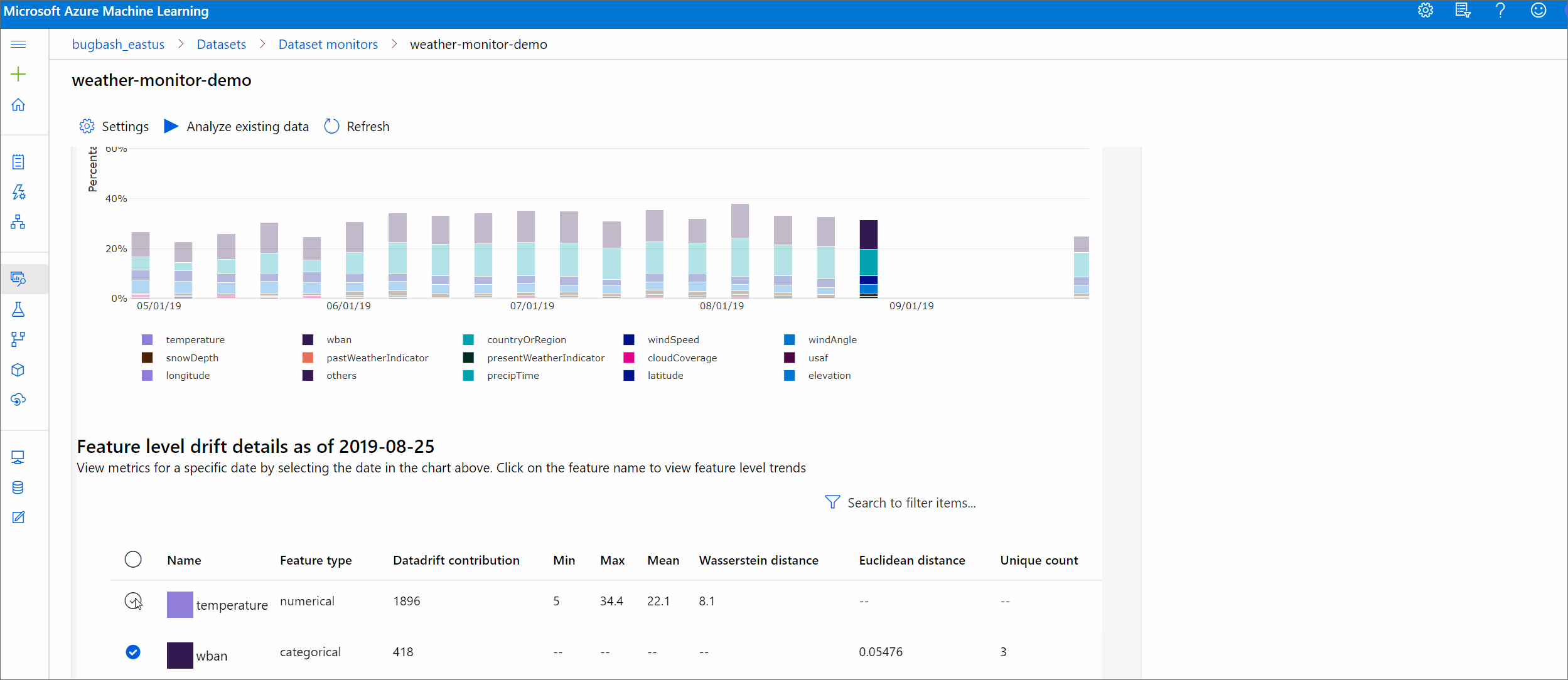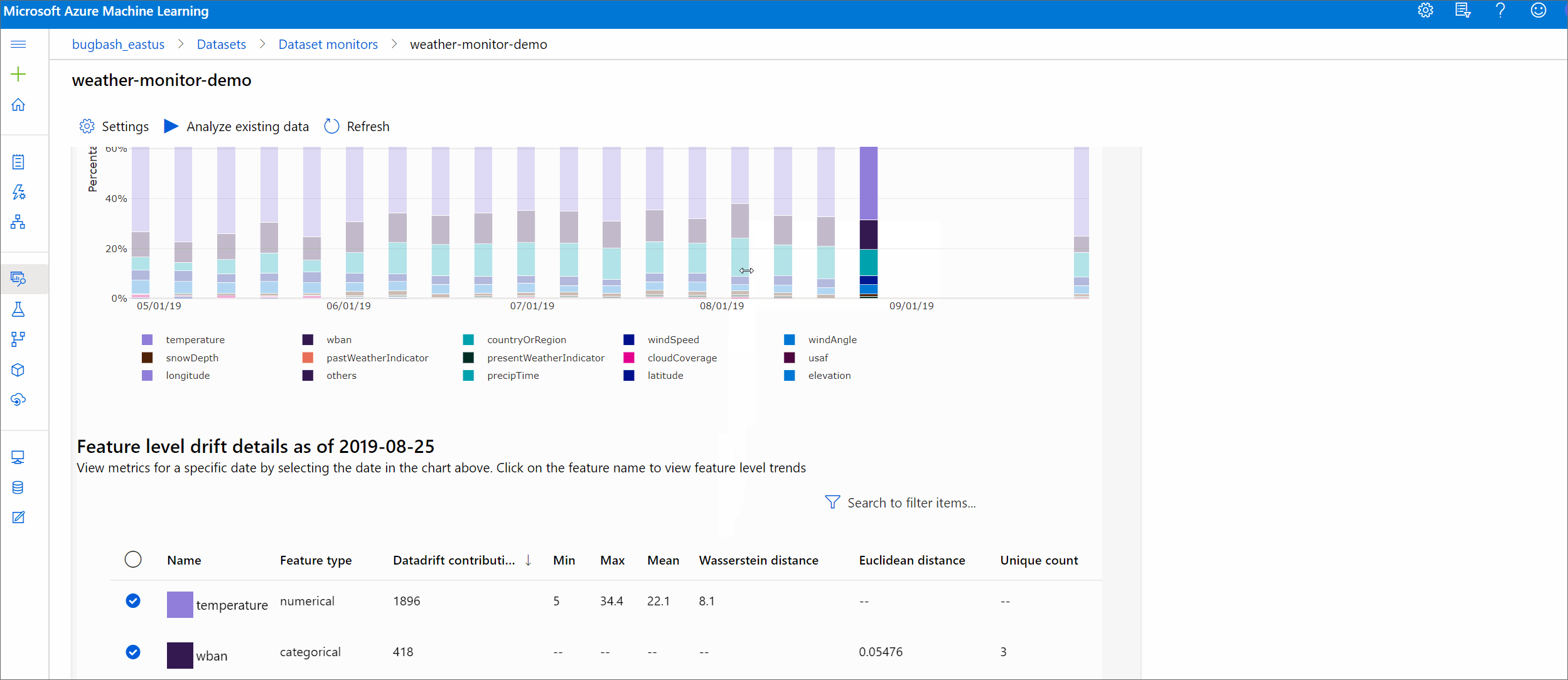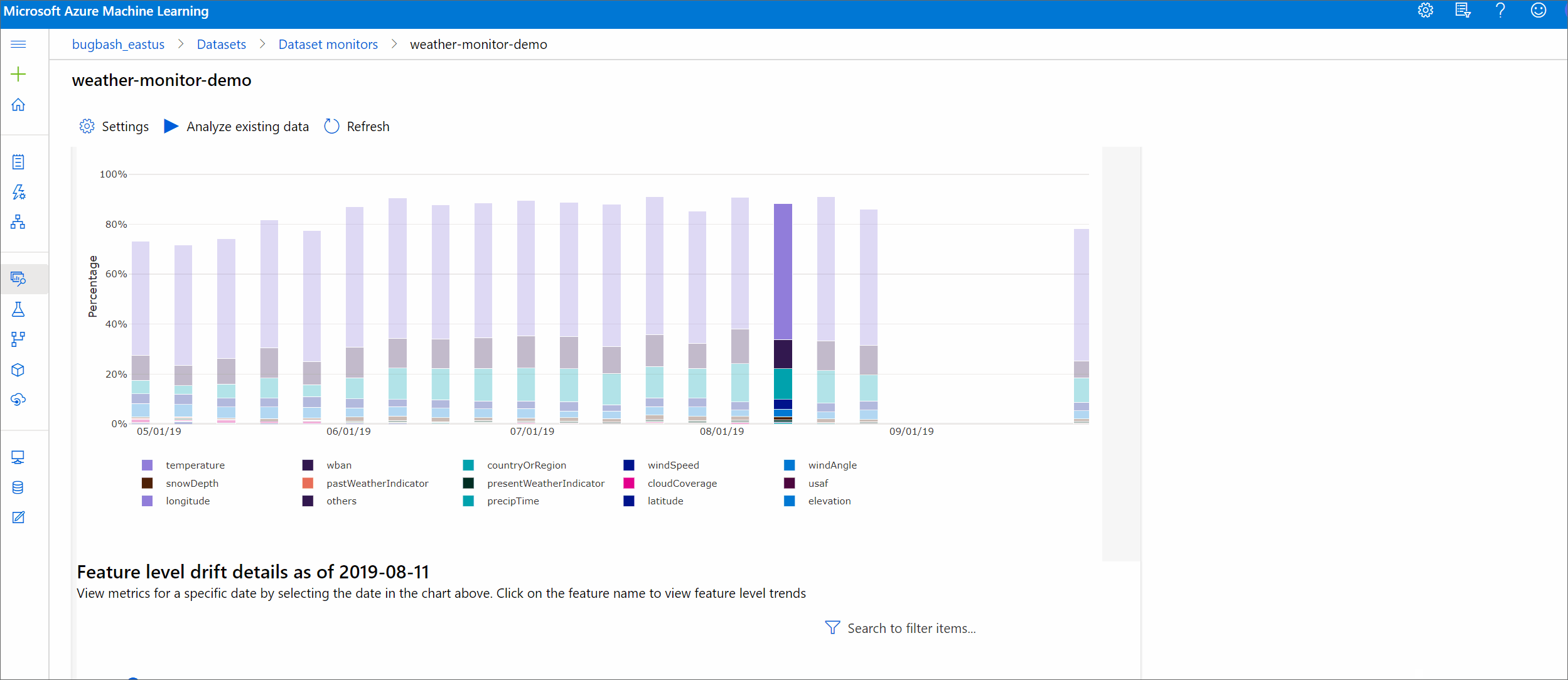
Detalles de la característica
Por último, desplácese hacia abajo para ver los detalles de cada característica individual. Use las listas desplegables sobre el gráfico para seleccionar la característica y, además, seleccione la métrica que desea ver.
Las métricas del gráfico dependen del tipo de característica.
Características numéricas
Métrica Descripción Distancia de Wasserstein Cantidad mínima de trabajo para transformar la distribución de la línea base en la distribución de destino. Valor medio Valor promedio de la característica. Valor mínimo Valor mínimo de la característica. Valor máximo Valor máximo de la característica. Características de categorías
Métrica Descripción Distancia euclidiana Calculado para columnas categóricas. La distancia euclidiana se calcula en dos vectores, generados a partir de la distribución empírica de la misma columna categórica de dos conjuntos de datos. 0 indica ninguna diferencia en las distribuciones empíricas. Cuanto más se desvía de 0, más esta columna ha desfase. Las tendencias se pueden observar desde un gráfico de series temporales de esta métrica y pueden ser útiles para descubrir una característica de desfase. Valores únicos Número de valores únicos (cardinalidad) de la característica.
En este gráfico, seleccione una sola fecha para comparar la distribución de características entre el destino y esta fecha para la característica mostrada. En el caso de las características numéricas, se muestran dos distribuciones de probabilidad. Si la característica es numérica, se muestra un gráfico de barras.
Métricas, alertas y eventos
Las métricas se pueden consultar en el recurso de Azure Application Insights asociado con el área de trabajo de aprendizaje automático. Tiene acceso a todas las características de Application Insights, incluida la configuración de reglas de alertas personalizadas y grupos de acciones para desencadenar una acción como correo electrónico, SMS, inserción o voz o función de Azure. Consulte la documentación completa de Application Insights para más información.
Para empezar, vaya a Azure Portal y seleccione la página Información general de su área de trabajo. El recurso de Application Insights asociado está en el extremo derecho:

Seleccione Registros (Analytics) en Supervisión en el panel izquierdo:
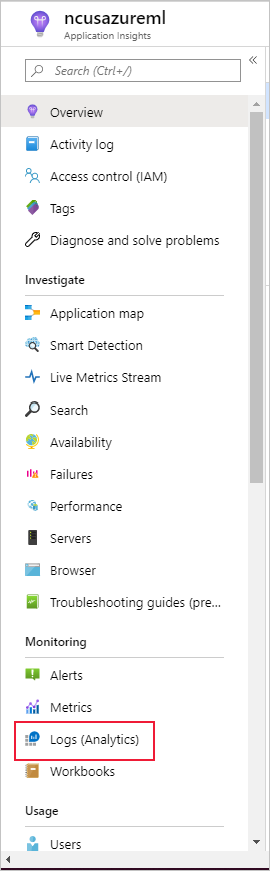
Las métricas del monitor de conjuntos de datos se almacenan como customMetrics. Para verlas, puede escribir y ejecutar una consulta después de configurar un monitor de conjuntos de datos:

Después de identificar las métricas para configurar reglas de alerta, cree una regla:
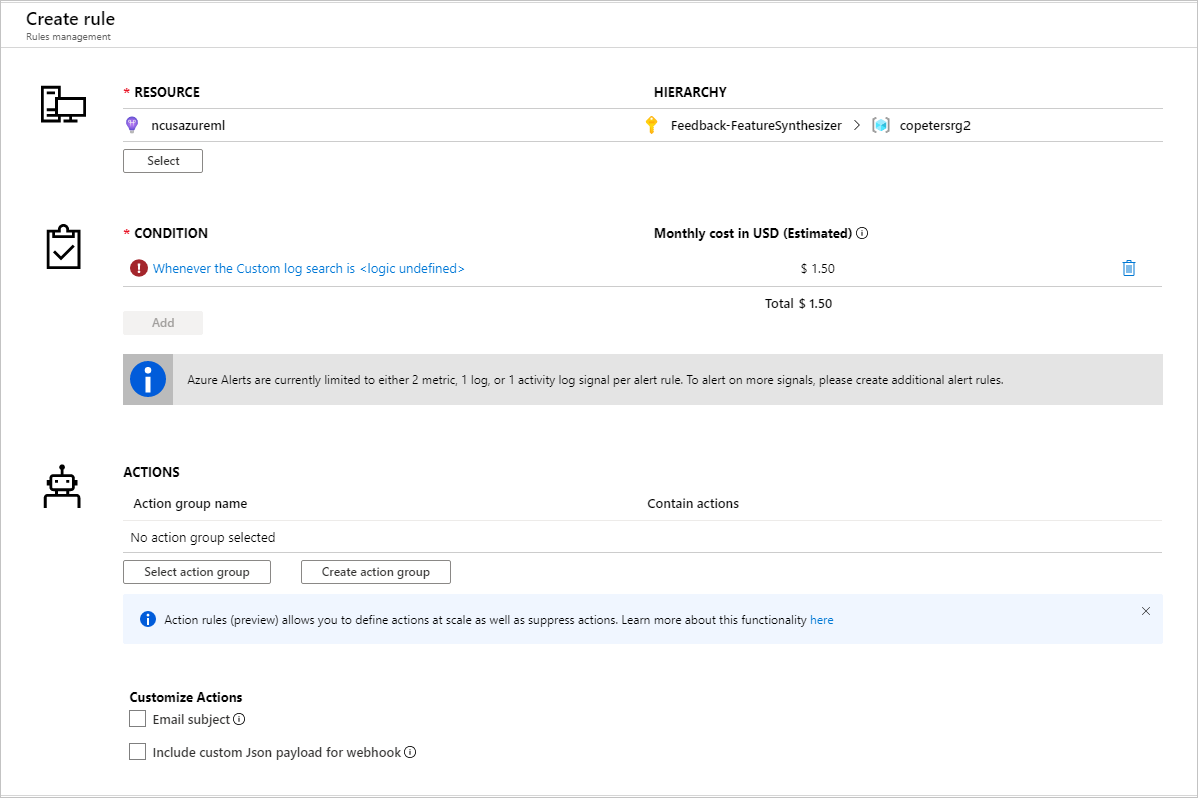
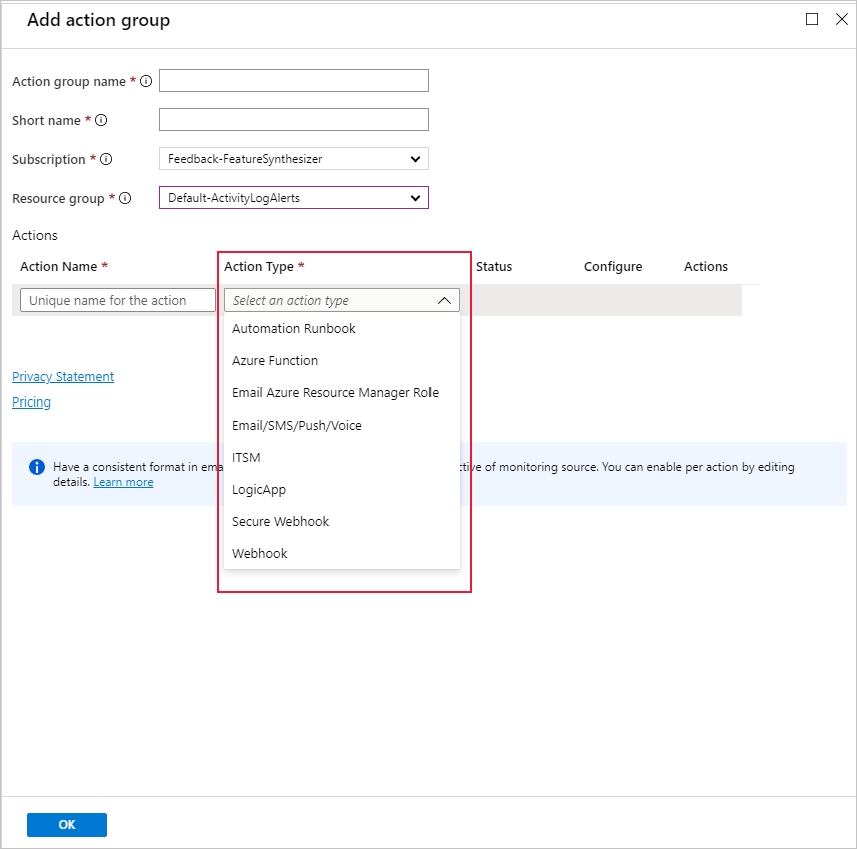
Puede usar un grupo de acciones existente o crear uno nuevo para definir la acción que se realizará cuando se cumplan las condiciones establecidas:
Solución de problemas
Limitaciones y problemas conocidos de los monitores de desfase de datos:
El intervalo de tiempo del análisis de datos históricos está limitado a 31 intervalos de la configuración de frecuencia del monitor.
Limitación de 200 características, a menos que no se especifique ninguna lista de características (se usan todas las características).
El tamaño de proceso debe ser lo suficientemente grande como para controlar los datos.
Asegúrese de que el conjunto de datos tiene datos dentro de la fecha de inicio y finalización de un trabajo de supervisión determinado.
Los monitores de conjuntos de datos solo funcionan en conjuntos de datos que contienen 50 filas o más.
Las columnas o características del conjunto de datos se clasifican como categóricas o numéricas en función de las condiciones de la tabla siguiente. Si la característica no cumple estas condiciones por ejemplo, una columna de tipo cadena con >100 valores únicos, la característica se quita del algoritmo de desfase de datos, pero sigue generando perfiles.
Tipo de característica Tipo de datos Condición Limitaciones Categorías cuerda / cadena El número de valores únicos de la característica es menor que 100 y menor que el 5 % del número de filas. NULL se trata como su propia categoría. Numérico int, float Los valores de la característica son de un tipo de datos numérico y no cumplen la condición de una característica categórica. Característica eliminada si >el 15 % de los valores son null. Cuando haya creado un monitor de desfase de datos, pero no pueda ver datos en la página Monitores de conjuntos de datos en Estudio de Azure Machine Learning, intente lo siguiente.
- Compruebe si ha seleccionado el intervalo de fechas correcto en la parte superior de la página.
- En la pestaña Monitores de conjuntos de datos, seleccione el vínculo de experimento para comprobar el estado del trabajo. El vínculo se encuentra en el extremo derecho de la tabla.
- Si el trabajo se completó correctamente, compruebe los registros del controlador para ver el número de métricas que se han generado o si hay algún mensaje de advertencia. Busque registros de controladores en la pestaña Salida y registros después de seleccionar un experimento.
Si la función
backfill()del SDK no genera la salida esperada, puede deberse a un problema de autenticación. Al crear el proceso para pasar a esta función, no useRun.get_context().experiment.workspace.compute_targets. En su lugar, use una ServicePrincipalAuthentication como la siguiente para crear el proceso que se pasa en esa funciónbackfill():
Nota:
No codifique de forma rígida la contraseña de la entidad de servicio en el código. En su lugar, recuperelo del entorno de Python, el almacén de claves u otro método seguro de acceso a secretos.
auth = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=app_id,
service_principal_password=client_secret
)
ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx")
compute = ws.compute_targets.get("xxx")
Desde el recopilador de datos de modelos, los datos pueden tardar hasta 10 minutos en llegar a la cuenta de Blob Storage. Sin embargo, normalmente tarda menos tiempo. En un script o cuaderno, espere 10 minutos para asegurarse de que las celdas siguientes se ejecutan correctamente.
import time time.sleep(600)
Pasos siguientes
- Vaya a Estudio de Azure Machine Learning o al cuaderno de Python para configurar un monitor de conjunto de datos.
- Consulte cómo configurar el desfase de datos en modelos implementados en Azure Kubernetes Service.
- Configure los monitores de desfase de un conjunto de datos con Azure Event Grid.