Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se muestra cómo usar cargas de trabajo de GPU de NVIDIA con Red Hat OpenShift en Azure.
Prerrequisitos
- CLI de OpenShift
- jq, moreutils y gettext package
- Red Hat OpenShift en Azure 4.10
Si necesita instalar un clúster, consulte Tutorial: Creación de un clúster de Red Hat OpenShift en Azure 4. los clústeres deben tener la versión 4.10.x o superior.
Nota:
A partir de la versión 4.10, ya no es necesario configurar derechos para usar el operador NVIDIA. Esto ha simplificado considerablemente la configuración del clúster en cargas de trabajo de GPU.
Linux:
sudo dnf install jq moreutils gettext
macOS
brew install jq moreutils gettext
Solicitud de cuota de GPU
Todas las cuotas de GPU en Azure son 0 de forma predeterminada. Tendrá que iniciar sesión en el Azure Portal y solicitar la cuota de GPU. Debido a la competencia para los trabajadores de GPU, es posible que tenga que aprovisionar un clúster en una región donde realmente puede reservar GPU.
admite los siguientes trabajos de GPU:
- NC4as T4 v3
- NC6s v3
- NC8as T4 v3
- NC12s v3
- NC16as T4 v3
- NC24s v3
- NC24rs v3
- NC64as T4 v3
Las siguientes instancias también son compatibles con MachineSets adicionales:
- Standard_ND96asr_v4
- NC24ads_A100_v4
- NC48ads_A100_v4
- NC96ads_A100_v4
- ND96amsr_A100_v4
Nota:
Al solicitar una cuota, recuerde que Azure está configurado por núcleo. Para solicitar un único nodo NC4as T4 v3, deberá solicitar cuota en grupos de 4. Si desea solicitar un NC16as T4 v3, deberá solicitar la cuota de 16.
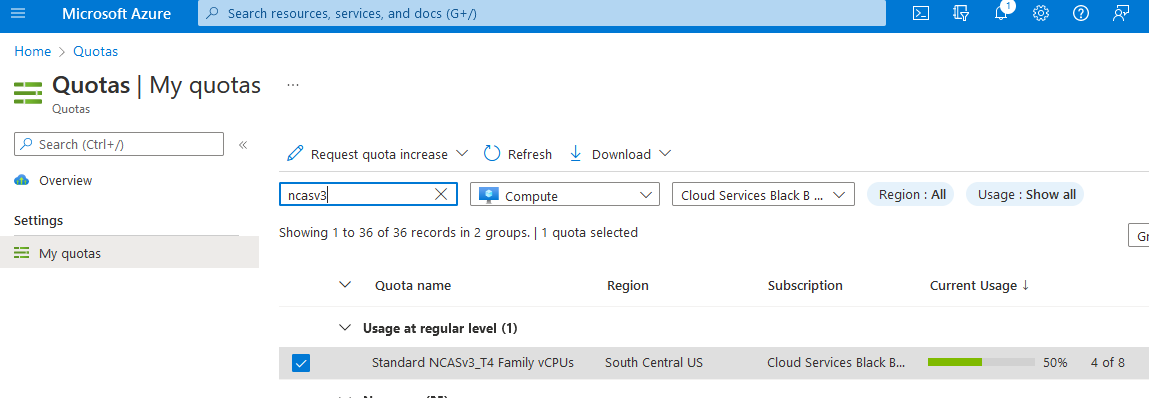
Inicie sesión en Azure Portal.
Escriba cuotas en el cuadro de búsqueda y, a continuación, seleccione Cómputo.
En el cuadro de búsqueda, escriba NCAsv3_T4, active la casilla de la región en la que se encuentra el clúster y, a continuación, seleccione Solicitar aumento de cuota.
Configure la cuota.
Acceder al clúster
Inicie sesión en OpenShift con una cuenta de usuario con privilegios de administrador de clúster. En el ejemplo siguiente se usa una cuenta denominada kubadmin:
oc login <apiserver> -u kubeadmin -p <kubeadminpass>
Secreto de extracción (condicional)
Actualice el secreto de extracción para asegurarse de que pueda instalar operadores y conectarse a cloud.redhat.com.
Nota:
Omita este paso si ya ha vuelto a crear un secreto de extracción completo con cloud.redhat.com habilitado.
Inicie sesión en cloud.redhat.com.
Navegue a https://cloud.redhat.com/openshift/install/azure/aro-provisioned.
Seleccione Descargar secreto de extracción y guarde el secreto de extracción como
pull-secret.txt.Importante
Los pasos restantes de esta sección deben ejecutarse en el mismo directorio de trabajo que
pull-secret.txt.Exporte el secreto de extracción existente.
oc get secret pull-secret -n openshift-config -o json | jq -r '.data.".dockerconfigjson"' | base64 --decode > export-pull.jsonCombine el secreto de extracción descargado con el secreto de extracción del sistema para agregar
cloud.redhat.com.jq -s '.[0] * .[1]' export-pull.json pull-secret.txt | tr -d "\n\r" > new-pull-secret.jsonCargue el nuevo archivo secreto.
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=new-pull-secret.jsonEs posible que tenga que esperar aproximadamente 1 hora para que todo se sincronice con cloud.redhat.com.
Elimina secretos.
rm pull-secret.txt export-pull.json new-pull-secret.json
Conjunto de máquinas de GPU
usa MachineSet de Kubernetes para crear conjuntos de máquinas. En el procedimiento siguiente se explica cómo exportar el primer conjunto de máquinas de un clúster y usarlo como plantilla para compilar una sola máquina de GPU.
Vea los conjuntos de máquinas existentes.
Para facilitar la instalación, en este ejemplo se usa el primer conjunto de máquinas como el que se clona para crear un nuevo conjunto de máquinas de GPU.
MACHINESET=$(oc get machineset -n openshift-machine-api -o=jsonpath='{.items[0]}' | jq -r '[.metadata.name] | @tsv')Guarde una copia del conjunto de máquinas de ejemplo.
oc get machineset -n openshift-machine-api $MACHINESET -o json > gpu_machineset.jsonCambie el campo
.metadata.namea un nuevo nombre único.jq '.metadata.name = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonAsegúrese de que
spec.replicascoincide con el número de réplicas deseado para el conjunto de máquinas.jq '.spec.replicas = 1' gpu_machineset.json| sponge gpu_machineset.jsonCambie el campo
.spec.selector.matchLabels.machine.openshift.io/cluster-api-machinesetpara que coincida con el campo.metadata.name.jq '.spec.selector.matchLabels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonCambie el
.spec.template.metadata.labels.machine.openshift.io/cluster-api-machinesetpara que coincida con el campo.metadata.name.jq '.spec.template.metadata.labels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonCambie el
spec.template.spec.providerSpec.value.vmSizepara que coincida con el tipo de instancia de GPU deseado de Azure.La máquina usada en este ejemplo es Standard_NC4as_T4_v3.
jq '.spec.template.spec.providerSpec.value.vmSize = "Standard_NC4as_T4_v3"' gpu_machineset.json | sponge gpu_machineset.jsonCambie el
spec.template.spec.providerSpec.value.zonepara que coincida con la zona deseada de Azure.jq '.spec.template.spec.providerSpec.value.zone = "1"' gpu_machineset.json | sponge gpu_machineset.jsonElimine la sección
.statusdel archivo YAML.jq 'del(.status)' gpu_machineset.json | sponge gpu_machineset.jsonCompruebe los demás datos del archivo YAML.
Asegúrese de que se ha establecido la SKU correcta
Dependiendo de la imagen utilizada para el conjunto de máquinas, ambos valores para image.sku y image.version deben establecerse en consecuencia. Esto es para asegurarse de que se usará la máquina virtual de generación 1 o 2 para Hyper-V. Consulte aquí para obtener más información.
Ejemplo:
Si usa Standard_NC4as_T4_v3, se admiten ambas versiones. Como se mencionó en Compatibilidad de características. En este caso, no se requieren cambios.
Si usa Standard_NC24ads_A100_v4, solo se admite la máquina virtual de generación 2.
En este caso, el valor de image.sku debe seguir la versión v2 equivalente de la imagen que corresponde al image.sku original del clúster. En este ejemplo, el valor será v410-v2.
Esto se puede encontrar mediante el siguiente comando:
az vm image list --architecture x64 -o table --all --offer aro4 --publisher azureopenshift
Filtered output:
SKU VERSION
------- ---------------
v410-v2 410.84.20220125
aro_410 410.84.20220125
Si el clúster se creó con la imagen de SKU base aro_410 y el mismo valor se mantiene en el conjunto de máquinas, se producirá el siguiente error:
failure sending request for machine myworkernode: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="The selected VM size 'Standard_NC24ads_A100_v4' cannot boot Hypervisor Generation '1'.
Creación de un conjunto de máquinas de GPU
Siga estos pasos para crear la nueva máquina de GPU. Puede llevar entre 10 y 15 minutos en aprovisionar una nueva máquina de GPU. Si se produce un error en este paso, inicie sesión en Azure Portal y asegúrese de que no haya problemas de disponibilidad. Para ello, vaya a Virtual Machines y busque el nombre del trabajo que creó anteriormente para ver el estado de las máquinas virtuales.
Cree el conjunto de máquinas de GPU.
oc create -f gpu_machineset.jsonEste comando tardará varios minutos en completarse.
Verifique el conjunto de máquinas de GPU.
Las máquinas deberían implementarse. Puede ver el estado del conjunto de máquinas con los siguientes comandos:
oc get machineset -n openshift-machine-api oc get machine -n openshift-machine-apiUna vez que se aprovisionen las máquinas, que pueden tardar entre 5 y 15 minutos, estas se mostrarán como nodos en la lista de nodos:
oc get nodesDebería ver un nodo con el nombre
nvidia-worker-southcentralus1que se creó anteriormente.
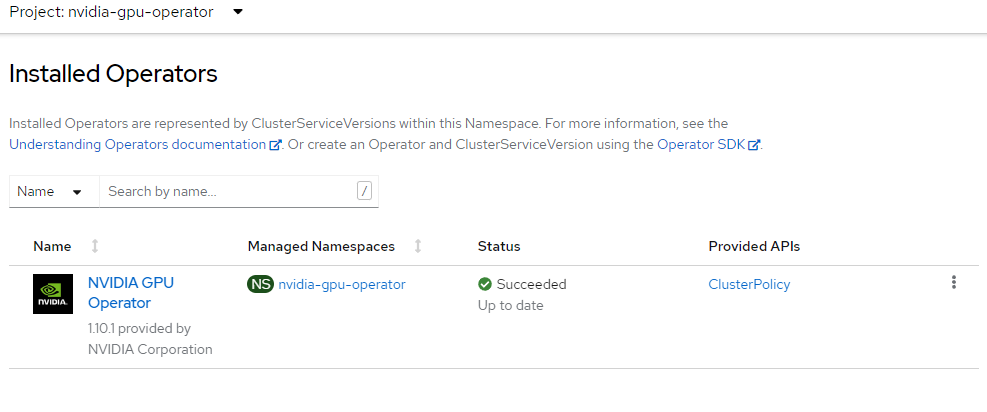
Instalación del operador de GPU de NVIDIA
En esta sección se explica cómo crear el espacio de nombres nvidia-gpu-operator, configurar el grupo de operadores e instalar el operador de GPU de NVIDIA.
Cree un espacio de nombres de NVIDIA.
cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: nvidia-gpu-operator EOFCree un grupo de operadores.
cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: nvidia-gpu-operator-group namespace: nvidia-gpu-operator spec: targetNamespaces: - nvidia-gpu-operator EOFObtenga el canal de NVIDIA más reciente con el siguiente comando:
CHANNEL=$(oc get packagemanifest gpu-operator-certified -n openshift-marketplace -o jsonpath='{.status.defaultChannel}')
Nota:
Si el clúster se creó sin proporcionar el secreto de extracción, no incluirá ejemplos ni operadores de Red Hat ni de asociados certificados. Esto generará el siguiente mensaje de error:
Error del servidor (NotFound): no se encontró packagemanifests.packages.operators.coreos.com "gpu-operator-certified".
Para agregar el secreto de extracción de Red Hat en un clúster de Red Hat OpenShift en Azure, siga estas instrucciones.
Obtenga el paquete de NVIDIA más reciente con el siguiente comando:
PACKAGE=$(oc get packagemanifests/gpu-operator-certified -n openshift-marketplace -ojson | jq -r '.status.channels[] | select(.name == "'$CHANNEL'") | .currentCSV')Cree la suscripción.
envsubst <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: gpu-operator-certified namespace: nvidia-gpu-operator spec: channel: "$CHANNEL" installPlanApproval: Automatic name: gpu-operator-certified source: certified-operators sourceNamespace: openshift-marketplace startingCSV: "$PACKAGE" EOFEspere a que el operador termine de instalarse.
No continúe hasta que haya comprobado que el operador ha terminado de instalarse. Además, asegúrese de que el trabajo de GPU esté en línea.
Instalación de un operador de detección de características de nodo
El operador de detección de características de nodo detectará la GPU en los nodos y etiquetará adecuadamente los nodos para que pueda dirigirse a ellos para cargas de trabajo.
En este ejemplo se instala el operador NFD en el espacio de nombres openshift-ndf y se crea la "suscripción", que es la configuración de NFD.
Documentación oficial para instalar el operador de detección de características de nodo.
Configure
Namespace.cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: openshift-nfd EOFCree
OperatorGroup.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: openshift-nfd- name: openshift-nfd namespace: openshift-nfd EOFCree
Subscription.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: nfd namespace: openshift-nfd spec: channel: "stable" installPlanApproval: Automatic name: nfd source: redhat-operators sourceNamespace: openshift-marketplace EOFEspere a que la detección de características de nodo complete la instalación.
Puede iniciar sesión en la consola de OpenShift para ver operadores o simplemente esperar unos minutos. Si no se espera a que el operador se instale, se producirá un error en el paso siguiente.
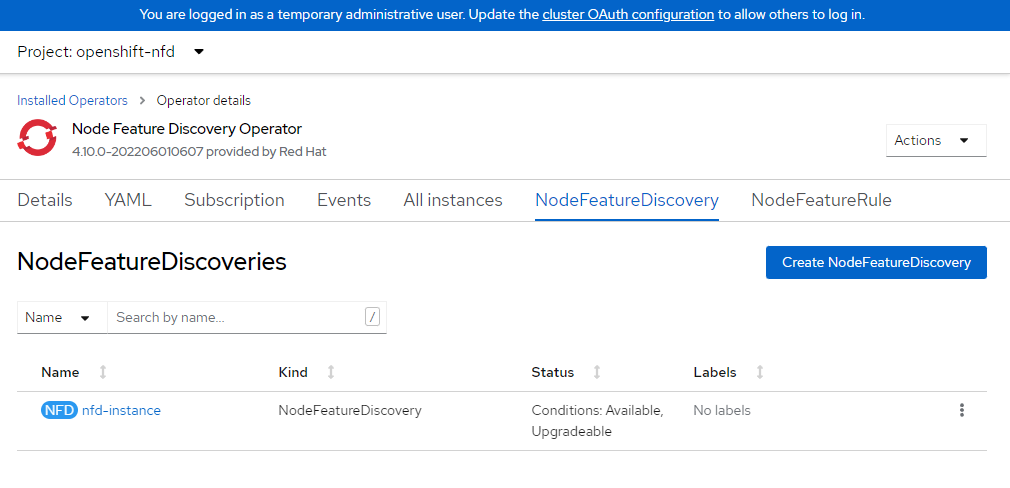
Cree una instancia de NFD.
cat <<EOF | oc apply -f - kind: NodeFeatureDiscovery apiVersion: nfd.openshift.io/v1 metadata: name: nfd-instance namespace: openshift-nfd spec: customConfig: configData: | # - name: "more.kernel.features" # matchOn: # - loadedKMod: ["example_kmod3"] # - name: "more.features.by.nodename" # value: customValue # matchOn: # - nodename: ["special-.*-node-.*"] operand: image: >- registry.redhat.io/openshift4/ose-node-feature-discovery@sha256:07658ef3df4b264b02396e67af813a52ba416b47ab6e1d2d08025a350ccd2b7b servicePort: 12000 workerConfig: configData: | core: # labelWhiteList: # noPublish: false sleepInterval: 60s # sources: [all] # klog: # addDirHeader: false # alsologtostderr: false # logBacktraceAt: # logtostderr: true # skipHeaders: false # stderrthreshold: 2 # v: 0 # vmodule: ## NOTE: the following options are not dynamically run-time ## configurable and require a nfd-worker restart to take effect ## after being changed # logDir: # logFile: # logFileMaxSize: 1800 # skipLogHeaders: false sources: # cpu: # cpuid: ## NOTE: attributeWhitelist has priority over attributeBlacklist # attributeBlacklist: # - "BMI1" # - "BMI2" # - "CLMUL" # - "CMOV" # - "CX16" # - "ERMS" # - "F16C" # - "HTT" # - "LZCNT" # - "MMX" # - "MMXEXT" # - "NX" # - "POPCNT" # - "RDRAND" # - "RDSEED" # - "RDTSCP" # - "SGX" # - "SSE" # - "SSE2" # - "SSE3" # - "SSE4.1" # - "SSE4.2" # - "SSSE3" # attributeWhitelist: # kernel: # kconfigFile: "/path/to/kconfig" # configOpts: # - "NO_HZ" # - "X86" # - "DMI" pci: deviceClassWhitelist: - "0200" - "03" - "12" deviceLabelFields: # - "class" - "vendor" # - "device" # - "subsystem_vendor" # - "subsystem_device" # usb: # deviceClassWhitelist: # - "0e" # - "ef" # - "fe" # - "ff" # deviceLabelFields: # - "class" # - "vendor" # - "device" # custom: # - name: "my.kernel.feature" # matchOn: # - loadedKMod: ["example_kmod1", "example_kmod2"] # - name: "my.pci.feature" # matchOn: # - pciId: # class: ["0200"] # vendor: ["15b3"] # device: ["1014", "1017"] # - pciId : # vendor: ["8086"] # device: ["1000", "1100"] # - name: "my.usb.feature" # matchOn: # - usbId: # class: ["ff"] # vendor: ["03e7"] # device: ["2485"] # - usbId: # class: ["fe"] # vendor: ["1a6e"] # device: ["089a"] # - name: "my.combined.feature" # matchOn: # - pciId: # vendor: ["15b3"] # device: ["1014", "1017"] # loadedKMod : ["vendor_kmod1", "vendor_kmod2"] EOFCompruebe que NFD esté listo.
El estado de este operador debe mostrarse como Disponible.
Aplicación de la configuración del clúster de NVIDIA
En esta sección se explica cómo aplicar la configuración del clúster de NVIDIA. Lea la documentación de NVIDIA para consultar cómo personalizar esto si tiene sus propios repositorios privados o configuraciones específicas. Este proceso puede tardar varios minutos en completarse.
Aplique la configuración del clúster.
cat <<EOF | oc apply -f - apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: migManager: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia deployGFD: true dcgm: enabled: true gfd: {} dcgmExporter: config: name: '' driver: licensingConfig: nlsEnabled: false configMapName: '' certConfig: name: '' kernelModuleConfig: name: '' repoConfig: configMapName: '' virtualTopology: config: '' enabled: true use_ocp_driver_toolkit: true devicePlugin: {} mig: strategy: single validator: plugin: env: - name: WITH_WORKLOAD value: 'true' nodeStatusExporter: enabled: true daemonsets: {} toolkit: enabled: true EOFCompruebe la directiva de clúster.
Inicie sesión en la consola de OpenShift y vaya a los operadores. Asegúrese de que está en el espacio de nombres
nvidia-gpu-operator. Debería decirState: Ready once everything is complete.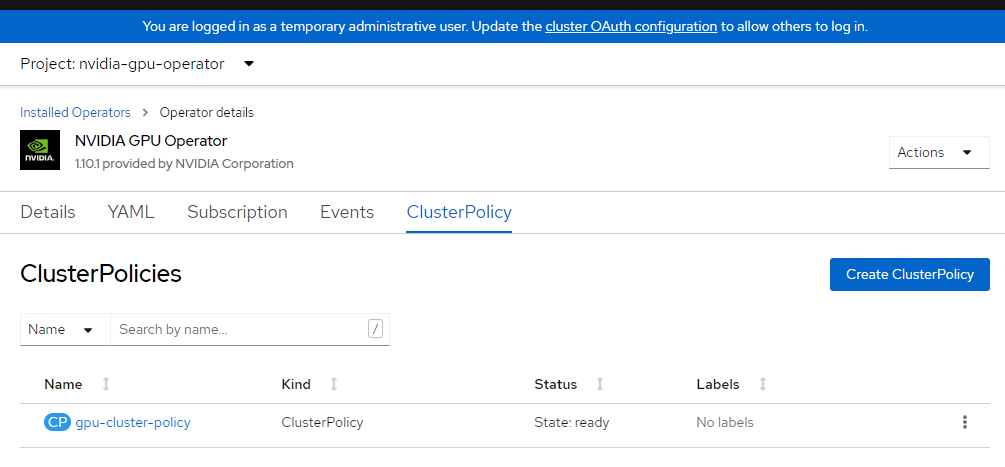
Validación de GPU
El operador de NVIDIA y NFD pueden tardar algún tiempo en instalar e identificar por completo las máquinas. Ejecute los comandos siguientes para validar que todo se ejecuta según lo previsto:
Compruebe que NFD puede ver las GPU.
oc describe node | egrep 'Roles|pci-10de' | grep -v masterLa salida debe ser similar a la siguiente:
Roles: worker feature.node.kubernetes.io/pci-10de.present=trueCompruebe las etiquetas de nodo.
Puede ver las etiquetas de nodo iniciando sesión en la consola de OpenShift -> Cómputo -> Nodos -> nvidia-worker-southcentralus1-. Debería ver varias etiquetas de GPU de NVIDIA y el dispositivo pci-10de anterior.
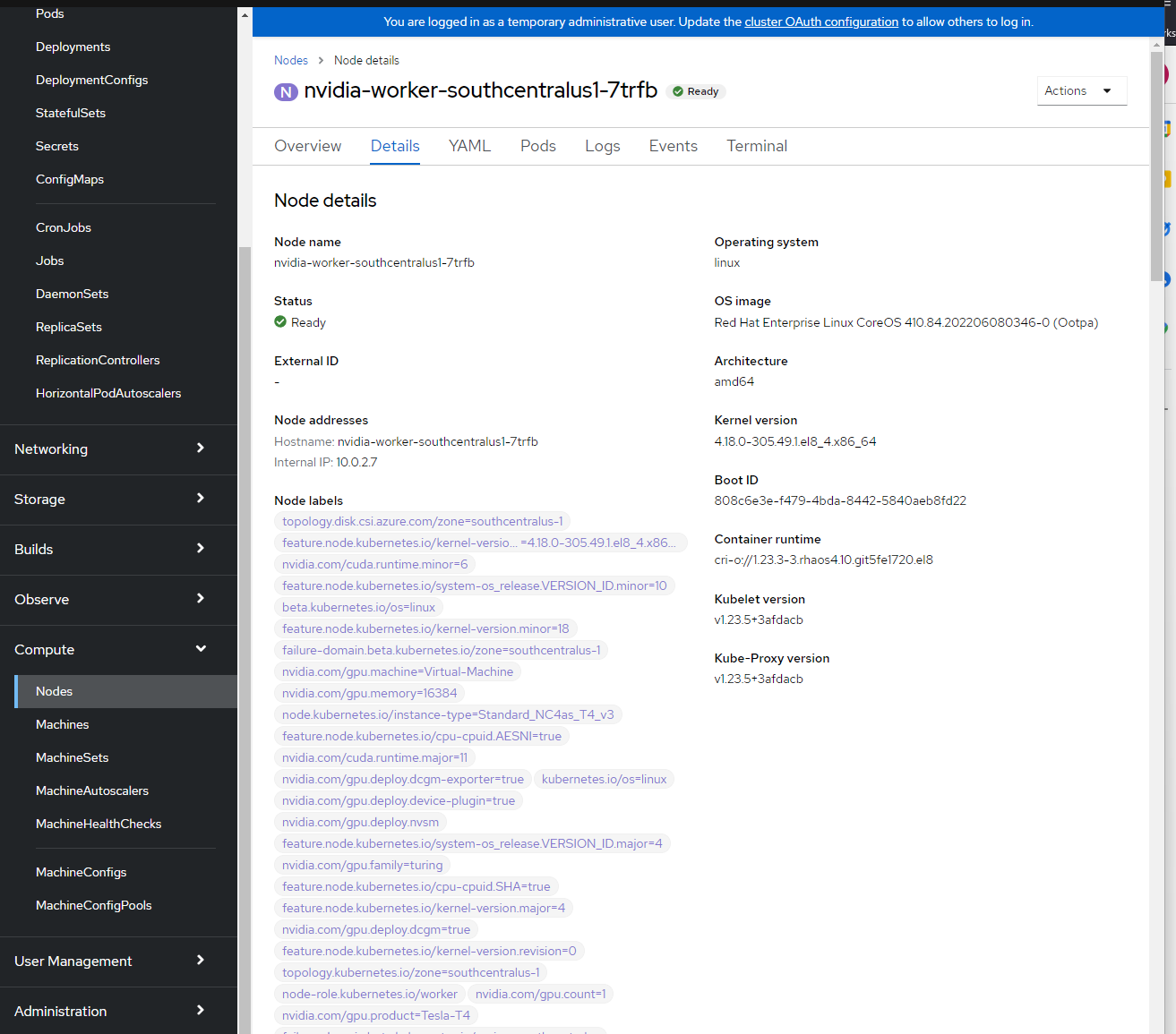
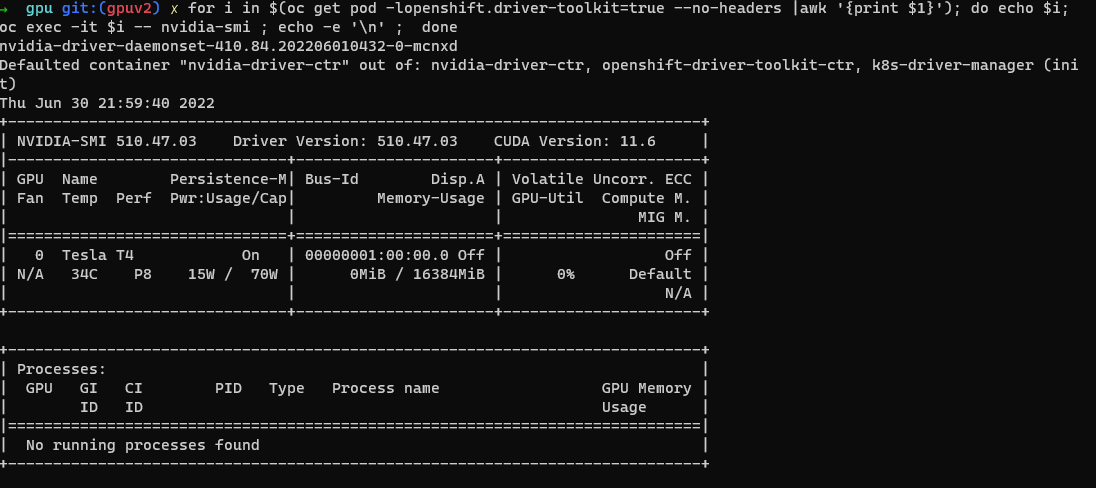
Comprobación de la herramienta SMI de NVIDIA.
oc project nvidia-gpu-operator for i in $(oc get pod -lopenshift.driver-toolkit=true --no-headers |awk '{print $1}'); do echo $i; oc exec -it $i -- nvidia-smi ; echo -e '\n' ; doneDebería ver la salida que muestra las GPU disponibles en el host, como esta captura de pantalla de ejemplo. (varía en función del tipo de trabajo de GPU).
Creación de un pod para ejecutar una carga de trabajo de GPU
oc project nvidia-gpu-operator cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "quay.io/giantswarm/nvidia-gpu-demo:latest" resources: limits: nvidia.com/gpu: 1 nodeSelector: nvidia.com/gpu.present: true EOFVer registros.
oc logs cuda-vector-add --tail=-1
Nota:
Si recibe un error Error from server (BadRequest): container "cuda-vector-add" in pod "cuda-vector-add" is waiting to start: ContainerCreating, intente ejecutar oc delete pod cuda-vector-add y vuelva a ejecutar la instrucción "create" anterior.
La salida debe ser similar a la siguiente (depende de la GPU):
[Vector addition of 5000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
Si se ejecuta correctamente, el pod se puede eliminar:
oc delete pod cuda-vector-add