DevOps para una canalización de ingesta de datos
En la mayoría de los escenarios, una solución de ingesta de datos es una composición de scripts e invocaciones de servicio, junto con una canalización que organiza todas las actividades. En este artículo, obtendrá información sobre cómo aplicar procedimientos de DevOps al ciclo de vida de desarrollo de una canalización de ingesta de datos común que prepare los datos para el entrenamiento de un modelo de Machine Learning. La canalización se crea con los siguientes servicios de Azure:
- Azure Data Factory: Lee los datos sin procesar y organiza la preparación de datos.
- Azure Databricks: Ejecuta un cuaderno de Python que transforma los datos.
- Azure Pipelines: Automatiza un proceso de desarrollo e integración continua.
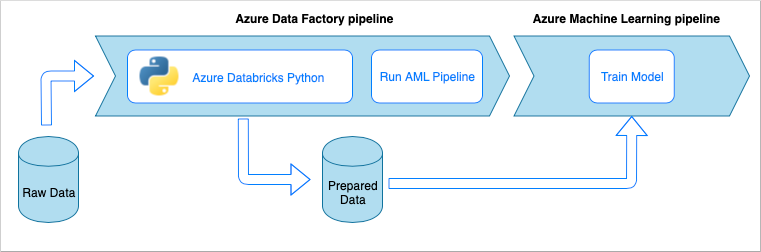
Flujo de una canalización de ingesta de datos
La canalización de ingesta de datos implementa el siguiente flujo de trabajo:
- Una canalización de Azure Data Factory (ADF) lee los datos sin procesar.
- La canalización de ADF envía los datos a un clúster de Azure Databricks, que ejecuta un cuaderno de Python para transformar los datos.
- Los datos se almacenan en un contenedor de blobs, en el que se puede usar Azure Machine Learning para entrenar un modelo.
Información general de integración y entrega continuas
Al igual que sucede con muchas soluciones de software, hay un equipo (por ejemplo, ingenieros de datos) que trabaja en ello. Sus miembros colaboran y comparten los mismos recursos de Azure, como cuentas de Azure Data Factory, Azure Databricks y Azure Storage. La colección de estos recursos es un entorno de desarrollo. Los ingenieros de datos contribuyen a la misma base de código fuente.
Un sistema de integración y entrega continuas automatiza el proceso de creación, prueba y entrega (implementación) de la solución. El proceso de integración continua (CI) realiza las siguientes tareas:
- Ensambla el código
- Lo comprueba con las pruebas de calidad del código
- Ejecuta pruebas unitarias
- Genera artefactos, como código probado y plantillas de Azure Resource Manager
El proceso de entrega continua (CD) implementa los artefactos en los entornos de bajada.
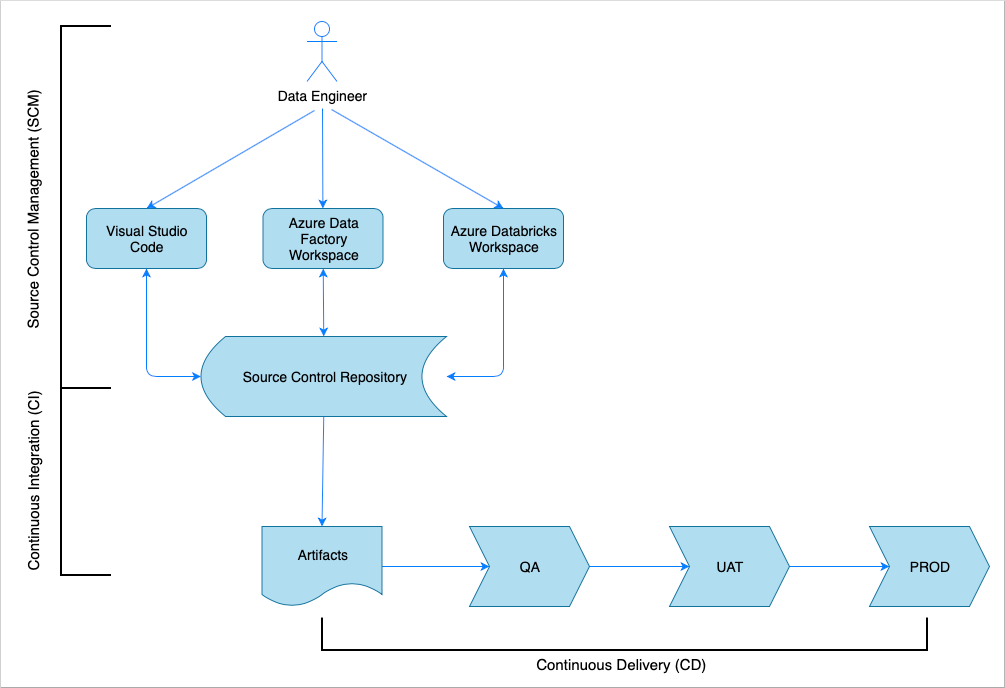
En este artículo se muestra cómo automatizar los procesos de CI y CD con Azure Pipelines.
Administración del control de código fuente
La administración del control de código fuente es necesaria para realizar un seguimiento de los cambios y permitir la colaboración entre los miembros del equipo. Por ejemplo, el código se almacenaría en un repositorio de Azure DevOps, GitHub o GitLab. El flujo de trabajo de colaboración está basado en un modelo de ramificación. Por ejemplo, GitFlow.
Código fuente del cuaderno de Python
Los ingenieros de datos trabajan con el código fuente del cuaderno de Python bien de forma local en un IDE (por ejemplo, Visual Studio Code) o directamente en el área de trabajo de Databricks. Una vez completados los cambios del código, se fusionan mediante combinación siguiendo una directiva de ramificación.
Sugerencia
Se recomienda almacenar el código en archivos .py en lugar de .ipynb, que es el formato de Jupyter Notebook. El motivo es que la legibilidad del código mejora y permite comprobaciones automáticas de calidad del código en el proceso de CI.
Código fuente de Azure Data Factory
El código fuente de las canalizaciones de Azure Data Factory es una colección de archivos JSON que genera un área de trabajo de Azure Data Factory. Normalmente, los ingenieros de datos trabajan con un diseñador visual en el área de trabajo de Azure Data Factory en lugar de con los archivos de código fuente directamente.
Si quiere configurar el área de trabajo para usar un repositorio de control de código fuente, consulte Creación con la integración de Git de Azure Repos.
Integración continua (CI)
El objetivo final del proceso de integración continua es recopilar del código fuente el trabajo conjunto del equipo y prepararlo para la implementación en los entornos de bajada. Al igual que sucede con la administración del código fuente, este proceso es diferente para los cuadernos de Python y las canalizaciones de Azure Data Factory.
CI de cuadernos de Python
El proceso de CI en los cuadernos de Python obtiene el código de la rama de colaboración (por ejemplo, master o develop) y realiza las siguientes actividades:
- Búsqueda de errores en el código
- Pruebas unitarias
- Guardar el código como un artefacto
El siguiente fragmento de código muestra la implementación de estos pasos en una canalización yaml de Azure DevOps:
steps:
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
- publish: $(Build.SourcesDirectory)
artifact: di-notebooks
La canalización usa flake8 para realizar la búsqueda de errores en el código de Python. Se ejecutan las pruebas unitarias definidas en el código fuente y se publican los resultados de las pruebas y la búsqueda de errores para que estén disponibles en la pantalla de ejecución de la canalización de Azure.
Si las pruebas unitarias y la búsqueda de errores se realizan correctamente, la canalización copia el código fuente en el repositorio de artefactos para usarlo en los pasos posteriores de implementación.
CI de Azure Data Factory
El proceso de CI para una canalización Azure Data Factory es un cuello de botella para una canalización de ingesta de datos. No hay integración continua. Un artefacto implementable para Azure Data Factory es una colección de plantillas de Azure Resource Manager. La única manera de generar esas plantillas es hacer clic en el botón publicar en el área de trabajo de Azure Data Factory.
- Los ingenieros de datos combinan el código fuente de sus ramas de características en la rama de colaboración, por ejemplo, master o develop.
- Un usuario al que se le han concedido los permisos hace clic en el botón publicar para generar plantillas de Azure Resource Manager a partir del código fuente de la rama de colaboración.
- El área de trabajo valida las canalizaciones (es decir, se realiza el linting y las pruebas unitarias), genera plantillas de Azure Resource Manager (es decir, se realiza la compilación) y guarda las plantillas generadas en una rama técnica adf_publish en el mismo repositorio de código (es decir, se publican los artefactos). Esta rama se crea automáticamente en el área de trabajo de Azure Data Factory.
Para obtener más información sobre este proceso, consulte Integración y entrega continuas en Azure Data Factory.
Es importante asegurarse de que las plantillas de Azure Resource Manager generadas sean independientes del entorno. Esto significa que todos los valores que puedan diferir entre entornos se parametrizan. Azure Data Factory es lo suficientemente inteligente como para exponer la mayoría de estos valores como parámetros. Por ejemplo, en la siguiente plantilla las propiedades de conexión a un área de trabajo de Azure Machine Learning se exponen como parámetros:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
"AzureMLService_servicePrincipalKey": {
"value": ""
},
"AzureMLService_properties_typeProperties_subscriptionId": {
"value": "0fe1c235-5cfa-4152-17d7-5dff45a8d4ba"
},
"AzureMLService_properties_typeProperties_resourceGroupName": {
"value": "devops-ds-rg"
},
"AzureMLService_properties_typeProperties_servicePrincipalId": {
"value": "6e35e589-3b22-4edb-89d0-2ab7fc08d488"
},
"AzureMLService_properties_typeProperties_tenant": {
"value": "72f988bf-86f1-41af-912b-2d7cd611db47"
}
}
}
Sin embargo, querrá exponer las propiedades personalizadas que no se administran de forma predeterminada en el área de trabajo de Azure Data Factory. En el escenario de este artículo, una canalización de Azure Data Factory invoca un cuaderno de Python que procesa los datos. El cuaderno acepta un parámetro con el nombre de un archivo de datos de entrada.
import pandas as pd
import numpy as np
data_file_name = getArgument("data_file_name")
data = pd.read_csv(data_file_name)
labels = np.array(data['target'])
...
Este nombre es diferente para los entornos Dev, QA, UAT y PROD. En una canalización compleja con varias actividades, puede haber varias propiedades personalizadas. Es recomendable recopilar todos esos valores en un solo lugar y definirlos como variables de canalización:
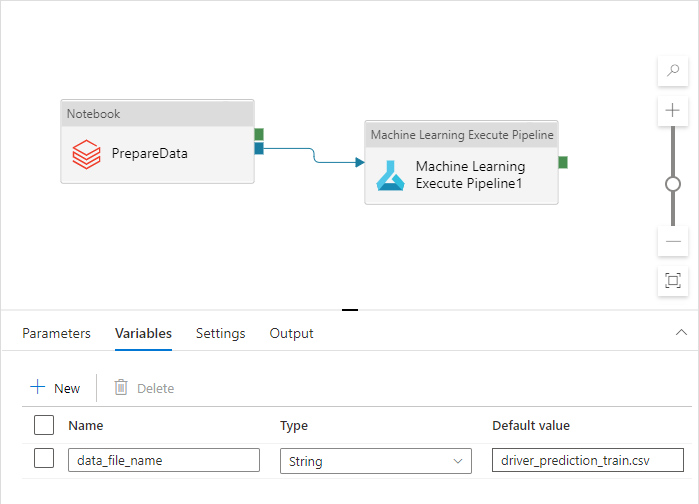
Las actividades de canalización pueden hacer referencia a las variables de canalización mientras se usan realmente:
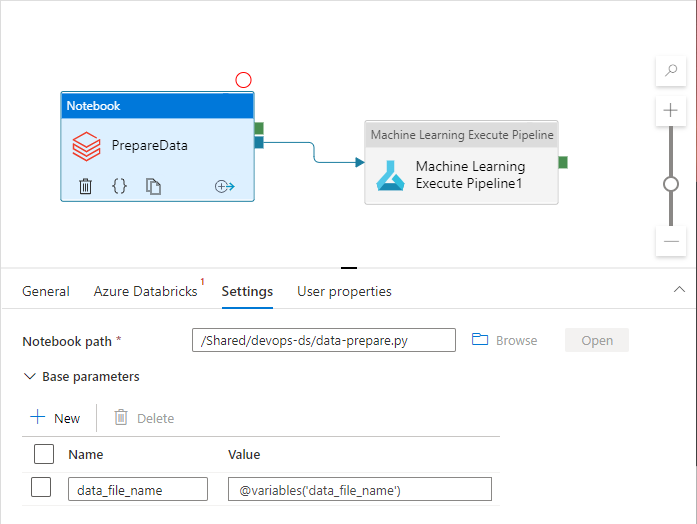
El área de trabajo de Azure Data Factory no expone variables de canalización como parámetros de plantilla de Azure Resource Manager de forma predeterminada. El área de trabajo usa la plantilla de parametrización predeterminada que dictamina qué propiedades de canalización deben exponerse como parámetros de plantilla de Azure Resource Manager. Para agregar variables de canalización a la lista, actualice la sección "Microsoft.DataFactory/factories/pipelines" de la plantilla de parametrización predeterminada con el siguiente fragmento de código y coloque el archivo JSON resultante en la raíz de la carpeta de origen:
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"variables": {
"*": {
"defaultValue": "="
}
}
}
}
Al hacerlo, se fuerza el área de trabajo de Azure Data Factory a que agregue las variables a la lista de parámetros cuando se hace clic en el botón publicar:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
...
"data-ingestion-pipeline_properties_variables_data_file_name_defaultValue": {
"value": "driver_prediction_train.csv"
}
}
}
Los valores del archivo JSON son valores predeterminados configurados en la definición de la canalización. Se espera que se reemplacen por los valores de entorno de destino cuando se implemente la plantilla de Azure Resource Manager.
Entrega continua (CD)
El proceso de entrega continua toma los artefactos y los implementa en el primer entorno de destino. Para garantizar que la solución funcione, se ejecutan pruebas. Si se superan, se pasa al entorno siguiente.
La canalización de Azure Pipelines de CD consta de varias fases que representan los entornos. Cada fase contiene implementaciones y trabajos que realizan los siguientes pasos:
- Implementación de un cuaderno de Python en un área de trabajo de Azure Databricks
- Implementación de una canalización de Azure Data Factory
- Ejecución de la canalización
- Comprobación del resultado de la ingesta de datos
Las fases de canalización se pueden configurar con aprobaciones y puertas que ofrecen control adicional sobre cómo evoluciona el proceso de implementación a través de la cadena de entornos.
Implementación de un cuaderno de Python
El siguiente fragmento de código define una implementación de canalización de Azure que copia un cuaderno de Python en un clúster de Databricks:
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
Los artefactos generados en el proceso de CI se copian automáticamente en el agente de implementación y están disponibles en la carpeta $(Pipeline.Workspace). En este caso, la tarea de implementación hace referencia al artefacto di-notebooks que contiene el cuaderno de Python. Esta implementación usa la extensión de Azure DevOps para Databricks para copiar los archivos de cuaderno en el área de trabajo de Databricks.
La fase Deploy_to_QA contiene una referencia al grupo de variables devops-ds-qa-vg definido en el proyecto de Azure DevOps. Los pasos de esta fase hacen referencia a las variables de este grupo de variables (por ejemplo, $(DATABRICKS_URL) y $(DATABRICKS_TOKEN)). La idea es que la siguiente fase (por ejemplo, Deploy_to_UAT) funcione con los mismos nombres de variable definidos en su propio grupo de variables con ámbito de UAT.
Implementación de una canalización de Azure Data Factory
Un artefacto implementable para Azure Data Factory es una plantilla de Azure Resource Manager. Se implementará con la tarea Implementación del grupo de recursos de Azure, como se muestra en el siguiente fragmento de código:
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
El valor del parámetro de nombre de archivo de datos procede de la variable $(DATA_FILE_NAME) definida en un grupo de variables de la fase QA. Del mismo modo, todos los parámetros definidos en ARMTemplateForFactory.json se pueden reemplazar. En caso contrario, se usan los valores predeterminados.
Ejecución de la canalización y comprobación del resultado de la ingesta de datos
El siguiente paso consiste en asegurarse de que la solución implementada funciona. La siguiente definición de trabajo ejecuta una canalización de Azure Data Factory con un script de PowerShell y ejecuta un cuaderno de Python en un clúster de Azure Databricks. El cuaderno comprueba si los datos se han ingerido correctamente y valida el archivo de datos de resultados con el nombre $(bin_FILE_NAME).
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'
La tarea final del trabajo comprueba el resultado de la ejecución del cuaderno. Si se devuelve un error, se establece el estado de ejecución de la canalización como erróneo.
Conclusión
La canalización de Azure de CI/CD consta de las siguientes fases:
- CI
- Implementar en QA
- Implementar en Databricks + implementar en ADF
- Prueba de integración
Contiene una serie de fases de implementación igual al número de entornos de destino que tiene. Cada fase de implementación contiene dos implementaciones que se ejecutan en paralelo y un trabajo que se ejecuta después de las implementaciones para probar la solución en el entorno.
Una implementación de ejemplo de la canalización se ensambla en el siguiente fragmento de código yaml:
variables:
- group: devops-ds-vg
stages:
- stage: 'CI'
displayName: 'CI'
jobs:
- job: "CI_Job"
displayName: "CI Job"
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- script: pip install --upgrade flake8 flake8_formatter_junit_xml
displayName: 'Install flake8'
- checkout: self
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
# The CI stage produces two artifacts (notebooks and ADF pipelines).
# The pipelines Azure Resource Manager templates are stored in a technical branch "adf_publish"
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/code/dataingestion
artifact: di-notebooks
- checkout: git://${{variables['System.TeamProject']}}@adf_publish
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/devops-ds-adf
artifact: adf-pipelines
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'