Migración de una base de datos de PostgreSQL mediante volcado y restauración
SE APLICA A:  Azure Database for PostgreSQL con servidor único Azure Database for PostgreSQL: servidor flexible
Azure Database for PostgreSQL con servidor único Azure Database for PostgreSQL: servidor flexible
Puede usar pg_dump para extraer una base de datos de PostgreSQL en un archivo de volcado. El método para restaurar la base de datos depende del formato de volcado que elija. Si el volcado se realiza sin formato (que es el valor -Fp predeterminado, por lo que no debe especificarse ninguna opción concreta), la única opción para restaurarlo es mediante psql, ya que genera un archivo de texto sin formato. Para los otros tres métodos de volcado (personalizado, directorio y tar), debe utilizarse pg_restore.
Importante
Las instrucciones y comandos que se proporcionan en este artículo están diseñados para ejecutarse en terminales Bash. Esto incluye entornos como el Subsistema de Windows para Linux (WSL), Azure Cloud Shell y otras interfaces compatibles con Bash. Asegúrese de usar un terminal de Bash para seguir los pasos y ejecutar los comandos detallados en esta guía. El uso de un tipo de entorno de shell o terminal distinto puede dar lugar a diferencias en el comportamiento de los comandos y es posible que no genere los resultados previstos.
En este artículo, nos centramos en los formatos simple (predeterminado) y de directorio. El formato de directorio es útil, ya que permite usar varios núcleos para el procesamiento, lo que puede mejorar significativamente la eficacia, sobre todo para bases de datos de gran tamaño.
Azure Portal simplifica este proceso mediante la hoja de conexión al ofrecer comandos preconfigurados que se adaptan a su servidor, con valores que se sustituyen por los datos de usuario. Es importante tener en cuenta que la hoja de conexión solo está disponible para el servidor flexible de Azure Database for PostgreSQL y no para el servidor único. A continuación, se indica cómo utilizar esta característica:
Acceda a Azure Portal: en primer lugar, vaya a Azure Portal y elija la hoja de conexión.

Seleccione la base de datos: en la hoja de conexión, encontrará una lista desplegable de sus bases de datos. Seleccione la base de datos de la que quiere realizar un volcado.

Elija el método adecuado: según el tamaño de la base de datos, puede elegir entre dos métodos:
pg_dumpypsql: con un solo archivo de texto: ideal para bases de datos más pequeñas, esta opción utiliza un único archivo de texto para el proceso de volcado y restauración.pg_dumpypg_restore: con varios núcleos: para bases de datos más grandes, este método es más eficaz, ya que usa varios núcleos para controlar el proceso de volcado y restauración.
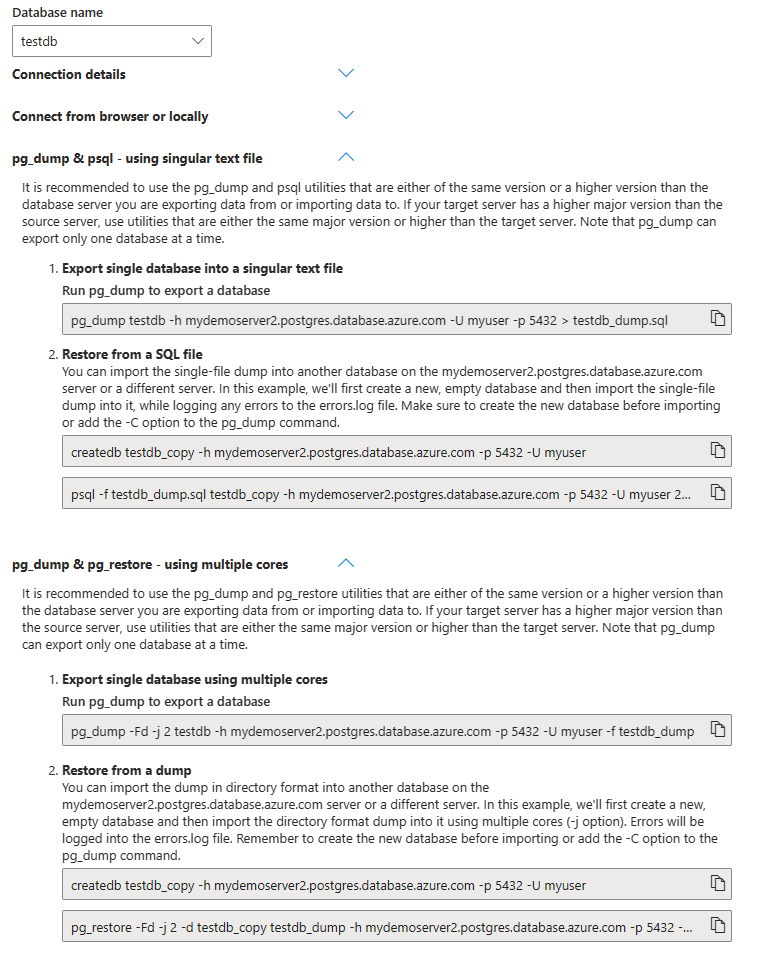
Comandos para copiar y pegar: el portal le proporciona los comandos
pg_dumpypsqlopg_restorelistos para usar. Estos comandos incluyen valores que ya se han sustituido en función del servidor y la base de datos que haya elegido. Copie y pegue estos comandos.



Requisitos previos
Si usa un único servidor o no tiene acceso al portal del servidor flexible, lea esta página de la documentación. Contiene información similar a la que se presenta en la hoja de conexión para el servidor flexible en el portal.
Nota:
Dado que las utilidades pg_dump, psql, pg_restore y pg_dumpall se basan en libpq, puede usar cualquiera de las variables de entorno admitidas que le ofrece o puede usar el archivo de contraseña para evitar que se le solicite la contraseña cada vez que ejecute cualquiera de estos comandos.
Para seguir esta guía, necesitará:
- Un servidor de Azure Database for PostgreSQL que incluya reglas de firewall para permitir el acceso.
- pg_dump, psql, pg_restore y pg_dumpall en caso de que quiera migrar con roles y permisos, utilidades de línea de comandos instaladas.
- Decidir la ubicación del volcado: elija el lugar desde el que quiere realizar el volcado. Se puede hacer desde varias ubicaciones, como una máquina virtual independiente, Cloud Shell (donde las utilidades de la línea de comandos ya están instaladas, pero puede que no tengan la versión adecuada, por lo que debe comprobar siempre la versión, por ejemplo, con
psql --version) o su propio portátil. Tenga siempre en cuenta la distancia y la latencia entre el servidor de PostgreSQL y la ubicación desde la que se ejecuta el volcado o la restauración.
Importante
Es fundamental usar las utilidades pg_dump, psql, pg_restore y pg_dumpall con la misma versión principal o una versión principal superior a la del servidor de bases de datos al que exporta datos o desde el que los importa. En caso contrario, la migración de los datos puede ser incorrecta. Si el servidor de destino tiene una versión principal superior a la del servidor de origen, use utilidades con la misma versión principal que el servidor de destino o una superior.
Nota:
Es importante tener en cuenta que pg_dump solo puede exportar una base de datos a la vez. Esta limitación se aplica independientemente del método que haya elegido, ya sea con un solo archivo o varios núcleos.
Volcado de usuarios y roles con pg_dumpall -r
pg_dump se usa para extraer una base de datos de PostgreSQL en un archivo de volcado. Sin embargo, es fundamental comprender que pg_dumpno realiza un volcado de roles ni de definiciones de usuario, ya que estos se consideran objetos globales dentro del entorno de PostgreSQL. Para una migración exhaustiva que incluya usuarios y roles debe utilizar pg_dumpall -r.
Este comando permite capturar toda la información de roles y usuarios del entorno de PostgreSQL. Si va a realizar una migración en bases de datos del mismo servidor, no dude en omitir este paso y avanzar a la sección Creación de una base de datos.
pg_dumpall -r -h <server name> -U <user name> > roles.sql
Por ejemplo, si tiene un servidor denominado mydemoserver y un usuario denominado myuser, ejecute el siguiente comando:
pg_dumpall -r -h mydemoserver.postgres.database.azure.com -U myuser > roles.sql
Si usa un único servidor, el nombre de usuario incluye el componente de nombre de servidor. Por lo tanto, en lugar de myuser, use myuser@mydemoserver.
Volcado de roles desde un servidor flexible
En un entorno de servidor flexible, las medidas de seguridad mejoradas significan que los usuarios no tienen acceso a la tabla pg_authid, que es donde se almacenan las contraseñas de rol. Esta restricción afecta a cómo se realiza un volcado de roles, ya que el comando pg_dumpall -r estándar intenta acceder a esta tabla para las contraseñas y genera un error debido a la falta de permiso.
Al volcar roles desde un servidor flexible, es fundamental incluir la opción --no-role-passwords en el comando pg_dumpall. Esta opción impide que pg_dumpall intente acceder a la tabla pg_authid, que no puede leer debido a las restricciones de seguridad.
Para volcar correctamente los roles desde un servidor flexible, utilice el siguiente comando:
pg_dumpall -r --no-role-passwords -h <server name> -U <user name> > roles.sql
Por ejemplo, si tiene un servidor denominado mydemoserver y un usuario denominado myuser, ejecute el siguiente comando:
pg_dumpall -r --no-role-passwords -h mydemoserver.postgres.database.azure.com -U myuser > roles.sql
Limpieza del volcado de roles
Al migrar el archivo de salida roles.sql, puede que se incluyan ciertos roles y atributos que no son aplicables al nuevo entorno o que no se permiten en este. Debe tener en cuenta lo siguiente:
Quitar atributos que solo pueden establecer los superusuarios: si se migra a un entorno en el que no tiene privilegios de superusuario, quite atributos como
NOSUPERUSERyNOBYPASSRLSdel volcado de roles.Excluir usuarios específicos de un servicio: excluya los usuarios del servicio de servidor único, como
azure_superuseroazure_pg_admin. Son específicos del servicio y se crearán de forma automática en el nuevo entorno.
Use el comando sed siguiente para limpiar el volcado de roles:
sed -i '/azure_superuser/d; /azure_pg_admin/d; /azuresu/d; /^CREATE ROLE replication/d; /^ALTER ROLE replication/d; /^ALTER ROLE/ {s/NOSUPERUSER//; s/NOBYPASSRLS//;}' roles.sql
Este comando elimina las líneas que contienen azure_superuser, azure_pg_admin, azuresu, las líneas que empiezan por CREATE ROLE replication y ALTER ROLE replication, y quita los atributos NOSUPERUSER y NOBYPASSRLS de las instrucciones ALTER ROLE.
Creación de un archivo de volcado con los datos que se van a cargar
Para exportar la base de datos de PostgreSQL existente en el entorno local o en una máquina virtual a un archivo de script de SQL, ejecute el siguiente comando en el entorno existente:
pg_dump <database name> -h <server name> -U <user name> > <database name>_dump.sql
Por ejemplo, si tiene un servidor denominado mydemoserver, un usuario denominado myuser y una base de datos denominada testdb, ejecute el siguiente comando:
pg_dump testdb -h mydemoserver.postgres.database.azure.com -U myuser > testdb_dump.sql
Si usa un único servidor, el nombre de usuario incluye el componente de nombre de servidor. Por lo tanto, en lugar de myuser, use myuser@mydemoserver.
Restauración de los datos en la base de datos de destino
Restauración de roles y usuarios
Antes de restaurar los objetos de base de datos, asegúrese de haber volcado y limpiado los roles correctamente. Si va a realizar una migración en bases de datos de un mismo servidor, puede que no sea necesario volcar los roles y restaurarlos. Sin embargo, para las migraciones entre distintos servidores o entornos, este paso es fundamental.
Para restaurar los roles y los usuarios en la base de datos de destino, use el siguiente comando:
psql -f roles.sql -h <server_name> -U <user_name>
Reemplace <server_name> por el nombre del servidor de destino y <user_name> por su nombre de usuario. Este comando usa la utilidad psql para ejecutar los comandos SQL contenidos en el archivo roles.sql, que restaura eficazmente los roles y los usuarios en la base de datos de destino.
Por ejemplo, si tiene un servidor denominado mydemoserver y un usuario denominado myuser, ejecute el siguiente comando:
psql -f roles.sql -h mydemoserver.postgres.database.azure.com -U myuser
Si usa un único servidor, el nombre de usuario incluye el componente de nombre de servidor. Por lo tanto, en lugar de myuser, use myuser@mydemoserver.
Nota:
Si ya tiene usuarios con los mismos nombres en el servidor único o en el servidor local desde el que va a migrar y en el servidor de destino, tenga en cuenta que este proceso de restauración puede cambiar las contraseñas de estos roles. Por lo tanto, cualquier comando posterior que deba ejecutar puede requerir las contraseñas actualizadas. Esto no es aplicable si el servidor de origen es un servidor flexible, ya que este tipo de servidor no permite el volcado de contraseñas para los usuarios debido a la mejora de las medidas de seguridad.
Cree una nueva base de datos
Antes de restaurar la base de datos, puede que tenga que crear una base de datos nueva y vacía. Para ello, el usuario que utiliza debe tener el permiso CREATEDB. Estos son dos métodos de uso común:
Uso de la utilidad
createdbEl programacreatedbpermite la creación de bases de datos directamente desde la línea de comandos de Bash, sin necesidad de iniciar sesión en PostgreSQL ni de dejar el entorno del sistema operativo. Por ejemplo:createdb <new database name> -h <server name> -U <user name>Por ejemplo, si tiene un servidor denominado
mydemoserver, un usuario denominadomyusery la base de datos nueva que quiere crear estestdb_copy, ejecute el siguiente comando:createdb testdb_copy -h mydemoserver.postgres.database.azure.com -U myuserSi usa un único servidor, el nombre de usuario incluye el componente de nombre de servidor. Por lo tanto, en lugar de
myuser, usemyuser@mydemoserver.Uso del comando SQL Para crear una base de datos mediante un comando SQL, debe conectarse al servidor de PostgreSQL a través de una interfaz de línea de comandos o una herramienta de administración de bases de datos. Una vez que se haya conectado, puede usar el siguiente comando SQL para crear una base de datos:
CREATE DATABASE <new database name>;
Reemplace <new database name> por el nombre que quiere asignar a la base de datos nueva. Por ejemplo, para crear una base de datos denominada testdb_copy, el comando sería:
CREATE DATABASE testdb_copy;
Restauración del volcado
Después de haber creado la base de datos de destino, puede restaurar los datos en esta base de datos desde el archivo de volcado. Durante la restauración, registre los errores en un archivo errors.log y compruebe su contenido para ver si hay errores una vez finalizada la restauración.
psql -f <database name>_dump.sql <new database name> -h <server name> -U <user name> 2> errors.log
Por ejemplo, si tiene un servidor denominado mydemoserver, un usuario denominado myuser y una nueva base de datos denominada testdb_copy, ejecute el siguiente comando:
psql -f testdb_dump.sql testdb_copy -h mydemoserver.postgres.database.azure.com -U myuser 2> errors.log
Comprobación posterior a la restauración
Una vez completado el proceso de restauración, es importante revisar el archivo errors.log para ver si se han producido errores. Este paso es fundamental para garantizar la integridad y la exhaustividad de los datos restaurados. Solucione cualquier problema que encuentre en el archivo de registro para mantener la confiabilidad de la base de datos.
Optimización del proceso de migración
Al trabajar con bases de datos de gran tamaño, el proceso de volcado y restauración puede durar bastante y requerir optimización para garantizar su eficacia y confiabilidad. Es importante tener en cuenta los distintos factores que pueden afectar al rendimiento de estas operaciones y tomar medidas para optimizarlas.
Para obtener instrucciones detalladas sobre cómo optimizar el proceso de volcado y restauración, consulte el artículo Procedimientos recomendados para pg_dump y pg_restore. Este recurso proporciona información exhaustiva y estrategias que pueden ser beneficiosas para tratar bases de datos de gran tamaño.
Pasos siguientes
- Procedimientos recomendados para pg_dump y pg_restore.
- Para obtener más información sobre cómo migrar bases de datos a Azure Database for PostgreSQL, vea la Guía de migración de base de datos.