Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Siempre que sea posible, se recomienda usar la replicación nativa de Apache Cassandra para migrar datos del clúster existente a Azure Managed Instance for Apache Cassandra mediante la configuración de un clúster híbrido. Este enfoque usará el protocolo de Gossip de Apache Cassandra para replicar datos del centro de datos de origen en el nuevo centro de datos de la instancia administrada. Sin embargo, puede haber algunos escenarios en los que la versión de la base de datos de origen no sea compatible, o una configuración de clúster híbrido no sea factible.
En este tutorial se describe cómo migrar datos a Azure Managed Instance for Apache Cassandra sin conexión mediante el conector de Spark para Cassandra y Azure Databricks para Apache Spark.
Prerrequisitos
Aprovisione un clúster de Azure Managed Instance for Apache Cassandra mediante Azure Portal o la CLI de Azure, y asegúrese de que puede conectarse al clúster con CQLSH.
Aprovisione una cuenta de Azure Databricks dentro de la red virtual de Cassandra administrada. Asegúrese de que también tiene acceso de red al clúster de Cassandra de origen.
Asegúrese de ya haber migrado el esquema del espacio de claves o tablas de la base de datos de Cassandra de origen a la base de datos de Managed Instance for Cassandra de destino.
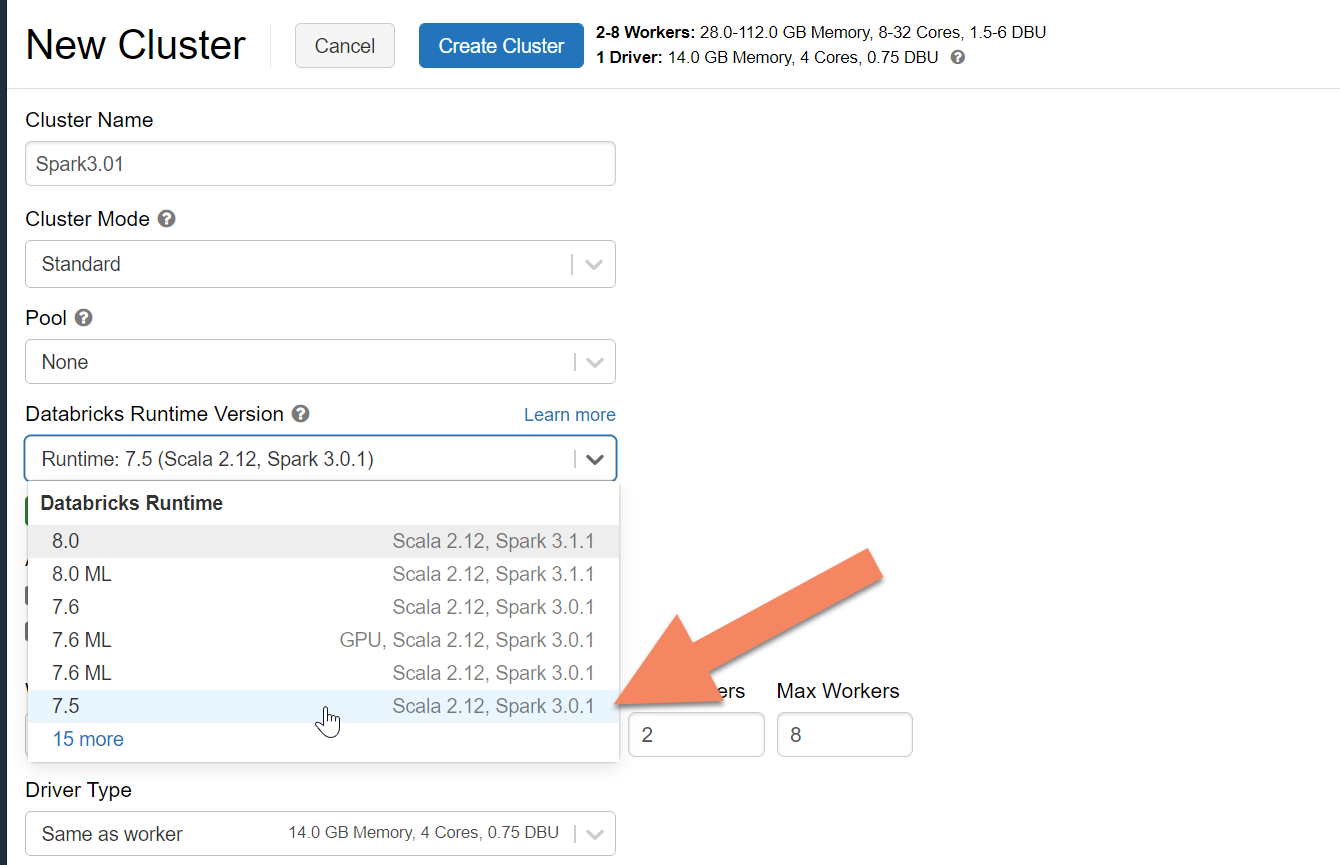
Aprovisionar un clúster de Azure Databricks
Se recomienda seleccionar el entorno de ejecución de Databricks Runtime versión 7.5, que admite Spark 3.0:
Adición de dependencias
Agregue la biblioteca de conectores de Cassandra de Apache Spark a su clúster para conectarse a los puntos de conexión nativos y de Cassandra de Azure Cosmos DB. En el clúster, seleccione Libraries>Install New>Maven (Bibliotecas > Instalar nueva > Maven) y, después, agregue com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 en las coordenadas de Maven.

Seleccione Install (Instalar) y asegúrese de reiniciar el clúster cuando se complete la instalación.
Nota
Asegúrese de reiniciar el clúster de Databricks después de que se haya instalado la biblioteca de conectores de Cassandra.
Creación de un cuaderno de Scala para la migración
Cree un cuaderno de Scala en Databricks. Reemplace las configuraciones de Cassandra de origen y de destino con las credenciales correspondientes, así como los espacios de claves y las tablas de origen y destino. Después, ejecute el código siguiente:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "10",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Nota
Si necesita conservar el original writetime de cada fila, consulte la muestra del migrador de Cassandra.