Principios y preparación de la recuperación ante desastres
En este artículo, trataremos principios importantes de recuperación ante desastres (DR) para HANA (instancias grandes) (lo que también se conoce como infraestructura BareMetal). Recorreremos los pasos que debe seguir para preparar la recuperación ante desastres. También verá cómo lograr el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO) en caso de desastre.
Principios de recuperación ante desastres para HANA (instancias grandes)
HANA (instancias grandes) ofrece una funcionalidad de recuperación ante desastres entre sus stamps de diferentes regiones de Azure. Por ejemplo, supongamos que implementa HANA (instancias grandes) en la región Oeste de EE. UU. de Azure. Puede usar entonces HANA (instancias grandes) en la región Este de EE. UU. como unidades de recuperación ante desastres. La recuperación ante desastres no se configura automáticamente, ya que es necesario pagar por otra unidad de HANA (instancias grandes) en la región de la recuperación ante desastres. El programa de instalación de la recuperación ante desastres funciona tanto en configuraciones de escalado vertical como de escalado horizontal.
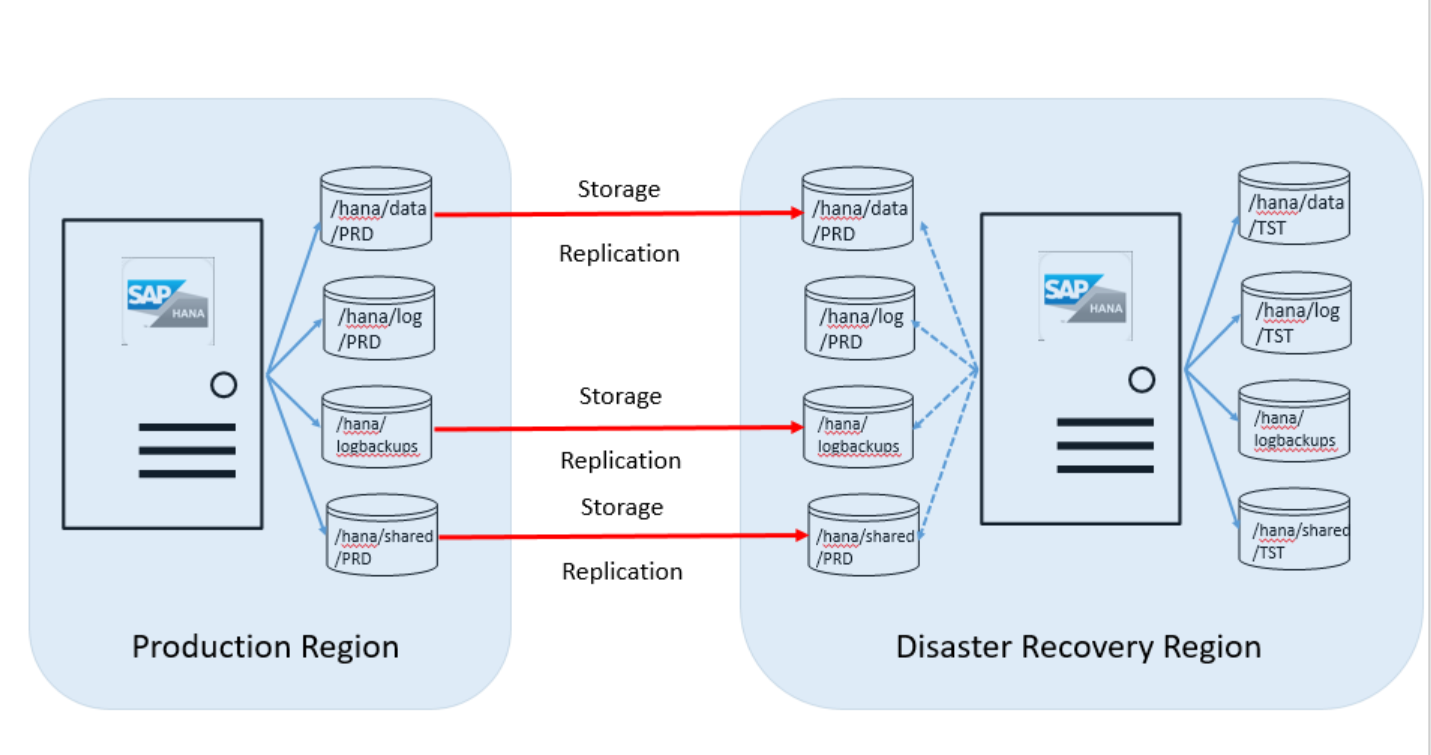
La mayoría de los clientes usan la unidad de la región de recuperación ante desastres para ejecutar sistemas que no son de producción que usan instancias instaladas de HANA. La unidad de HANA (instancias grandes) debe tener la misma SKU que la que se usa con fines de producción. La siguiente imagen muestra cómo es la configuración de discos entre la unidad del servidor de la región de producción de Azure y la región de recuperación ante desastres:
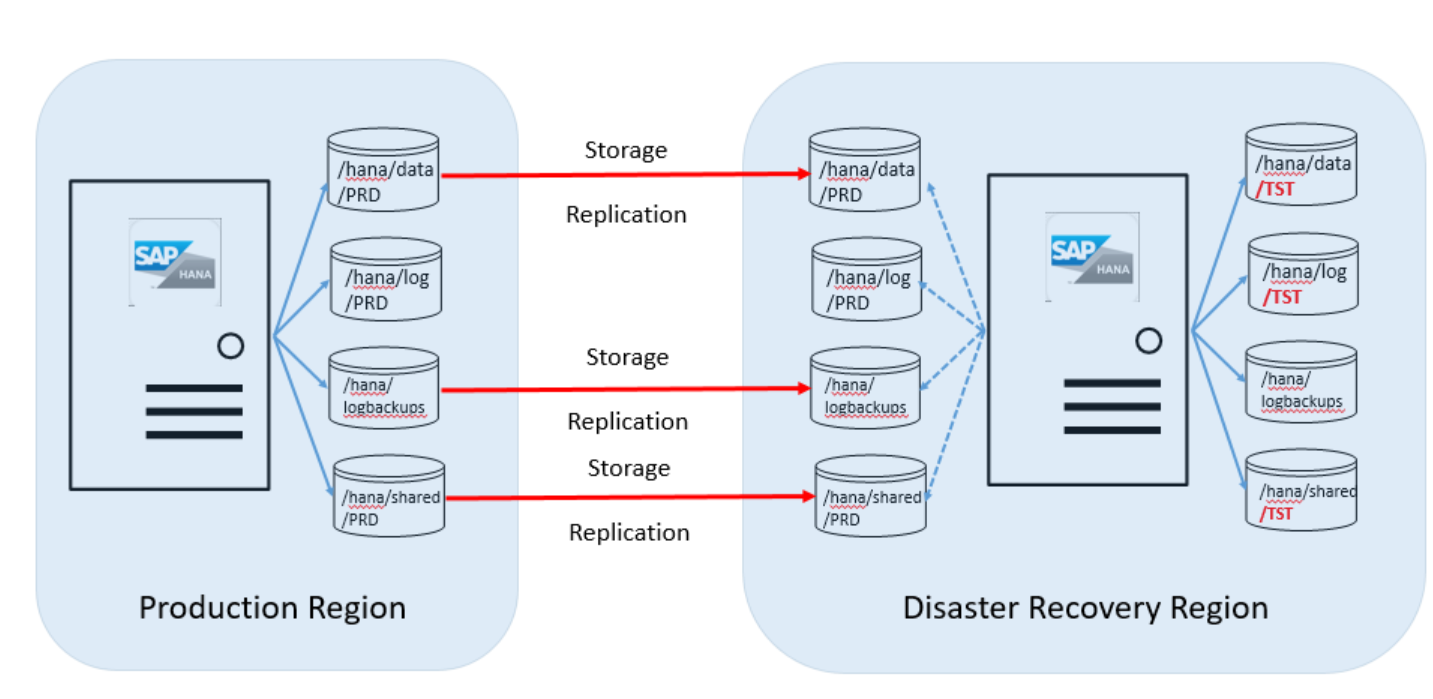
Como se muestra en este gráfico de información general, deberá solicitar un segundo conjunto de volúmenes de disco. Los volúmenes de disco de destino asociados al servidor de HANA (instancias grandes) en el sitio de recuperación ante desastres tienen el mismo tamaño que los volúmenes de producción.
Los siguientes volúmenes se replican desde la región de producción al sitio de recuperación ante desastres:
- /hana/data
- /hana/logbackups
- /hana/shared (incluye /usr/sap)
El volumen /hana/log no se replica. El registro de transacciones de SAP HANA no es necesario al realizar la restauración desde esos volúmenes.
Replicación de almacenamiento de HANA (instancias grandes)
La base de la funcionalidad de recuperación ante desastres en la infraestructura de HANA (instancias grandes) es la replicación de su almacenamiento. La funcionalidad que se usa en el almacenamiento no es un flujo constante de los cambios que se replican de manera asincrónica a medida que se realizan los cambios en el volumen de almacenamiento. En cambio, se trata de un mecanismo que se basa en la creación de instantáneas de estos volúmenes de manera periódica. La diferencia entre una instantánea ya replicada y una instantánea nueva que aún no se ha replicado se transfiere al sitio de recuperación ante desastres en los volúmenes de disco de destino. Estas instantáneas se almacenan en los volúmenes. Si hay una conmutación por error de recuperación ante desastres, se debe restaurar en esos volúmenes.
La primera transmisión de los datos completos del volumen debe suceder antes de que la cantidad de datos sea menor que las diferencias entre las instantáneas. Por lo tanto, los volúmenes del sitio de recuperación ante desastres contendrán todas las instantáneas de volumen tomadas en el sitio de producción. Eventualmente, puede usar ese sistema de recuperación ante desastres para ir a un estado anterior con el fin de recuperar los datos perdidos sin tener que revertir el sistema de producción.
Si hay una implementación MCOD con varias instancias de SAP HANA independientes en una unidad de HANA (instancias grandes), todas las instancias de SAP HANA tendrán el almacenamiento replicado en el lado de recuperación ante desastres.
Cuando se usa la replicación del sistema HANA para conseguir alta disponibilidad en el sitio de producción, y se usa la replicación basada en almacenamiento en el sitio de recuperación ante desastres, se replican los volúmenes de ambos nodos desde el sitio principal hasta la instancia de recuperación ante desastres. Compre almacenamiento adicional (el mismo tamaño que el nodo principal) en el sitio de recuperación ante desastres para que haya espacio para la replicación desde los nodos principal y secundario hasta dicho sitio.
Nota
La funcionalidad de replicación del almacenamiento de HANA (instancias grandes) refleja y replica las instantáneas de almacenamiento. Si no toma instantáneas de almacenamiento como se describe en Copia de seguridad y restauración, no puede haber replicación en el sitio de recuperación ante desastres. La ejecución de la instantánea de almacenamiento es un requisito previo para la replicación del almacenamiento en el sitio de recuperación ante desastres.
Preparación del escenario de recuperación ante desastres
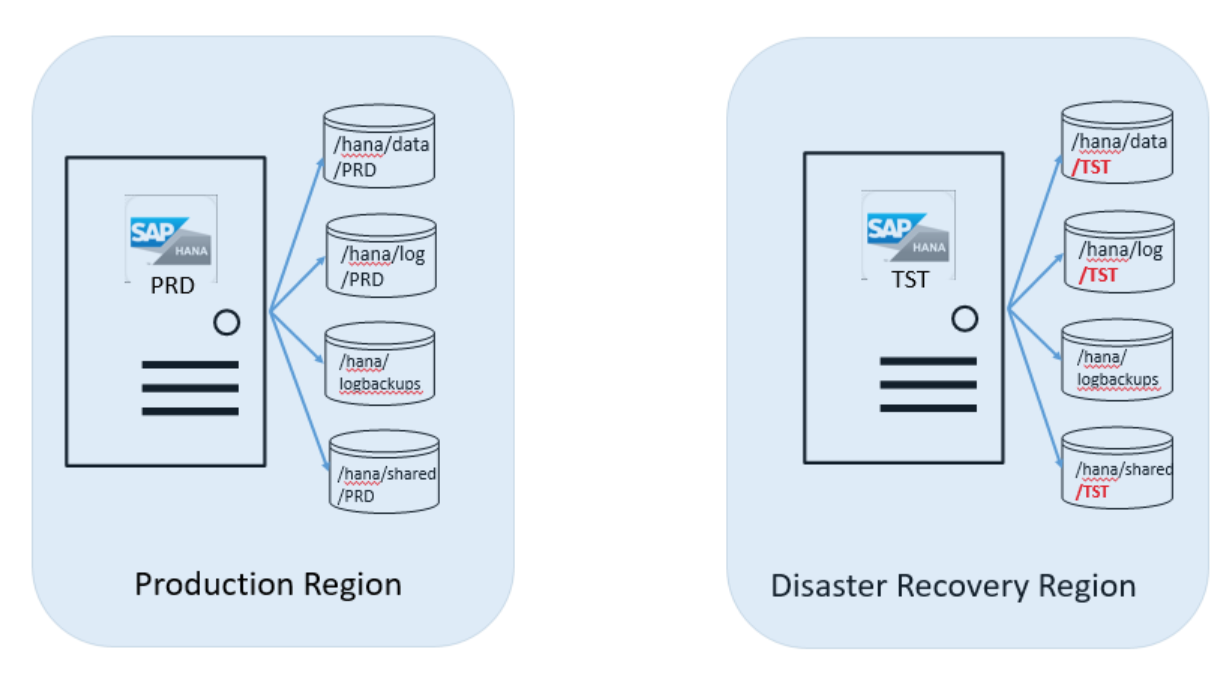
En este escenario, tiene un sistema de producción que se ejecuta en HANA (instancias grandes) en la región de Azure de producción. Para los siguientes pasos, supongamos que el SID del sistema HANA es "PRD" y que tiene un sistema ajeno a la producción que se ejecuta en HANA (instancias grandes) en la región de Azure de recuperación ante desastres. El SID es "TST". La siguiente imagen muestra esta configuración:
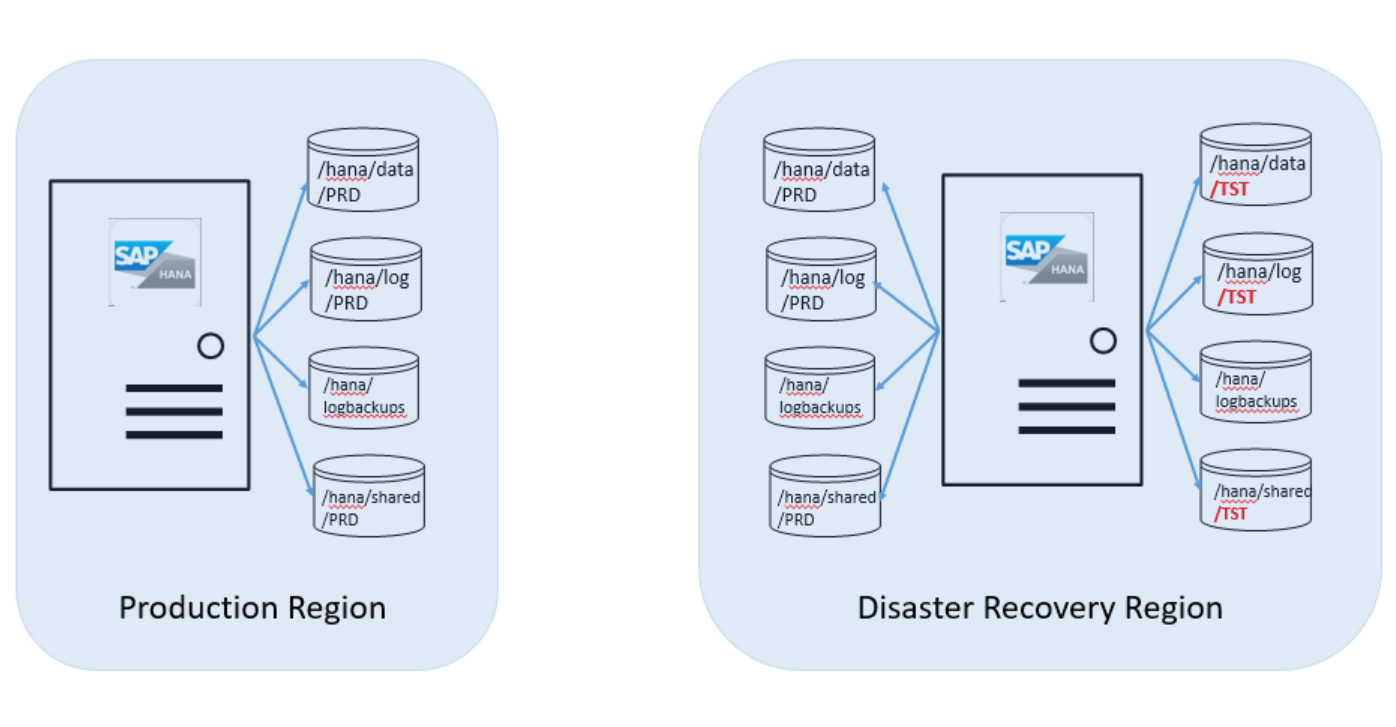
Supongamos que la instancia del servidor aún no se ha pedido con el conjunto de volúmenes de almacenamiento adicional. Por lo tanto, SAP HANA en Azure Service Management asocia los volúmenes agregados. Estos son uno de los destinos de la réplica de producción en la unidad de HANA (instancias grandes) en la que se ejecuta la instancia de HANA TST. Deberá proporcionar el SID de la instancia de HANA de producción. Después de que SAP HANA en Azure Service Management confirme la asociación de esos volúmenes, deberá montarlos en la unidad de HANA (instancias grandes).
El paso siguiente es instalar la segunda instancia de SAP HANA en la unidad de HANA (instancias grandes) de la región de Azure de recuperación ante desastres, donde se ejecuta la instancia de HANA TST. La instancia de SAP HANA recién instalada debe tener el mismo SID. Los usuarios creados deben tener el mismo UID e identificador de grupo que la instancia de producción. Lea Copia de seguridad y restauración para obtener más información. Si la instalación se realizó correctamente, debe hacer lo siguiente:
- Ejecute el paso 2 de la preparación de la instantánea de almacenamiento que se describe en Copia de seguridad y restauración.
- Si aún no lo ha hecho, cree una clave pública para la unidad de recuperación ante desastres de HANA (instancias grandes). Vea el paso 3 de la preparación de la instantánea de almacenamiento que se describe en Copia de seguridad y restauración.
- Conserve el archivo HANABackupCustomerDetails.txt con la nueva instancia de HANA y pruebe si la conectividad en el almacenamiento funciona correctamente.
- Detenga la instancia de SAP HANA que acaba de instalar en la unidad de HANA (instancias grandes) de la región de Azure de recuperación ante desastres.
- Desmontar los volúmenes PRD y ponerse en contacto con SAP HANA en Azure Service Management. Los volúmenes no pueden permanecer montados en la unidad porque no se puede acceder a ellos mientras funcionen como destino de replicación de almacenamiento.
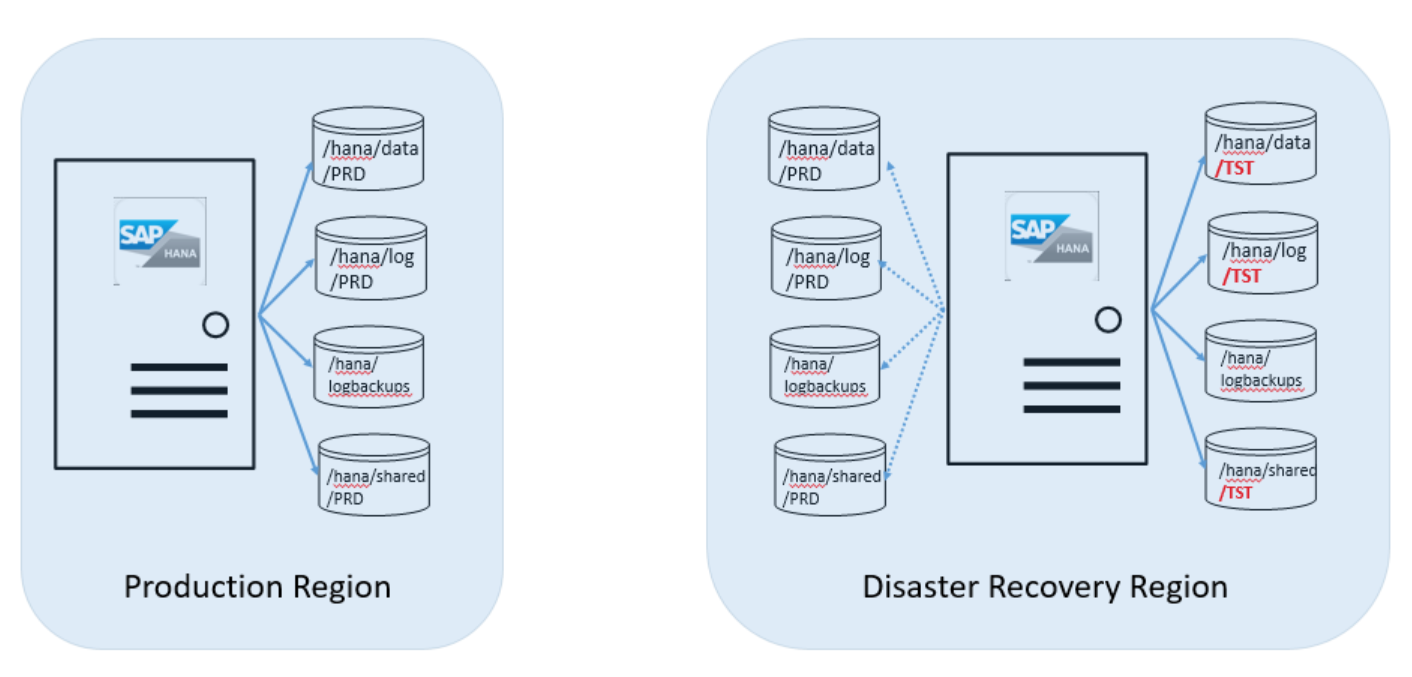
El equipo de operaciones establece la relación de replicación entre los volúmenes PRD de la región de producción y los volúmenes PRD de la región de recuperación ante desastres.
Importante
El volumen /hana/log no se replica porque no es necesario para restaurar la base de datos de SAP HANA replicada a un estado coherente en el sitio de recuperación ante desastres.
A continuación, establezca la programación de copia de seguridad de instantáneas de almacenamiento para lograr el RTO y el RPO si se produce un desastre. Para minimizar el RPO, establezca los siguientes intervalos de replicación en el servicio de HANA (instancias grandes):
- En el caso de los volúmenes que cubre la instantánea combinada (tipo de instantánea hana), establezca que se repliquen cada 15 minutos en los destinos de volúmenes de almacenamiento equivalentes del sitio de recuperación ante desastres.
- En cuanto al volumen de la copia de seguridad del registro de transacciones (tipo de instantánea logs), establezca que se replique cada 3 minutos en los destinos de volúmenes de almacenamiento equivalentes del sitio de recuperación ante desastres.
Para minimizar el RPO:
- Tome una instantánea de almacenamiento de tipo hana cada 30 minutos o 1 hora. Para más información, consulte Copia de seguridad con la herramienta Azure Application Consistent Snapshot.
- Realice copias de seguridad del registro de transacciones de SAP HANA cada 5 minutos.
- Tome una instantánea de almacenamiento de tipo logs cada 5 o 15 minutos. Con este período, se logra un RPO de entre 15 y 25 minutos.
Con esta configuración, la secuencia de copias de seguridad del registro de transacciones, las instantáneas de almacenamiento y la replicación del volumen de copia de seguridad del registro de transacciones de HANA y /hana/data y /hana/log, /hana/shared (incluye /usr/sap) podría ser similar a los datos de este gráfico:
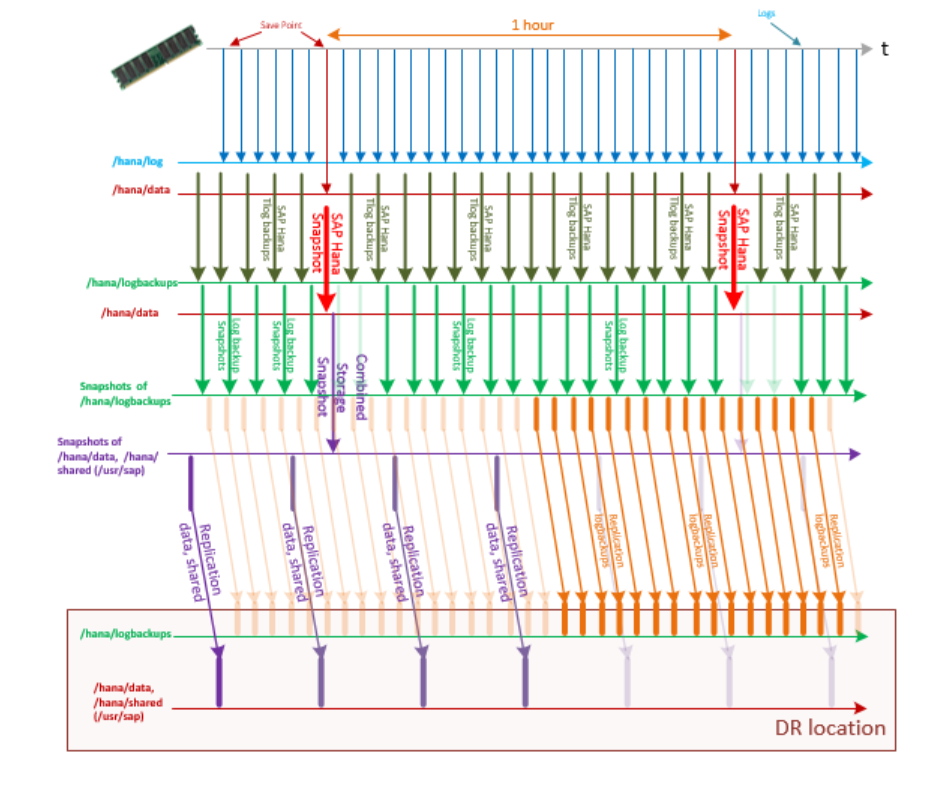
Para conseguir un RPO incluso mejor en caso de recuperación ante desastres, puede copiar las copias de seguridad del registro de transacciones de HANA de SAP HANA en Azure (instancias grandes) a la otra región de Azure. Para conseguir esta reducción adicional del RPO, siga estos pasos:
- Realizar una copia de seguridad del registro de transacciones de HANA tan frecuentemente como sea posible en /hana/logbackups.
- Utilice rsync para copiar las copias de seguridad del registro de transacciones en las máquinas virtuales de Azure hospedadas en el recurso compartido NFS. Las máquinas virtuales (VM) se encuentran en redes virtuales de Azure en la región de producción de Azure y en las regiones de recuperación ante desastres. Conecte ambas redes virtuales de Azure al circuito que conecta la unidad de producción de HANA (instancias grandes) a Azure. Para más información, consulte Consideraciones de red para recuperación ante desastres con instancias grandes de HANA.
- Conserve las copias de seguridad del registro de transacciones en la región de la máquina virtual asociada al almacenamiento exportado de NFS.
- En caso de una conmutación por error ante desastres, complemente las copias de seguridad del registro de transacciones que encuentre en el volumen /hana/logbackups con las copias de seguridad del registro de transacciones creadas más recientemente en el recurso compartido NFS del sitio de recuperación ante desastres.
- Inicie una copia de seguridad del registro de transacciones que se restaure a la copia de seguridad más reciente que se podría guardar en la región de recuperación ante desastres.
Cuando las operaciones de HANA (instancias grandes) confirman la configuración de la relación de replicación y se inician las copias de seguridad de instantáneas del almacenamiento de ejecución, los datos empiezan a replicarse.
A medida que la replicación progresa, las instantáneas de los volúmenes PRD de las regiones de Azure de recuperación ante desastres no se restauran. Las instantáneas solo se almacenan. Si los volúmenes se montan en ese estado, representan el estado en el que se desmontaron esos volúmenes después de que la instancia de SAP HANA PRD se instalara en el servidor en la región de Azure de recuperación ante desastres. También representan las copias de seguridad de almacenamiento que no se han restaurado todavía.
Si hay una conmutación por error, también puede optar por realizar la restauración a una instantánea de almacenamiento más antigua en lugar de a la más reciente.
Pasos siguientes
Aprenda sobre el proceso de conmutación por error en la recuperación ante desastres.