Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A:  Servidor flexible de Azure Database for PostgreSQL
Servidor flexible de Azure Database for PostgreSQL
El servidor flexible de Azure Database for PostgreSQL proporciona la capacidad de ampliar la funcionalidad de la base de datos mediante extensiones. Las extensiones agrupan varios objetos SQL relacionados en un solo paquete que se puede cargar o quitar de la base de datos con un comando. Después de cargarse en la base de datos, las extensiones funcionan como características integradas.
¿Cómo se utilizan las extensiones de PostgreSQL?
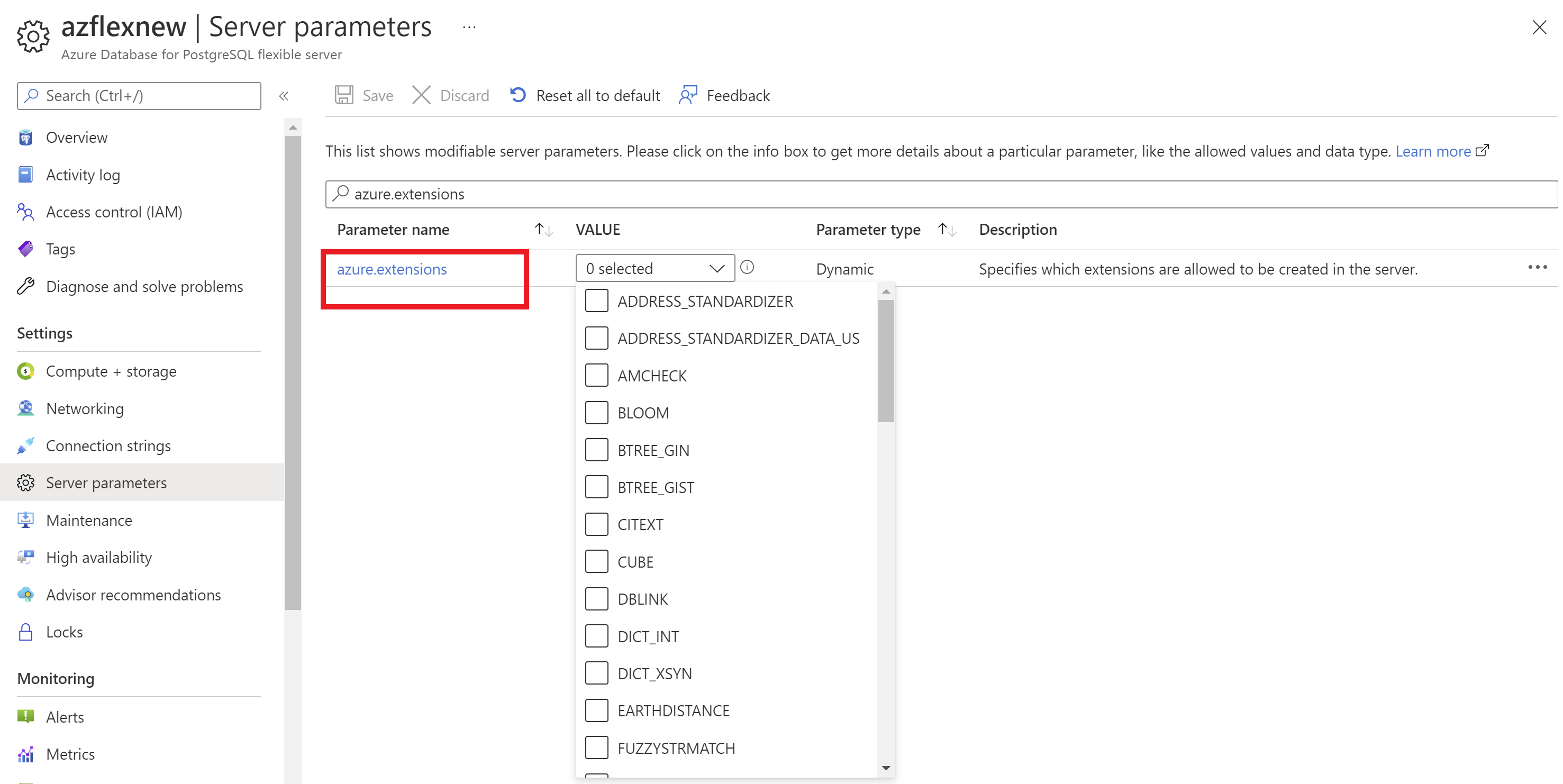
Antes de instalar extensiones en la opción de servidor flexible de Azure Database for PostgreSQL, debe agregar a la lista de permitidos estas extensiones para su uso.
Mediante Azure Portal:
- Seleccione la instancia de servidor flexible de Azure Database for PostgreSQL.
- En el menú de recursos, en sección Configuración, seleccione Parámetros del servidor.
- Busque el parámetro
azure.extensions. - Seleccione las extensiones que desea permitir.

Mediante la CLI de Azure:
Puede agregar extensiones a la lista de permitidos mediante el comando del conjunto de parámetros de la CLI.
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name azure.extensions --value <extension_name>,<extension_name>
Uso de Plantilla de ARM : en el ejemplo siguiente se dblinkextensiones permitidas, dict_xsyn, pg_buffercache en un servidor cuyo nombre es postgres-test-server:
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"flexibleServers_name": {
"defaultValue": "postgres-test-server",
"type": "String"
},
"azure_extensions_set_value": {
"defaultValue": " dblink,dict_xsyn,pg_buffercache",
"type": "String"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.DBforPostgreSQL/flexibleServers/configurations",
"apiVersion": "2021-06-01",
"name": "[concat(parameters('flexibleServers_name'), '/azure.extensions')]",
"properties": {
"value": "[parameters('azure_extensions_set_value')]",
"source": "user-override"
}
}
]
}
shared_preload_libraries es un parámetro de configuración de servidor que determina qué bibliotecas deben cargarse cuando se inicia el servidor flexible de Azure Database for PostgreSQL. Las bibliotecas que usan memoria compartida deben cargarse a través de este parámetro. Si la extensión debe agregarse a las bibliotecas de precarga compartida, siga estos pasos:
Mediante Azure Portal:
- Seleccione la instancia de servidor flexible de Azure Database for PostgreSQL.
- En el menú de recursos, en sección Configuración, seleccione Parámetros del servidor.
- Busque el parámetro
shared_preload_libraries. - Seleccione las bibliotecas que desea agregar.
:::image type="content" source="./media/concepts-extensions/shared-libraries.png" alt-text="Screenshot showing Azure Database for PostgreSQL -setting shared preload libraries parameter setting for extensions installation." lightbox="./media/concepts-extensions/shared-libraries.png":::
```Using [Azure CLI](/cli/azure/):
You can set `shared_preload_libraries` via CLI [parameter set](/cli/azure/postgres/flexible-server/parameter?view=azure-cli-latest&preserve-view=true) command.
```azurecli
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name shared_preload_libraries --value <extension_name>,<extension_name>
Crear extensión
Una vez que las extensiones estén permitidas y cargadas, deben instalarse en cada base de datos en la que planee usarlos.
- Un usuario debe ser miembro de
azure_pg_adminrol para crear una extensión. Un miembro del rol deazure_pg_adminpuede conceder privilegios a otros usuarios para crear extensiones. - Para instalar una extensión determinada, debe ejecutar el comando CREATE EXTENSION. Este comando carga los objetos empaquetados en la base de datos.
Nota:
Las extensiones de terceros que se ofrecen en el servidor flexible de Azure Database for PostgreSQL tienen una licencia de código abierto. Actualmente, no ofrecemos extensiones de terceros ni versiones de extensión con modelos de licencia premium o propietario.
La instancia de servidor flexible de Azure Database for PostgreSQL admite un subconjunto de extensiones de PostgreSQL clave, como se muestra en la tabla siguiente. Esta información también está disponible al ejecutar SHOW azure.extensions;. Las extensiones no enumeradas en este documento no se admiten en el servidor flexible de Azure Database for PostgreSQL. No puede crear o cargar su propia extensión en el servidor flexible de Azure Database for PostgreSQL.
Versiones de extensión
Las extensiones siguientes están disponibles en el servidor flexible Azure Database for PostgreSQL:
Nota:
Las extensiones de la tabla siguiente con la marca ✔️ requieren que sus bibliotecas correspondientes estén habilitadas en el parámetro de servidor shared_preload_libraries.
| Nombre de la extensión | Descripción | PostgreSQL 17 | PostgreSQL 16 | PostgreSQL 15 | PostgreSQL 14 | PostgreSQL 13 | PostgreSQL 12 | PostgreSQL 11 |
|---|---|---|---|---|---|---|---|---|
| address_standardizer | Se utilizan para analizar una dirección en los elementos que la componen. Por lo general se usa para admitir el paso de normalización de la dirección de codificación geográfica. | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| address_standardizer_data_us | Aborda el ejemplo del conjunto de datos estandarizado de EE. UU. | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| antigüedad (versión preliminar) | Proporciona funcionalidades de base de datos de grafos | N/D | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | N/D | N/D |
| amcheck | Funciones de comprobación de la integridad de la relación | 1.4 | 1.3 | 1.3 | 1.3 | 1.2 | 1.2 | 1.1 |
| anon (versión preliminar) | Herramientas de anonimización de datos | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ |
| azure_ai | Integración de Azure AI y ML Services para PostgreSQL | N/D | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | N/D |
| azure_storage | Integración de Azure para PostgreSQL | N/D | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | N/D |
| bloom | Método de acceso de bloom: índice basado en archivos de firma | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1.0 |
| btree_gin | Compatibilidad con la indexación de tipos de datos comunes en GIN | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| btree_gist | Compatibilidad con la indexación de tipos de datos comunes en GiST | 1.7 | 1.7 | 1.7 | 1.6 | 1.5 | 1.5 | 1.5 |
| citext | Tipo de datos para cadenas de caracteres que no distinguen mayúsculas de minúsculas | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 |
| cube | Tipo de datos para los cubos multidimensionales | 1.5 | 1.5 | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 |
| dblink | Se conecta a otras bases de datos de PostgreSQL desde una base de datos | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| dict_int | Plantilla de diccionario de búsqueda de texto para números enteros | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1.0 |
| dict_xsyn | Plantilla de diccionario de búsqueda de texto para el procesamiento de sinónimos extendido | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1.0 |
| earthdistance | Calcula distancias de círculo máximo en la superficie de la Tierra | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| fuzzystrmatch | Determina las similitudes y la distancia entre las cadenas | 1.2 | 1.2 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| hstore | Tipo de datos para almacenar conjuntos de pares (clave/valor) | 1.8 | 1.8 | 1.8 | 1.8 | 1.7 | 1.6 | 1.5 |
| hypopg | Índices hipotéticos para PostgreSQL | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 |
| intagg | Agregador entero y enumerador (obsoleto) | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| intarray | Funciones, operadores e índices compatibles con matrices 1D de números enteros | 1.5 | 1.5 | 1.5 | 1.5 | 1.3 | 1.2 | 1.2 |
| isn | Tipos de datos para los estándares internacionales de numeración de productos | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| lo | Mantenimiento de objetos grandes | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| login_hook | Login_hook: enlace para ejecutar login_hook.login() en el momento del inicio de sesión | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 |
| ltree | Tipo de datos para las estructuras de árbol jerárquicas | 1.3 | 1.2 | 1.2 | 1.2 | 1.2 | 1.1 | 1.1 |
| oracle_fdw | Contenedor de datos externos para bases de datos de Oracle | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | N/D |
| orafce | Funciones y operadores que emulan un subconjunto de funciones y paquetes de RDBMS de Oracle | 4,9 | 4.4. | 3,24 | 3,18 | 3,18 | 3,18 | 3.7 |
| pageinspect | Inspección del contenido de páginas de bases de datos a un nivel bajo | 1.12 | 1.12 | 1.11 | 1.9 | 1.8 | 1.7 | 1.7 |
| pgaudit | Proporciona funcionalidad de auditoría | 16.0 ✔️ | 16.0 ✔️ | 1.7 ✔️ | 1.6.2 ✔️ | 1.5 ✔️ | 1.4.3 ✔️ | 1.3.2 ✔️ |
| pg_buffercache | Examina la caché del búfer compartido | 1.5 | 1.4 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_cron | Programador de trabajos para PostgreSQL | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.4-1 ✔️ |
| pgcrypto | Funciones de cifrado | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_freespacemap | Examen de la asignación de espacio libre (FSM) | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_hint_plan | Permite ajustar los planes de ejecución de PostgreSQL mediante las llamadas sugerencias en los comentarios de SQL. | 1.7.0 ✔️ | 1.6.0 ✔️ | 1.5 ✔️ | 1.4 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ |
| pglogical | Replicación lógica de PostgreSQL | 2.4.5 ✔️ | 2.4.4 ✔️ | 2.4.2 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ |
| pg_partman | Extensión para administrar tablas con particiones por hora o identificador | 5.0.1 ✔️ | 5.0.1 ✔️ | 4.7.1 ✔️ | 4.6.1 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ |
| pg_prewarm | Prepara los datos de relación | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ |
| pg_repack | Reorganización de tablas en bases de datos PostgreSQL con bloqueos mínimos | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 |
| pgrouting | Extensión PgRouting | N/D | N/D | 3.5.0 | 3.3.0 | 3.3.0 | 3.3.0 | 3.3.0 |
| pgrowlocks | Muestra información de bloqueo de nivel de fila | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_squeeze | Herramienta para quitar el espacio sin usar de una relación. | 1.7 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ |
| pg_stat_statements | Realiza un seguimiento de las estadísticas de ejecución de todas las instrucciones SQL ejecutadas | 1.11 ✔️ | 1.10 ✔️ | 1.10 ✔️ | 1.9 ✔️ | 1.8 ✔️ | 1.7 ✔️ | 1.6 ✔️ |
| pgstattuple | Muestra estadísticas de nivel de tupla | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 |
| pg_trgm | Medición de similitud de texto y búsqueda de índice basada en trigramas | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 | 1.4 | 1.4 |
| pg_visibility | Examen del mapa de visibilidad (VM) y la información de visibilidad de nivel de página | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| plpgsql | Lenguaje de procedimientos de PL/pgSQL | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| plv8 | Lenguaje de procedimientos de confianza de PL/JavaScript (v8) | 3.1.7 | 3.1.7 | 3.1.7 | 3.0.0 | 3.0.0 | 3.0.0 | 3.0.0 |
| postgis | Funciones y tipos espaciales de geometría y geografía de PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_raster | Funciones y tipos de trama de PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_sfcgal | Funciones de PostGIS SFCGAL | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_tiger_geocoder | Geocoder de PostGIS tiger y geocoder inverso | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_topology | Funciones y tipos espaciales de topología PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgres_fdw | Contenedor de datos externos para servidores PostgreSQL remotos | 1.1 | 1.1 | 1.1 | 1.1 | 1,0 | 1,0 | 1,0 |
| postgres_protobuf | Búferes de protocolo para PostgreSQL | 0,2 | 0,2 | 0,2 | 0,2 | 0,2 | 0,2 | N/D |
| semver | Tipo de datos de versión semántica | 0.32.1 | 0.32.1 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 |
| session_variable | Session_variable: registro y manipulación de variables y constantes de sesión | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 |
| sslinfo | Información sobre los certificados SSL | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| tablefunc | Funciones que manipulan la totalidad del contenido de las tablas, incluidas tablas de referencias cruzadas | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 |
| tds_fdw | Contenedor de datos externos para consultar una base de datos de TDS (Sybase o Microsoft SQL Server) | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 |
| timescaledb | Habilita las inserciones escalables y las consultas complejas para los datos de serie temporal | N/D | 2.13.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 1.7.4 ✔️ |
| tsm_system_rows | Método TABLESAMPLE que acepta el número de filas como un límite. | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1.0 |
| tsm_system_time | Método TABLESAMPLE que acepta el tiempo en milisegundos como un límite. | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1,0 | 1.0 |
| unaccent | Diccionario de búsqueda de texto que quita los acentos | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| uuid-ossp | Genera identificadores únicos universales (UUID). | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| vector | Tipos de datos vectoriales y métodos de acceso ivfflat y hnsw | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.5.1 |
Actualización de extensiones de PostgreSQL
Las actualizaciones locales de las extensiones de base de datos se permiten mediante un comando sencillo. Esta característica permite a los clientes actualizar automáticamente sus extensiones de terceros a las versiones más recientes, y mantener sistemas actuales y seguros sin esfuerzo manual.
Actualización de extensiones
Para actualizar una extensión instalada a la versión más reciente disponible compatible con Azure, use el siguiente comando SQL:
ALTER EXTENSION <extension_name> UPDATE;
Este comando simplifica la administración de extensiones de base de datos, ya que permite a los usuarios actualizar manualmente a la versión más reciente aprobada por Azure, lo que mejora la compatibilidad y la seguridad.
Limitaciones
Aunque la actualización de extensiones es sencilla, existen ciertas limitaciones:
- Selección de una versión específica: el comando no admite la actualización a versiones intermedias de una extensión. Siempre se actualiza a la versión más reciente disponible.
- Degradación: no admite la degradación de una extensión a una versión anterior. Si es necesario cambiar a una versión anterior, puede requerir asistencia de soporte técnico y depende de la disponibilidad de la versión anterior.
Extensiones instaladas
Para enumerar las extensiones instaladas actualmente en la base de datos, use el siguiente comando SQL:
SELECT * FROM pg_extension;
Extensiones disponibles y sus versiones
Para comprobar qué versiones de una extensión están disponibles para la instalación actual de la base de datos, consulte la vista de catálogo del sistema de pg_available_extensions. Por ejemplo, para determinar la versión disponible para la extensión azure_ai, ejecute:
SELECT * FROM pg_available_extensions WHERE name = 'azure_ai';
Estos comandos proporcionan las conclusiones necesarias sobre las configuraciones de extensión de la base de datos, lo que ayuda a mantener los sistemas de forma eficaz y segura. Al habilitar actualizaciones sencillas a las versiones de extensión más recientes, Azure Database for PostgreSQL sigue admitiendo la administración sólida, segura y eficaz de las aplicaciones de base de datos.
Consideraciones específicas del servidor flexible de Azure Database for PostgreSQL
A continuación se muestra una lista de extensiones admitidas que requieren algunas consideraciones específicas cuando se usan en el servicio de servidor flexible de Azure Database for PostgreSQL. La lista está ordenada alfabéticamente.
dblink
dblink permite conectarse desde una instancia de servidor flexible de Azure Database for PostgreSQL a otra o a otra base de datos del mismo servidor. El servidor flexible de Azure Database for PostgreSQL admite conexiones entrantes y salientes a cualquier servidor PostgreSQL. El servidor de envío debe permitir conexiones de salida al servidor de recepción. Del mismo modo, el servidor de recepción debe permitir conexiones del servidor de envío.
Se recomienda implementar los servidores con integración de red virtual si tiene previsto usar esta extensión. De forma predeterminada, la integración de red virtual permite conexiones entre servidores de la red virtual. También puede elegir usar grupos de seguridad de red de red virtual para personalizar el acceso.
pg_buffercache
pg_buffercache se puede usar para estudiar el contenido de shared_buffers. Con esta extensión puede indicar si una relación determinada está almacenada en caché o no (en shared_buffers). Esta extensión puede ayudarle a solucionar problemas de rendimiento (problemas de rendimiento relacionados con el almacenamiento en caché).
Esta extensión se integra con la instalación principal de PostgreSQL y es fácil de instalar.
CREATE EXTENSION pg_buffercache;
pg_cron
pg_cron es un programador de trabajos sencillo basado en cron para PostgreSQL que se ejecuta dentro de la base de datos como una extensión. La extensión pg_cron se puede usar para ejecutar tareas de mantenimiento programadas dentro de una base de datos PostgreSQL. Por ejemplo, puede ejecutar un vaciado periódico de una tabla o quitar trabajos de datos antiguos.
pg_cron puede ejecutar varios trabajos en paralelo, pero ejecuta como máximo una sola instancia de un determinado trabajo a la vez. Si se supone que debe comenzar una segunda ejecución antes de que finalice la primera, la segunda ejecución se pone en cola y se inicia en cuanto se completa la primera. De este modo, se garantiza que los trabajos se ejecuten exactamente tantas veces como estén programados y no se ejecuten simultáneamente con ellos mismos.
He aquí algunos ejemplos:
Para eliminar datos antiguos el sábado a las 3:30 a. m. (GMT).
SELECT cron.schedule('30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
Ejecutar el vacío todos los días a las 10:00 a. m. de la mañana (GMT) en la base de datos predeterminada postgres.
SELECT cron.schedule('0 10 * * *', 'VACUUM');
Para anular la programación de todas las tareas de pg_cron.
SELECT cron.unschedule(jobid) FROM cron.job;
Para ver todos los trabajos programados actualmente con pg_cron.
SELECT * FROM cron.job;
Para ejecutar el vacío todos los días a las 10:00 a. m. (GMT) en la base de datos "testcron" en azure_pg_admin cuenta de rol.
SELECT cron.schedule_in_database('VACUUM','0 10 * * * ','VACUUM','testcron',null,TRUE);
Nota:
La extensión pg_cron se carga previamente en shared_preload_libraries cada instancia de servidor flexible de Azure Database for PostgreSQL dentro de la base de datos Postgres para ofrecerle la capacidad de programar trabajos para que se ejecuten en otras bases de datos dentro de su instancia de servidor flexible de Azure Database para PostgreSQL sin comprometer la seguridad. Sin embargo, por razones de seguridad, debe permitir la extensión de la lista pg_cron e instalarla mediante comando CREATE EXTENSION.
A partir de pg_cron versión 1.4, puede usar las funciones cron.schedule_in_database y cron.alter_job para programar el trabajo en una base de datos específica y actualizar una programación existente, respectivamente.
He aquí algunos ejemplos:
En este ejemplo se eliminan datos antiguos el sábado a las 3:30 a. m. (GMT) en la base de datos DBName
SELECT cron.schedule_in_database('JobName', '30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$,'DBName');
Nota:
La función cron_schedule_in_database permite el nombre de usuario como parámetro opcional. Para establecer el nombre de usuario en un valor que no sea NULL se necesitan privilegios de superusuario de PostgreSQL y no se admite en el servidor flexible de Azure Database for PostgreSQL. En los ejemplos anteriores se muestra la ejecución de esta función con el parámetro de nombre de usuario opcional omitido o establecido en NULL, que ejecuta el trabajo en el contexto de la programación del trabajo por parte del usuario, que debe tener los privilegios de rol azure_pg_admin.
Para actualizar o cambiar el nombre de la base de datos de la programación existente
SELECT cron.alter_job(job_id:=MyJobID,database:='NewDBName');
pg_failover_slots
La extensión PG Failover Slots mejora el servidor flexible de Azure Database for PostgreSQL cuando se trabaja con servidores habilitados para replicación lógica y alta disponibilidad. Aborda eficazmente el desafío dentro del motor de PostgreSQL estándar que no conserva las ranuras de replicación lógica después de una conmutación por error. Mantener estas ranuras es fundamental para evitar pausas de replicación o errores de coincidencia de datos durante los cambios en el rol de servidor principal, lo que garantiza la continuidad operativa y la integridad de los datos.
La extensión simplifica el proceso de conmutación por error mediante la administración de la transferencia, la limpieza y la sincronización necesarias de las ranuras de replicación, lo que proporciona una transición sin problemas durante los cambios en el rol de servidor. La extensión es compatible con las versiones 11 y 16 de PostgreSQL.
Puede encontrar más información y cómo usar la extensión de ranuras de conmutación por error de PG en su página de GitHub.
Habilitar pg_failover_slots
Para habilitar la extensión de ranuras de conmutación por error de PG para la instancia de servidor flexible de Azure Database for PostgreSQL, debe modificar la configuración del servidor mediante la inclusión de la extensión en las bibliotecas de precarga compartida del servidor y ajustar un parámetro de servidor específico. Este es el proceso:
- Agregue
pg_failover_slotsa las bibliotecas de precarga compartidas del servidor actualizando el parámetroshared_preload_libraries. - Cambie el parámetro del servidor de
hot_standby_feedbackaon.
Los cambios en el parámetro shared_preload_libraries requieren un reinicio del servidor para surtir efecto.
Mediante Azure Portal:
- Seleccione la instancia de servidor flexible de Azure Database for PostgreSQL.
- En el menú de recursos, en sección Configuración, seleccione Parámetros del servidor.
- Busque el parámetro
shared_preload_librariesy edite su valor para incluirpg_failover_slots. - Busque el parámetro
hot_standby_feedbacky establezca su valor enon. - Seleccione Guardar para conservar los cambios. Ahora, tiene la opción de Guardar y reiniciar. Elija esto para asegurarse de que los cambios surtan efecto, ya que modificar
shared_preload_librariesrequiere un reinicio del servidor.
Al seleccionar Guardar y reiniciar, el servidor se reinicia automáticamente, aplicando los cambios que acaba de realizar. Una vez que el servidor vuelve a estar en línea, la extensión de ranuras de conmutación por error de PG está habilitada y operativa en la instancia principal del servidor flexible de Azure Database for PostgreSQL, lista para controlar las ranuras de replicación lógica durante las conmutaciones por error.
pg_hint_plan
pg_hint_plan permite ajustar los planes de ejecución de PostgreSQL mediante "sugerencias" en los comentarios de SQL, como:
/*+ SeqScan(a) */
pg_hint_plan lee frases de sugerencia en un comentario de una forma especial proporcionada con la instrucción SQL de destino. La forma especial comienza por la secuencia de caracteres "/*+" y termina con "*/". Las frases de sugerencia están formadas por el nombre de la sugerencia y los parámetros siguientes entre paréntesis y delimitados por espacios. Las nuevas líneas de legibilidad pueden delimitar cada frase de sugerencia.
Ejemplo:
/*+
HashJoin(a b)
SeqScan(a)
*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts an ON b.bid = a.bid
ORDER BY a.aid;
El ejemplo anterior hace que el planificador use los resultados de un seq scan en la tabla a que se combinará con la tabla b como un hash join.
Para instalar pg_hint_plan, además, para permitir su enumeración, como se muestra en cómo usar extensiones de PostgreSQL, debe incluirla en las bibliotecas de precarga compartidas del servidor. Si cambia el parámetro shared_preload_libraries de Postgres deberá shared_preload_libraries para que tenga efecto. Puede cambiar los parámetros mediante Azure Portal o la CLI de Azure.
Mediante Azure Portal:
- Seleccione la instancia de servidor flexible de Azure Database for PostgreSQL.
- En el menú de recursos, en sección Configuración, seleccione Parámetros del servidor.
- Busque el parámetro
shared_preload_librariesy edite su valor para incluirpg_hint_plan. - Seleccione Guardar para conservar los cambios. Ahora, tiene la opción de Guardar y reiniciar. Elija esto para asegurarse de que los cambios surtan efecto, ya que modificar
shared_preload_librariesrequiere un reinicio del servidor. Ahora puede habilitar pg_hing_plan en su base de datos del servidor flexible de Azure Database for PostgreSQL. Conéctese a la base de datos y ejecute el comando siguiente:
CREATE EXTENSION pg_hint_plan;
pg_prewarm
La extensión pg_prewarm carga los datos relacionales en la memoria caché. El precalentamiento de las memorias caché significa que las consultas tengan mejores tiempos de respuesta en su primera ejecución después de un reinicio. La función de precalentamiento automático no está disponible actualmente en el servidor flexible Azure Database for PostgreSQL.
pg_repack
Una pregunta típica que hacen las personas cuando intentan usar esta extensión es: ¿es pg_repack una extensión o un ejecutable del lado cliente, como psql o pg_dump?
La respuesta a eso es que es realmente ambas. pg_repack/lib contiene el código de la extensión, incluidos los artefactos de esquema y SQL que crea, y la biblioteca de C que implementa el código de varias de esas funciones. Por otro lado, pg_repack/bin mantiene el código de la aplicación cliente, que sabe cómo interactuar con los artefactos de programación creados por la extensión. Esta aplicación cliente tiene como objetivo facilitar la complejidad de interactuar con las diferentes interfaces expuestas por la extensión del lado servidor, por medio de ofrecer al usuario algunas opciones de línea de comandos que son más fáciles de entender. La aplicación cliente sin la extensión creada en la base de datos a la que apunta es inútil. La extensión del lado servidor por sí misma sería totalmente funcional, pero requeriría que el usuario comprenda un patrón de interacción complicado que consiste en ejecutar consultas para recuperar datos que se usan como entrada para las funciones implementadas por la extensión.
Permiso denegado para volver a empaquetar el esquema
A partir de ahora, debido a la forma en que concedemos permisos al esquema de reempaquetado creado por esta extensión, solo se admite la ejecución de pg_repack funcionalidad desde el contexto de azure_pg_admin.
Es posible que observe que si el propietario de una tabla, que no es azure_pg_admin, intenta ejecutar pg_repack, terminan recibiendo un error similar al siguiente:
NOTICE: Setting up workers.conns
ERROR: pg_repack failed with error: ERROR: permission denied for schema repack
LINE 1: select repack.version(), repack.version_sql()
Para evitar ese error, asegúrese de ejecutar pg_repack desde el contexto de azure_pg_admin.
pg_stat_statements
La extensión pg_stat_statements proporciona una vista de todas las consultas que se han ejecutado en la base de datos. Esto es útil para comprender el aspecto del rendimiento de la carga de trabajo de consultas en un sistema de producción.
La extensión pg_stat_statements se carga previamente en shared_preload_libraries cada instancia de servidor flexible de Azure Database for PostgreSQL para proporcionar un medio de seguimiento de las estadísticas de ejecución de instrucciones SQL.
Sin embargo, por motivos de seguridad, todavía tiene que lista de permitidos pg_stat_statements extensión e instalarla mediante comando CREATE EXTENSION.
La configuración pg_stat_statements.track, que controla las instrucciones que la extensión cuenta, se establece de manera predeterminada en top, lo que significa que se realiza el seguimiento de todas las instrucciones que los clientes emiten directamente. Los otros dos niveles de seguimiento son none y all. Esta configuración se puede configurar como parámetro de servidor.
Hay un equilibrio entre la información de ejecución de consultas que pg_stat_statements proporciona y el efecto en el rendimiento del servidor al registrar cada instrucción SQL. Si no usa activamente la extensión pg_stat_statements, se recomienda establecer pg_stat_statements.track en none. Algunos servicios de supervisión de terceros pueden depender de pg_stat_statements para ofrecer información de rendimiento de consultas, así que confirme si este es el caso para usted o no.
postgres_fdw
postgres_fdw permite conectarse desde una instancia de servidor flexible de Azure Database for PostgreSQL a otra o a otra base de datos del mismo servidor. El servidor flexible de Azure Database for PostgreSQL admite conexiones entrantes y salientes a cualquier servidor PostgreSQL. El servidor de envío debe permitir conexiones de salida al servidor de recepción. Del mismo modo, el servidor de recepción debe permitir conexiones del servidor de envío.
Se recomienda implementar los servidores con integración de red virtual si tiene previsto usar esta extensión. De forma predeterminada, la integración de red virtual permite conexiones entre servidores de la red virtual. También puede elegir usar grupos de seguridad de red de red virtual para personalizar el acceso.
pgstattuple
Al usar la extensión "pgstattuple" para intentar obtener estadísticas de tupla de objetos conservados en el esquema de pg_toast en versiones de Postgres 11 a 13, recibirá un error de "permiso denegado para el esquema pg_toast".
Permiso denegado para el esquema pg_toast
Los clientes que usen las versiones 11 y 13 de PostgreSQL en Azure Database para el servidor flexible no podrán usar la extensión pgstattuple en los objetos que haya dentro del esquema de pg_toast.
En PostgreSQL 16 y 17, el rol de pg_read_all_data se concede automáticamente a azure_pg_admin, lo que permite que pgstattuple funcione correctamente. En PostgreSQL 14 y 15, los clientes pueden conceder manualmente el rol de pg_read_all_data a azure_pg_admin para lograr el mismo resultado. Sin embargo, en PostgreSQL 11 a 13, el rol de pg_read_all_data no existe.
Los clientes no pueden conceder directamente los permisos necesarios. En caso de necesitar ejecutar pgstattuple para acceder a objetos en el esquema de pg_toast, continúe con crear una solicitud de soporte técnico de Azure.
TimescaleDB
TimescaleDB es una base de datos de serie temporal que se empaqueta como una extensión para PostgreSQL. TimescaleDB proporciona funciones analíticas orientadas al tiempo, optimizaciones y escala Postgres para las cargas de trabajo de serie temporal. Más información sobre TimescaleDB, una marca registrada de Timescale, Inc. El servidor flexible de Azure Database for PostgreSQL proporciona la edición Apache-2 de TimescaleDB.
Instalación de TimescaleDB
Para instalar TimescaleDB, además de permitir su enumeración, como se muestra anteriormente, debe incluirlo en las bibliotecas de precarga compartida del servidor. Si cambia el parámetro shared_preload_libraries de Postgres deberá shared_preload_libraries para que tenga efecto. Puede cambiar los parámetros mediante Azure Portal o la CLI de Azure.
Mediante Azure Portal:
- Seleccione la instancia de servidor flexible de Azure Database for PostgreSQL.
- En el menú de recursos, en sección Configuración, seleccione Parámetros del servidor.
- Busque el parámetro
shared_preload_librariesy edite su valor para incluirTimescaleDB. - Seleccione Guardar para conservar los cambios. Ahora, tiene la opción de Guardar y reiniciar. Elija esto para asegurarse de que los cambios surtan efecto, ya que modificar
shared_preload_librariesrequiere un reinicio del servidor. Ahora puede habilitar TimescaleDB en su base de datos del servidor flexible de Azure Database for PostgreSQL. Conéctese a la base de datos y ejecute el comando siguiente:
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
Sugerencia
Si ve un error, confirme que ha reiniciado el servidor después de guardar shared_preload_libraries.
Ahora puede crear una hipertabla de TimescaleDB desde cero o migrar datos de serie temporal existentes en PostgreSQL.
Restauración de una base de datos de Timescale mediante pg_dump y pg_restore
Para restaurar una base de datos de Timescale mediante pg_dump y pg_restore, tiene que ejecutar dos procedimientos auxiliares en la base de datos de destino: timescaledb_pre_restore() y timescaledb_post restore().
Primero prepare la base de datos de destino:
--create the new database where you want to perform the restore
CREATE DATABASE tutorial;
\c tutorial --connect to the database
CREATE EXTENSION timescaledb;
SELECT timescaledb_pre_restore();
Ahora puede ejecutar pg_dump en la base de datos original y, a continuación, pg_restore. Después de la restauración, asegúrese de ejecutar el siguiente comando en la base de datos restaurada:
SELECT timescaledb_post_restore();
Para obtener más información sobre el método de restauración con la base de datos habilitada para escala temporal, consulte documentación de Timescale.
Restauración de una base de datos de escala de tiempo mediante timescaledb-backup
Al ejecutar el procedimiento SELECT timescaledb_post_restore() mencionado anteriormente, es posible que se denieguen permisos al actualizar la marca timescaledb.restoring. Esto se debe a un permiso ALTER DATABASE limitado en los servicios de base de datos PaaS en la nube. En este caso, puede usar un método alternativo mediante la herramienta timescaledb-backup para hacer una copia de seguridad y restaurar la base de datos de escala de tiempo. Timescaledb-backup es un programa para facilitar el volcado y la restauración de una base de datos de TimescaleDB, que sean menos propensos a errores y mejorar el rendimiento.
Para ello, debe hacer lo siguiente
- Instale las herramientas como se detalla aquí.
- Creación de una instancia y base de datos de destino de servidor flexible de Azure Database for PostgreSQL
- Habilite la extensión de escala de tiempo como se ha mostrado anteriormente.
- Conceda el rol
azure_pg_adminal usuario que usará ts-restore. - Ejecute ts-restore para restaurar la base de datos
Aquí puede obtener más información sobre estas utilidades.
Extensiones y actualización de versión principal
El servidor flexible de Azure Database for PostgreSQL ha introducido la característica de actualización local de versiones principales localesque realiza una actualización local de la instancia de servidor flexible de Azure Database for PostgreSQL con un solo clic. La actualización de la versión principal local simplifica el proceso de actualización del servidor flexible de Azure Database for PostgreSQL, lo que minimiza la interrupción de los usuarios y las aplicaciones que acceden al servidor. La actualización de la versión principal local no admite extensiones específicas y hay algunas limitaciones para actualizar determinadas extensiones. Las extensiones anon, Apache AGE, dblink, orafce, pgaudit, postgres_fdw, y Timescaledb no son compatibles con todas las versiones de servidor flexible de Azure Database for PostgreSQL al usar característica de actualización de versión principal local.