Uso de máquinas virtuales de prioridad baja en implementaciones por lotes
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Las implementaciones de Azure Batch admiten máquinas virtuales de prioridad baja para reducir el costo de las cargas de trabajo de inferencia por lotes. Las máquinas virtuales de prioridad baja permiten usar una gran cantidad de capacidad de proceso por un bajo costo. Las máquinas virtuales de prioridad baja aprovechan la capacidad sobrante en Azure. Al especificar máquinas virtuales de prioridad baja en sus grupos, Azure puede usar este excedente cuando esté disponible.
El inconveniente a la hora de usarlas es que esas máquinas virtuales pueden no estar siempre disponibles para su asignación o pueden reemplazarse en cualquier momento, según la capacidad disponible. Por este motivo, resultan más adecuadas para las cargas de trabajo de procesamiento por lotes y asincrónicas en las que el tiempo de finalización del trabajo es flexible y el trabajo se distribuye entre muchas máquinas virtuales.
Las máquinas virtuales de prioridad baja se ofrecen a un precio considerablemente reducido en comparación con las máquinas virtuales dedicadas. Para obtener más información sobre los precios, consulte Precios de Azure Machine Learning.
Funcionamiento de la implementación por lotes con máquinas virtuales de prioridad baja
Las implementaciones por lotes de Azure Machine Learning ofrecen varias funcionalidades que facilitan el consumo y se benefician de las máquinas virtuales de prioridad baja:
- Los trabajos de implementación de Batch consumen máquinas virtuales de prioridad baja mediante la ejecución en clústeres de proceso de Azure Machine Learning creados con máquinas virtuales de prioridad baja. Una vez que una implementación está asociada a un clúster de máquinas virtuales de prioridad baja, todos los trabajos generados por dicha implementación usarán máquinas virtuales de prioridad baja. La configuración por trabajo no es posible.
- Los trabajos de implementación por lotes buscan automáticamente el número de máquinas virtuales del clúster de proceso disponible en función del número de tareas que se van a enviar. Si las máquinas virtuales han sido reemplazadas o no están disponibles, los trabajos de implementación por lotes intentan reemplazar la capacidad perdida mediante la puesta en cola de las tareas con errores en el clúster.
- Las máquinas virtuales de prioridad baja tienen una cuota de vCPU diferente de las máquinas virtuales dedicadas. Los núcleos de baja prioridad por región tienen un límite predeterminado de 100 a 3000, según el tipo de oferta de la suscripción. El número de núcleos de baja prioridad por suscripción se puede aumentar y es un valor único en todas las familias de máquinas virtuales. Consulte Cuotas de proceso de Azure Machine Learning.
Consideraciones y casos de uso
Muchas cargas de trabajo de Batch son una buena opción para las máquinas virtuales de prioridad baja. Aunque esto pueda causar retrasos adicionales en la ejecución cuando se produce la desasignación de máquinas virtuales, las posibles caídas de capacidad se pueden tolerar a costa de ejecutarse a un coste menor si hay flexibilidad con el tiempo en el que los trabajos tienen que completarse.
Al implementar modelos en puntos de conexión por lotes, la reprogramación se puede realizar en el nivel de minilotes. Con ello se obtiene la ventaja adicional de que la desasignación solo afecta a los minilotes que se están procesando en ese momento y no han finalizado en el nodo afectado. Se conservan todos los progresos realizados.
Creación de implementaciones por lotes con máquinas virtuales de prioridad baja
Los trabajos de implementación de Batch consumen máquinas virtuales de prioridad baja mediante la ejecución en clústeres de proceso de Azure Machine Learning creados con máquinas virtuales de prioridad baja.
Nota
Una vez que una implementación está asociada a un clúster de máquinas virtuales de prioridad baja, todos los trabajos generados por dicha implementación usarán máquinas virtuales de prioridad baja. La configuración por trabajo no es posible.
Puede crear un clúster de proceso de Azure Machine Learning de prioridad baja de la siguiente manera:
Cree una definición de proceso YAML como la siguiente:
low-pri-cluster.yml
$schema: https://azuremlschemas.azureedge.net/latest/amlCompute.schema.json
name: low-pri-cluster
type: amlcompute
size: STANDARD_DS3_v2
min_instances: 0
max_instances: 2
idle_time_before_scale_down: 120
tier: low_priority
Cree el proceso con el siguiente comando:
az ml compute create -f low-pri-cluster.yml
Una vez creado el nuevo proceso, puede crear o actualizar la implementación para usar el nuevo clúster:
Para crear o actualizar una implementación en el nuevo clúster de proceso, cree una configuración YAML como la siguiente:
$schema: https://azuremlschemas.azureedge.net/latest/batchDeployment.schema.json
endpoint_name: heart-classifier-batch
name: classifier-xgboost
description: A heart condition classifier based on XGBoost
type: model
model: azureml:heart-classifier@latest
compute: azureml:low-pri-cluster
resources:
instance_count: 2
settings:
max_concurrency_per_instance: 2
mini_batch_size: 2
output_action: append_row
output_file_name: predictions.csv
retry_settings:
max_retries: 3
timeout: 300
Después, cree la implementación con el siguiente comando:
az ml batch-endpoint create -f endpoint.yml
Visualización y supervisión de la desasignación de nodos
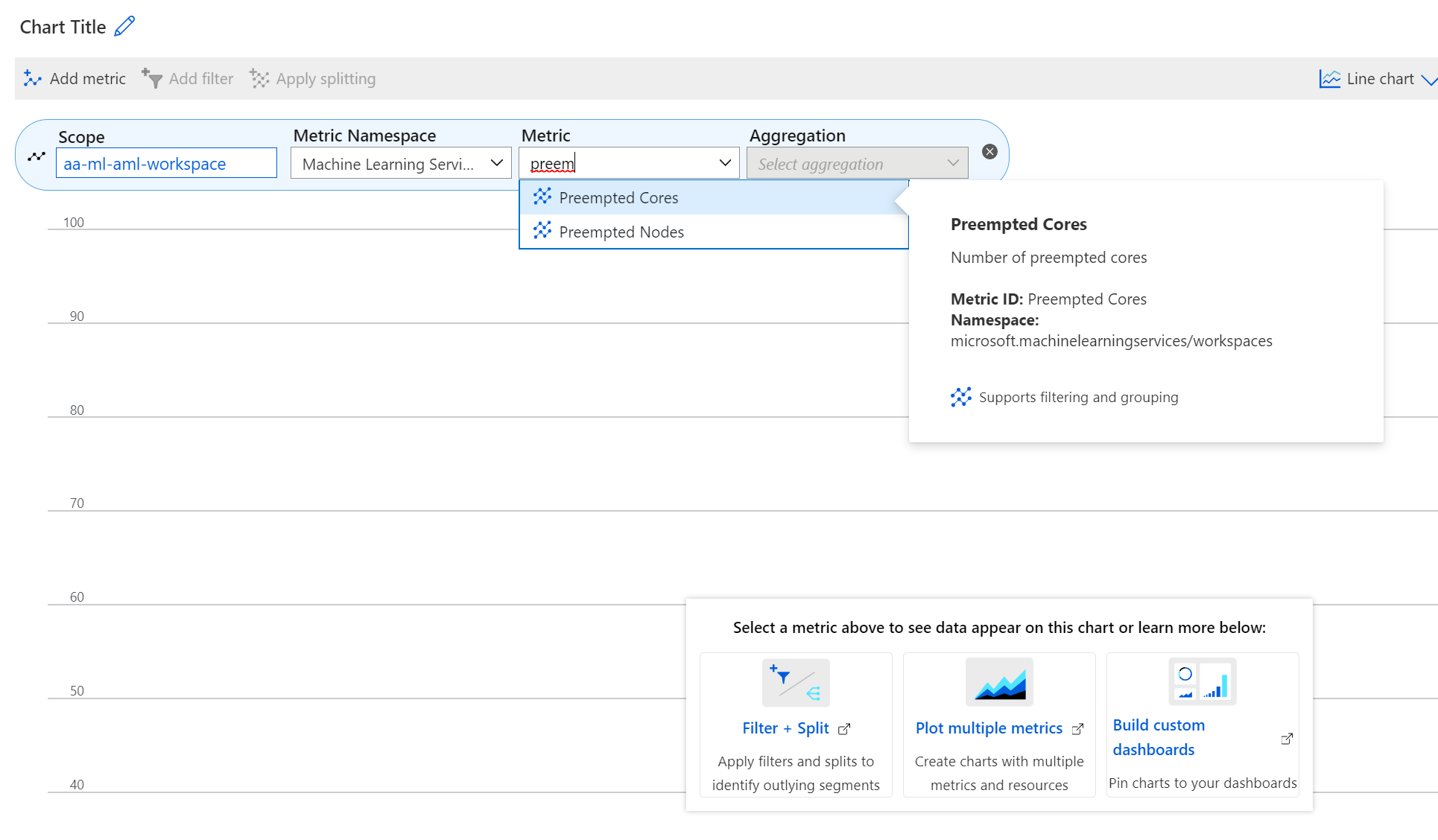
Existen nuevas métricas disponibles en Azure Portal para supervisar las máquinas virtuales de prioridad baja. Estas son las métricas:
- Nodos con prioridad
- Núcleos con prioridad
Para ver estas métricas en Azure Portal
- En Azure Portal, vaya al área de trabajo de Azure Machine Learning.
- Seleccione Métricas en la sección Supervisión.
- Seleccione las métricas que quiere en la lista Métricas.
Limitaciones
- Una vez que una implementación está asociada a un clúster de máquinas virtuales de prioridad baja, todos los trabajos generados por dicha implementación usarán máquinas virtuales de prioridad baja. La configuración por trabajo no es posible.
- La reprogramación se realiza en el nivel de lote pequeño, independientemente del progreso. No se proporciona ninguna capacidad de punto de comprobación.
Advertencia
En los casos en los que se adelante todo el clúster (o se ejecute en un clúster de un solo nodo), el trabajo se cancelará porque no hay capacidad disponible para que se ejecute. En este caso, volver a enviar el trabajo será obligatorio.