Control de versiones y seguimiento de conjuntos de datos de Azure Machine Learning
SE APLICA A: Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
En este artículo, aprenderá a controlar versiones y realizar un seguimiento de los conjuntos de datos de Azure Machine Learning para fines de reproducibilidad. El control de versiones del conjunto de datos es una manera de delimitar el estado de los datos, con el fin de que pueda aplicar una versión específica del conjunto de datos para futuros experimentos.
Escenarios de control de versiones típicos:
- Cuando hay nuevos datos disponibles para el reentrenamiento
- Cuando se aplican diferentes enfoques de preparación de datos o de ingeniería de características
Prerrequisitos
En este tutorial, necesitará:
El SDK de Azure Machine Learning para Python instalado. Este SDK incluye el paquete de azureml-datasets.
Un área de trabajo de Azure Machine Learning. Para recuperar una existente, ejecute el código siguiente o cree una nueva área de trabajo.
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Registrar y recuperar versiones del conjunto de datos
Al registrar un conjunto de datos, puede mejorar su versión, volver a utilizarlo y compartirlo entre experimentos y con colegas. Puede registrar varios conjuntos de datos con el mismo nombre y recuperar una versión específica por nombre y número de versión.
Registrar una versión del conjunto de datos
El código siguiente registra una nueva versión del conjunto de datos titanic_ds estableciendo el parámetro create_new_version en True. Si no hay ningún conjunto de datos de titanic_ds existente registrado en el área de trabajo, el código crea un nuevo conjunto de datos con el nombre titanic_ds y establece su versión en 1.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Recuperar un conjunto de datos por nombre
De manera predeterminada, el método get_by_name() de la clase Dataset devuelve la versión más reciente del conjunto de datos registrada en el área de trabajo.
El código siguiente obtiene la versión 1 del conjunto de datos titanic_ds.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Procedimientos recomendados de control de versiones
Cuando crea una versión de conjunto de datos, no está creando una copia adicional de datos con el área de trabajo. Dado que los conjuntos de datos son referencias a los datos en el servicio de almacenamiento, tiene una única fuente verdadera, administrada por el servicio de almacenamiento.
Importante
Si se sobrescriben o se eliminan los datos a los que hace referencia el conjunto de datos, la llamada a una versión específica del conjunto de datos no revierte el cambio.
Cuando se cargan datos de un conjunto de datos, siempre se carga el contenido de datos actual al que hace referencia el conjunto de datos. Si quiere asegurarse de que cada versión del conjunto de datos se puede reproducir, se recomienda no modificar el contenido de datos al que hace referencia la versión del conjunto de datos. Cuando lleguen nuevos datos, guarde los nuevos archivos de datos en una carpeta de datos independiente y, después, cree una nueva versión del conjunto de datos para incluir los datos de esa nueva carpeta.
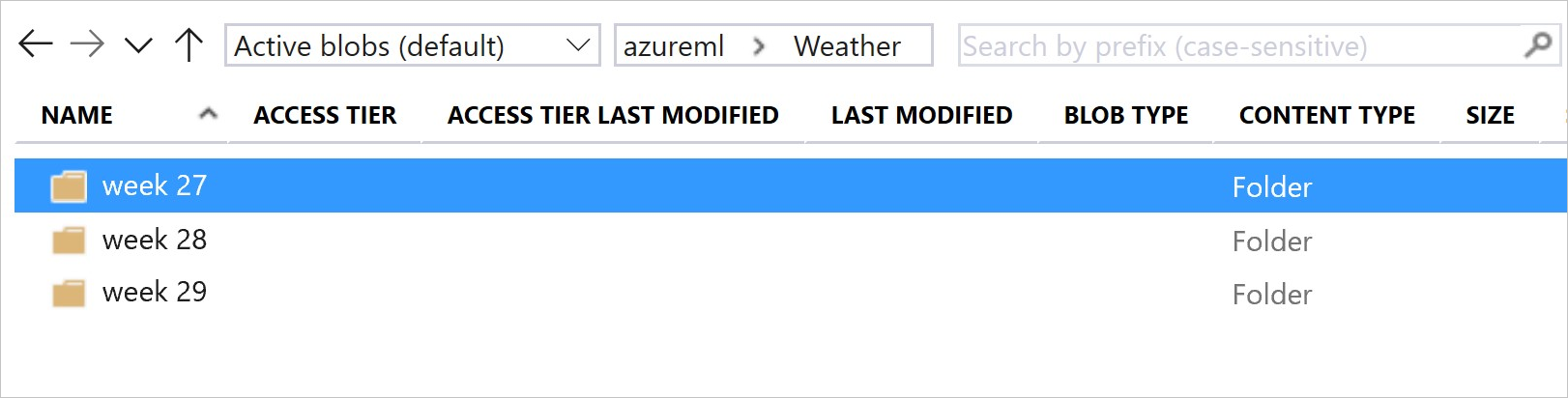
En la siguiente imagen y código de ejemplo se muestra el método recomendado para estructurar las carpetas de datos y crear versiones del conjunto de datos que hacen referencia a esas carpetas:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Control de versiones de un conjunto de datos de salida de canalización de ML
Puede usar un conjunto de datos como entrada y salida de cada paso de canalización de ML. Al volver a ejecutar las canalizaciones, la salida de cada paso de la canalización se registra como una nueva versión del conjunto de datos.
Las canalizaciones de ML rellenan la salida de cada paso en una nueva carpeta cada vez que se vuelve a ejecutar la canalización. Este comportamiento permite que los conjuntos de datos de salida con versión sean reproducibles. Más información sobre los conjuntos de datos en canalizaciones.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Seguimiento de los datos de los experimentos
Azure Machine Learning realiza un seguimiento de los datos a lo largo del experimento como conjuntos de datos de entrada y salida.
Estos son los escenarios en los que se realiza un seguimiento de los datos como conjunto de datos de entrada.
Como objeto
DatasetConsumptionConfigmediante el parámetroinputsoargumentsdel objetoScriptRunConfigal enviar el trabajo del experimento.Cuando se llama a métodos, como, get_by_name () o get_by_id (), en el script. En este escenario, el nombre que se asigna al conjunto de datos al registrarlo en el área de trabajo es el nombre que se muestra.
Estos son los escenarios en los que se realiza un seguimiento de los datos como conjunto de datos de salida.
Pasar un objeto
OutputFileDatasetConfigmediante el parámetrooutputso el parámetroargumentsal enviar un trabajo del experimento. Los objetosOutputFileDatasetConfigtambién se pueden usar para conservar los datos entre los pasos de una canalización. Consulte Movimiento de datos entre los pasos de canalización de ML.Registrar un conjunto de datos en el script. En este escenario, el nombre que se asigna al conjunto de datos al registrarlo en el área de trabajo es el nombre que se muestra. En el ejemplo siguiente,
training_dses el nombre que se mostraría.training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Enviar un trabajo secundario con un conjunto de datos no registrado en el script. El resultado es un conjunto de datos guardado anónimo.
Seguimiento de conjuntos de datos en trabajos de experimentos
Para cada experimento de Machine Learning, puede realizar fácilmente el seguimiento de los conjuntos de datos que se usan como entrada con el objeto Job del experimento.
El código siguiente usa el método get_details() para realizar un seguimiento de los conjuntos de datos de entrada que se utilizaron en la ejecución del experimento:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
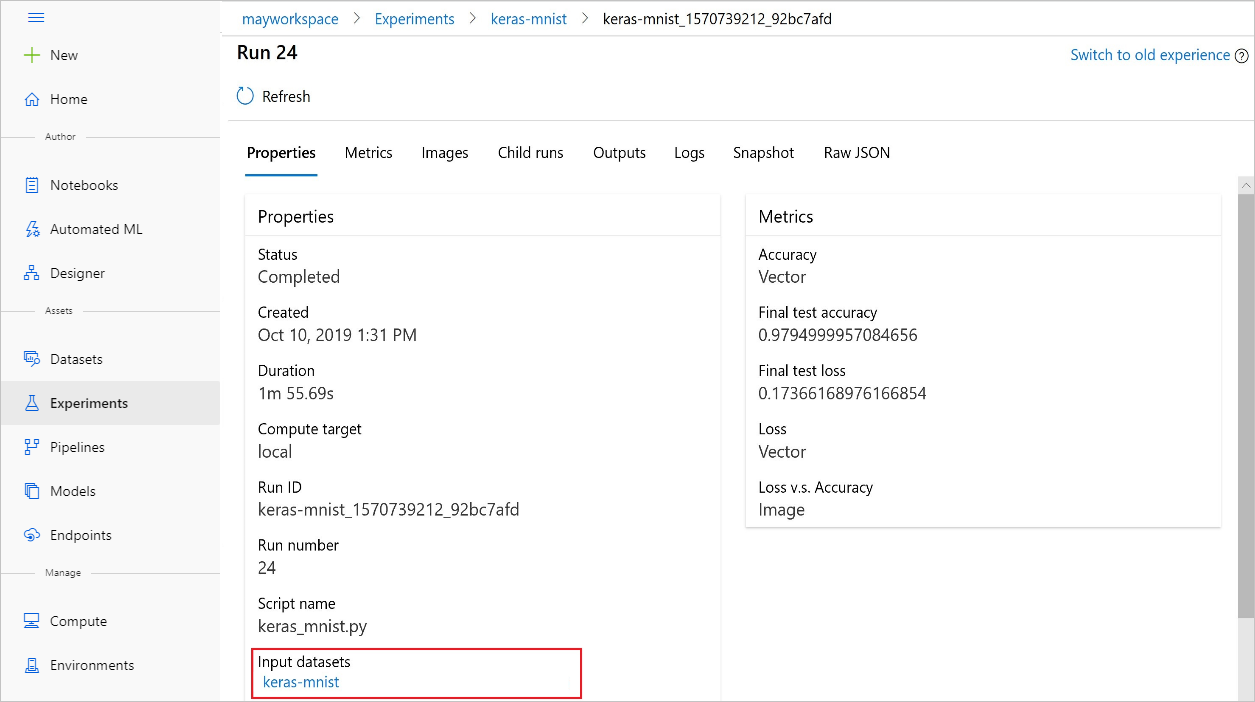
También puede encontrar los elementos input_datasets de los experimentos con Azure Machine Learning Studio.
En la imagen siguiente se muestra dónde encontrar el conjunto de datos de entrada de un experimento en Azure Machine Learning Studio. En este ejemplo, vaya al panel Experimentos y abra la pestaña Propiedades para una ejecución concreta del experimento, keras-mnist.
Use el código siguiente para registrar modelos con conjuntos de datos:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
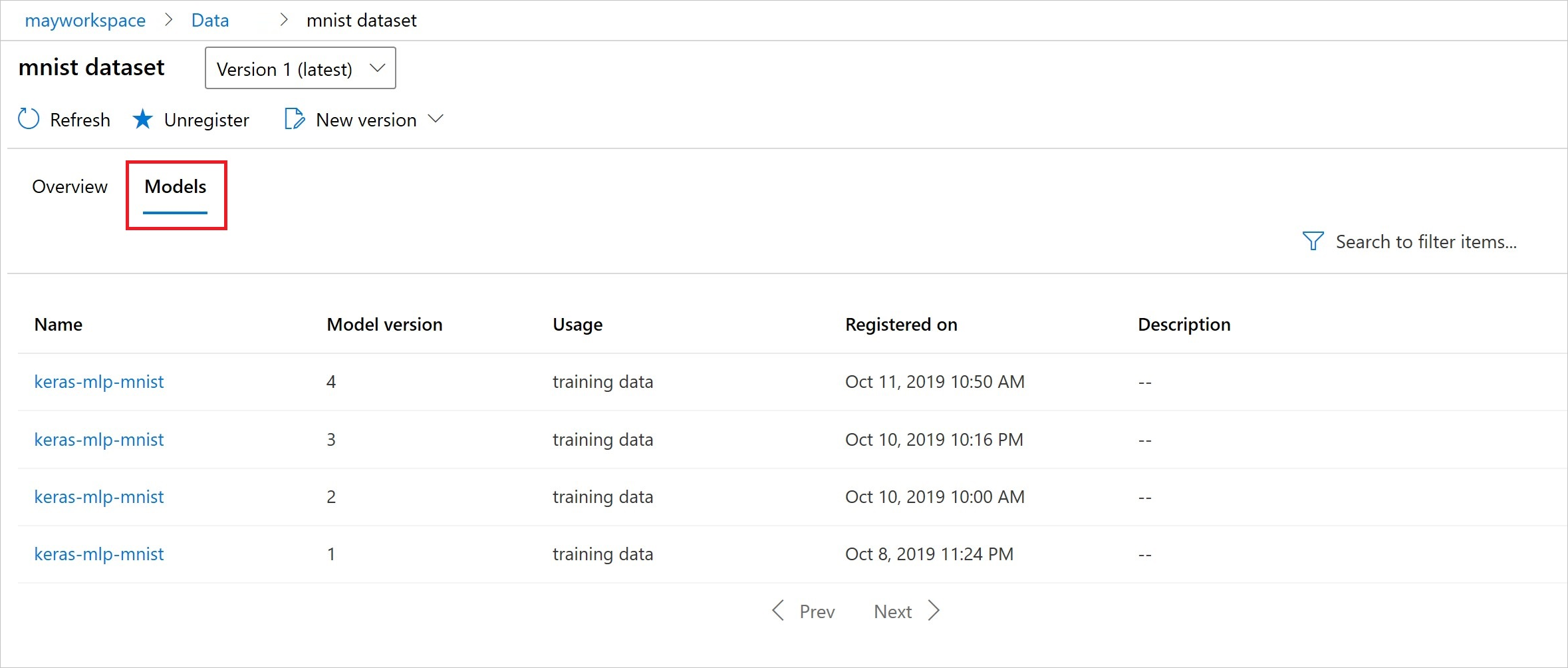
Después del registro, puede ver la lista de modelos registrados con el conjunto de datos mediante Python o ir a Studio.
La siguiente vista es del panel Conjunto de datos en Activos. Seleccione el conjunto de datos y, después, seleccione la pestaña Modelos para obtener una lista de modelos registrados el conjunto de datos.