Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
La solución Azure Machine Learning tiene varias dependencias entrantes y salientes. Algunas de estas dependencias pueden plantear un riesgo de filtración de datos que algún agente malintencionado que esté dentro de su organización podría aprovechar. En este documento se explica cómo limitar los requisitos de entrada y salida para minimizar el riesgo de filtración de datos.
Entrante: si la instancia de proceso o el clúster usa una dirección IP pública, tiene una etiqueta de servicio entrante en
azuremachinelearning(puerto 44224). Para controlar este tráfico entrante, puede usar un grupo de seguridad de red (NSG) y etiquetas de servicio. Es difícil ocultar las IP de servicio de Azure, por lo que existe un riesgo bajo de filtración de datos. También puede configurar el proceso de manera que no use una IP pública. De esta forma, se eliminarán los requisitos de entrada.Salida: si los agentes malintencionados no tienen acceso de escritura a los recursos de salida de destino, no podrán usar esa salida para un proceso de filtración de datos. Microsoft Entra ID, Azure Resource Manager, Azure Machine Learning y el Registro de contenedor de Microsoft se incluyen en esta categoría. Por otro lado, Storage y AzureFrontDoor.frontend sí que se pueden usar en un proceso de filtración de datos.
Salida de almacenamiento: este requisito procede de la instancia de proceso y el clúster de proceso. Un agente malintencionado puede usar esta regla de salida para filtrar datos mediante procesos de aprovisionamiento y guardado de datos en su propia cuenta de almacenamiento. Para disminuir el riesgo de filtración de datos, puede usar una directiva de punto de conexión de servicio de Azure junto con la arquitectura simplificada de comunicación de nodo de Azure Batch.
Salida de AzureFrontDoor.frontend: la UI de Estudio de Azure Machine Learning y AutoML utilizan Azure Front Door. En lugar de permitir la salida a la etiqueta de servicio (AzureFrontDoor.frontend), cambie a los siguientes nombres de dominio completos (FQDN). Al cambiar a estos FQDN, se quita el tráfico de salida innecesario incluido en la etiqueta de servicio y solo se permite lo necesario para Estudio de Azure Machine Learning interfaz de usuario y AutoML.
ml.azure.comautomlresources-prod-d0eaehh7g8andvav.b02.azurefd.net
Sugerencia
La información de este artículo se centra principalmente en el uso de una instancia de Azure Virtual Network. Azure Machine Learning también puede usar redes virtuales administradas. Con una red virtual administrada, Azure Machine Learning se hace cargo del trabajo de aislamiento de red para el área de trabajo y los procesos administrados.
Para abordar los problemas de filtración de datos, las redes virtuales administradas permiten restringir la salida solo al tráfico de salida aprobado. Para más información, consulte Aislamiento de red gestionada del área de trabajo.
Requisitos previos
- Una suscripción de Azure
- Una instancia de Azure Virtual Network (VNet)
- Un área de trabajo de Azure Machine Learning con un punto de conexión privado que se conecte a la red virtual.
- La cuenta de almacenamiento que se use en el área de trabajo también deberá conectarse a la VNet mediante un punto de conexión privado.
- Debe volver a crear la instancia de proceso o reducir verticalmente el clúster de proceso a cero nodos.
- No es necesario si se ha unido a la versión preliminar.
- No es necesario si tiene una instancia de proceso y un clúster de proceso nuevos creados después de diciembre de 2022.
¿Por qué es necesario usar la directiva de punto de conexión de servicio?
Las directivas de punto de conexión de servicio permiten filtrar el tráfico de red virtual de salida a cuentas de Azure Storage a través de un punto de conexión de servicio y habilitan la filtración de datos únicamente a cuentas específicas de Azure Storage. La instancia de proceso y el clúster de proceso de Azure Machine Learning requieren acceso a cuentas de almacenamiento administradas por Microsoft para su aprovisionamiento. El alias de Azure Machine Learning en las directivas de punto de conexión de servicio incluye cuentas de almacenamiento administradas por Microsoft. Usamos directivas de punto de conexión de servicio con el alias de Azure Machine Learning para evitar la filtración de datos o controlar las cuentas de almacenamiento de destino. Puede obtener más información en la documentación de la política de extremo de servicio.
1. Creación de la directiva de punto de conexión de servicio
Desde el portal de Azure, agregue una nueva política de punto de conexión de servicio. En la pestaña Aspectos básicos , proporcione la información necesaria y, a continuación, seleccione Siguiente.
En la pestaña Definiciones de directiva, realice las siguientes acciones:
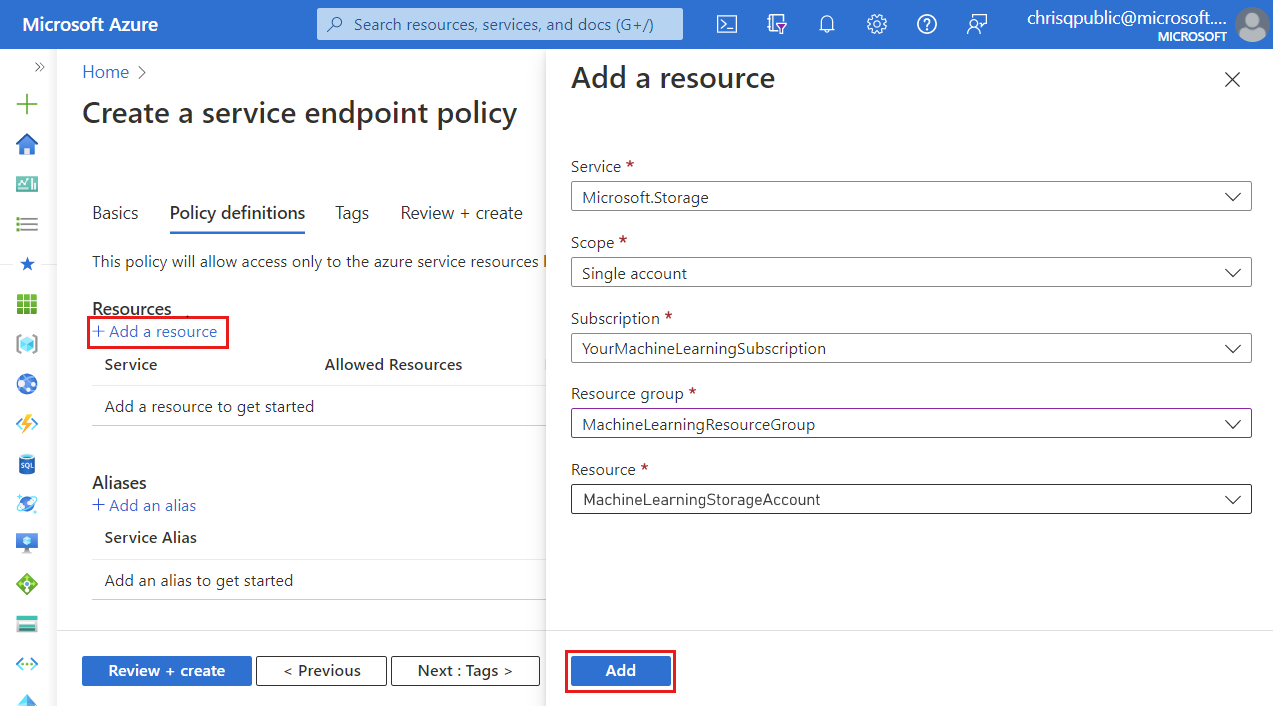
Seleccione + Agregar un recurso y proporcione la siguiente información:
- Servicio: Microsoft.Storage
- Ámbito: seleccione el ámbito como Cuenta única para limitar el tráfico de red a una cuenta de almacenamiento.
- Suscripción: la suscripción de Azure que contiene la cuenta de almacenamiento.
- Grupo de recursos: el grupo de recursos que contiene la cuenta de almacenamiento.
- Recurso: la cuenta de almacenamiento predeterminada del área de trabajo.
Seleccione Agregar para agregar la información del recurso.
Seleccione + Agregar un alias y, a continuación, seleccione
/services/Azure/MachineLearningcomo valor alias de servidor . Seleccione Agregar para agregar el alias.Nota:
La CLI de Azure y Azure PowerShell no proporcionan compatibilidad para agregar un alias a la directiva.
Seleccione Revisar y crear y, a continuación, seleccione Crear.

Importante
Si la instancia de proceso y el clúster de proceso necesitan acceso a cuentas de almacenamiento adicionales, la directiva de punto de conexión de servicio debe incluir las cuentas de almacenamiento adicionales en la sección de recursos. Tenga en cuenta que no es necesario si usa puntos de conexión privados de Storage. La directiva de punto de conexión de servicio y el punto de conexión privado son independientes.
2. Concesión de permiso para el tráfico de red entrante y saliente
Entrada
Importante
La siguiente información modifica las instrucciones proporcionadas en el artículo Protección del entorno de entrenamiento .
Importante
La siguiente información modifica las instrucciones proporcionadas en el artículo Protección del entorno de entrenamiento .
Al usar la instancia de proceso de Azure Machine Learning con una dirección IP pública, permita el tráfico entrante desde la administración de Azure Batch (etiqueta BatchNodeManagement.<region>de servicio). Una instancia de proceso sin dirección IP públicano requiere esta comunicación entrante.
Salida
Importante
La siguiente información se suma a las instrucciones proporcionadas en el entorno de entrenamiento seguro con redes virtuales y artículos Configuración del tráfico de red entrante y saliente .
Importante
La siguiente información se suma a las instrucciones proporcionadas en el entorno de entrenamiento seguro con redes virtuales y artículos Configuración del tráfico de red entrante y saliente .
A continuación, seleccione la configuración que va a usar:
Permitir el tráfico saliente a las siguientes etiquetas de servicio. Reemplace el elemento <region> con la región de Azure donde se ubique el clúster o la instancia de proceso en cuestión:
| Etiqueta de servicio | Protocolo | Puerto |
|---|---|---|
BatchNodeManagement.<region> |
CUALQUIER | 443 |
AzureMachineLearning |
TCP | 443 |
Storage.<region> |
TCP | 443 |
Nota:
Para el almacenamiento saliente, se aplicará una directiva de punto de conexión de servicio en un paso posterior para limitar el tráfico saliente.
Para obtener más información, consulte Protección de entornos de entrenamiento y Configuración del tráfico de red entrante y saliente.
Para obtener más información, consulte Protección de entornos de entrenamiento y Configuración del tráfico de red entrante y saliente.
3. Habilitación del punto de conexión de almacenamiento para la subred
Siga estos pasos para habilitar un punto de conexión de almacenamiento para la subred que contiene los clústeres y las instancias de proceso de Azure Machine Learning:
- En Azure Portal, seleccione Azure Virtual Network para el área de trabajo de Azure Machine Learning.
- En la parte izquierda de la página, seleccione Subredes y, a continuación, seleccione la subred que contiene el clúster de proceso y la instancia de proceso.
- En el formulario que aparece, expanda la lista desplegable Servicios y, a continuación, habilite Microsoft.Storage. Seleccione Guardar para guardar estos cambios.
- Aplique la directiva de punto de conexión de servicio a la subred del área de trabajo.

4. Entornos mantenidos
Cuando use entornos mantenidos de Azure Machine Learning, asegúrese de que utiliza la versión más reciente del entorno. El registro de contenedor del entorno también deberá ser mcr.microsoft.com. Siga estos pasos para comprobar el registro de contenedor:
En Azure Machine Learning Studio, seleccione el área de trabajo y, después, entornos.
Compruebe que Azure Container Registry comienza con un valor de
mcr.microsoft.com.Importante
Si el registro de contenedor es
viennaglobal.azurecr.io, no podrá usar el entorno mantenido con la filtración de datos. Intente actualizar la versión del entorno mantenido a la más reciente.Si usa
mcr.microsoft.com, también deberá permitir la configuración de salida para los siguientes recursos. A continuación, seleccione la opción de configuración que va a usar:Permita el tráfico saliente a través del puerto TCP 443 a los siguientes tags de servicio. Reemplace el elemento
<region>con la región de Azure donde se ubique el clúster o la instancia de proceso en cuestión.MicrosoftContainerRegistry.<region>AzureFrontDoor.FirstParty
Pasos siguientes
Para más información, consulte los siguientes artículos.