Administración de la sesión de proceso del flujo de avisos en Estudio de Azure Machine Learning
Una sesión de proceso del flujo de avisos proporciona recursos informáticos necesarios para que la aplicación se ejecute, incluida una imagen de Docker que contiene todos los paquetes de dependencia necesarios. Este entorno confiable y escalable permite al flujo de avisos ejecutar eficazmente sus tareas y funciones para brindar una experiencia fluida a los usuarios.
Permisos y roles para la administración de sesiones de proceso
Para asignar un rol, es necesario tener owner o disponer de permiso Microsoft.Authorization/roleAssignments/write sobre el recurso.
Para los usuarios de la sesión de proceso, asigne el rol AzureML Data Scientist en el área de trabajo. Para obtener más información, consulte Administración del acceso a un área de trabajo de Azure Machine Learning.
La asignación de roles puede tardar varios minutos en surtir efecto.
Inicio de una sesión de proceso en Studio
Antes de usar Estudio de Azure Machine Learning para iniciar una sesión de proceso, asegúrese de:
- Tener el rol
AzureML Data Scientisten el área de trabajo. - El almacén de datos predeterminado (por lo general,
workspaceblobstore) del área de trabajo es el tipo de blob. - El directorio de trabajo (
workspaceworkingdirectory) existe en el área de trabajo. - Si usa una red virtual para el flujo de avisos, comprende las consideraciones que se indican en Aislamiento de red en el flujo de avisos.
Iniciar una sesión de proceso en una página de flujo
Un flujo se enlaza a una sesión de proceso. Puede iniciar una sesión de proceso en una página de flujo.
Seleccione Iniciar. Inicie una sesión de proceso mediante el entorno definido en
flow.dag.yamlen la carpeta de flujo; se ejecuta en el tamaño de máquina virtual (VM) de proceso sin servidor que tiene suficiente cuota en el área de trabajo.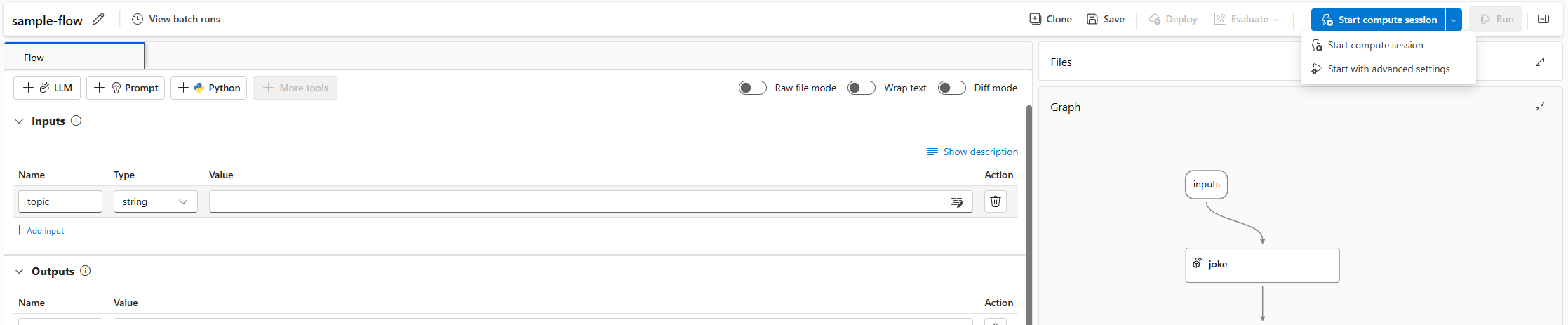
Seleccione Inicio con la configuración avanzada. En la configuración avanzada, puede:
- Seleccione el tipo de proceso. Puede elegir entre el proceso sin servidor y la instancia de proceso.
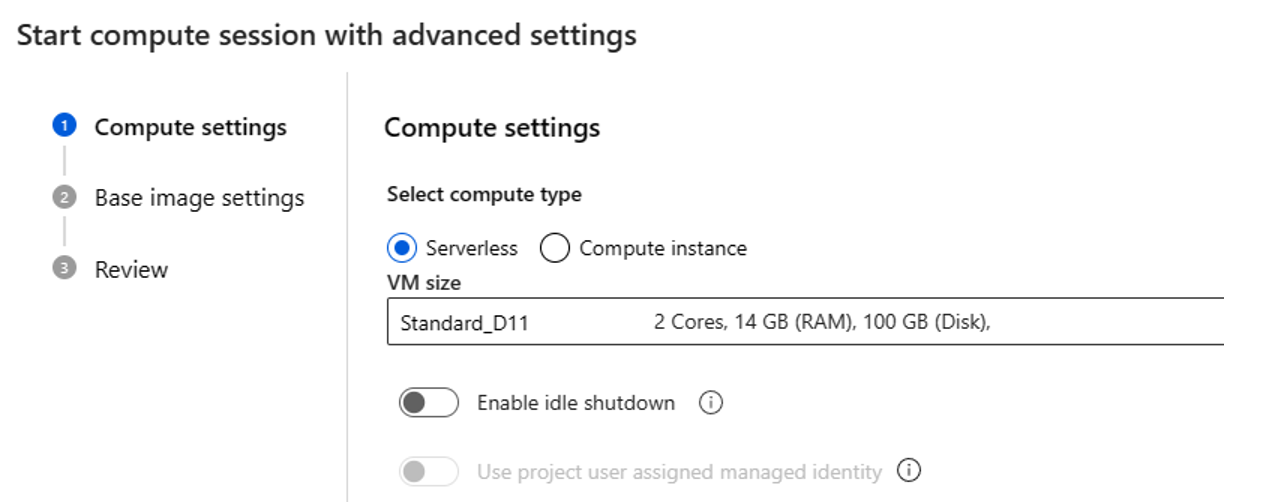
Si elige proceso sin servidor, puede establecer la siguiente configuración:
- Personalice el tamaño de máquina virtual que usa la sesión de proceso. Opte por la serie D de máquinas virtuales y versiones posteriores. Para más información, consulte la sección sobre Series y tamaños de máquina virtual compatibles
- Personalice el tiempo de inactividad, que elimina automáticamente la sesión de proceso si no está en uso durante un tiempo.
- Incorporar la identidad administrada asignada por el usuario. La sesión de proceso usa esta identidad para extraer una imagen base, autenticar con paquetes de conexión e instalación. Asegúrese de que la identidad administrada asignada por el usuario tenga permisos suficientes. Si no establece esta identidad, usamos la identidad de usuario de forma predeterminada.
- Puede usar el siguiente comando de la CLI para asignar la identidad administrada asignada por el usuario al área de trabajo. Obtenga más información sobre cómo crear y actualizar identidades asignadas por el usuario para un área de trabajo.
az ml workspace update -f workspace_update_with_multiple_UAIs.yml --subscription <subscription ID> --resource-group <resource group name> --name <workspace name>Donde el contenido de workspace_update_with_multiple_UAIs.yml es el siguiente:
identity: type: system_assigned, user_assigned user_assigned_identities: '/subscriptions/<subscription_id>/resourcegroups/<resource_group_name>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<uai_name>': {} '<UAI resource ID 2>': {}Sugerencia
Las siguientes asignaciones de roles RBAC de Azure son necesarias en la identidad administrada asignada por el usuario para que el área de trabajo de Azure Machine Learning acceda a los datos de los recursos asociados al área de trabajo.
Recurso Permiso Área de trabajo de Azure Machine Learning Colaborador Azure Storage Colaborador (plano de control) + Colaborador de datos de blobs de almacenamiento + Colaborador con privilegios de datos de archivos de almacenamiento (plano de datos, consumir borrador de flujo en el recurso compartido de archivos y los datos del blob) Azure Key Vault (al usar el modelo de permisos de directivas de acceso) Colaborador y cualquier permiso de directiva de acceso además de operaciones de purgar, es el modo predeterminado para Azure Key Vault vinculado. Azure Key Vault (al usar el modelo de permisos RBAC) Colaborador (plano de control) + administrador de Key Vault (plano de datos) Azure Container Registry Colaborador Azure Application Insights Colaborador Nota:
El remitente del trabajo necesita tener permiso
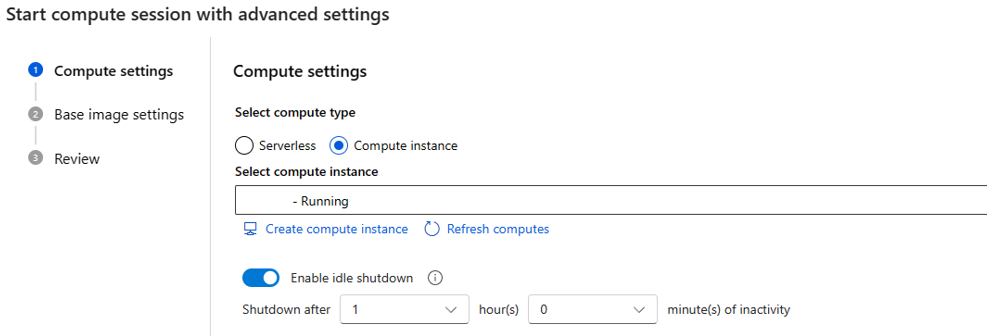
assignen la identidad administrada asignada por el usuario, puede asignar el rolManaged Identity Operator, ya que cada vez que crea una sesión de proceso sin servidor, asignará la identidad administrada asignada por el usuario al proceso.Si elige la instancia de proceso como tipo de proceso, solo puede establecer el tiempo de apagado de inactividad.
A medida que se ejecuta en una instancia de proceso existente, el tamaño de la máquina virtual es fijo y no puede cambiar en el lado de la sesión.
La identidad que se usa para esta sesión también se define en la instancia de proceso; de forma predeterminada usa la identidad del usuario. Obtenga más información sobre cómo asignar identidad a la instancia de proceso
Para el tiempo de apagado de inactividad que se usa para definir el ciclo de vida de la sesión de proceso, si la sesión está inactiva durante el tiempo establecido, se elimina automáticamente. Además, tiene habilitado el apagado inactivo en la instancia de proceso y, a continuación, surte efecto desde el nivel de proceso.
Obtenga más información sobre cómo crear y administrar instancias de proceso
- Seleccione el tipo de proceso. Puede elegir entre el proceso sin servidor y la instancia de proceso.



Uso de una sesión de proceso para enviar una ejecución de flujo en la CLI o el SDK
Además de Studio, también puede especificar la sesión de proceso en la CLI o el SDK al enviar una ejecución de flujo.
También puede especificar el tipo de instancia o el nombre de instancia de proceso en la parte del recurso. Si no especifica el tipo de instancia o el nombre de instancia de proceso, Azure Machine Learning elige un tipo de instancia (tamaño de máquina virtual) en función de factores como cuota, costo, rendimiento y tamaño de disco. Obtenga más información sobre Proceso sin servidor.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
# specify identity used by serverless compute.
# default value
# identity:
# type: user_identity
# use workspace first UAI
# identity:
# type: managed
# use specified client_id's UAI
# identity:
# type: managed
# client_id: xxx
column_mapping:
url: ${data.url}
# define cloud resource
resources:
instance_type: <instance_type> # serverless compute type
# compute: <compute_instance_name> # use compute instance as compute type
Envíe esta ejecución a través de la CLI:
pfazure run create --file run.yml
Nota:
El apagado inactivo es de una hora si usa la CLI o el SDK para enviar una ejecución de flujo. Puede ir a la página de proceso para liberar el proceso.
Archivos de referencia fuera de la carpeta de flujo
A veces, es posible que quiera hacer referencia a un archivo requirements.txt que está fuera de la carpeta de flujo. Por ejemplo, puede tener un proyecto complejo que incluya varios flujos y comparta el mismo archivo requirements.txt. Para ello, puede agregar este campo additional_includes al flow.dag.yaml. El valor de este campo es una lista de la ruta de acceso relativa de archivo o carpeta a la carpeta de flujo. Por ejemplo, si requirements.txt está en la carpeta primaria de la carpeta de flujo, puede agregar ../requirements.txt al campo additional_includes.
inputs:
question:
type: string
outputs:
output:
type: string
reference: ${answer_the_question_with_context.output}
environment:
python_requirements_txt: requirements.txt
additional_includes:
- ../requirements.txt
...
El archivo requirements.txt se copia en la carpeta de flujo y se usa para iniciar la sesión de proceso.
Actualización de una sesión de proceso en la página de flujo de Studio
En una página de flujo, puede usar las siguientes opciones para administrar una sesión de proceso:
- Cambiar la configuración de la sesión de proceso, se cambia la configuración de proceso, como el tamaño de máquina virtual y la identidad administrada asignada por el usuario para el proceso sin servidor; si usa la instancia de proceso, puede cambiar para usar otra instancia. También puede cambiar
- también puede cambiar la identidad administrada asignada por el usuario para el proceso sin servidor. Si cambia el tamaño de la máquina virtual, la sesión de proceso se restablece con el nuevo tamaño de máquina virtual. Si está
- Instalar paquetes desde requirements.txt Abre
requirements.txten la interfaz de usuario del flujo de avisos; puede agregar paquetes en él. - Ver paquetes instalados muestra los paquetes instalados en la sesión de proceso. Incluye los paquetes que se instalan en la imagen base y los paquetes especifican en el archivo
requirements.txtde la carpeta de flujo. - Restablecer sesión de proceso elimina la sesión de proceso actual y crea una nueva con el mismo entorno. Si encuentra un problema de conflicto de paquetes, puede probar esta opción.
- Detener sesión de proceso elimina la sesión de proceso actual. Si no hay ninguna sesión de proceso activa en el proceso subyacente, también se eliminará el recurso de proceso sin servidor.

También puede personalizar el entorno que usa para ejecutar este flujo agregando paquetes en el archivo requirements.txt de la carpeta de flujo. Después de agregar más paquetes en este archivo, puede elegir cualquiera de estas opciones:
- Guardar e instalar desencadena
pip install -r requirements.txten la carpeta de flujo. El proceso puede tardar unos minutos, en función de los paquetes que instale. - Guardar solo guarda el archivo
requirements.txt. Puede instalar los paquetes más adelante.

Nota:
Puede cambiar la ubicación e incluso el nombre de archivo de requirements.txt, pero asegúrese de cambiarlo también en el archivo de la flow.dag.yaml carpeta de flujo.
No ancle la versión de promptflow y promptflow-tools en requirements.txt, porque ya las incluimos en la imagen base de sesión.
requirements.txt no admitirá archivos de rueda local. Compilarlos en la imagen y actualizar la imagen base personalizada en flow.dag.yaml. Obtenga más información sobre cómo crear una imagen base personalizada.
Adición de paquetes en una fuente privada en Azure DevOps
Si quiere usar una fuente privada en Azure DevOps, siga estos pasos:
Asigne una identidad administrada al área de trabajo o a la instancia de proceso.
Use el proceso sin servidor como sesión de proceso; debe asignar la identidad administrada asignada por el usuario al área de trabajo.
Cree una identidad administrada asignada por el usuario y agregue esta identidad en la organización de Azure DevOps. Para más información, vea Uso de entidades de servicio e identidades administradas.
Nota:
Si el botón Agregar usuarios no está visible, probablemente no tenga los permisos necesarios para realizar esta acción.
Agregue o actualice las identidades asignadas por el usuario al área de trabajo.
Nota:
Asegúrese de que la identidad administrada asignada por el usuario tiene
Microsoft.KeyVault/vaults/readen el almacén de claves vinculado del área de trabajo.
Use la instancia de proceso como sesión de proceso; necesita asignar una identidad administrada asignada por el usuario a una instancia de proceso.
Agregue
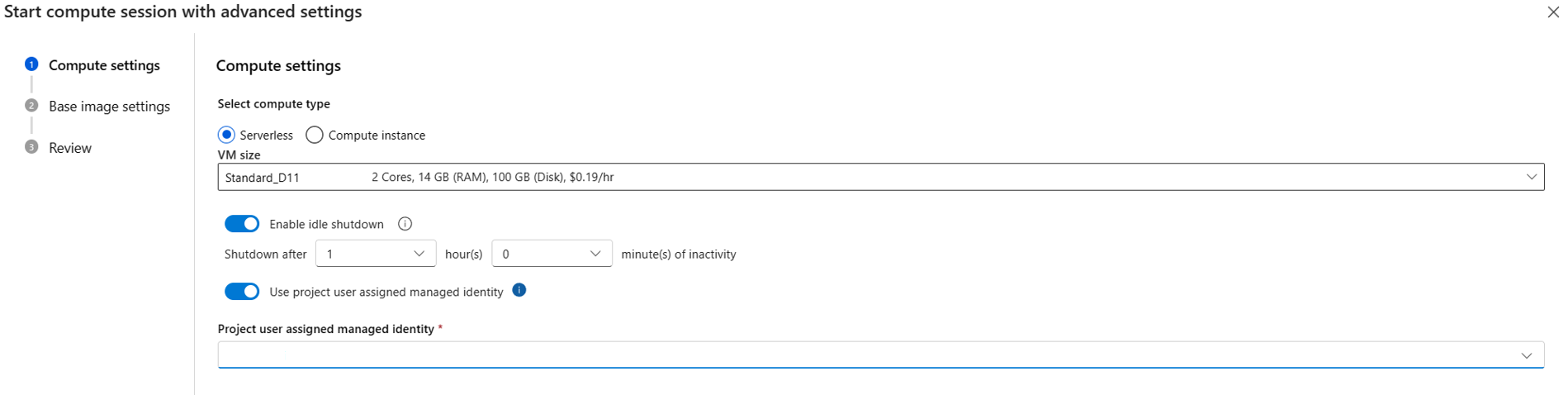
{private}a la dirección URL de la fuente privada. Por ejemplo, si quiere instalartest_packagedesdetest_feeden Azure DevOps, agregue-i https://{private}@{test_feed_url_in_azure_devops}enrequirements.txt:-i https://{private}@{test_feed_url_in_azure_devops} test_packageEspecifique el uso de la identidad administrada asignada por el usuario en la configuración de la sesión de proceso.
Si usa proceso sin servidor, especifique la identidad administrada asignada por el usuario en Inicio con la configuración avanzada si la sesión de proceso no se está ejecutando o use el botón Cambiar configuración de sesión de proceso si se está ejecutando la sesión de proceso.
Si usa la instancia de proceso, se usa la identidad administrada asignada por el usuario que asignó a la instancia de proceso.

Nota:
Este enfoque se centra principalmente en las pruebas rápidas en la fase de desarrollo de flujo, si también desea implementar este flujo como punto de conexión, cree esta fuente privada en la imagen y actualice la personalización de la imagen base en flow.dag.yaml. Obtenga más información sobre cómo crear una imagen base personalizada
Cambio de la imagen base para la sesión de proceso
De forma predeterminada, usamos la imagen base del flujo de avisos más reciente. Si desea usar otra imagen base, puede crear una personalizada.
- En Studio, puede cambiar la imagen base en la configuración de la imagen base en configuración de sesión de proceso.

También puede especificar la nueva imagen base en
environmenten el archivoflow.dag.yamlde la carpeta de flujo.
environment: image: <your-custom-image> python_requirements_txt: requirements.txt

Para usar la nueva imagen base, debe restablecer la sesión de proceso. Este proceso tarda varios minutos a medida que extrae la nueva imagen base y vuelve a instalar los paquetes.
Administración de instancias sin servidor usadas por la sesión de proceso
Cuando se usa el proceso sin servidor como una sesión de proceso, puede administrar la instancia sin servidor. Vea la instancia sin servidor en la pestaña lista de sesiones de proceso en la página de proceso.

También puede acceder a los flujos y ejecuciones que se ejecutan en el proceso en la pestaña Activar y ejecutar flujos. Al eliminar la instancia, se afecta el flujo y las ejecuciones en ella.

Relación entre la sesión de proceso, el recurso de proceso, el flujo y el usuario
- Un solo usuario puede tener varios recursos de proceso (instancia sin servidor o de proceso). Debido a diferentes necesidades, un único usuario puede tener varios recursos de proceso. Por ejemplo, un usuario puede tener varios recursos de proceso con un tamaño de máquina virtual diferente o una identidad administrada asignada por el usuario diferente.
- Un mismo usuario solo puede usar un recurso de proceso. Un recurso de proceso se usa como cuadro de desarrollo privado de un solo usuario. Varios usuarios no pueden compartir los mismos recursos de proceso.
- Un recurso de proceso puede hospedar varias sesiones de proceso. Una sesión de proceso es un contenedor que se ejecuta en un recurso de proceso subyacente. Por ejemplo, la creación del flujo de avisos no necesita demasiados recursos de proceso, por lo que un único recurso de proceso puede hospedar varias sesiones de proceso desde el mismo usuario.
- Una sesión de proceso solo pertenece a un único recurso de proceso a la vez. Pero puede eliminar o detener una sesión de proceso y reasignarla a otro recurso de proceso.
- Un flujo solo puede tener una sesión de proceso. Cada flujo es independiente y define la imagen base y los paquetes de Python necesarios en la carpeta de flujo para la sesión de proceso.
Cambio del entorno de ejecución a la sesión de proceso
Las sesiones de proceso tienen las siguientes ventajas sobre los entornos de ejecución de la instancia de proceso:
- Administrar automáticamente el ciclo de vida de la sesión y el proceso subyacente. Ya no es necesario crearlos y administrarlos manualmente.
- Personalice fácilmente los paquetes agregando paquetes en el archivo
requirements.txtde la carpeta de flujos, en lugar de crear un entorno personalizado.
Cambie un entorno de ejecución de instancia de proceso a una sesión de proceso mediante los pasos siguientes:
- Prepare el archivo
requirements.txtde la carpeta de flujos. Asegúrese de no anclar la versión depromptflowypromptflow-toolsenrequirements.txt, ya que ya las incluimos en la imagen base. La sesión de proceso instala los paquetes en el archivorequirements.txtcuando se inicia. - Si crea un entorno personalizado para crear un entorno de ejecución de instancia de proceso, puede obtener la imagen de la página de detalles del entorno y especificarla en el archivo
flow.dag.yamlde la carpeta de flujo. Para obtener más información, consulte Cambio de la imagen base para la sesión de proceso. Asegúrese de que usted o la identidad administrada asignada por el usuario relacionado en el área de trabajo tiene permiso deacr pullpara la imagen.

- Para el recurso de proceso, puede seguir usando la instancia de proceso existente si desea administrar manualmente el ciclo de vida o puede probar el proceso sin servidor cuyo ciclo de vida está administrado por el sistema.