¿Qué es la recuperación ante desastres?
Una catástrofe es un acontecimiento único y grave con un impacto mayor y más duradero que el que una aplicación puede mitigar mediante la parte de alta disponibilidad de su diseño. La recuperación ante desastres (DR) consiste en recuperarse de eventos de alto impacto, como desastres naturales o implementaciones con errores, lo que produce tiempo de inactividad y pérdida de datos. Independientemente de la causa, el mejor remedio para un desastre es un plan de recuperación ante desastres bien definido y probado y un diseño de aplicaciones que apoye activamente la recuperación ante desastres.
Objetivos de recuperación
Un plan de recuperación ante desastres completo debe especificar los siguientes requisitos empresariales críticos para cada proceso que implementa la aplicación:
Objetivo de punto de recuperación (RPO): duración máxima de la pérdida de datos que resulta aceptable. El RPO se mide en unidades de tiempo, no en volumen, como "30 minutos de datos" o "cuatro horas de datos". El RPO trata de limitar y recuperarse de la pérdida de datos, no del robo de datos.
Objetivo de tiempo de recuperación (RTO): duración máxima del tiempo de inactividad aceptable, donde "tiempo de inactividad" se define según sus propias especificaciones. Por ejemplo, si la duración del tiempo de inactividad aceptable es de ocho horas en caso de desastre, entonces el RTO es de ocho horas.
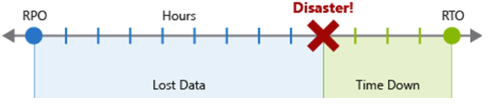
Cada proceso o carga de trabajo principal que implementa una aplicación debe tener valores de RPO y RTO independientes mediante el examen de los riesgos del escenario de desastres y las posibles estrategias de recuperación. El proceso de especificar un RPO y RTO crea eficazmente requisitos de recuperación ante desastres para la aplicación como resultado de sus preocupaciones empresariales únicas (costos, impacto, pérdida de datos, etc.).
Diseño de la recuperación ante desastres
La recuperación ante desastres no es una característica automática, pero debe diseñarse, compilarse y probarse. Para admitir una estrategia sólida de recuperación ante desastres, debe compilar una aplicación teniendo en cuenta la recuperación ante desastres desde el principio. Azure ofrece servicios, características e instrucciones para ayudarle a admitir la recuperación ante desastres al crear aplicaciones.
Recuperación de datos
Durante un desastre, hay dos métodos principales para restaurar datos: copias de seguridad y replicación.
La copia de seguridad restaura los datos a un momento dado específico. Mediante la copia de seguridad, puede proporcionar soluciones sencillas, seguras y rentables para realizar copias de seguridad y recuperar los datos en la nube de Microsoft Azure. Use Azure Backup para crear instantáneas de datos de solo lectura de larga duración para su uso en la recuperación.
La replicación de datos crea copias en tiempo real o casi en tiempo real de datos activos en varias réplicas de almacén de datos teniendo en cuenta una pérdida de datos mínima. El objetivo de la replicación es mantener las réplicas sincronizadas con la menor latencia posible al tiempo que se mantiene la capacidad de respuesta de la aplicación. La mayoría de los sistemas de base de datos con características completas y otros productos y servicios de almacenamiento de datos incluyen algún tipo de replicación como una característica estrechamente integrada debido a sus requisitos funcionales y de rendimiento. Un ejemplo de esto es almacenamiento con redundancia geográfica (GRS).
Los distintos diseños de replicación establecen distintas prioridades en cuanto a costo, rendimiento y coherencia de los datos.
La replicación activa requiere que las actualizaciones se realicen en varias réplicas al mismo tiempo, lo que garantiza la coherencia, a costa del rendimiento.
La replicación pasiva realiza la sincronización en segundo plano, lo que evita que la replicación sea una restricción en el rendimiento de la aplicación pero aumenta el RPO.
La replicación activa-activa o multimaestro permite usar varias réplicas simultáneamente, lo que permite equilibrar la carga a costa de complicar la coherencia de los datos.
La replicación activa-pasiva reserva réplicas para su uso activo solo durante la conmutación por error.
Nota:
La mayoría de los sistemas de base de datos completos y otros productos y servicios de almacenamiento de datos incluyen algún tipo de replicación, como el almacenamiento con redundancia geográfica (GRS), debido a sus requisitos funcionales y de rendimiento.
Compilar aplicaciones resistentes
Las situaciones de desastre también suelen provocar tiempos de inactividad, ya sea por problemas de conectividad de la red, interrupciones en el centro de datos o daños en las máquinas virtuales (VM) o las implementaciones de software. En la mayoría de los casos, la recuperación de aplicaciones implica la conmutación por error a una implementación de trabajo independiente. Como resultado, puede ser necesario recuperar procesos en otra región de Azure en caso de un desastre a gran escala. Otras consideraciones pueden incluir: ubicaciones de recuperación, número de entornos replicados y cómo mantener estos entornos.
En función del diseño de la aplicación, puede usar varias estrategias y características de Azure diferentes, como Azure Site Recovery, para mejorar la compatibilidad de la aplicación con la recuperación de procesos después de un desastre.
Características de recuperación ante desastres específicas del servicio
La mayoría de los servicios que se ejecutan en ofertas de plataforma como servicio (PaaS) de Azure, como App de Azure Service, proporcionan características e instrucciones para admitir la recuperación ante desastres. En determinados casos, puede usar características específicas del servicio para posibilitar una recuperación rápida. Por ejemplo, Azure SQL Server admite la replicación geográfica para restaurar rápidamente el servicio en otra región. Azure App Service tiene una característica de copia de seguridad y restauración, y la documentación incluye instrucciones para usar Azure Traffic Manager para poder enrutar el tráfico a una región secundaria.