Tutorial: Indexación de datos de gran tamaño de Apache Spark mediante SynapseML y Azure AI Search
En este tutorial de Azure AI Search, aprenderá a indexar y consultar datos de gran tamaño cargados desde clústeres de Spark. Configure un Jupyter Notebook que realice las siguientes acciones:
- Cargar varios formularios (facturas) en una trama de datos en una sesión de Apache Spark
- Analizarlos para determinar sus características
- Ensamblar la salida resultante en una estructura de datos tabulares
- Escritura de la salida en un índice de búsqueda hospedado en Azure AI Search
- Explorar y consultar en el contenido que ha creado
Este tutorial depende de SynapseML, una biblioteca de código abierto que admite el aprendizaje automático paralelo masivo con macrodatos. En SynapseML, la indexación de búsqueda y el aprendizaje automático se exponen a través de transformadores que realizan tareas especializadas. Los transformadores aprovechan una amplia gama de funcionalidades de inteligencia artificial. En este ejercicio, usará las API de AzureSearchWriter para el análisis y el enriquecimiento con IA.
Aunque Azure AI Search tiene enriquecimiento con IA nativo, en este tutorial se muestra cómo acceder a las funcionalidades de la inteligencia artificial fuera de Azure AI Search. Al usar SynapseML en lugar de indexadores o aptitudes, no tendrá límites de datos ni otras restricciones asociadas a esos objetos.
Sugerencia
Vea un breve vídeo de esta demostración en https://www.youtube.com/watch?v=iXnBLwp7f88. El vídeo amplía este tutorial con más pasos y objetos visuales.
Requisitos previos
Necesita la biblioteca synapseml y varios recursos de Azure. Si es posible, use la misma suscripción y región para los recursos de Azure y coloque todo en un grupo de recursos para que la limpieza posterior resulte más sencilla. Los vínculos siguientes son para las instalaciones del portal. Los datos de ejemplo se importan desde un sitio público.
- Paquete de SynapseML 1
- Azure AI Search (cualquier nivel) 2
- Servicios de Azure AI (cualquier nivel) 3
- Azure Databricks (cualquier nivel) 4
1 Este vínculo se resuelve en un tutorial para cargar el paquete.
2 Puede usar el nivel de búsqueda gratuito para indexar los datos de muestra, pero elija un nivel superior si los volúmenes de datos son grandes. En el caso de los niveles facturables, proporcione la clave de API de búsqueda en el paso Configurar dependencias más adelante.
3 En este tutorial se usa Documento de inteligencia de Azure AI y Traductor de Azure AI. En las instrucciones siguientes, proporcione una clave de varios servicios y la región. La misma clave funciona para ambos servicios.
4 En este tutorial, Azure Databricks proporciona la plataforma informática Spark. Usamos las instrucciones del portal para configurar el área de trabajo.
Nota:
Todos los recursos de Azure anteriores admiten características de seguridad en la Plataforma de identidad de Microsoft. Para simplificar, en este tutorial se usa la autenticación basada en claves, con puntos de conexión y claves que se copian de las páginas del portal de cada servicio. Si implementa este flujo de trabajo en un entorno de producción o comparte la solución con otros usuarios, recuerde reemplazar las claves codificadas de forma rígida por otras cifradas o de seguridad integradas.
Paso 1: Crear un clúster y un cuaderno de Spark
En esta sección, cree un clúster, instale la biblioteca synapseml y cree un cuaderno para ejecutar el código.
En Azure Portal, busque el área de trabajo de Azure Databricks y seleccione Iniciar área de trabajo.
En el menú de la izquierda, seleccione Proceso.
Seleccione Crear proceso.
Acepte la configuración predeterminada. La creación del clúster tarda varios minutos.
Instale la biblioteca
synapsemldespués de crear el clúster:Seleccione Bibliotecas en las pestañas de la parte superior de la página del clúster.
Seleccione Instalar nueva.
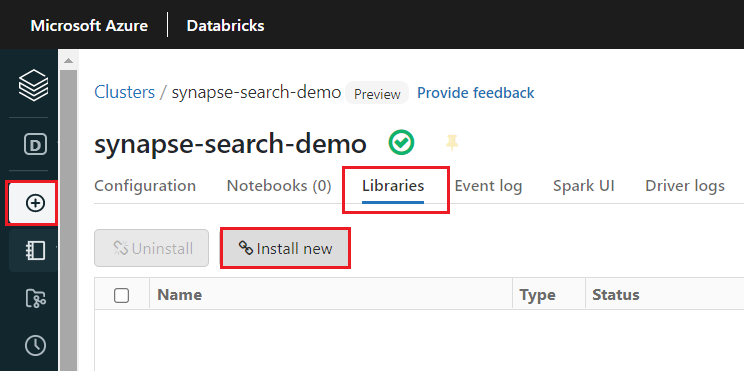
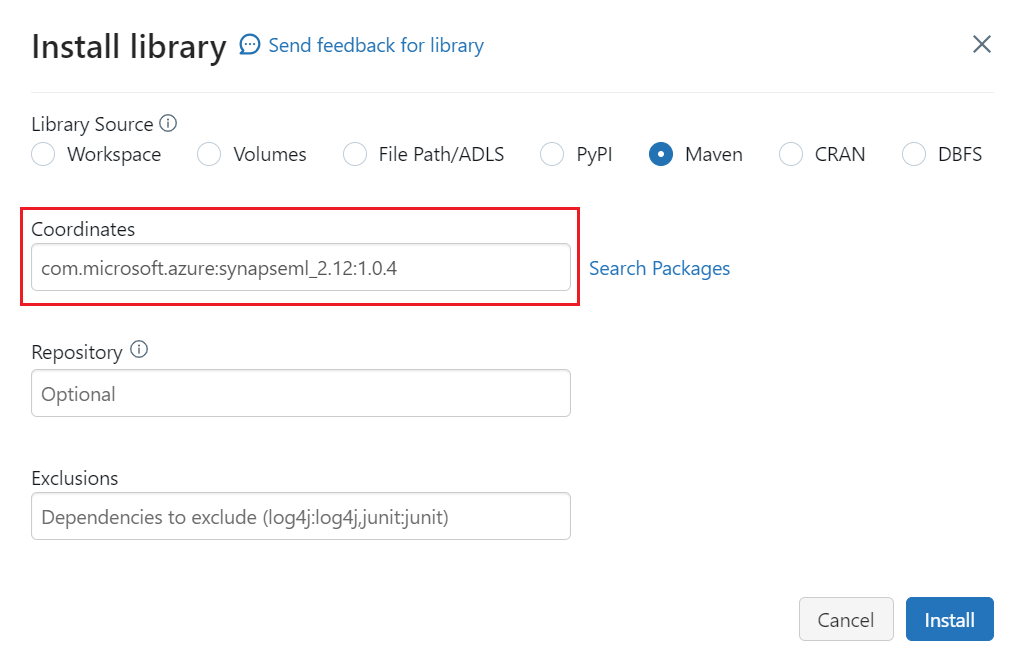
Seleccione Maven.
En Coordenadas, escriba
com.microsoft.azure:synapseml_2.12:1.0.4.Seleccione Instalar.
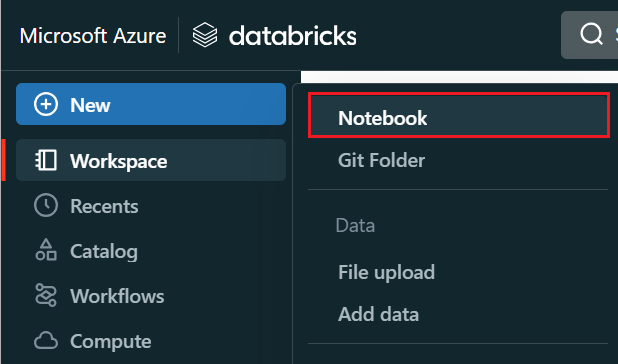
En el menú de la izquierda, seleccione Crear>cuaderno.
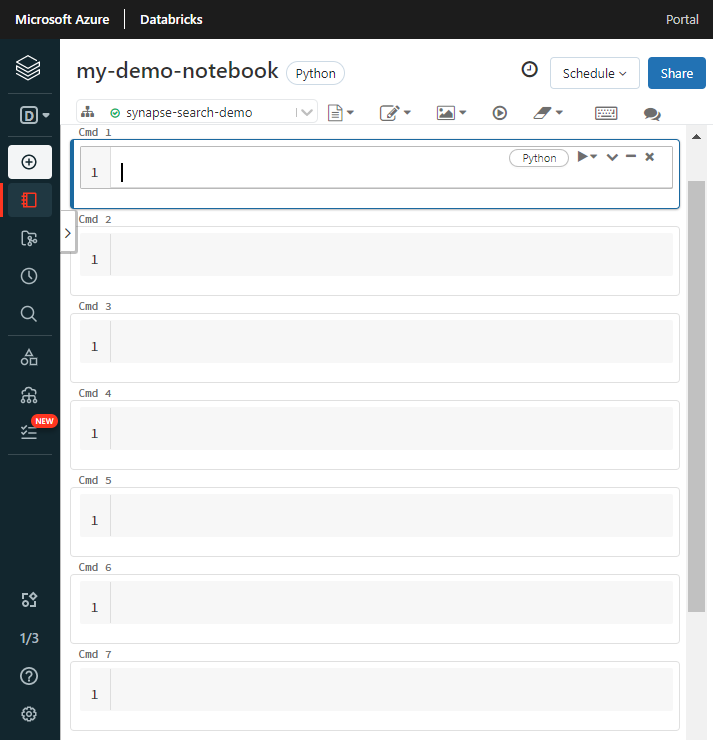
Asígnele un nombre al cuaderno, seleccione Python como lenguaje predeterminado y, después, el clúster que tiene la biblioteca
synapseml.Cree siete celdas consecutivas. Pegue código en cada una de ellas.
Paso 2: Configurar dependencias
Pegue el siguiente código en la primera celda del cuaderno.
Reemplace los marcadores de posición por los puntos de conexión y las claves de acceso de cada recurso. Proporcione un nombre para un nuevo índice de búsqueda. No se requieren otras modificaciones, por lo que podrá ejecutar el código cuando esté listo.
Este código importa múltiples paquetes y configura el acceso a los recursos de Azure de este flujo de trabajo.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
Paso 3: Cargar datos en Spark
Pegue el código siguiente en la segunda celda. No se requieren modificaciones, por lo que podrá ejecutar el código cuando esté listo.
Este código carga algunos archivos externos de una cuenta de almacenamiento de Azure. Los archivos son varias facturas y se leen en una trama de datos.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Paso 4: Agregar documento de inteligencia
Pegue el código siguiente en la tercera celda. No se requieren modificaciones, por lo que podrá ejecutar el código cuando esté listo.
Este código carga el transformador AnalyzeInvoices y pasa una referencia a la trama de datos que contiene las facturas. Llama al modelo de factura precompilado de Documento de inteligencia de Azure AI para extraer información de las facturas.
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
La salida de este paso debe ser similar a la siguiente captura de pantalla. Observe cómo el análisis de formularios se empaqueta en una columna densamente estructurada, con la que es difícil trabajar. La siguiente transformación resuelve este problema mediante el análisis de la columna en filas y columnas.
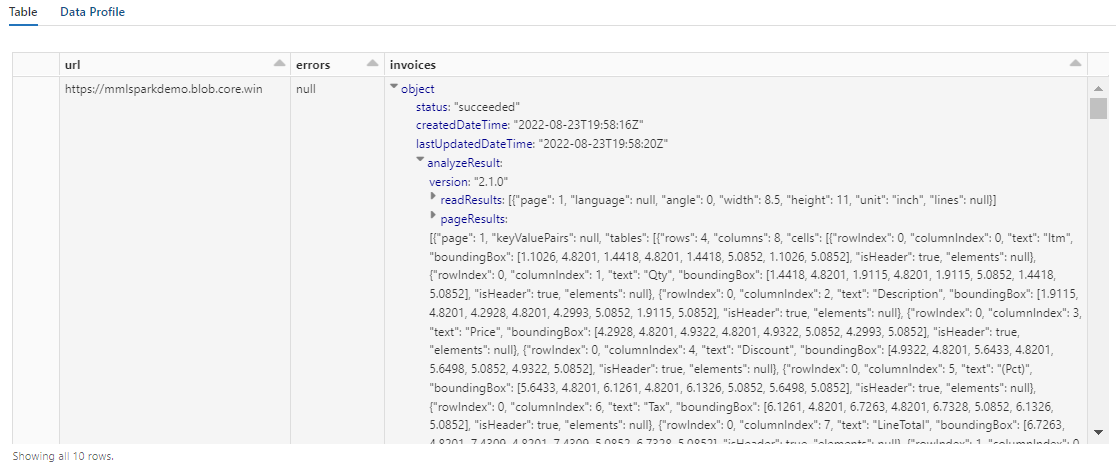
Paso 5: Reestructurar la salida del documento de inteligencia
Pegue el código siguiente en la cuarta celda y ejecútelo. No se necesitan modificaciones.
Este código carga FormOntologyLearner, un transformador que analiza la salida de los transformadores de Document Intelligence y deduce una estructura de datos tabulares. La salida de AnalyzeInvoices es dinámica y varía en función de las características detectadas en el contenido. Además, el transformador consolida la salida en una sola columna. Dado que la salida es dinámica y consolidada, es difícil de usar en transformaciones de bajada que requieren más estructura.
FormOntologyLearner amplía la utilidad del transformador AnalyzeInvoices buscando patrones que se puedan usar para crear una estructura de datos tabulares. La organización de la salida en varias columnas y filas hace que el contenido se pueda consumir en otros transformadores, como AzureSearchWriter.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
Observe cómo esta transformación vuelve a convertir los campos anidados en una tabla, lo que permite las dos transformaciones siguientes. Esta captura de pantalla se recorta para mayor brevedad. Si va a seguir en su propio cuaderno, tendrá 19 columnas y 26 filas.
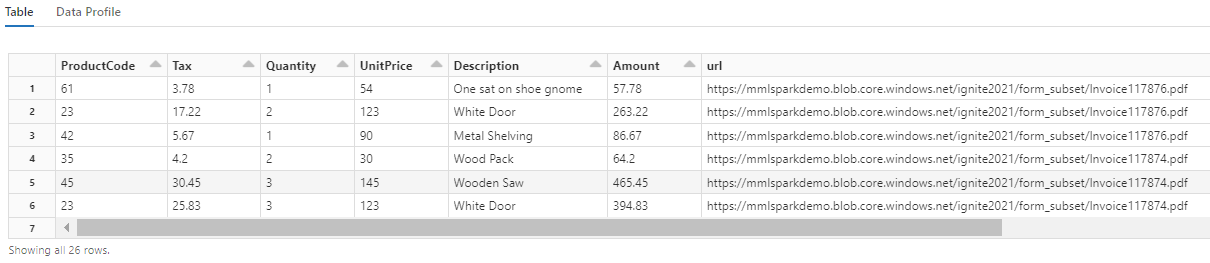
Paso 6: Agregar traducciones
Pegue el código siguiente en la quinta celda. No se requieren modificaciones, por lo que podrá ejecutar el código cuando esté listo.
Este código carga Translate, un transformador que llama al servicio Traductor de Azure AI de servicios de Azure AI. El texto original, que se encuentra en inglés en la columna "Description", se traduce automáticamente a varios idiomas. Toda la salida se consolida en la matriz "output.translations".
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
Sugerencia
Para comprobar las cadenas traducidas, desplácese hasta el final de las filas.
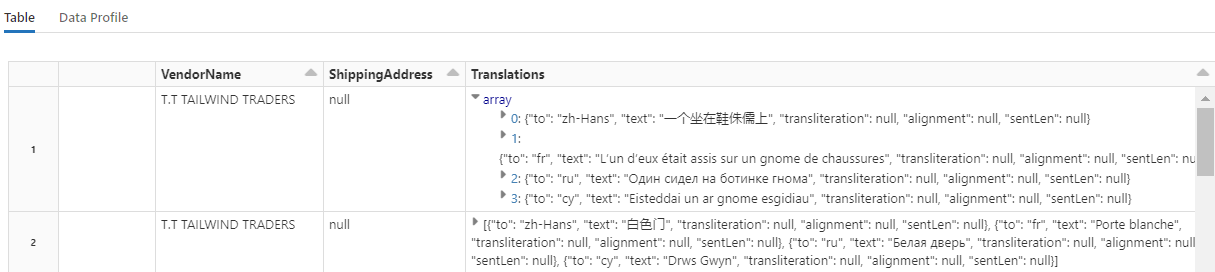
Paso 7: Agregar un índice de búsqueda con AzureSearchWriter
Pegue el código siguiente en la sexta celda y ejecútelo. No se necesitan modificaciones.
Este código carga AzureSearchWriter. Consume un conjunto de datos tabular y deduce un esquema de índice de búsqueda que define un campo para cada columna. Ya que la estructura de las traducciones es una matriz, esta se articula en el índice como una colección compleja con subcampos para cada idioma traducido. El índice generado tiene una clave de documento y usa los valores predeterminados para los campos creados mediante la API de REST de creación de índices.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
Puede comprobar las páginas del servicio de búsqueda en Azure Portal para explorar la definición de índice creada por AzureSearchWriter.
Nota
Si no puede usar el índice de búsqueda predeterminado, puede proporcionar una definición personalizada externa en JSON, pasando su URI como una cadena en la propiedad "indexJson". Genere primero el índice predeterminado para que sepa qué campos especificar y, después, siga con las propiedades personalizadas si necesita analizadores específicos, por poner un ejemplo.
Paso 8: Consultar el índice
Pegue el código siguiente en la séptima celda y ejecútelo. No se requieren modificaciones, salvo que es posible que desee modificar la sintaxis o probar más ejemplos para explorar aún más el contenido:
No hay ningún transformador o módulo que emite consultas. Esta celda es una llamada sencilla a la API de REST Buscar documentos.
En este ejemplo concreto se busca la palabra "door" ("search": "door"). También devuelve un "recuento" del número de documentos coincidentes y selecciona solo el contenido de los campos "Descripción" y "Traducciones" para los resultados. Si desea ver la lista completa de campos, quite el parámetro "select".
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
En la captura de pantalla siguiente se muestra la salida de celda del script de ejemplo.
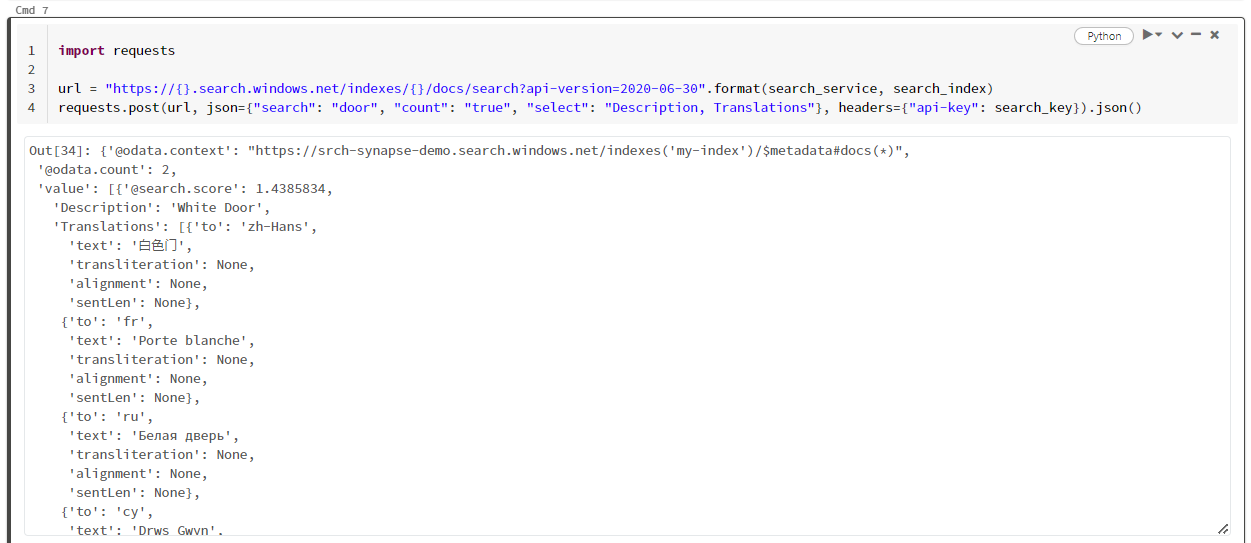
Limpieza de recursos
Cuando trabaje con su propia suscripción, al final de un proyecto, es recomendable eliminar los recursos que ya no necesite. Los recursos que se dejan en ejecución pueden costarle mucho dinero. Puede eliminar los recursos de forma individual o eliminar el grupo de recursos para eliminar todo el conjunto de recursos.
Puede encontrar y administrar recursos en el portal, mediante el vínculo Todos los recursos o Grupos de recursos en el panel de navegación izquierdo.
Pasos siguientes
En este tutorial, ha obtenido información sobre el transformador AzureSearchWriter en SynapseML, que es una nueva forma de crear y cargar índices de búsqueda en Azure AI Search. El transformador toma JSON estructurado como entrada. FormOntologyLearner puede proporcionar la estructura necesaria para la salida generada por los transformadores de Document Intelligence en SynapseML.
Como paso siguiente, consulte otros tutoriales de SynapseML que generan contenido transformado que puede explorar mediante Azure AI Search: