Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe cómo implementar y configurar las máquinas virtuales, y cómo instalar el marco del clúster y un sistema SAP NetWeaver o SAP ABAP de alta disponibilidad. En las configuraciones de ejemplo se usan el número de instancia 00 de ASCS, el número de instancia 02 de ERS y el identificador de sistema de SAP NW1.
Para las nuevas implementaciones de SLES for SAP Applications 15, se recomienda implementar la alta disponibilidad para ASCS/ERS de SAP en una configuración de montaje sencilla. La configuración clásica de Pacemaker, basada en los sistemas de archivos controlados por clústeres para los directorios de servicios centrales de SAP que se describe en este artículo, sigue siendo compatible.
Lea primero las notas y los documentos de SAP siguientes
- Nota de SAP 1928533, que incluye:
- La lista de tamaños de máquina virtual de Azure que se admiten para la implementación del software de SAP
- Información importante sobre la capacidad para los tamaños de máquina virtual de Azure
- Software de SAP admitido y combinaciones de sistema operativo y base de datos
- Versión del kernel de SAP requerida para Windows y Linux en Microsoft Azure
- La nota de SAP 2015553 enumera los requisitos previos para las implementaciones de software de SAP admitidas por SAP en Azure.
- La nota de SAP 2205917 contiene configuraciones recomendadas del sistema operativo para SUSE Linux Enterprise Server para SAP Applications
- La nota de SAP 1944799 contiene guías de SAP HANA para SUSE Linux Enterprise Server para SAP Applications
- La nota de SAP 2178632 contiene información detallada sobre todas las métricas de supervisión notificadas para SAP en Azure.
- La nota de SAP 2191498 incluye la versión de SAP Host Agent necesaria para Linux en Azure.
- La nota de SAP 2243692 incluye información acerca de las licencias de SAP en Linux en Azure.
- La nota de SAP 1984787 incluye información general sobre SUSE Linux Enterprise Server 12.
- La nota de SAP 1999351 contiene más soluciones de problemas de la extensión de supervisión mejorada de Azure para SAP.
- La WIKI de la comunidad SAP contiene todas las notas de SAP que se necesitan para Linux.
- Planeación e implementación de Azure Virtual Machines para SAP en Linux
- Implementación de Azure Virtual Machines para SAP en Linux
- Implementación de DBMS de Azure Virtual Machines para SAP en Linux
- Guías de procedimientos recomendados de SUSE SAP HA Las guías contienen toda la información necesaria para la configuración de Netweaver HA y la replicación del sistema de SAP HANA en el entorno local. Use estas guías como base de referencia general. Proporcionan información mucho más detallada.
- Notas de la versión de la Extensión 12 SP3 de alta disponibilidad para SUSE
Información general
Para lograr alta disponibilidad, SAP NetWeaver requiere un servidor NFS. El servidor NFS está configurado en un clúster distinto y lo pueden usar varios sistemas SAP.
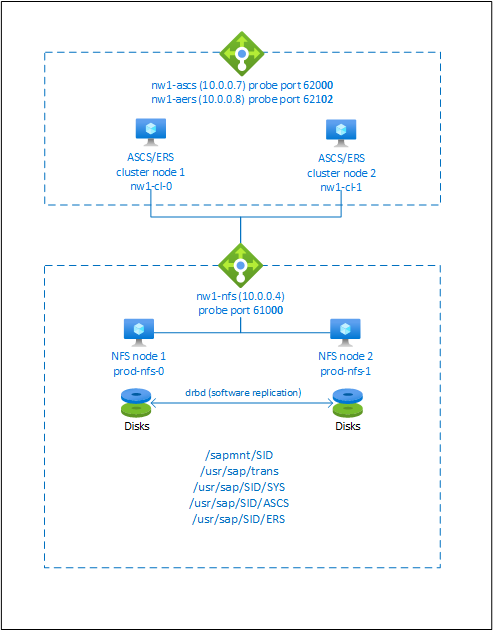
El servidor NFS, SAP NetWeaver ASCS, SAP NetWeaver SCS, SAP NetWeaver ERS y la base de datos SAP HANA usan direcciones IP virtuales y nombre de host virtual. En Azure, se requiere un equilibrador de carga para usar una dirección IP virtual. Se recomienda usar Standard Load Balancer. La configuración presentada muestra un equilibrador de carga con:
- Dirección IP de front-end 10.0.0.7 para ASCS
- Dirección IP de front-end 10.0.0.8 para ERS
- Puerto de sondeo 62000 para ASCS
- Puerto de sondeo 62101 para ERS
Configuración de un servidor NFS de alta disponibilidad
Nota
Se recomienda implementar uno de los servicios NFS propios de Azure: NFS en Azure Files o volúmenes NFS ANF para almacenar datos compartidos en un sistema SAP de alta disponibilidad. Tenga en cuenta que estamos dejando de lado las arquitecturas de referencia de SAP, que usan clústeres NFS.
Las guías de configuración de SAP para el sistema SAP de alta disponibilidad de SAP NW con servicios NFS nativos son:
- SAP NW de alta disponibilidad en máquinas virtuales de Azure con montaje sencillo y NFS en SLES para aplicaciones SAP
- Alta disponibilidad para SAP NW en máquinas virtuales de Azure con NFS en Azure Files en SLES para aplicaciones SAP
- Alta disponibilidad para SAP NW en máquinas virtuales de Azure con NFS en Azure NetApp Files en SLES para aplicaciones SAP
SAP NetWeaver requiere un almacenamiento compartido para el directorio de transporte y perfil. Lea Alta disponibilidad para NFS en máquinas virtuales de Azure en SUSE Linux Enterprise Server para obtener información acerca de cómo configurar un servidor NFS para SAP NetWeaver.
Preparación de la infraestructura
El agente de recursos para SAP Instance se incluye en SUSE Linux Enterprise Server para SAP Applications. En Azure Marketplace se puede encontrar una imagen para SUSE Linux Enterprise Server para SAP Applications 12 o 15. Puede usar la imagen para implementar nuevas máquinas virtuales.
Implementación manual de VM de Linux mediante Azure Portal
Este documento asume que ya ha implementado un grupo de recursos, Azure Virtual Network y una subred.
Implemente máquinas virtuales con SLES para la imagen de SAP Applications. Elija una versión adecuada de la imagen de SLES compatible con el sistema SAP. Puede implementar la máquina virtual en cualquiera de las opciones de disponibilidad: conjunto de escalado de máquinas virtuales, zona de disponibilidad o conjunto de disponibilidad.
Configurar Azure Load Balancer
Durante la configuración de la máquina virtual, tiene una opción para crear o seleccionar salir del equilibrador de carga en la sección de redes. Siga los pasos siguientes para configurar un equilibrador de carga estándar para la configuración de alta disponibilidad de ASCS de SAP y ERS de SAP.
Siga la guía de creación del equilibrador de carga para configurar un equilibrador de carga estándar para un sistema SAP de alta disponibilidad mediante Azure Portal. Durante la configuración del equilibrador de carga, tenga en cuenta los siguientes puntos.
- Configuración de IP de front-end: cree dos direcciones IP de front-end, una para ASCS y otra para ERS. Seleccione la misma red virtual y subred que las máquinas virtuales ASCS/ERS.
- Grupo de back-end: cree un grupo de back-end y agregue máquinas virtuales ASCS y ERS.
-
Reglas de entrada: cree dos reglas de equilibrio de carga, una para ASCS y otra para ERS. Siga los mismos pasos para ambas reglas de equilibrio de carga.
- Dirección IP de front-end: selección de IP de front-end
- Grupo de back-end: selección del grupo de back-end
- Comprobación de "Puertos de alta disponibilidad"
- Protocolo: TCP
- Sondeo de estado: cree un sondeo de estado con los detalles siguientes (se aplica tanto para ASCS como para ERS)
- Protocolo: TCP
- Puerto: [por ejemplo: 620<Instance-no.> para ASCS, 621<Instance-no.> para ERS]
- Intervalo: 5
- Umbral de sondeo: 2
- Tiempo de espera de inactividad (minutos): 30
- Active "Habilitar IP flotante"
Nota
No se respeta la propiedad de configuración del sondeo de estado numberOfProbes, también conocida como "umbral incorrecto" en el Portal. Por lo tanto, para controlar el número de sondeos consecutivos correctos o erróneos, establezca la propiedad "probeThreshold" en 2. Actualmente no es posible establecer esta propiedad mediante Azure Portal, por lo que puede usar la CLI de Azure o el comando de PowerShell.
Nota
Cuando las máquinas virtuales sin direcciones IP públicas se colocan en el grupo de back-end de Standard Load Balancer interno (sin dirección IP pública), no hay conectividad saliente de Internet, a menos que se realice una configuración adicional para permitir el enrutamiento a puntos de conexión públicos. Para obtener más información sobre cómo obtener conectividad saliente, vea Conectividad de punto de conexión público para máquinas virtuales con Azure Standard Load Balancer en escenarios de alta disponibilidad de SAP.
Importante
- No habilite las marcas de tiempo TCP en máquinas virtuales de Azure que se encuentren detrás de Azure Load Balancer. Si habilita las marcas de tiempo TCP provocará un error en los sondeos de estado. Establezca el parámetro
net.ipv4.tcp_timestampsen0. Para más información, consulte Sondeos de estado de Load Balancer. - Para evitar que saptune cambie el valor
net.ipv4.tcp_timestampsestablecido manualmente de0a nuevamente1, debe actualizar la versión de saptune a la versión 3.1.1 o posterior. Para más información, consulte saptune 3.1.1: ¿Necesito actualizar?
Configuración de (A)SCS
A continuación, preparará e instalará las instancias de SAP ASCS y ERS.
Creación del clúster de Pacemaker
Siga los pasos que se describen en Configuración de Pacemaker en SUSE Linux Enterprise Server en Azure para crear un clúster de Pacemaker básico para este servidor (A)SCS.
Instalación
Los elementos siguientes tienen el prefijo [A]: aplicable a todos los nodos, [1]: aplicable solo al nodo 1 o [2]: aplicable solo al nodo 2.
[A] Instale el conector de SUSE
sudo zypper install sap-suse-cluster-connectorNota
El problema conocido con el uso de un guion en los nombres de host se ha corregido con la versión 3.1.1 del paquete sap-suse-cluster-connector. Si utiliza nodos de clúster con un guion en el nombre de host, asegúrese de usar al menos la versión 3.1.1 del paquete sap-suse-cluster-connector. Si lo hace, el clúster no funcionará.
Asegúrese de que instaló la nueva versión del conector de clúster SUSE SAP. La antigua se llamaba sap_suse_cluster_connector y la nueva se llama sap-suse-cluster-connector.
sudo zypper info sap-suse-cluster-connector Information for package sap-suse-cluster-connector: --------------------------------------------------- Repository : SLE-12-SP3-SAP-Updates Name : sap-suse-cluster-connector <b>Version : 3.0.0-2.2</b> Arch : noarch Vendor : SUSE LLC <https://www.suse.com/> Support Level : Level 3 Installed Size : 41.6 KiB <b>Installed : Yes</b> Status : up-to-date Source package : sap-suse-cluster-connector-3.0.0-2.2.src Summary : SUSE High Availability Setup for SAP Products[A] Actualice los agentes de recursos de SAP
Se requiere una revisión del paquete de agentes de recursos para usar la nueva configuración que se describe este artículo. Puede usar el comando siguiente para comprobar si la revisión ya está instalada
sudo grep 'parameter name="IS_ERS"' /usr/lib/ocf/resource.d/heartbeat/SAPInstanceLa salida debe ser similar a
<parameter name="IS_ERS" unique="0" required="0">Si el comando grep no encuentra el parámetro IS_ERS, necesita instalar la revisión que aparece en la página de descarga de SUSE.
# example for patch for SLES 12 SP1 sudo zypper in -t patch SUSE-SLE-HA-12-SP1-2017-885=1 # example for patch for SLES 12 SP2 sudo zypper in -t patch SUSE-SLE-HA-12-SP2-2017-886=1[A] Configure la resolución nombres de host
Puede usar un servidor DNS o modificar /etc/hosts en todos los nodos. En este ejemplo se muestra cómo utilizar el archivo /etc/hosts. Reemplace la dirección IP y el nombre de host en los siguientes comandos.
sudo vi /etc/hosts # Insert the following lines to /etc/hosts. Change the IP address and hostname to match your environment # IP address of the load balancer frontend configuration for NFS 10.0.0.4 nw1-nfs # IP address of the load balancer frontend configuration for SAP NetWeaver ASCS 10.0.0.7 nw1-ascs # IP address of the load balancer frontend configuration for SAP NetWeaver ASCS ERS 10.0.0.8 nw1-aers # IP address of the load balancer frontend configuration for database 10.0.0.13 nw1-db
Preparación de la instalación de SAP NetWeaver
[A] Cree los directorios compartidos
sudo mkdir -p /sapmnt/NW1 sudo mkdir -p /usr/sap/trans sudo mkdir -p /usr/sap/NW1/SYS sudo mkdir -p /usr/sap/NW1/ASCS00 sudo mkdir -p /usr/sap/NW1/ERS02 sudo chattr +i /sapmnt/NW1 sudo chattr +i /usr/sap/trans sudo chattr +i /usr/sap/NW1/SYS sudo chattr +i /usr/sap/NW1/ASCS00 sudo chattr +i /usr/sap/NW1/ERS02[A] Configuración de autofs
sudo vi /etc/auto.master # Add the following line to the file, save and exit +auto.master /- /etc/auto.directCree un archivo con
sudo vi /etc/auto.direct # Add the following lines to the file, save and exit /sapmnt/NW1 -nfsvers=4,nosymlink,sync nw1-nfs:/NW1/sapmntsid /usr/sap/trans -nfsvers=4,nosymlink,sync nw1-nfs:/NW1/trans /usr/sap/NW1/SYS -nfsvers=4,nosymlink,sync nw1-nfs:/NW1/sidsysReinicie autofs para montar los recursos compartidos nuevos
sudo systemctl enable autofs sudo service autofs restart[A] Configure el archivo de intercambio
Cree un archivo de intercambio tal como se define en Creación de un archivo SWAP para una máquina virtual Linux de Azure
#!/bin/sh # Percent of space on the ephemeral disk to dedicate to swap. Here 30% is being used. Modify as appropriate. PCT=0.3 # Location of swap file. Modify as appropriate based on location of ephemeral disk. LOCATION=/mnt if [ ! -f ${LOCATION}/swapfile ] then # Get size of the ephemeral disk and multiply it by the percent of space to allocate size=$(/bin/df -m --output=target,avail | /usr/bin/awk -v percent="$PCT" -v pattern=${LOCATION} '$0 ~ pattern {SIZE=int($2*percent);print SIZE}') echo "$size MB of space allocated to swap file" # Create an empty file first and set correct permissions /bin/dd if=/dev/zero of=${LOCATION}/swapfile bs=1M count=$size /bin/chmod 0600 ${LOCATION}/swapfile # Make the file available to use as swap /sbin/mkswap ${LOCATION}/swapfile fi # Enable swap /sbin/swapon ${LOCATION}/swapfile /sbin/swapon -a # Display current swap status /sbin/swapon -sConversión del archivo en ejecutable.
chmod +x /var/lib/cloud/scripts/per-boot/swap.shDetenga e inicie la VM. La detención e inicio de la máquina virtual solo es necesaria la primera vez que se crea el archivo de intercambio.
Instalación de SAP NetWeaver ASCS/ERS
[1] Cree un recurso IP virtual y un sondeo de estado para la instancia de ASCS
Importante
Pruebas recientes han mostrado situaciones en las que netcat deja de responder a las solicitudes debido al trabajo pendiente y a su limitación para controlar solo una conexión. El recurso netcat deja de escuchar las solicitudes del equilibrador de carga de Azure y la dirección IP flotante deja de estar disponible.
En el caso de los clústeres de Pacemaker existentes, en el pasado se recomendaba reemplazar netcat por socat. Actualmente se recomienda usar el agente de recursos azure-lb, que forma parte de los agentes de recursos de paquetes, con los siguientes requisitos de versión de paquete:- En el caso de SLES 12 SP4/SP5, la versión debe ser, al menos, resource-agents-4.3.018.a7fb5035-3.30.1.
- Para SLES 15/15 SP1, la versión debe ser al menos resource-agents-4.3.0184.6ee15eb2-4.13.1.
Tenga en cuenta que el cambio requerirá un breve tiempo de inactividad.
En el caso de los clústeres de Pacemaker existentes, si la configuración ya se ha cambiado para usar socat, como se describe en Protección de la detección del equilibrador de carga de Azure, no hay ningún requisito para cambiar inmediatamente al agente de recursos de azure-lb.sudo crm node standby nw1-cl-1 sudo crm configure primitive fs_NW1_ASCS Filesystem device='nw1-nfs:/NW1/ASCS' directory='/usr/sap/NW1/ASCS00' fstype='nfs4' \ op start timeout=60s interval=0 \ op stop timeout=60s interval=0 \ op monitor interval=20s timeout=40s sudo crm configure primitive vip_NW1_ASCS IPaddr2 \ params ip=10.0.0.7 \ op monitor interval=10 timeout=20 sudo crm configure primitive nc_NW1_ASCS azure-lb port=62000 \ op monitor timeout=20s interval=10 sudo crm configure group g-NW1_ASCS fs_NW1_ASCS nc_NW1_ASCS vip_NW1_ASCS \ meta resource-stickiness=3000Asegúrese de que el estado del clúster sea el correcto y que se iniciaron todos los recursos. No es importante en qué nodo se ejecutan los recursos.
sudo crm_mon -r # Node nw1-cl-1: standby # Online: [ nw1-cl-0 ] # # Full list of resources: # # stonith-sbd (stonith:external/sbd): Started nw1-cl-0 # Resource Group: g-NW1_ASCS # fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-0 # nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-0 # vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-0[1] Instale SAP NetWeaver ASCS
Instale SAP NetWeaver ASCS como raíz en el primer nodo mediante un nombre de host virtual que se asigna a la dirección IP de la configuración de front-end del equilibrador de carga para ASCS; por ejemplo, nw1-ascs, 10.0.0.7. Especifique también el número de instancia que usó para el sondeo del equilibrador de carga; por ejemplo, 00.
Puede usar el parámetro de sapinst SAPINST_REMOTE_ACCESS_USER para permitir que un usuario no raíz se conecta a sapinst.
sudo <swpm>/sapinst SAPINST_REMOTE_ACCESS_USER=sapadmin SAPINST_USE_HOSTNAME=virtual_hostnameSi se produce un error en la instalación para crear una subcarpeta en/usr/sap/NW1/ASCS00, pruebe a establecer el propietario y el grupo de la carpeta ASCS00 e inténtelo de nuevo.
chown nw1adm /usr/sap/NW1/ASCS00 chgrp sapsys /usr/sap/NW1/ASCS00[1] Cree un recurso IP virtual y un sondeo de estado para la instancia de ERS
sudo crm node online nw1-cl-1 sudo crm node standby nw1-cl-0 sudo crm configure primitive fs_NW1_ERS Filesystem device='nw1-nfs:/NW1/ASCSERS' directory='/usr/sap/NW1/ERS02' fstype='nfs4' \ op start timeout=60s interval=0 \ op stop timeout=60s interval=0 \ op monitor interval=20s timeout=40s sudo crm configure primitive vip_NW1_ERS IPaddr2 \ params ip=10.0.0.8 \ op monitor interval=10 timeout=20 sudo crm configure primitive nc_NW1_ERS azure-lb port=62102 \ op monitor timeout=20s interval=10 sudo crm configure group g-NW1_ERS fs_NW1_ERS nc_NW1_ERS vip_NW1_ERSAsegúrese de que el estado del clúster sea el correcto y que se iniciaron todos los recursos. No es importante en qué nodo se ejecutan los recursos.
sudo crm_mon -r # Node nw1-cl-0: standby # Online: [ nw1-cl-1 ] # # Full list of resources: # # stonith-sbd (stonith:external/sbd): Started nw1-cl-1 # Resource Group: g-NW1_ASCS # fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 # nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 # vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 # Resource Group: g-NW1_ERS # fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-1 # nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-1 # vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-1[2] Instale SAP NetWeaver ERS
Instale SAP NetWeaver ERS como raíz en el segundo nodo mediante un nombre de host virtual que se asigna a la dirección IP de la configuración de front-end del equilibrador de carga para ERS (por ejemplo, nw1-aers, 10.0.0.8) y el número de instancia que usó para el sondeo del equilibrador de carga (por ejemplo, 02).
Puede usar el parámetro de sapinst SAPINST_REMOTE_ACCESS_USER para permitir que un usuario no raíz se conecta a sapinst.
sudo <swpm>/sapinst SAPINST_REMOTE_ACCESS_USER=sapadmin SAPINST_USE_HOSTNAME=virtual_hostnameNota
Use SWPM SP 20 PL 05 o superior. Las versiones inferiores no establecen correctamente los permisos y se producirá un error de instalación.
Si se produce un error en la instalación para crear una subcarpeta en/usr/sap/NW1/ERS00, pruebe a establecer el propietario y el grupo de la carpeta ERS02 e inténtelo de nuevo.
chown nw1adm /usr/sap/NW1/ERS02 chgrp sapsys /usr/sap/NW1/ERS02[1] Adapte los perfiles de instancias ASCS/SCS y ERS
Perfil ASCS/SCS
sudo vi /sapmnt/NW1/profile/NW1_ASCS00_nw1-ascs # Change the restart command to a start command #Restart_Program_01 = local $(_EN) pf=$(_PF) Start_Program_01 = local $(_EN) pf=$(_PF) # Add the following lines service/halib = $(DIR_EXECUTABLE)/saphascriptco.so service/halib_cluster_connector = /usr/bin/sap_suse_cluster_connector # Add the keep alive parameter, if using ENSA1 enque/encni/set_so_keepalive = TRUEEn el caso de ENSA1 y ENSA2, asegúrese de que los parámetros del sistema operativo
keepalivese establecen tal y como se describe en la nota de SAP 1410736.Perfil ERS
sudo vi /sapmnt/NW1/profile/NW1_ERS02_nw1-aers # Change the restart command to a start command #Restart_Program_00 = local $(_ER) pf=$(_PFL) NR=$(SCSID) Start_Program_00 = local $(_ER) pf=$(_PFL) NR=$(SCSID) # Add the following lines service/halib = $(DIR_EXECUTABLE)/saphascriptco.so service/halib_cluster_connector = /usr/bin/sap_suse_cluster_connector # remove Autostart from ERS profile # Autostart = 1
[A] Configure la conexión persistente
La comunicación entre el servidor de aplicaciones de SAP NetWeaver y ASCS/SCS se enruta a través de un equilibrador de carga de software. El equilibrador de carga desconecta las conexiones inactivas después de un tiempo de expiración que se puede configurar. Para evitarlo, tendrá que establecer un parámetro en el perfil de SAP NetWeaver ASCS/SCS, si usa ENSA1, y cambiar la configuración
keepalivedel sistema Linux en todos los servidores SAP para ENSA1 y ENSA2. Para más información, lea la nota de SAP 1410736.# Change the Linux system configuration sudo sysctl net.ipv4.tcp_keepalive_time=300[A] Configure los usuarios de SAP después de la instalación
# Add sidadm to the haclient group sudo usermod -aG haclient nw1adm[1] Agregue los servicios SAP de ASCS y ERS al archivo sapservice
Agregue la entrada del servicio ASCS al segundo nodo y copie la entrada del servicio ERS al primer nodo.
cat /usr/sap/sapservices | grep ASCS00 | sudo ssh nw1-cl-1 "cat >>/usr/sap/sapservices" sudo ssh nw1-cl-1 "cat /usr/sap/sapservices" | grep ERS02 | sudo tee -a /usr/sap/sapservices[A] Deshabilitación de los servicios
systemdde la instancia de SAP de ASCS y ERS. Este paso solo es aplicable, si el marco de inicio de SAP se administra mediante sistema según la nota SAP 3115048Nota
Al administrar instancias de SAP como ASCS de SAP y ERS de SAP mediante la configuración del clúster de SLES, tendría que realizar modificaciones adicionales para integrar el clúster con el marco de inicio de SAP basado en sistema nativo. Esto garantiza que los procedimientos de mantenimiento no pongan en peligro la estabilidad del clúster. Después de instalar o cambiar el marco de inicio de SAP a la configuración habilitada para systemd según la nota SAP 3115048, debe deshabilitar los servicios de
systemdpara las instancias de SAP de ASCS y ERS.# Stop ASCS and ERS instances using <sid>adm sapcontrol -nr 00 -function Stop sapcontrol -nr 00 -function StopService sapcontrol -nr 01 -function Stop sapcontrol -nr 01 -function StopService # Execute below command on VM where you have performed ASCS instance installation (e.g. nw1-cl-0) sudo systemctl disable SAPNW1_00 # Execute below command on VM where you have performed ERS instance installation (e.g. nw1-cl-1) sudo systemctl disable SAPNW1_01[1] Cree los recursos de clúster de SAP
En función de si ejecuta un sistema ENSA1 o ENSA2, seleccione la pestaña correspondiente para definir los recursos. SAP introdujo compatibilidad con ENSA2, incluida la replicación, en SAP NetWeaver 7.52. A partir de la plataforma ABAP 1809, ENSA2 se instala de forma predeterminada. Para información sobre la compatibilidad con ENSA2, consulte la nota de SAP 2630416.
sudo crm configure property maintenance-mode="true" sudo crm configure primitive rsc_sap_NW1_ASCS00 SAPInstance \ operations \$id=rsc_sap_NW1_ASCS00-operations \ op monitor interval=11 timeout=60 on-fail=restart \ params InstanceName=NW1_ASCS00_nw1-ascs START_PROFILE="/sapmnt/NW1/profile/NW1_ASCS00_nw1-ascs" \ AUTOMATIC_RECOVER=false \ meta resource-stickiness=5000 failure-timeout=60 migration-threshold=1 priority=10 sudo crm configure primitive rsc_sap_NW1_ERS02 SAPInstance \ operations \$id=rsc_sap_NW1_ERS02-operations \ op monitor interval=11 timeout=60 on-fail=restart \ params InstanceName=NW1_ERS02_nw1-aers START_PROFILE="/sapmnt/NW1/profile/NW1_ERS02_nw1-aers" AUTOMATIC_RECOVER=false IS_ERS=true \ meta priority=1000 sudo crm configure modgroup g-NW1_ASCS add rsc_sap_NW1_ASCS00 sudo crm configure modgroup g-NW1_ERS add rsc_sap_NW1_ERS02 sudo crm configure colocation col_sap_NW1_no_both -5000: g-NW1_ERS g-NW1_ASCS sudo crm configure location loc_sap_NW1_failover_to_ers rsc_sap_NW1_ASCS00 rule 2000: runs_ers_NW1 eq 1 sudo crm configure order ord_sap_NW1_first_start_ascs Optional: rsc_sap_NW1_ASCS00:start rsc_sap_NW1_ERS02:stop symmetrical=false sudo crm_attribute --delete --name priority-fencing-delay sudo crm node online nw1-cl-0 sudo crm configure property maintenance-mode="false"
Si va a actualizar desde una versión anterior y va a cambiar al servidor 2 de puesta en cola, vea la nota de SAP 2641019.
Asegúrese de que el estado del clúster sea el correcto y que se iniciaron todos los recursos. No es importante en qué nodo se ejecutan los recursos.
sudo crm_mon -r
# Online: [ nw1-cl-0 nw1-cl-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started nw1-cl-1
# Resource Group: g-NW1_ASCS
# fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1
# nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1
# vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1
# rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1
# Resource Group: g-NW1_ERS
# fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0
# nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0
# vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0
# rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0
Preparación del servidor de aplicaciones de SAP NetWeaver
Algunas bases de datos requieren que la instalación de la instancia de base de datos se ejecute en un servidor de aplicaciones. Prepare las máquinas virtuales del servidor de aplicaciones para poder usarlas en estos casos.
En los pasos siguientes, se supone que el servidor de aplicaciones se va a instalar en un servidor que no es ASCS/SCS ni HANA. De lo contrario, no se necesitan algunos de los pasos que aparecen a continuación (como configurar la resolución de nombres de host).
Configuración del sistema operativo
Reduzca el tamaño de la caché de datos incorrectos. Para más información, consulte Low write performance on SLES 11/12 servers with large RAM (Bajo rendimiento de escritura en servidores SLES 11/12 con RAM grande).
sudo vi /etc/sysctl.conf # Change/set the following settings vm.dirty_bytes = 629145600 vm.dirty_background_bytes = 314572800Configure la resolución de nombres de host
Puede usar un servidor DNS o modificar /etc/hosts en todos los nodos. En este ejemplo se muestra cómo utilizar el archivo /etc/hosts. Reemplace la dirección IP y el nombre de host en los siguientes comandos
sudo vi /etc/hostsInserte las siguientes líneas en /etc/hosts. Cambie la dirección IP y el nombre de host para que coincida con su entorno
# IP address of the load balancer frontend configuration for NFS 10.0.0.4 nw1-nfs # IP address of the load balancer frontend configuration for SAP NetWeaver ASCS/SCS 10.0.0.7 nw1-ascs # IP address of the load balancer frontend configuration for SAP NetWeaver ERS 10.0.0.8 nw1-aers # IP address of the load balancer frontend configuration for database 10.0.0.13 nw1-db # IP address of all application servers 10.0.0.20 nw1-di-0 10.0.0.21 nw1-di-1Cree el directorio sapmnt
sudo mkdir -p /sapmnt/NW1 sudo mkdir -p /usr/sap/trans sudo chattr +i /sapmnt/NW1 sudo chattr +i /usr/sap/transConfiguración de autofs
sudo vi /etc/auto.master # Add the following line to the file, save and exit +auto.master /- /etc/auto.directCree un nuevo archivo con
sudo vi /etc/auto.direct # Add the following lines to the file, save and exit /sapmnt/NW1 -nfsvers=4,nosymlink,sync nw1-nfs:/NW1/sapmntsid /usr/sap/trans -nfsvers=4,nosymlink,sync nw1-nfs:/NW1/transReinicie autofs para montar los recursos compartidos nuevos
sudo systemctl enable autofs sudo service autofs restartConfigure el archivo de intercambio
sudo vi /etc/waagent.conf # Set the property ResourceDisk.EnableSwap to y # Create and use swapfile on resource disk. ResourceDisk.EnableSwap=y # Set the size of the SWAP file with property ResourceDisk.SwapSizeMB # The free space of resource disk varies by virtual machine size. Make sure that you do not set a value that is too big. You can check the SWAP space with command swapon # Size of the swapfile. ResourceDisk.SwapSizeMB=2000Reinicie el agente para activar el cambio
sudo service waagent restart
Instalar la base de datos
En este ejemplo, SAP NetWeaver se instala en SAP HANA. En esta instalación puede usar todas las bases de datos admitidas. Para más información acerca de cómo instalar SAP HANA en Azure, consulte Alta disponibilidad de SAP HANA en Azure Virtual Machines (VM). Para ver una lista de las bases de datos admitidas, consulte la nota de SAP 1928533.
Ejecute la instalación de la instancia de base de datos de SAP
Instale la instancia de base de datos de SAP NetWeaver como raíz con un nombre de host virtual que se asigna a la dirección IP de la configuración de front-end del equilibrador de carga para la base de datos, por ejemplo, nw1-db y 10.0.0.13.
Puede usar el parámetro de sapinst SAPINST_REMOTE_ACCESS_USER para permitir que un usuario no raíz se conecta a sapinst.
sudo <swpm>/sapinst SAPINST_REMOTE_ACCESS_USER=sapadmin SAPINST_USE_HOSTNAME=virtual_hostname
Instalación del servidor de aplicaciones de SAP NetWeaver
Siga estos pasos para instalar un servidor de aplicaciones de SAP.
Preparación del servidor de aplicaciones
Siga los pasos descritos en el capítulo Preparación del servidor de aplicaciones de SAP NetWeaver anterior para preparar el servidor de aplicaciones.
Instale el servidor de aplicaciones de SAP NetWeaver
Instale un servidor de aplicaciones de SAP NetWeaver principal o adicional.
Puede usar el parámetro de sapinst SAPINST_REMOTE_ACCESS_USER para permitir que un usuario no raíz se conecta a sapinst.
sudo <swpm>/sapinst SAPINST_REMOTE_ACCESS_USER=sapadmin SAPINST_USE_HOSTNAME=virtual_hostnameActualice el almacenamiento seguro de SAP HANA
Actualice el almacenamiento seguro de SAP HANA que apunte al nombre virtual de la configuración de la replicación del sistema SAP HANA.
Ejecute el siguiente comando para mostrar las entradas:
hdbuserstore ListSe deberían mostrar todas las entradas y deberían ser parecidas a estas:
DATA FILE : /home/nw1adm/.hdb/nw1-di-0/SSFS_HDB.DAT KEY FILE : /home/nw1adm/.hdb/nw1-di-0/SSFS_HDB.KEY KEY DEFAULT ENV : 10.0.0.14:30313 USER: SAPABAP1 DATABASE: HN1El resultado muestra que la dirección IP de la entrada predeterminada apunta a la máquina virtual y no a la dirección IP del equilibrador de carga. Esta entrada debe modificarse para que apunte al nombre de host virtual del equilibrador de carga. Asegúrese de usar el mismo puerto (30313 en la salida anterior) y el mismo nombre de base de datos (HN1 en la salida anterior).
su - nw1adm hdbuserstore SET DEFAULT nw1-db:30313@HN1 SAPABAP1 <password of ABAP schema>
Prueba de la configuración del clúster
Las siguientes pruebas son una copia de los casos de prueba de las guías de procedimientos recomendados de SUSE. Se copian para su comodidad. Además, lea siempre las guías de procedimientos recomendados y realice todas las pruebas adicionales que puedan haberse agregado.
Prueba de HAGetFailoverConfig, HACheckConfig y HACheckFailoverConfig
Ejecute los siguientes comandos como <sapsid>adm en el nodo donde se ejecuta actualmente la instancia de ASCS. Si los comandos producen un error de memoria insuficiente, los guiones en el nombre de host pueden ser la causa. Se trata de un problema conocido que SUSE corregirá en el paquete sap-suse-cluster-connector.
nw1-cl-0:nw1adm 54> sapcontrol -nr 00 -function HAGetFailoverConfig # 15.08.2018 13:50:36 # HAGetFailoverConfig # OK # HAActive: TRUE # HAProductVersion: Toolchain Module # HASAPInterfaceVersion: Toolchain Module (sap_suse_cluster_connector 3.0.1) # HADocumentation: https://www.suse.com/products/sles-for-sap/resource-library/sap-best-practices/ # HAActiveNode: # HANodes: nw1-cl-0, nw1-cl-1 nw1-cl-0:nw1adm 55> sapcontrol -nr 00 -function HACheckConfig # 15.08.2018 14:00:04 # HACheckConfig # OK # state, category, description, comment # SUCCESS, SAP CONFIGURATION, Redundant ABAP instance configuration, 2 ABAP instances detected # SUCCESS, SAP CONFIGURATION, Redundant Java instance configuration, 0 Java instances detected # SUCCESS, SAP CONFIGURATION, Enqueue separation, All Enqueue server separated from application server # SUCCESS, SAP CONFIGURATION, MessageServer separation, All MessageServer separated from application server # SUCCESS, SAP CONFIGURATION, ABAP instances on multiple hosts, ABAP instances on multiple hosts detected # SUCCESS, SAP CONFIGURATION, Redundant ABAP SPOOL service configuration, 2 ABAP instances with SPOOL service detected # SUCCESS, SAP STATE, Redundant ABAP SPOOL service state, 2 ABAP instances with active SPOOL service detected # SUCCESS, SAP STATE, ABAP instances with ABAP SPOOL service on multiple hosts, ABAP instances with active ABAP SPOOL service on multiple hosts detected # SUCCESS, SAP CONFIGURATION, Redundant ABAP BATCH service configuration, 2 ABAP instances with BATCH service detected # SUCCESS, SAP STATE, Redundant ABAP BATCH service state, 2 ABAP instances with active BATCH service detected # SUCCESS, SAP STATE, ABAP instances with ABAP BATCH service on multiple hosts, ABAP instances with active ABAP BATCH service on multiple hosts detected # SUCCESS, SAP CONFIGURATION, Redundant ABAP DIALOG service configuration, 2 ABAP instances with DIALOG service detected # SUCCESS, SAP STATE, Redundant ABAP DIALOG service state, 2 ABAP instances with active DIALOG service detected # SUCCESS, SAP STATE, ABAP instances with ABAP DIALOG service on multiple hosts, ABAP instances with active ABAP DIALOG service on multiple hosts detected # SUCCESS, SAP CONFIGURATION, Redundant ABAP UPDATE service configuration, 2 ABAP instances with UPDATE service detected # SUCCESS, SAP STATE, Redundant ABAP UPDATE service state, 2 ABAP instances with active UPDATE service detected # SUCCESS, SAP STATE, ABAP instances with ABAP UPDATE service on multiple hosts, ABAP instances with active ABAP UPDATE service on multiple hosts detected # SUCCESS, SAP STATE, SCS instance running, SCS instance status ok # SUCCESS, SAP CONFIGURATION, SAPInstance RA sufficient version (nw1-ascs_NW1_00), SAPInstance includes is-ers patch # SUCCESS, SAP CONFIGURATION, Enqueue replication (nw1-ascs_NW1_00), Enqueue replication enabled # SUCCESS, SAP STATE, Enqueue replication state (nw1-ascs_NW1_00), Enqueue replication active nw1-cl-0:nw1adm 56> sapcontrol -nr 00 -function HACheckFailoverConfig # 15.08.2018 14:04:08 # HACheckFailoverConfig # OK # state, category, description, comment # SUCCESS, SAP CONFIGURATION, SAPInstance RA sufficient version, SAPInstance includes is-ers patchMigración manual de la instancia de ASCS
Estado del recurso antes de iniciar la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-0 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-0 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-1Ejecute los siguientes comandos como raíz para migrar la instancia de ASCS.
nw1-cl-0:~ # crm resource migrate rsc_sap_NW1_ASCS00 force # INFO: Move constraint created for rsc_sap_NW1_ASCS00 nw1-cl-0:~ # crm resource unmigrate rsc_sap_NW1_ASCS00 # INFO: Removed migration constraints for rsc_sap_NW1_ASCS00 # Remove failed actions for the ERS that occurred as part of the migration nw1-cl-0:~ # crm resource cleanup rsc_sap_NW1_ERS02Estado del recurso después de la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-0 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0Prueba de HAFailoverToNode
Estado del recurso antes de iniciar la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-0 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0Ejecute los comandos siguientes como <sapsid>adm para migrar la instancia de ASCS.
nw1-cl-0:nw1adm 55> sapcontrol -nr 00 -host nw1-ascs -user nw1adm <password> -function HAFailoverToNode "" # run as root # Remove failed actions for the ERS that occurred as part of the migration nw1-cl-0:~ # crm resource cleanup rsc_sap_NW1_ERS02 # Remove migration constraints nw1-cl-0:~ # crm resource clear rsc_sap_NW1_ASCS00 #INFO: Removed migration constraints for rsc_sap_NW1_ASCS00Estado del recurso después de la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-0 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-0 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-1Simulación de bloqueo de nodo
Estado del recurso antes de iniciar la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-0 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-0 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-1Ejecute el siguiente comando como raíz en el nodo donde se ejecuta la instancia de ASCS
nw1-cl-0:~ # echo b > /proc/sysrq-triggerSi usa SBD, Pacemaker no se iniciará automáticamente en el nodo terminado. El estado después de que el nodo se inicia de nuevo debe parecerse a este.
Online: [ nw1-cl-1 ] OFFLINE: [ nw1-cl-0 ] Full list of resources: stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Failed Actions: * rsc_sap_NW1_ERS02_monitor_11000 on nw1-cl-1 'not running' (7): call=219, status=complete, exitreason='none', last-rc-change='Wed Aug 15 14:38:38 2018', queued=0ms, exec=0msUse los siguientes comandos para iniciar Pacemaker en el nodo terminado, limpiar los mensajes de SBD y limpiar los recursos con error.
# run as root # list the SBD device(s) nw1-cl-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" nw1-cl-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message nw1-cl-0 clear nw1-cl-0:~ # systemctl start pacemaker nw1-cl-0:~ # crm resource cleanup rsc_sap_NW1_ASCS00 nw1-cl-0:~ # crm resource cleanup rsc_sap_NW1_ERS02Estado del recurso después de la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0Bloqueo de la comunicación de red
Estado del recurso antes de iniciar la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0Ejecute la regla de firewall para bloquear la comunicación en uno de los nodos.
# Execute iptable rule on nw1-cl-0 (10.0.0.5) to block the incoming and outgoing traffic to nw1-cl-1 (10.0.0.6) iptables -A INPUT -s 10.0.0.6 -j DROP; iptables -A OUTPUT -d 10.0.0.6 -j DROPCuando los nodos del clúster no se pueden comunicar entre sí, existe el riesgo de un escenario de cerebro dividido. En tales situaciones, los nodos de clúster intentarán cercarse simultáneamente, lo que da lugar a una carrera de barreras.
Al configurar un dispositivo de barrera, se recomienda configurar la propiedad
pcmk_delay_max. Por lo tanto, en caso de escenario de cerebro dividido, el clúster introduce un retraso aleatorio hasta el valorpcmk_delay_max, a la acción de barrera en cada nodo. El nodo con el retraso más corto se seleccionará para la barrera.Además, en la configuración de ENSA 2, para priorizar el nodo que hospeda el recurso ASCS sobre el otro nodo durante un escenario de cerebro dividido, se recomienda configurar la propiedad
priority-fencing-delayen el clúster. Al habilitar la propiedad priority-fencing-delay se permite que el clúster introduzca un retraso adicional en la acción de barrera específicamente en el nodo que hospeda el recurso ASCS, lo que permite al nodo ASCS ganar la carrera de barreras.Ejecute el comando siguiente para eliminar la regla de firewall.
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command. iptables -D INPUT -s 10.0.0.6 -j DROP; iptables -D OUTPUT -d 10.0.0.6 -j DROPPrueba del reinicio manual de la instancia de ASCS
Estado del recurso antes de iniciar la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0Cree un bloqueo de puesta en cola; por ejemplo, edite un usuario en la transacción su01. Ejecute los comandos siguientes como <sapsid>adm en el nodo donde se ejecuta la instancia de ASCS. Los comandos detendrán la instancia de ASCS y la volverán a iniciar. Si usa la arquitectura del servidor 1 de puesta en cola, es posible que el bloqueo de puesta en cola se pierda en esta prueba. Si usa la arquitectura del servidor 2 de puesta en cola, se conservará la puesta en cola.
nw1-cl-1:nw1adm 54> sapcontrol -nr 00 -function StopWait 600 2Ahora, la instancia de ASCS se deshabilitará en Pacemaker
rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Stopped (disabled)Vuelva a iniciar la instancia de ASCS en el mismo nodo.
nw1-cl-1:nw1adm 54> sapcontrol -nr 00 -function StartWait 600 2El bloqueo de puesta en cola de la transacción su01 se perderá y el back-end se habrá restablecido. Estado del recurso después de la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0Terminación del proceso del servidor de mensajes
Estado del recurso antes de iniciar la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0Ejecute los siguientes comandos como raíz para identificar el proceso del servidor de mensajes y terminarlo.
nw1-cl-1:~ # pgrep -f ms.sapNW1 | xargs kill -9Si solo termina el servidor de mensajes una vez, se reiniciará mediante sapstart. Si lo termina con bastante frecuencia, Pacemaker acabará moviendo la instancia de ASCS al otro nodo, en caso de ENSA1. Ejecute los siguientes comandos como raíz para limpiar el estado del recurso de la instancia de ASCS y ERS después de la prueba.
nw1-cl-0:~ # crm resource cleanup rsc_sap_NW1_ASCS00 nw1-cl-0:~ # crm resource cleanup rsc_sap_NW1_ERS02Estado del recurso después de la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-0 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-1Terminación del proceso del servidor de puesta en cola
Estado del recurso antes de iniciar la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-0 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-1Ejecute los siguientes comandos como raíz en el nodo donde se ejecuta la instancia de ASCS para terminar el servidor de puesta en cola.
nw1-cl-0:~ # #If using ENSA1 pgrep -f en.sapNW1 | xargs kill -9 #If using ENSA2 pgrep -f enq.sapNW1 | xargs kill -9La instancia de ASCS conmutará por error inmediatamente al otro nodo, en el caso de ENSA1. La instancia de ERS también conmutará por error después de iniciarse la instancia de ASCS. Ejecute los siguientes comandos como raíz para limpiar el estado del recurso de la instancia de ASCS y ERS después de la prueba.
nw1-cl-0:~ # crm resource cleanup rsc_sap_NW1_ASCS00 nw1-cl-0:~ # crm resource cleanup rsc_sap_NW1_ERS02Estado del recurso después de la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0Terminación del proceso del servidor de replicación
Estado del recurso antes de iniciar la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0Ejecute el siguiente comando como raíz en el nodo donde se ejecuta la instancia de ERS para terminar el proceso del servidor de replicación de puesta en cola.
nw1-cl-0:~ # pgrep -f er.sapNW1 | xargs kill -9Si solo ejecuta el comando una vez, sapstart reiniciará el proceso. Si lo ejecuta con bastante frecuencia, sapstart no reiniciará el proceso y el recurso estará en estado detenido. Ejecute los siguientes comandos como raíz para limpiar el estado del recurso de la instancia de ERS después de la prueba.
nw1-cl-0:~ # crm resource cleanup rsc_sap_NW1_ERS02Estado del recurso después de la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0Terminación del proceso sapstartsrv de puesta en cola
Estado del recurso antes de iniciar la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0Ejecute los siguientes comandos como raíz en el nodo donde se ejecuta ASCS.
nw1-cl-1:~ # pgrep -fl ASCS00.*sapstartsrv # 59545 sapstartsrv nw1-cl-1:~ # kill -9 59545El proceso sapstartsrv siempre se debe reiniciar con el agente de recursos de Pacemaker. Estado del recurso después de la prueba:
stonith-sbd (stonith:external/sbd): Started nw1-cl-1 Resource Group: g-NW1_ASCS fs_NW1_ASCS (ocf::heartbeat:Filesystem): Started nw1-cl-1 nc_NW1_ASCS (ocf::heartbeat:azure-lb): Started nw1-cl-1 vip_NW1_ASCS (ocf::heartbeat:IPaddr2): Started nw1-cl-1 rsc_sap_NW1_ASCS00 (ocf::heartbeat:SAPInstance): Started nw1-cl-1 Resource Group: g-NW1_ERS fs_NW1_ERS (ocf::heartbeat:Filesystem): Started nw1-cl-0 nc_NW1_ERS (ocf::heartbeat:azure-lb): Started nw1-cl-0 vip_NW1_ERS (ocf::heartbeat:IPaddr2): Started nw1-cl-0 rsc_sap_NW1_ERS02 (ocf::heartbeat:SAPInstance): Started nw1-cl-0
Pasos siguientes
- Alta disponibilidad para SAP NetWeaver en máquinas virtuales de Azure en SUSE Linux Enterprise Server para SAP Applications: guía de varios SID
- Planeamiento e implementación de Azure Virtual Machines para SAP
- Implementación de Azure Virtual Machines para SAP
- Implementación de DBMS de Azure Virtual Machines para SAP
- Para más información sobre cómo establecer la alta disponibilidad y planear la recuperación ante desastres de SAP HANA en Azure Virtual Machines, consulte Alta disponibilidad de SAP HANA en las máquinas virtuales de Azure.