Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En Azure AI Search, hay varias maneras de ejecutar un indexador:
- Ejecute inmediatamente después de la creación del indexador. Este es el valor predeterminado a menos que cree el indexador en un estado "deshabilitado".
- Programar la ejecución del indexador para invocar la ejecución a intervalos regulares.
- Ejecute a petición, con o sin un "restablecimiento".
En este artículo se explica cómo ejecutar indexadores a petición, con y sin un restablecimiento. También describe la ejecución, la duración y la simultaneidad del indexador.
Cómo se conectan los indexadores a los recursos de Azure
Los indexadores son uno de los pocos subsistemas que realizan llamadas salientes abiertas a otros recursos de Azure. Puede usar claves o roles para autenticar la conexión.
En términos de roles de Azure, los indexadores no tienen identidades independientes: una conexión del motor de búsqueda a otro recurso de Azure se realiza mediante el sistema o la identidad administrada asignada por el usuario de un servicio de búsqueda, además de una asignación de roles en el recurso de Azure de destino. Si el indexador se conecta a un recurso de Azure en una red virtual, debe crear un vínculo privado compartido para esa conexión.
Ejecución del indexador
Un servicio de búsqueda ejecuta un trabajo de indizador por unidad de búsqueda. Cada servicio de búsqueda comienza con una unidad de búsqueda, pero cada nueva partición o réplica aumenta las unidades de búsqueda del servicio. Puede comprobar el recuento de unidades de búsqueda en la sección Essential de Azure Portal de la página Información general . Si necesita procesamiento simultáneo, asegúrese de que las unidades de búsqueda incluyan réplicas suficientes. Los indexadores no se ejecutan en segundo plano, por lo que es posible que experimente más limitación de consultas de lo habitual si el servicio está bajo presión.
En la captura de pantalla siguiente se muestra el número de unidades de búsqueda, que determina el número de indizadores que se pueden ejecutar a la vez.

Una vez iniciada la ejecución del indizador, no se puede pausar ni detener. La ejecución del indizador se detiene cuando no hay más documentos para cargar o actualizar, o cuando se alcanza el límite máximo de tiempo de ejecución.
Puede ejecutar varios indizadores a la vez suponiendo que tenga capacidad suficiente, pero cada indizador es una sola instancia. Al iniciar una nueva instancia mientras el indexador ya está en ejecución, se produce este error: "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."
Entorno de ejecución de los indexadores
Un trabajo de indexador se ejecuta en un entorno de ejecución administrado. Actualmente, hay dos entornos:
Un entorno de ejecución privado se ejecuta en clústeres de búsqueda específicos del servicio de búsqueda.
Microsoft administra y protege un entorno multiinquilino con procesadores de contenido sin costo adicional. Este entorno se usa para descargar el procesamiento intensivo a nivel computacional, lo que permite que los recursos específicos del servicio estén disponibles para las operaciones rutinarias. Cuando sea posible, la mayoría de los conjuntos de habilidades se ejecutan en el entorno multitenant. Este es el valor predeterminado.
El procesamiento intensivo de cálculo hace referencia a los conjuntos de aptitudes que se ejecutan en los procesadores de contenido y trabajos de indexador que procesan un gran volumen de documentos o documentos de gran tamaño. El procesamiento de conjuntos de aptitudes en los procesadores de contenido multiinquilino viene determinado por heurística e información del sistema y no está bajo control de clientes.
Puede evitar el uso del entorno multiinquilino en los servicios Standard2 o superior anclando un indexador y procesamiento de conjuntos de aptitudes exclusivamente a los clústeres de búsqueda. Establezca el executionEnvironment parámetro en la definición del indexador para ejecutar siempre un indexador en el entorno de ejecución privado.
Los firewalls IP bloquean el entorno multiinquilino, por lo que si tiene un firewall, cree una regla que permita conexiones de procesador multiinquilino.
Los límites del indexador varían para cada entorno:
| Carga de trabajo | Duración máxima | Número máximo de trabajos | Entorno de ejecución |
|---|---|---|---|
| Ejecución privada | 24 horas | Un trabajo de indexador por unidad de búsqueda1. | La indexación no se ejecuta en segundo plano. En su lugar, el servicio de búsqueda equilibra todos los trabajos de indexación con las consultas en curso y las acciones de administración de objetos (como crear o actualizar índices). Al ejecutar indexadores, cabría esperar ver cierta latencia de consulta si los volúmenes de indexación son grandes. |
| Multiinquilino | 2 horas 2 | Indeterminado 3 | Dado que el clúster de procesamiento de contenido es multiinquilino, se agregan procesadores de contenido para satisfacer la demanda. Si experimenta un retraso en la ejecución a petición o programada, probablemente se deba a que el sistema está agregando procesadores o esperando a que uno esté disponible. |
1 Las unidades de búsqueda pueden ser combinaciones flexibles de particiones y réplicas, pero los trabajos del indexador no están vinculados ni a una ni a otra. En otras palabras, si tiene doce unidades, puede tener doce trabajos de indexador ejecutándose simultáneamente en una ejecución privada, independientemente de cómo se implementen las unidades de búsqueda.
2 Si se necesitan más de dos horas para procesar todos los datos, habilite la detección de cambios y programe el indexador para que se ejecute en intervalos de 5 minutos para reanudar la indexación rápidamente si se detiene debido a un tiempo de espera. Consulte Indexación de un conjunto de datos grande para obtener más estrategias.
3 "Indeterminado" significa que el límite no se cuantifica por el número de trabajos. Algunas cargas de trabajo, como el procesamiento de conjuntos de aptitudes, se pueden ejecutar en paralelo, lo que podría dar lugar a muchos trabajos aunque solo haya un indizador implicado. Aunque el entorno no impone restricciones, se siguen aplicando límites de indexador para el servicio de búsqueda.
Ejecución sin restablecimiento
Una operación Run Indexer detecta y procesa solo lo necesario para sincronizar el índice de búsqueda con cambios en el origen de datos subyacente. La indexación incremental comienza localizando un límite máximo interno para encontrar el documento de búsqueda actualizado por última vez, que se convierte en el punto de partida para la ejecución del indexador en documentos nuevos y actualizados del origen de datos.
La detección de cambios es esencial para determinar las novedades o las actualizaciones en el origen de datos. Los indexadores usan las funcionalidades de detección de cambios del origen de datos subyacente para determinar las novedades o actualizaciones del origen de datos.
Azure Storage incorpora detección de cambios gracias a su propiedad LastModified.
Otros orígenes de datos, como Azure SQL o Azure Cosmos DB, deben configurarse para la detección de cambios para que el indexador pueda leer filas nuevas y actualizadas.
Si el contenido subyacente no cambia, una operación de ejecución no tiene ningún efecto. En este caso, el historial de ejecución del indexador indica los documentos procesados 0\0 .
Debe restablecer el indexador, como se explica en la sección siguiente, para volver a procesarlo en su totalidad.
Restablecimiento de indexadores
Después de la ejecución inicial, un indexador realiza un seguimiento de los documentos de búsqueda que se indexan a través de una marca de agua alta interna. El marcador nunca se expone, aunque internamente el indizador sabe dónde se detuvo la última vez.
Si necesita recompilar todo o parte de un índice, use Reset API disponibles en niveles decrecientes en la jerarquía de objetos:
- Reset Indexers borra el límite superior y realiza una reindexación completa de todos los documentos.
- Los indexadores de resincronización (versión preliminar) realizan una redexación parcial eficaz de todos los documentos
- Reset Documents (versión preliminar) reindexa un documento concreto o una lista de documentos.
- Restablecer aptitudes (versión preliminar) invoca el procesamiento de aptitudes para una aptitud específica
Después del restablecimiento, siga con un comando Ejecutar para volver a procesar documentos nuevos y existentes. Los documentos de búsqueda huérfanos que no tienen ningún homólogo en el origen de datos no se pueden quitar a través del restablecimiento o ejecución. Si necesita eliminar documentos, vea Documentos: Indexar en su lugar.
Nota:
Las tablas no pueden estar vacías. Si usa TRUNCATE TABLE para borrar filas, un restablecimiento y la repetición del indexador no quitarán los documentos de búsqueda correspondientes. Para quitar documentos de búsqueda huérfanos, debe indexarlos con una acción de eliminación.
Restablecimiento y ejecución de indexadores
El restablecimiento borra el límite máximo. Todos los documentos del índice de búsqueda se marcan para la sobrescritura completa, sin actualizaciones insertadas ni combinación con contenido existente. Para los indexadores con un conjunto de aptitudes y almacenamiento en caché de enriquecimiento, el restablecimiento del índice también restablece implícitamente el conjunto de aptitudes.
El trabajo real ocurre cuando sigues un reinicio con un comando Ejecutar:
- Todos los documentos nuevos encontrados en el origen subyacente se agregarán al índice de búsqueda.
- Todos los documentos que existen en el origen de datos y en el índice de búsqueda se sobrescriben en el índice de búsqueda.
- Cualquier contenido enriquecido creado a partir de conjuntos de habilidades vuelve a generarse. La caché de enriquecimiento, si está habilitada, se actualiza.
Como se indicó anteriormente, el restablecimiento es una operación pasiva: debe seguir con una solicitud de ejecución para volver a generar el índice.
Las operaciones de restablecimiento o ejecución se aplican a un índice de búsqueda o un almacén de conocimiento, a documentos o proyecciones específicos y a enriquecimientos almacenados en caché si un restablecimiento incluye explícita o implícitamente aptitudes.
El restablecimiento también se aplica a las operaciones de creación y de actualización. No desencadenará la eliminación ni la limpieza de documentos huérfanos en el índice de búsqueda. Para más información sobre la eliminación de documentos, vea Documentos: Indexar.
Una vez que restablezca un indexador, no podrá deshacer la acción.
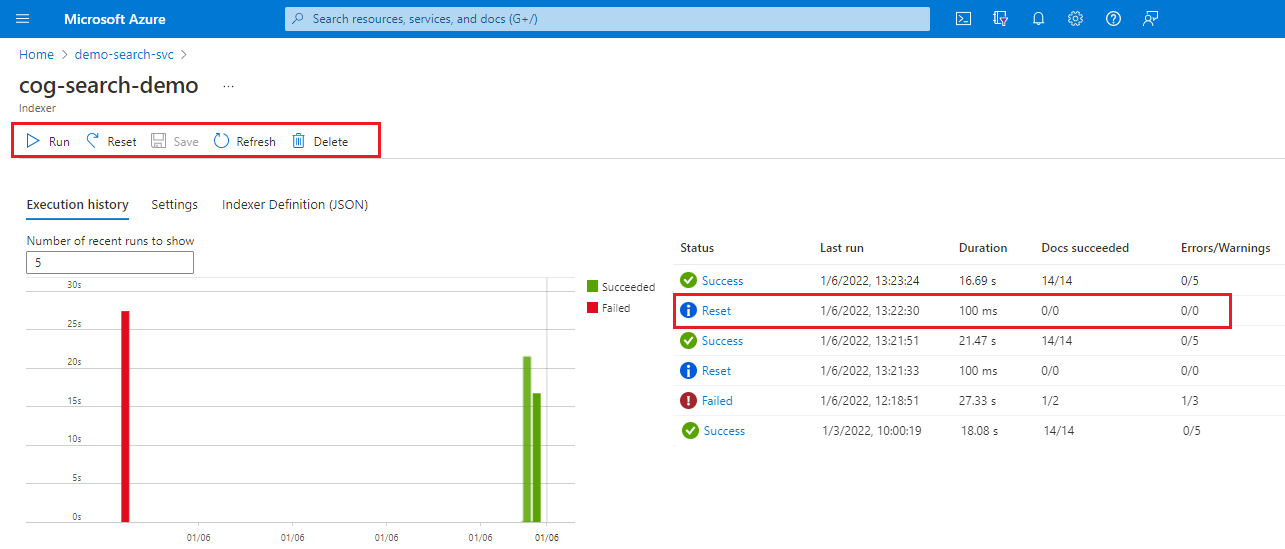
Inicia sesión en Azure Portal y abre la página del servicio de búsqueda.
En la página Información general, seleccione la pestaña Indexadores.
Seleccione un indexador.
Seleccione el comando Restablecer y, luego, elija Sí para confirmar la acción.
Actualice la página para mostrar el estado. Puede seleccionar el elemento para ver sus detalles.
Seleccione Ejecutar para iniciar el procesamiento del indexador o espere a la siguiente ejecución programada.
Restablecimiento de aptitudes (versión preliminar)
En el caso de los indexadores que tienen conjuntos de aptitudes, puede restablecer las aptitudes individuales para forzar el procesamiento de solo esa aptitud y cualquier aptitud de nivel inferior que dependa de su salida. La caché de enriquecimiento, si la ha habilitado, también se actualiza.
Restablecer aptitudes actualmente es de solo REST, disponible a través de 2020-06-30-preview o posterior. Se recomienda la API de versión preliminar más reciente.
POST /skillsets/[skillset name]/resetskills?api-version=2024-05-01-preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
Puede especificar aptitudes individuales, como se indica en el ejemplo anterior, pero si alguna de esas aptitudes requiere la salida de aptitudes que no están en la lista (n.º 2 a n.º 4), se ejecutarán estas últimas a menos que la memoria caché pueda proporcionar la información necesaria. Para que esto sea true, los enriquecimientos almacenados en caché para las aptitudes n.º 2 a n.º 4 no deben tener dependencias en n.º 1 (enumerados para el restablecimiento).
Si no se especifica ninguna aptitud, se ejecutará todo el conjunto de aptitudes y, si el almacenamiento en caché está habilitado, también se actualizará la memoria caché.
No olvide realizar un seguimiento con Run Indexer para invocar el procesamiento real.
Restablecimiento de documentos (versión preliminar)
Indexadores: Restablecer documentos acepta una lista de claves de documento para que pueda actualizar documentos específicos. Si se especifica, los parámetros de restablecimiento se convierten en el único factor determinante de lo que se procesa, independientemente de otros cambios en los datos subyacentes. Por ejemplo, si se agregaron o actualizaron 20 blobs desde la última vez que se ejecutó el indizador, pero solo se restablece un documento, solo se procesa ese documento.
Por documento, todos los campos del documento de búsqueda se actualizan con valores y metadatos del origen de datos. No se pueden elegir los campos que se van a actualizar.
Si el origen de datos es Azure Data Lake Storage (ADLS) Gen2 y los blobs están asociados a metadatos de permiso, esos permisos también se vuelven a ingerir en el índice de búsqueda si los permisos cambian en los datos subyacentes. Para obtener más información, consulte Reindexar ACL y ámbito RBAC con indexadores ADLS Gen2.
Si el documento se enriquece mediante un conjunto de aptitudes y tiene datos almacenados en caché, el conjunto de aptitudes se invoca solo para los documentos especificados y la caché se actualiza para los documentos reprocesados.
Al probar esta API por primera vez, las API siguientes pueden ayudar a validar y probar los comportamientos. Puede usar la versión preliminar de la API 2020-06-30-preview y versiones posteriores. Se recomienda la API de versión preliminar más reciente.
Llame a Indizadores: Obtener estado con una API de versión preliminar para comprobar los estados del restablecimiento y la ejecución. Puede encontrar información sobre la solicitud de restablecimiento al final de la respuesta de estado.
Llame a Indizadores: Restablecer documentos con una API de versión preliminar para especificar los documentos que se van a procesar.
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2024-05-01-preview { "documentKeys" : [ "1001", "4452" ] }Las claves de documento proporcionadas en la solicitud son valores del índice de búsqueda, que pueden ser diferentes de los campos correspondientes del origen de datos. Si no está seguro del valor de clave, envíe una consulta para devolver el valor. Puede usar
selectpara devolver solo el campo de clave del documento.En el caso de los blobs que se analizan en varios documentos de búsqueda (donde parsingMode se establece en jsonLines o jsonArrays, o delimitedText), el indizador genera la clave de documento y es posible que no la conozca. En este escenario, se consulta la clave de documento para devolver el valor correcto.
Llame a Run Indexer (cualquier versión de API) para procesar los documentos especificados. Solo se indexan esos documentos específicos.
Llame a Run Indexer una segunda vez para procesar desde el último límite máximo.
Llame a Search Documents para buscar valores actualizados y, también, para devolver claves de documento si no está seguro del valor. Use
"select": "<field names>"si desea limitar los campos que aparecerán en la respuesta.
Sobrescritura de la lista de claves de documento
Al llamar a la API Reset Documents varias veces con claves diferentes, se anexan las nuevas claves a la lista de restablecimiento de claves de documento. Al llamar a la API con el parámetro overwrite establecido en true, se sobrescribirá la lista actual con la nueva:
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
Cómo resincronizar indexadores (versión preliminar)
Resync Indexers es una nueva API en versión preliminar que realiza una reindexación parcial de todos los documentos. Un indexador se considera sincronizado con su origen de datos cuando los campos específicos de todos los documentos del índice de destino son coherentes con los datos del origen de datos. Normalmente, un indexador logra la sincronización después de una ejecución inicial correcta. Si se elimina un documento del origen de datos, el indexador permanece sincronizado según esta definición. Sin embargo, durante la siguiente ejecución del indexador, se quitará el documento correspondiente del índice de destino si el seguimiento de eliminación está habilitado.
Si se modifica un documento en el origen de datos, el indexador se desincroniza. Por lo general, los mecanismos de seguimiento de cambios volverán a sincronizar el indexador durante la siguiente ejecución. Por ejemplo, en Azure Storage, la modificación de un blob actualiza su hora de última modificación, lo que le permite volver a indexar en la ejecución posterior del indexador porque el tiempo actualizado supera la marca de agua alta establecida por la ejecución anterior.
Por el contrario, para determinados orígenes de datos como ADLS Gen2, modificar las listas de control de acceso (ACL) de un blob no cambia su hora de última modificación, lo que hace que el seguimiento de cambios sea ineficaz si las ACL se deben tener en cuenta. Por lo tanto, el blob modificado no se volverá a indexar en la ejecución posterior, ya que solo se procesarán los documentos modificados después del último punto de referencia alto.
Aunque el uso de "reset" o "reset docs" puede solucionar este problema, "reset" puede ser lento e ineficaz para grandes conjuntos de datos, y "reset docs" requiere identificar la clave de documento del blob destinado a la actualización.
Los indexadores de resincronización ofrecen una alternativa eficaz y práctica. Los usuarios simplemente colocan el indexador en modo de resincronización y especifican el contenido que se va a resincronizar llamando a la API de indexadores de resincronización. En la siguiente ejecución, el indexador inspeccionará solo la parte pertinente de los datos del origen y evitará cualquier procesamiento innecesario que no esté relacionado con los datos especificados. También consultará los documentos existentes en el índice de destino y solo actualizará los documentos que muestran discrepancias entre el origen de datos y el índice de destino. Después de la ejecución de resincronización, el indexador se sincronizará y revertirá al modo de ejecución normal del indexador para las ejecuciones posteriores.
Resincronizar y ejecutar los indexadores
Llame a Indexers - Resync con la versión preliminar de la API para especificar qué contenido resincronizar.
POST https://[service name].search.windows.net/indexers/[indexer name]/resync?api-version=2025-05-01-preview { "options" : [ "permissions" ] }- Se requiere el campo
options. Actualmente, la única opción admitida espermissions. Es decir, solo se actualizarán los campos de filtro de permisos del índice de destino.
- Se requiere el campo
Llame a Run Indexer (cualquier versión de API) para volver a sincronizar el indexador.
Llame a Run Indexer una segunda vez para procesar desde el último límite máximo.
Comprobación del estado de restablecimiento "currentState"
Para comprobar el estado de restablecimiento y ver qué claves de documento se ponen en cola para su procesamiento, siga estos pasos.
Llame a Obtener estado del indizador con una API de versión preliminar.
La API de versión preliminar devolverá la sección
currentState, que se encuentra al final de la respuesta."currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resyncInitialTrackingState": null, "resyncFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }Compruebe el "modo":
Para las aptitudes de restablecimiento, el "modo" será
indexingAllDocs(dado que posiblemente se vean afectados todos los documentos en los campos que se rellenan a través del enriquecimiento con IA).Para los indexadores de resincronización, "modo" debe establecerse en
indexingResync. El indexador comprueba todos los documentos y se centra en los datos interesados en el origen de datos y los campos interesados en el índice de destino.En Reset Documents, el "modo" debe establecerse en
indexingResetDocs. El indexador conserva este estado hasta que se procesan todas las claves de documento proporcionadas en la llamada de restablecimiento de documentos, tiempo durante el cual no se ejecutará ningún otro trabajo de indexador mientras la operación está en curso. Para buscar todos los documentos en la lista de claves de documento, es necesario descifrar cada documento para buscar y coincidir en la clave, lo que puede tardar unos minutos si el conjunto de datos es grande. Si un contenedor de blobs contiene centenares de blobs y los documentos que desea restablecer están al final, el indizador no encontrará los blobs coincidentes hasta que todos los demás se hayan comprobado primero.Una vez que se vuelvan a procesar los documentos, vuelva a ejecutar Get Indexer Status. El indexador regresa al modo
indexingAllDocsy se procesarán los documentos nuevos o actualizados en la siguiente ejecución.
Pasos siguientes
Las API de restablecimiento se usan para determinar el ámbito de la siguiente ejecución del indizador. Para el procesamiento real, deberá ejecutar un proceso de indexación bajo demanda o permitir que un trabajo programado complete la tarea. Una vez finalizada la ejecución, el indizador vuelve al procesamiento normal, ya sea según una programación o un procesamiento a petición.
Después de restablecer y volver a ejecutar trabajos del indexador, puede supervisar el estado desde el servicio de búsqueda o obtener información detallada a través del registro de recursos.