Generación de un panel de Información sobre IA responsable en la interfaz de usuario de Studio
En este artículo,creará un panel de IA responsable y un cuadro de mandos (versión preliminar) con una experiencia sin código en la UI de Estudio de Azure Machine Learning.
Importante
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin un Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas.
Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Para acceder al asistente de generación de paneles y generar un panel de IA responsable, haga lo siguiente:
Registre el modelo en Azure Machine Learning para poder acceder a la experiencia sin código.
En el panel izquierdo de Estudio de Azure Machine Learning, seleccione la pestaña Modelos.
Seleccione el modelo registrado para el que quiere crear información de IA responsable y. después, seleccione la pestaña Detalles.
Seleccione Create Responsible AI dashboard (preview) [Crear un panel de IA responsable (versión preliminar)].

Para obtener más información sobre los tipos de modelo y las limitaciones admitidos en el panel de inteligencia artificial responsable, consulte los escenarios y limitaciones admitidos.
El asistente proporciona una interfaz para introducir todos los parámetros necesarios para crear su panel de inteligencia artificial responsable sin tener que modificar el código. La experiencia se realiza por completo en la UI de Estudio de Azure Machine Learning. Studio presenta un flujo guiado y texto informativo para ayudar a contextualizar la variedad de opciones relacionadas con los componentes de inteligencia artificial responsable con los que quiere rellenar el panel.
El asistente se divide en cinco secciones:
- Conjuntos de datos de entrenamiento
- Conjunto de datos de prueba
- Tarea de modelado
- Componentes del panel
- Parámetros del componente
- Configuración del experimento
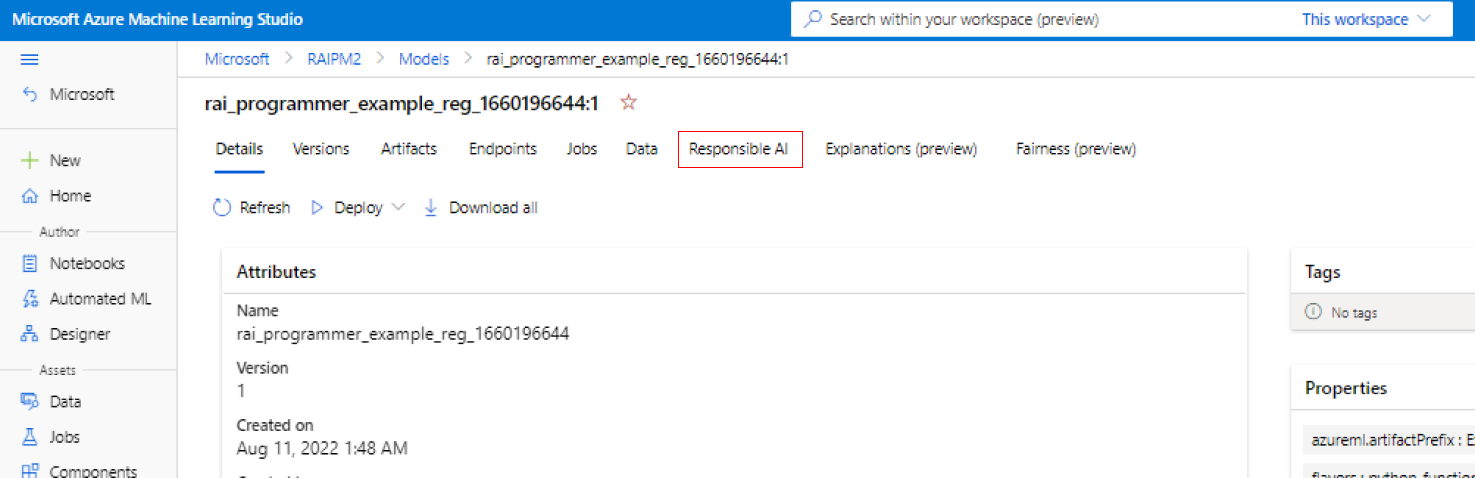
Selección de los conjuntos de datos
En las dos primeras secciones, seleccionará los conjuntos de datos de entrenamiento y prueba que usó al entrenar el modelo para generar información de depuración de modelos. En el caso de los componentes como el análisis causal, que no requiere un modelo, se usa el conjunto de datos de entrenamiento para entrenar el modelo causal y así generar la información causal.
Nota:
Solo se admiten formatos de conjuntos de datos tabulares en ML Table.
Seleccionar un conjunto de datos para el entrenamiento: en la lista de conjuntos de datos registrados en el área de trabajo de Azure Machine Learning, seleccione el conjunto de datos que desea usar para generar información de IA responsable para los componentes, como explicaciones del modelo y análisis de errores.
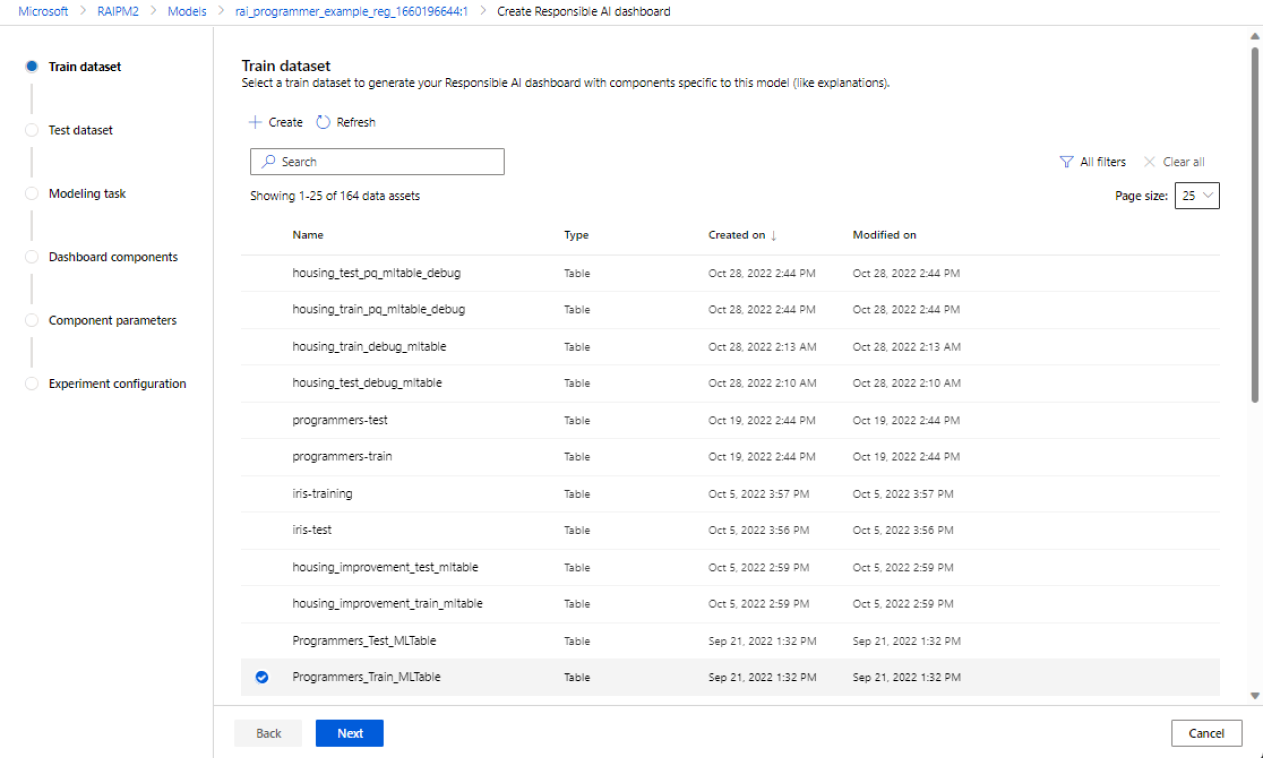
Seleccionar un conjunto de datos para realizar pruebas: en la lista de conjuntos de datos registrados, seleccione el conjunto de datos que desea usar para rellenar las visualizaciones del panel de IA responsable.
Si el conjunto de datos de entrenamiento o prueba que quiere usar no aparece en la lista, seleccione Crear para cargarlo.


Selección de la tarea de modelado
Después de seleccionar los conjuntos de datos, seleccione el tipo de tarea de modelado, como se muestra en la imagen siguiente:

Selección de los componentes del panel
El panel de inteligencia artificial responsable ofrece dos perfiles para conjuntos recomendados de herramientas que puede generar:
Model debugging (Depuración de modelos): comprenda y depure cohortes de datos erróneas en el modelo de Machine Learning mediante el análisis de errores, ejemplos hipotéticos contrafactuales, y la explicación del modelo.
Real-life interventions (Intervenciones en la vida real): comprenda y depure cohortes de datos erróneas en el modelo de Machine Learning mediante el análisis causal.
Nota
La clasificación multiclase no admite el perfil de análisis de intervenciones de la vida real.

- Seleccione el archivo de perfil que desee usar.
- Seleccione Next (Siguiente).
Configuración de parámetros para los componentes del panel
Después de seleccionar un perfil, aparece el panel Parámetros de componente para la depuración de modelos para los componentes correspondientes.

Parámetros del componente para la depuración de modelos:
Target feature (required) [Característica de destino (obligatoria)]: especifique la característica para cuya predicción recibió entrenamiento el modelo.
Características categóricas: indique qué características son categóricas para representarlas correctamente como valores de categorías en la interfaz de usuario del panel. Este campo se carga de antemano de forma automática basándose en los metadatos del conjunto de datos.
Generate error tree and heat map (Generar árbol y mapa térmico de errores): proceda a realizar las acciones de activación y desactivación para generar un componente de análisis de errores para el panel de inteligencia artificial responsable.
Features for error heat map (Características del mapa térmico de errores): seleccione hasta dos características de su elección para las que se va a generar previamente un mapa térmico de errores.
Configuración avanzada: especifique parámetros adicionales, como Maximum depth of error tree (Profundidad máxima del árbol de errores), Number of leaves in error tree (Número de hojas en el árbol de errores) y Minimum number of samples in each leaf node (Número mínimo de muestras en cada nodo hoja).
Generate counterfactual what-if examples (Generar ejemplos hipotéticos contrafactuales): proceda a realizar las acciones de activación y desactivación para generar un componente hipotético contrafactual para el panel de inteligencia artificial responsable.
Number of counterfactuals (required) [Número de contrafactuales (obligatorio)]: especifique el número de ejemplos contrafactuales que quiere generar por punto de datos. Se debe generar un mínimo de 10 para habilitar una vista de gráfico de barras de las características más alteradas, en promedio, para lograr la predicción deseada.
Range of value predictions (required) [Intervalo de predicciones de valor (obligatorio)]: especifique para escenarios de regresión el intervalo en el que quiere que los ejemplos contrafactuales tengan valores de predicción. Para escenarios de clasificación binaria, el rango se establecerá de forma automática para generar contrafactuales para la clase opuesta de cada punto de datos. Para escenarios de clasificación múltiple, use la lista desplegable para especificar como qué clase quiere que se prediga cada punto de datos.
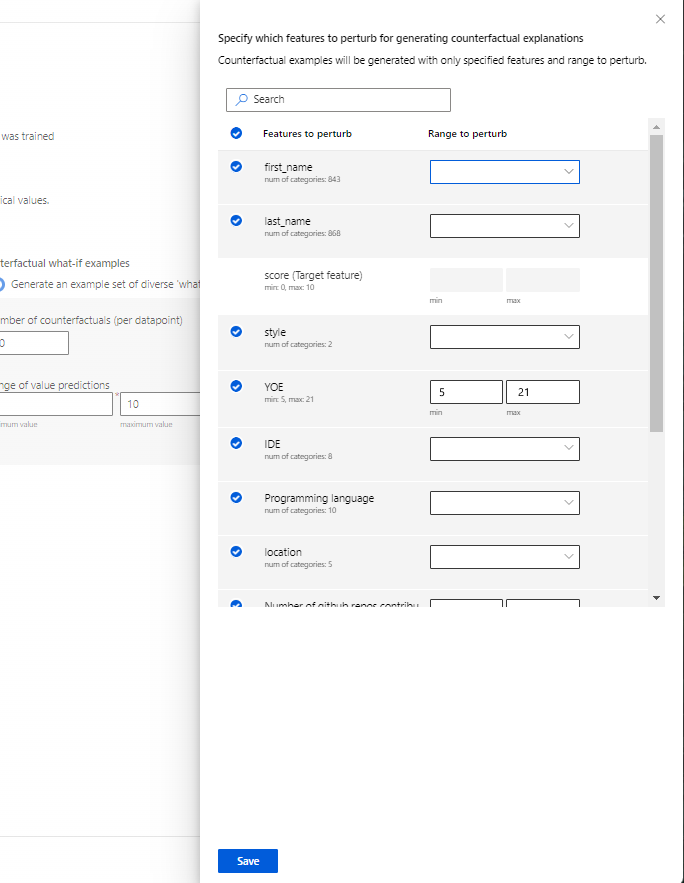
Specify which features to perturb (Especificar las características que se van a alterar): de forma predeterminada, todas las características se alterarán. Pero si solo desea que se produzcan características específicas, seleccione Specify which features to perturb for generating counterfactual explanations (Especificar qué características se van a perturb para generar explicaciones contrafactuales) para mostrar un panel con una lista de características que se van a seleccionar.
Al seleccionar Especificar las características que se van a alterar, puede especificar en qué intervalo quiere permitir las alteraciones. Por ejemplo: para la característica YOE (Años de experiencia), especifique que los contrafactuales deben tener valores de características comprendidos solo entre 10 y 21 en lugar de los valores predeterminados de entre 5 y 21.
Generar explicaciones: proceda a realizar las acciones de activación y desactivación para generar un componente de explicación del modelo para el panel de inteligencia artificial responsable. No es necesaria ninguna configuración, porque se usará un explicador mímico de caja opaca predeterminado para generar importancias de características.

Por otro lado, si selecciona el perfil de Intervenciones en la vida real, verá que la siguiente pantalla genera un análisis causal. Esto le ayudará a comprender los efectos causales de las características que quiere "tratar" en un determinado resultado que desea optimizar.

Los parámetros del componente para las intervenciones en la vida real usan el análisis causal. Haga lo siguiente:
- Característica de destino (obligatoria): elija el resultado para el que quiere que se calculen los efectos causales.
- Características de tratamiento (obligatorias): elija una o varias características que le interese cambiar ("tratar") para optimizar el resultado de destino.
- Características categóricas: indique qué características son categóricas para representarlas correctamente como valores de categorías en la interfaz de usuario del panel. Este campo se carga de antemano de forma automática basándose en los metadatos del conjunto de datos.
- Configuración avanzada: especifique parámetros adicionales para el análisis causal, como características heterogéneas (es decir, características adicionales para comprender la segmentación causal en el análisis además de las características de tratamiento) y qué modelo causal quiere que se use.
Configuración del experimento
Por último, configure el experimento para iniciar un trabajo a fin de generar el panel de inteligencia artificial responsable.

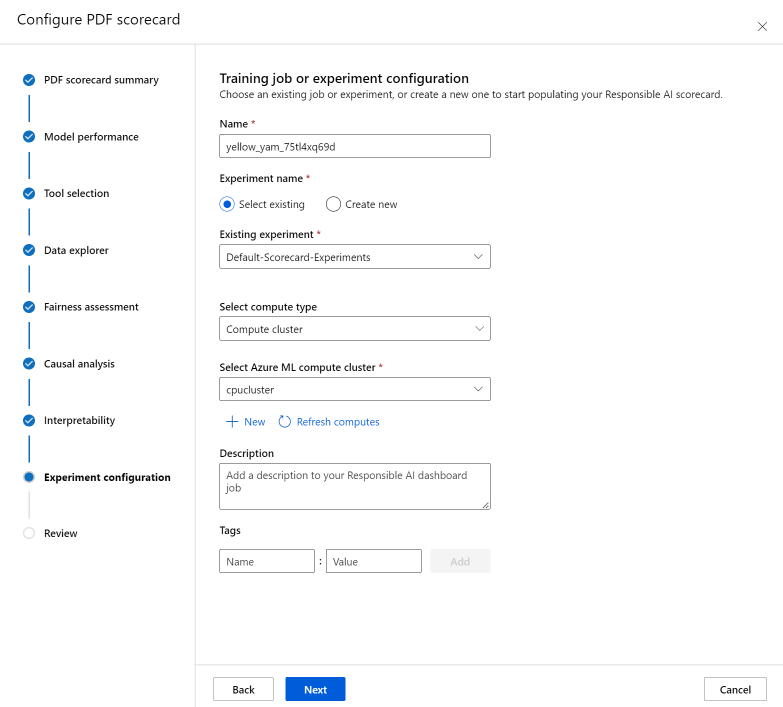
En el panel Entrenamiento de trabajo o Configuración del experimento, haga lo siguiente:
- Nombre: asigne un nombre único al panel para que pueda diferenciarlo cuando vea la lista de paneles para un modelo determinado.
- Nombre del experimento: seleccione un experimento existente en el que ejecutar el trabajo o cree un nuevo experimento.
- Experimento existente: en la lista desplegable, seleccione un experimento existente.
- Select compute type (Seleccionar tipo de proceso): especifique el tipo de proceso que quiere usar para ejecutar el trabajo.
- Select compute (Seleccionar proceso): en la lista desplegable, seleccione el proceso que desea usar. Si no hay recursos de proceso existentes, seleccione el símbolo más (+) para crear un nuevo recurso de proceso y, después, actualice la lista.
- Descripción: agregue una descripción más larga del panel de inteligencia artificial responsable.
- Etiquetas: agregue etiquetas a este panel de inteligencia artificial responsable.
Una vez finalizada la configuración del experimento, seleccione Crear para iniciar la generación del panel de inteligencia artificial responsable. Se le redirigirá a la página del experimento para realizar un seguimiento del progreso del trabajo con un vínculo al panel de IA responsable resultante desde la página del trabajo cuando se complete.
Para obtener información sobre cómo ver y usar el panel de IA responsable, consulte Uso del panel de IA responsable en Estudio de Azure Machine Learning.
Cómo generar un cuadro de mandos de IA responsable (versión preliminar)
Una vez creado un panel, puede usar una interfaz de usuario sin código en Estudio de Azure Machine Learning para personalizar y generar un cuadro de mandos de IA responsable. Esto le permite compartir información clave para la implementación responsable del modelo, como la equidad y la importancia de las características, con partes interesadas no técnicas y técnicas. De forma similar a la creación de un panel, puede usar los pasos siguientes para acceder al asistente para la generación de cuadros de mandos:
- Vaya a la pestaña Modelos desde la barra de navegación izquierda de Estudio de Azure Machine Learning.
- Seleccione el modelo registrado para el que quiere crear un cuadro de mandos y seleccione la pestaña IA responsable.
- En el panel superior, seleccione Crear información de IA responsable (versión preliminar) y, después, Generar nuevo cuadro de mandos PDF.
El asistente le permitirá personalizar el cuadro de mandos PDF sin tener que tocar el código. La experiencia tiene lugar íntegramente en la interfaz de usuario de Estudio de Azure Machine Learning para ayudar a contextualizar la variedad de opciones en los componentes de inteligencia artificial responsable con un flujo guiado y texto informativo para ayudarle a elegir los componentes de inteligencia artificial responsable con los que quiere rellenar el cuadro de mandos. El asistente se divide en siete pasos, con un octavo paso (evaluación de equidad) que solo aparecerá para los modelos con características categóricas:
- Resumen del cuadro de mandos PDF
- Rendimiento del modelo
- Selección de herramientas
- Análisis de datos (anteriormente denominado explorador de datos)
- Análisis causal
- Interoperabilidad
- Configuración del experimento
- Evaluación de equidad (solo si existen características categóricas)
Configuración del cuadro de mandos
En primer lugar, escriba un título descriptivo para el cuadro de mandos. También puede escribir una descripción opcional sobre la funcionalidad del modelo, los datos en los que se entrenó y evaluó, el tipo de arquitectura, etc.
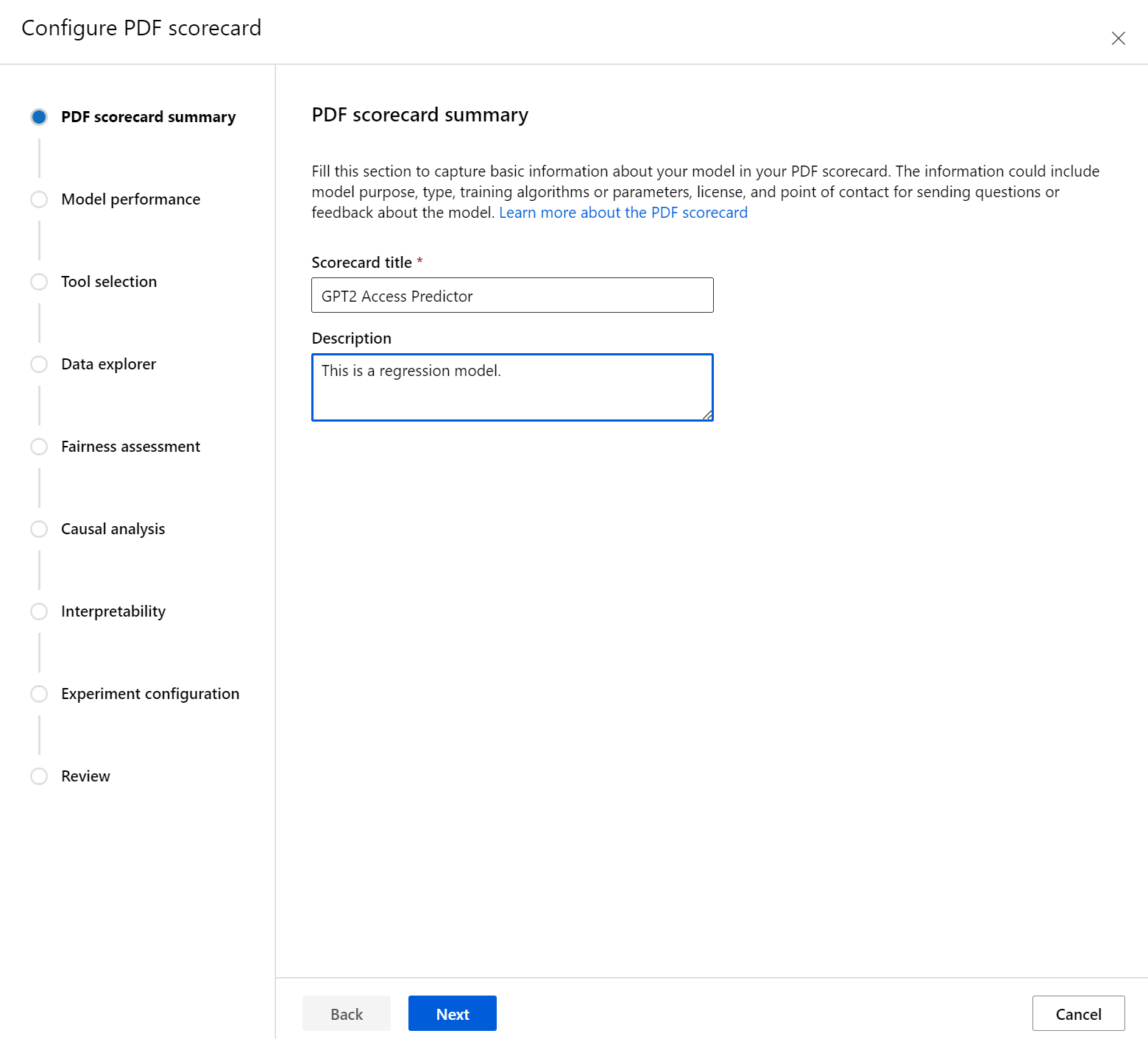
La sección Rendimiento del modelo permite incorporar las métricas de evaluación de modelos estándar del sector en el cuadro de mandos, al tiempo que permite establecer los valores de destino deseados para las métricas seleccionadas. Seleccione las métricas de rendimiento deseadas (hasta tres) y los valores de destino mediante las listas desplegables.
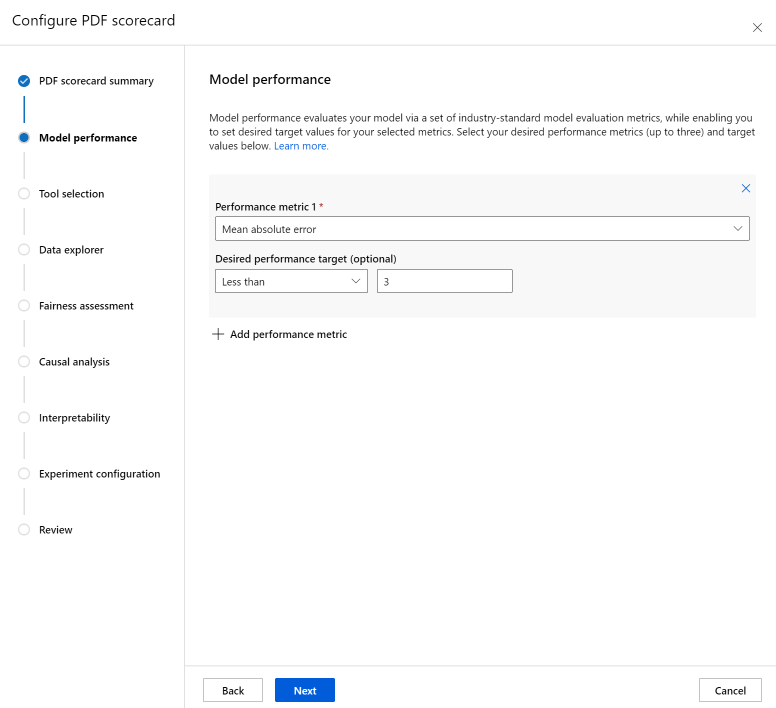
El paso de selección de herramientas le permite elegir qué componentes posteriores desea incluir en el cuadro de mandos. Active Incluir en el cuadro de mandos para incluir todos los componentes o active o desactive cada componente individualmente. Seleccione el icono de información ("i" en un círculo) junto a los componentes para obtener más información sobre ellos.
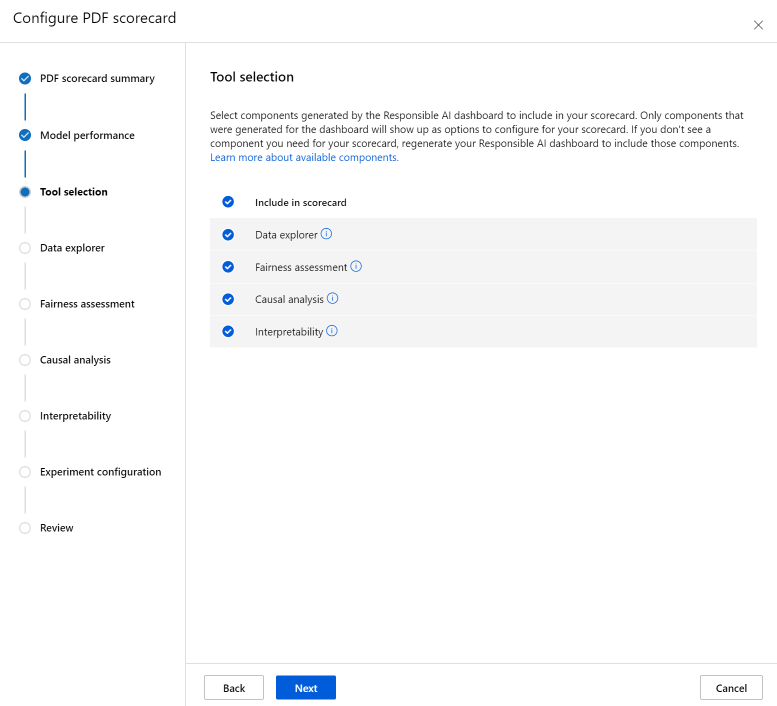
La sección Análisis de datos (anteriormente denominada Explorador de datos) habilita el análisis de cohortes. Aquí puede identificar problemas de sobre en infrarrepresentación para explorar cómo se agrupan los datos en el conjunto de datos y cómo afectan las predicciones de modelos a cohortes de datos específicas. Use casillas en la lista desplegable para seleccionar las características de interés siguientes para identificar el rendimiento del modelo en sus cohortes subyacentes.
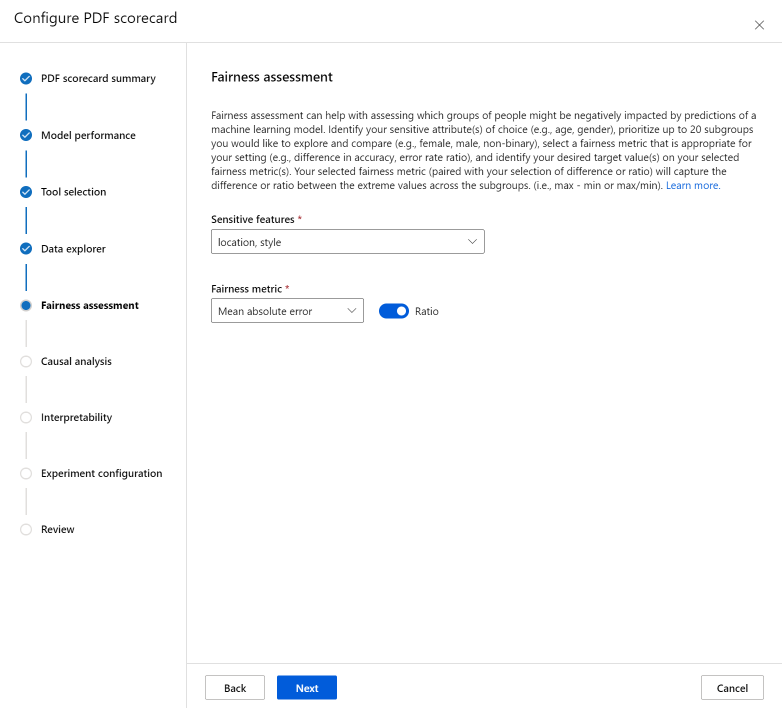
La sección evaluación de equidad puede ayudar a evaluar qué grupos de personas podrían verse afectados negativamente por las predicciones de un modelo de aprendizaje automático. Hay dos campos en esta sección.
Características confidenciales: identifique los atributos confidenciales que prefiera (por ejemplo, edad, género) al dar prioridad a hasta 20 subgrupos que desea explorar y comparar.
Métrica de equidad: seleccione una métrica de equidad que sea adecuada para la configuración (por ejemplo, la diferencia en la precisión, la relación de tasa de errores) e identifique los valores de destino deseados en las métricas de equidad seleccionadas. La métrica de equidad seleccionada (emparejada con la selección de diferencia o relación a través del botón de alternancia) capturará la diferencia o relación entre los valores extremos en los subgrupos. (máx - mín o máx/mín).
Nota:
Actualmente, la evaluación de equidad solo está disponible para atributos terminantemente confidenciales, como el género.
La sección Análisis causal responde a preguntas del mundo real de tipo "y si" sobre cómo los cambios de tratamiento afectarían a un resultado real. Si el componente causal se activa en el panel de IA responsable para el que está generando un cuadro de mandos, no se necesita más configuración.
La sección Interpretabilidad genera descripciones comprensibles para las predicciones realizadas por el modelo de aprendizaje automático. Con las explicaciones del modelo, puede comprender el razonamiento subyacente a las decisiones tomadas por el modelo. Seleccione un número (K) a continuación para ver las K principales características importantes que afectan a las predicciones generales del modelo. El valor predeterminado para K es 10.
Por último, configure el experimento para iniciar un trabajo a fin de generar el cuadro de mandos. Estas configuraciones son las mismas que las del panel de IA responsable.
Por último, revise las configuraciones y seleccione Crear para iniciar el trabajo.
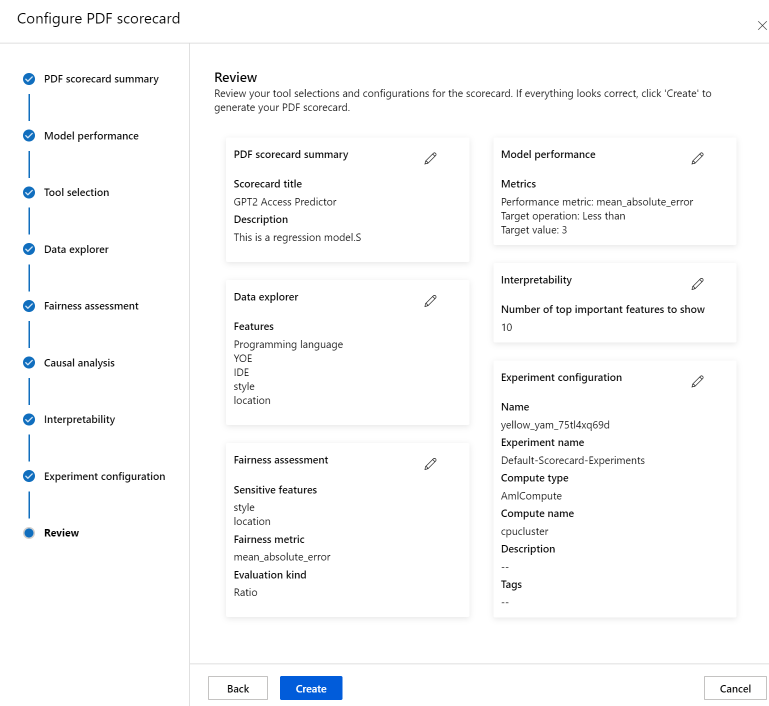
Se le redirigirá a la página del experimento para realizar un seguimiento del progreso del trabajo cuando lo haya iniciado. Para obtener información sobre cómo ver y usar el cuadro de mandos de IA responsable, consulte Uso del cuadro de mandos de IA responsable (versión preliminar).









Pasos siguientes
- Cuando se genere el panel de inteligencia artificial responsable, vea cómo acceder a él y usarlo en Estudio de Azure Machine Learning.
- Obtenga más información sobre los conceptos y técnicas detrás del panel de inteligencia artificial responsable.
- Más información sobre cómo recopilar datos de forma responsable.
- Más información sobre cómo usar el panel de IA responsable y el cuadro de mandos para depurar datos y modelos, e informar sobre la mejor toma de decisiones en esta entrada de blog de la comunidad tecnológica.
- Más información sobre cómo el Servicio Nacional de Salud del Reino Unido (NHS) ha usado el panel de inteligencia artificial responsable y el cuadro de mandos en una historia de cliente real.
- Explore las características del panel de inteligencia artificial responsable mediante esta demostración web interactiva de AI Lab.