Disponibilidad de SAP HANA entre regiones de Azure
En este artículo se describen escenarios relacionados con la disponibilidad de SAP HANA en diferentes regiones de Azure. Debido a la distancia entre las regiones de Azure, configurar la disponibilidad de SAP HANA en varias regiones de Azure implica consideraciones especiales.
Motivos para la implementación en varias regiones de Azure
A menudo, las regiones de Azure están separadas por grandes distancias. Dependiendo de la región geopolítica, la distancia entre regiones de Azure puede ser de cientos de kilómetros o incluso de varios miles de kilómetros, como en Estados Unidos. Debido a la distancia, el tráfico de red entre recursos implementados en dos regiones de Azure diferentes tiene una latencia de ida y vuelta de red importante. La latencia es suficientemente importante como para excluir el intercambio sincrónico de datos entre dos instancias de SAP HANA en cargas de trabajo típicas de SAP.
Por otro lado, las organizaciones suelen tener un requisito de distancia entre la ubicación del centro de datos principal y un centro de datos secundario. Un requisito de distancia ayuda a proporcionar disponibilidad si se produce un desastre natural en una ubicación geográfica más amplia. Por ejemplo, los huracanes que castigaron el área del Caribe y Florida en septiembre y octubre de 2017. Su organización podría tener al menos un requisito de distancia mínima. Para la mayoría de los clientes de Azure, la definición de una distancia mínima obliga a diseñar una disponibilidad que comprenda varias regiones de Azure. Puesto que la distancia entre dos regiones de Azure es demasiado grande para usar el modo de replicación sincrónica de HANA, los requisitos de RTO y el RPO podrían obligarle a implementar configuraciones de disponibilidad dentro de una región, y complementarlas con implementaciones adicionales en una segunda región.
Otro aspecto que debe tenerse en cuenta en este escenario es la conmutación por error y la redirección de cliente. Se supone que una conmutación por error entre instancias de SAP HANA en dos regiones diferentes de Azure es siempre una conmutación por error manual. Puesto que la replicación del sistema de SAP HANA tiene el modo de replicación establecido en asincrónico, es posible que haya datos confirmados en la instancia principal de HANA que no hayan llegado aún a la instancia secundaria de HANA. Por lo tanto, la conmutación por error automática no es una opción para configuraciones en las que la replicación es asincrónica. Incluso con una conmutación por error controlada manualmente, como en un ejercicio de conmutación por error, es necesario tomar medidas para asegurarse de que todos los datos confirmados en el lado principal hayan llegado a la instancia secundaria, antes de pasar manualmente a la otra región de Azure.
Azure Virtual Network usa un intervalo de direcciones IP distinto. Las direcciones IP se implementan en la segunda región de Azure. Por lo tanto, tendrá que cambiar la configuración del cliente de SAP HANA o, preferiblemente, deberá crear pasos para cambiar la resolución de nombres. De esta manera, los clientes se redirigen a la nueva dirección IP del servidor del sitio secundario. Para más información, consulte el artículo de SAP sobre recuperación de la conexión de cliente tras una adquisición.
Disponibilidad simple entre dos regiones de Azure
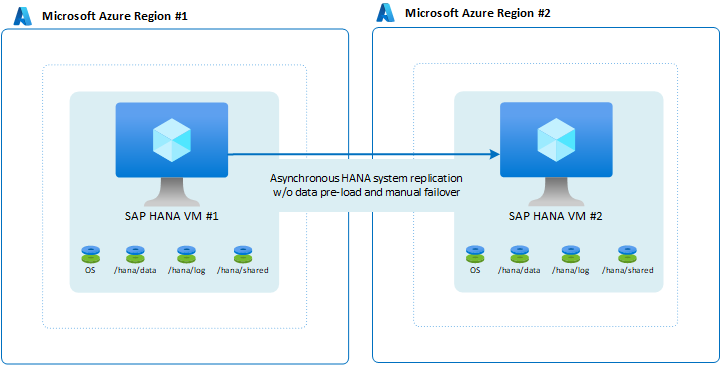
Puede decidir no contar con ninguna configuración de disponibilidad dentro de una única región, pero seguir teniendo la necesidad de tener la carga de trabajo atendida en caso de un desastre. Los sistemas que no son de producción son un caso clásico de este tipo. Aunque pueda ser admisible que el sistema permanezca inactivo durante medio día o incluso un día entero, no puede permitir que no esté disponible durante 48 horas o más. Para que la configuración sea menos costosa, ejecute otro sistema que sea aún menos importante en la máquina virtual. El otro sistema funciona como destino. También puede reducir el tamaño de la máquina virtual en la región secundaria y decidir no cargar previamente datos. Dado que la conmutación por error es manual y conlleva muchos pasos más para realizar también la conmutación por error de la pila de la aplicación completa, el tiempo adicional para apagar la VM, cambiar su tamaño y reiniciarla es aceptable.
Si usa el escenario de uso compartido del destino de recuperación ante desastres con un sistema de control de calidad en una máquina virtual, debe tener en cuenta estas consideraciones:
- Hay dos modos de operación con delta_datashipping y logreplay, que están disponibles para este escenario
- Ambos modos de operación tienen requisitos de memoria diferentes sin usar datos precargados
- Delta_datashipping podría requerir significativamente menos memoria sin la opción de precarga de lo que podría requerir logreplay. Consulte el capítulo 4.3 del documento de SAP How To Perform System Replication for SAP HANA (Cómo realizar la replicación del sistema para SAP HANA).
- El requisito de memoria del modo de operación de logreplay sin precarga no es determinista y depende de las estructuras de almacén de columnas cargadas. En casos extremos, es posible que necesite el 50 % de la memoria de la instancia principal. La memoria para el modo de operación logreplay es independiente de si elige establecer la carga previa de datos o no.
Nota:
En esta configuración, no puede proporcionar un RPO = 0, dado que el modo de replicación del sistema de HANA es asincrónico. Si tiene que proporcionar un RPO = 0, esta configuración no es una opción.
Un pequeño cambio que puede hacerse en la configuración sería configurar datos como carga previa. De todas formas, dada la naturaleza manual de la conmutación por error y el hecho de que los niveles de aplicación tengan que moverse también a la segunda región, puede que la carga previa de los datos no tenga sentido.
Combinación de disponibilidad dentro de una región y entre regiones
Una combinación de disponibilidad dentro de una región y entre regiones puede estar determinada por estos factores:
- Requisito de RPO = 0 dentro de una región de Azure.
- La organización no desea o no puede permitir que las operaciones globales se vean afectadas por una catástrofe natural importante que afecte a una región más grande. Este ha sido el caso de algunos huracanes cuyos efectos se han dejado sentir en el Caribe en los últimos años.
- Normativa que demanda distancias entre los sitios principal y secundario que se encuentran claramente por encima de las que las zonas de disponibilidad de Azure pueden proporcionar.
En estos casos, puede configurar lo que SAP llama a una configuración de replicación del sistema de varios niveles de SAP HANA mediante la replicación del sistema HANA. La arquitectura tendría este aspecto:
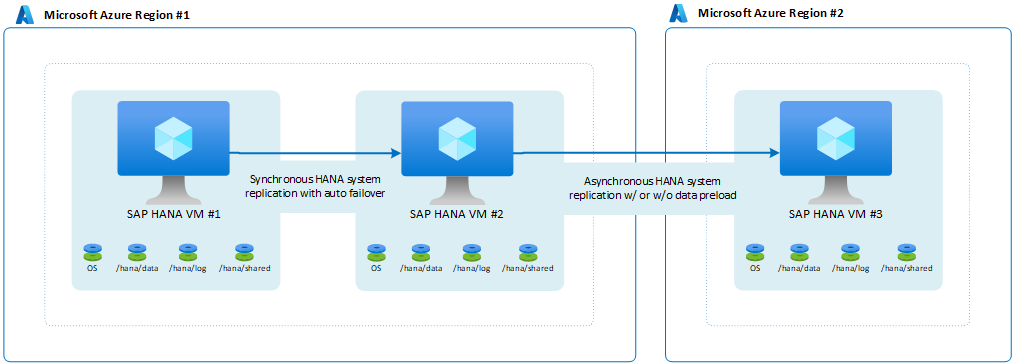
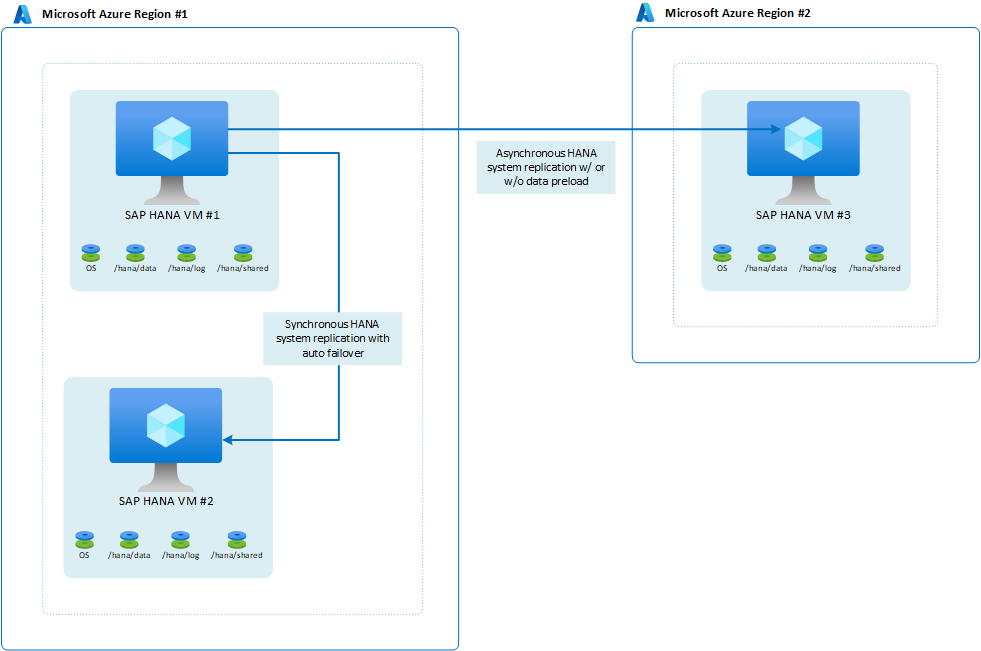
SAP introdujo la replicación del sistema en varios destinos con HANA 2.0 SPS3. La replicación del sistema en varios destinos aporta algunas ventajas en escenarios de actualización. Por ejemplo, el sitio de recuperación ante desastres (región 2) no se ve afectado cuando el sitio de alta disponibilidad secundario está inactivo para mantenimiento o actualizaciones. Puede encontrar más información acerca de la replicación del sistema en varios destinos de HANA en el portal de ayuda de SAP. Una arquitectura posible con la replicación en varios destinos tendría el siguiente aspecto:
Si la organización tiene requisitos para la preparación de la alta disponibilidad en la segunda región de recuperación ante desastres de Azure, la arquitectura sería como la del siguiente ejemplo:
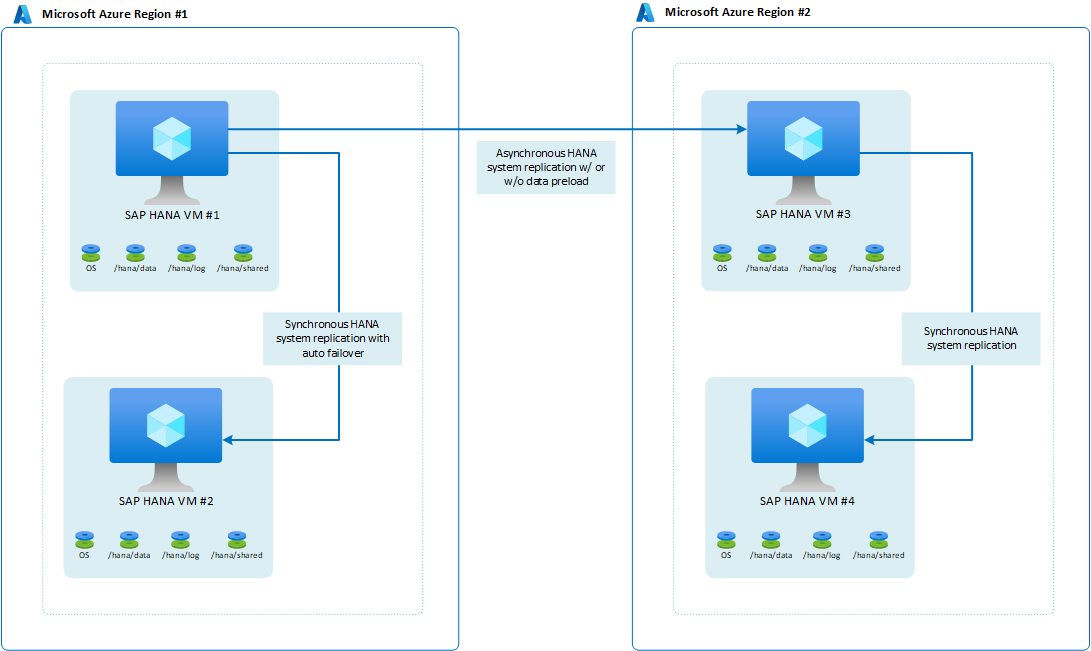
Con logreplay como modo de operación, esta configuración proporciona un RPO = 0, con un RTO bajo, dentro de la región principal. La configuración también proporciona un RPO aceptable en caso de que se necesite un traslado a la segunda región. Los tiempos de RTO en la segunda región dependen de si los datos se cargan previamente. Muchos clientes usan la máquina virtual en la región secundaria para ejecutar un sistema de prueba. En ese caso de uso, los datos no se pueden cargar previamente.
Importante
Los modos de operación entre los diferentes niveles de deben ser homogéneos. No puede usar logreplay como modo de operación entre el nivel 1 y el nivel 2 y delta_datashipping para proporcionar el nivel 3. Solo puede elegir entre un modo de operación u otro que deba ser coherente para todos los niveles. Puesto que delta_datashipping no es adecuado para ofrecerle un RPO=0, el único modo de operación razonable para este tipo de configuración de varios niveles sigue siendo logreplay. Para consultar detalles de los modos de operación y algunas restricciones, vea el artículo de SAP Operation modes for SAP HANA system replication (Modos de operación para la replicación de sistema de SAP HANA).
Pasos siguientes
Para obtener instrucciones paso a paso sobre cómo configurar estas configuraciones en Azure, vea:
- Configuración de la replicación del sistema de SAP HANA en máquinas virtuales de Azure
- High Availability for SAP HANA using System Replication (Alta disponibilidad en SAP HANA mediante la replicación del sistema)
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de