Implementación de un clúster administrado de Service Fabric en zonas de disponibilidad
Las zonas de disponibilidad de Azure son una función de alta disponibilidad que protege las aplicaciones y los datos frente a errores del centro de datos. Una zona de disponibilidad es una ubicación física única equipada con alimentación independiente, refrigeración y redes dentro de una región de Azure.
El clúster administrado de Service Fabric admite implementaciones que abarcan varias zonas de disponibilidad para proporcionar resistencia de zona. Esta configuración garantiza la alta disponibilidad de los servicios críticos del sistema y las aplicaciones para protegerse frente a puntos de error únicos. Azure Availability Zones solo está disponible en algunas regiones. Consulte Azure Availability Zones Overview (Información general de Azure Availability Zones).
Nota:
La distribución de zonas de disponibilidad solo está disponible en clústeres de SKU Estándar.
Están disponibles plantillas de ejemplo: Plantilla de Service Fabric en zona de disponibilidad
Topología para clústeres administrados de Azure Service Fabric resistentes a zonas
Nota
La ventaja de abarcar el tipo de nodo principal entre zonas de disponibilidad solo se ve para tres zonas y no solo dos.
Un clúster de Service Fabric distribuido en Availability Zones (AV) garantiza el estado de alta disponibilidad del clúster.
La topología recomendada para el clúster administrado requiere los recursos siguientes:
- La SKU de clúster debe ser Estándar.
- El tipo de nodo principal debe tener al menos nueve nodos (3 en cada zona de disponibilidad) para obtener la mejor resistencia, aunque se admite un número mínimo de seis (2 en cada zona de disponibilidad).
- Los tipos de nodos secundarios deben tener al menos seis nodos para obtener la mejor resistencia, aunque se admite un número mínimo de tres.
Nota:
Solo se admiten tres implementaciones de zona de disponibilidad.
Nota:
No es posible realizar un cambio local de conjuntos de escalado de máquinas virtuales en un clúster administrado en el que se pase de un clúster no distribuido a uno distribuido.
Diagrama en el que se muestra la arquitectura de zonas de disponibilidad de Azure Service Fabric 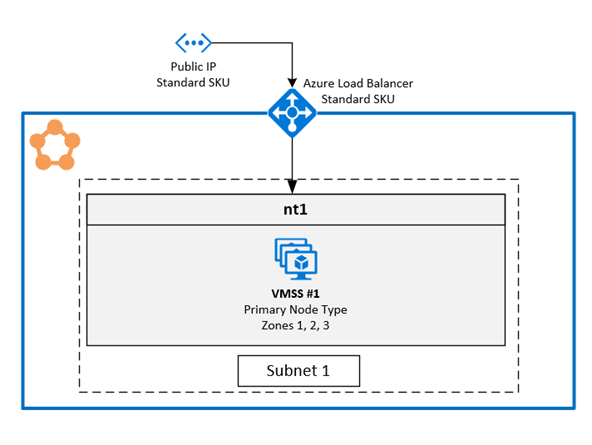
Lista de nodos de ejemplo que muestra los formatos FD/UD en las zonas de extensión de un conjunto de escalado de máquinas virtuales.
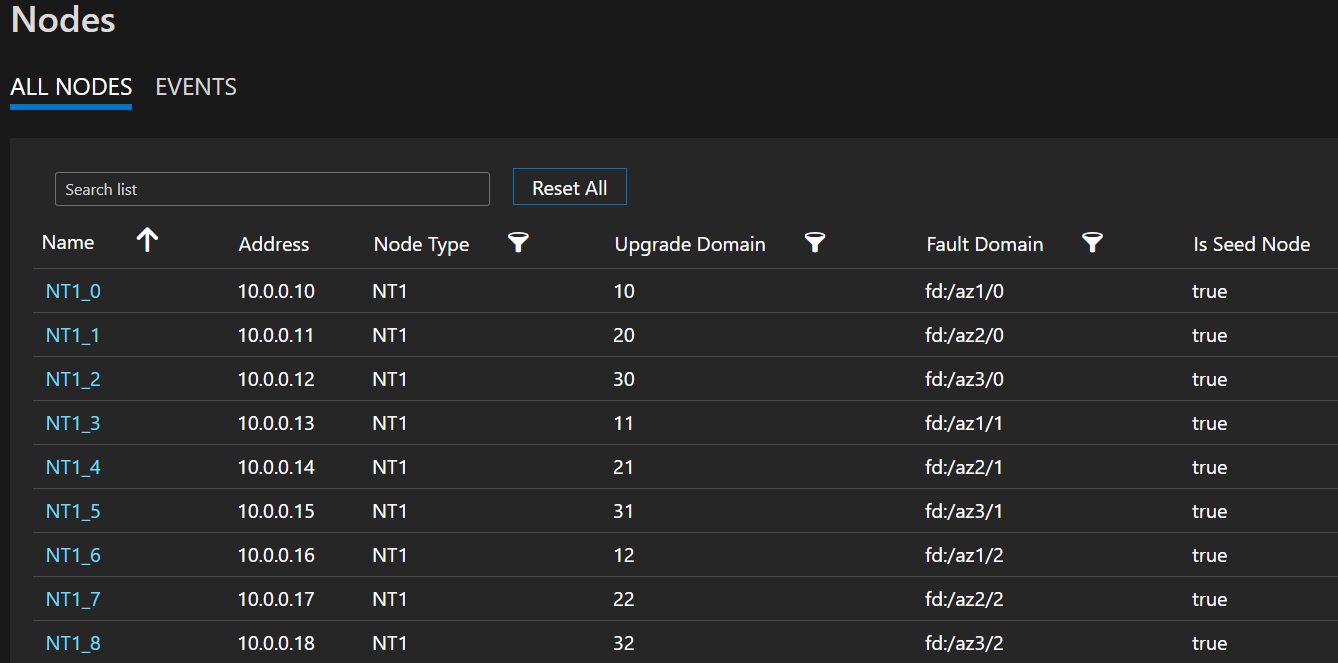
Distribución de las réplicas de servicio entre zonas: cuando se implementa un servicio en los tipos de nodo que son zonas distribuidas, las réplicas se colocan de modo que se garantice que están en zonas independientes. Esta separación está garantizada, ya que los dominios de error en los nodos presentes en cada uno de estos tipos de nodo se configuran con la información de zona (es decir, FD = fd:/zone1/1, etc.). Por ejemplo: para cinco réplicas o instancias de un servicio, la distribución es 2-2-1 y el runtime intenta asegurarse de que la distribución sea la misma en las zonas de disponibilidad.
Configuración de la réplica de servicio de usuario: los servicios de usuario con estado implementados en los tipos de nodo de zona de disponibilidad cruzada deben configurarse con esta opción: recuento de réplicas con destino = 9, min = 5. Esta configuración ayuda a garantizar que el servicio funcione incluso cuando una zona deje de funcionar, ya que las seis réplicas seguirán activas en las otras dos zonas. Una actualización de la aplicación en este escenario también se realizará.
Escenario de una zona que no funciona: cuando una zona deja de funcionar, todos los nodos de esa zona aparecen como inactivos. Las réplicas de servicio en estos nodos también estarán inactivas. Dado que hay réplicas en las otras zonas, el servicio sigue teniendo capacidad de respuesta con las réplicas principales que conmutan por error a las zonas que funcionan. Los servicios aparecerán en estado de advertencia, ya que el número de réplicas de destino no se ha alcanzado y el número de máquinas virtuales todavía es mayor que el tamaño mínimo de réplica de destino definido. Como resultado, el equilibrador de carga de Service Fabric abre réplicas en las zonas en funcionamiento para que coincidan con el número de réplicas de destino configurado. En este momento, los servicios deben aparecer en buen estado. Cuando la zona que estaba inactiva vuelva a funcionar, el equilibrador de carga volverá a distribuir todas las réplicas de servicio uniformemente en todas las zonas.
Configuración de redes
Para obtener más información, consulte Configuración de la red para clústeres administrados de Service Fabric.
Habilitación de un clúster administrado de Azure Service Fabric resistente a zona
Para habilitar un clúster administrado de Azure Service Fabric resistente a la zona, debe incluir la siguiente propiedad ZonalResiliency, que especifica si el clúster es resistente a la zona o no.
{
"apiVersion": "2021-05-01",
"type": "Microsoft.ServiceFabric/managedclusters",
"properties": {
...
"zonalResiliency": "true",
...
}
}
Migración de un clúster existente sin resistencia de zona a con resistencia de zona (versión preliminar)
Los clústeres administrados de Service Fabric existentes que no se extienden en zonas de disponibilidad ahora se pueden migrar de forma local para extenderse en zonas de disponibilidad. Los escenarios admitidos incluyen clústeres creados en regiones que tienen tres zonas de disponibilidad, así como clústeres de regiones en las que hay disponibles tres zonas de disponibilidad después de la implementación.
Requisitos:
- Clúster de SKU Estándar.
- Tres zonas de disponibilidad en la región.
Nota:
La migración a una configuración con resistencia de zona puede causar una pérdida breve de conectividad externa a través del equilibrador de carga, pero no afecta al estado del clúster. Esto ocurre cuando es necesario crear una nueva dirección IP pública para que las redes sean resistentes a los errores de zona. Planee la migración en consecuencia.
Comience por determinar si se requiere una nueva dirección IP y qué recursos se deben migrar para que sean resistentes a zona. Para obtener el estado de resistencia actual de la zona de disponibilidad de los recursos del clúster administrado, use la siguiente llamada API:
POST https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.ServiceFabric/managedClusters/{clusterName}/getazresiliencystatus?api-version=2022-02-01-previewO bien, puede usar el módulo Az de la siguiente manera:
Select-AzSubscription -SubscriptionId {subscriptionId} Invoke-AzResourceAction -ResourceId /subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.ServiceFabric/managedClusters/{clusterName} -Action getazresiliencystatus -ApiVersion 2022-02-01-previewEl comando debe proporcionar una respuesta similar a la siguiente:
{ "baseResourceStatus" :[ { "resourceName": "sfmccluster1" "resourceType": "Microsoft.Storage/storageAccounts" "isZoneResilient": false }, { "resourceName": "PublicIP-sfmccluster1" "resourceType": "Microsoft.Network/publicIPAddresses" "isZoneResilient": false }, { "resourceName": "primary" "resourceType": "Microsoft.Compute/virutalmachinescalesets" "isZoneResilient": false } ], "isClusterZoneResilient": false }Si el recurso de IP pública no es resistente a zona, la migración del clúster provoca una breve pérdida de conectividad externa. Esta pérdida de conexión se debe a que la migración configura una nueva dirección IP pública y actualiza el nombre de dominio completo (FQDN) del clúster a la nueva dirección IP. Si el recurso de dirección IP pública es resistente a zona, la migración no modificará el recurso de IP pública ni el FQDN, y no habrá ningún impacto sobre la conectividad externa.
Inicie la conversión de la cuenta de almacenamiento subyacente creada para el clúster administrado desde el almacenamiento con redundancia local (LRS) al almacenamiento con redundancia de zona (ZRS) mediante la conversión iniciada por el cliente. El grupo de recursos de la cuenta de almacenamiento que debe migrarse tendría el formato "SFC_ClusterId" (por ejemplo, SFC_9240df2f-71ab-4733-a641-53a846464d992d) en la misma suscripción que el recurso de clúster administrado.
Agregar una propiedad de zonas a los tipos de nodo existentes
Este paso configura el conjunto de escalado de máquinas virtuales administrado asociado al tipo de nodo como resistente a la zona, lo que garantiza que todas las máquinas virtuales nuevas agregadas se implementarán en zonas de disponibilidad (máquinas virtuales zonales). Si el tipo de nodo especificado es el principal, el proveedor de recursos realizará la migración de la dirección IP pública junto con una actualización de DNS de FQDN del clúster, si fuera necesario, para que sea resistente a zona. Use la API
getazresiliencystatuspara comprender las implicaciones de este paso.
Use apiVersion 2022-02-01-preview o posterior.
Agregue el parámetro
zonesestablecido en["1", "2", "3"]a los tipos de nodo existentes:{ "apiVersion": "2024-02-01-preview", "type": "Microsoft.ServiceFabric/managedclusters/nodetypes", "name": "[concat(parameters('clusterName'), '/', parameters('nodeTypeName'))]", "location": "[resourcegroup().location]", "dependsOn": [ "[concat('Microsoft.ServiceFabric/managedclusters/', parameters('clusterName'))]" ], "properties": { ... "isPrimary": true, "zones": ["1", "2", "3"] ... } }, { "apiVersion": "2024-02-01-preview", "type": "Microsoft.ServiceFabric/managedclusters/nodetypes", "name": "[concat(parameters('clusterName'), '/', parameters('nodeTypeNameSecondary'))]", "location": "[resourcegroup().location]", "dependsOn": [ "[concat('Microsoft.ServiceFabric/managedclusters/', parameters('clusterName'))]" ], "properties": { ... "isPrimary": false, "zones": ["1", "2", "3"] ... } }
Escale los tipos de nodos para agregar nodos zonales y quitar nodos regionales
En esta fase, Virtual Machine Scale Sets se marca como resistente a zonas. Por lo tanto, al escalar verticalmente, los nodos recién agregados serán zonales y, al reducir verticalmente, se quitarán los nodos regionales. Este enfoque proporciona la flexibilidad para escalar en cualquier orden que se alinee con los requisitos de capacidad ajustando la propiedad
vmInstanceCounten los tipos de nodo.Por ejemplo, si vmInstanceCount inicial está establecido en 6 (lo que indica seis nodos regionales), puede realizar dos implementaciones:
- Primera implementación: aumente vmInstanceCount a 12 para agregar 6 nodos zonales.
- Segunda implementación: reduzca vmInstanceCount a 6 para quitar todos los nodos regionales.
A lo largo del proceso, puede comprobar la API
getazresiliencystatuspara recuperar el estado del progreso, como se muestra a continuación. El proceso se considera completado una vez que cada tipo de nodo tiene un mínimo de seis nodos zonales y cero nodos regionales.{ "baseResourceStatus" :[ { "resourceName": "sfmccluster1" "resourceType": "Microsoft.Storage/storageAccounts" "isZoneResilient": true }, { "resourceName": "PublicIP-sfmccluster1" "resourceType": "Microsoft.Network/publicIPAddresses" "isZoneResilient": true }, { "resourceName": "ntPrimary" "resourceType": "Microsoft.Compute/virutalmachinescalesets" "isZoneResilient": false "details": "Status: InProgress, ZonalNodes: 6, RegionalNodes: 6" }, { "resourceName": "ntSecondary" "resourceType": "Microsoft.Compute/virutalmachinescalesets" "isZoneResilient": true "details": "Status: Done, ZonalNodes: 6, RegionalNodes: 0" } ], "isClusterZoneResilient": false }Nota:
El proceso de escalado del tipo de nodo principal requerirá tiempo adicional, ya que cada adición o eliminación de un nodo iniciará una actualización del clúster de Service Fabric.
Marcado del clúster resistente a errores de zona
Este paso ayuda en futuras implementaciones, ya que garantiza que todas las implementaciones futuras de tipos de nodo abarquen zonas de disponibilidad y, por tanto, el clúster siga siendo tolerante a errores de AZ. Establezca
zonalResiliency: trueen la plantilla de ARM del clúster y realice una implementación para marcar el clúster como resistente a zona, y asegúrese de que todas las nuevas implementaciones de tipos de nodos se distribuyan en zonas de disponibilidad. Esta actualización solo se permite si todos los tipos de nodo tienen al menos seis nodos zonales y cero nodos regionales.{ "apiVersion": "2022-02-01-preview", "type": "Microsoft.ServiceFabric/managedclusters", "zonalResiliency": "true" }También puede ver el estado actualizado en el portal, en Información general -> Propiedades similares a
Zonal resiliency True, una vez completado.Validación de que todos los recursos son resistentes a zona
Para comprobar el estado de resistencia de la zona de disponibilidad de los recursos del clúster administrado, use la siguiente llamada API GET:
POST https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.ServiceFabric/managedClusters/{clusterName}/getazresiliencystatus?api-version=2022-02-01-previewEsta llamada API debe proporcionar una respuesta similar a la siguiente:
{ "baseResourceStatus" :[ { "resourceName": "sfmccluster1" "resourceType": "Microsoft.Storage/storageAccounts" "isZoneResilient": true }, { "resourceName": "PublicIP-sfmccluster1" "resourceType": "Microsoft.Network/publicIPAddresses" "isZoneResilient": true }, { "resourceName": "ntPrimary" "resourceType": "Microsoft.Compute/virutalmachinescalesets" "isZoneResilient": true "details": "Status: Done, ZonalNodes: 6, RegionalNodes: 0" }, { "resourceName": "ntSecondary" "resourceType": "Microsoft.Compute/virutalmachinescalesets" "isZoneResilient": true "details": "Status: Done, ZonalNodes: 6, RegionalNodes: 0" } ], "isClusterZoneResilient": true }Si tiene algún problema, póngase en contacto con el soporte técnico para obtener ayuda.
Habilitar FastZonalUpdate en clústeres administrados de Service Fabric (versión preliminar)
Los clústeres administrados de Service Fabric admiten actualizaciones de aplicaciones y clústeres más rápidos al reducir el número máximo de dominios de actualización por zona de disponibilidad. La configuración predeterminada ahora mismo puede tener como máximo 15 dominios de actualización (UD) en varios tipos de nodo AZ. Este gran número de UD redujo la velocidad de actualización. La nueva configuración reduce los UD máximos, lo que se traduce en actualizaciones más rápidas, manteniendo intacta la seguridad de las actualizaciones.
La actualización se debe realizar a través de la plantilla de ARM estableciendo la propiedad zonalUpdateMode en "rápido" y, a continuación, modificando un atributo de tipo de nodo, como agregar un nodo y, a continuación, quitar el nodo a cada tipo de nodo (consulte los pasos necesarios 2 y 3). El valor de apiVersion del recurso de clúster administrado de Service Fabric debe ser 2022-10-01-preview o posterior.
- Modifique la plantilla de ARM con la nueva propiedad zonalUpdateMode.
"resources": [
{
"type": "Microsoft.ServiceFabric/managedClusters",
"apiVersion": "2022-10-01-preview",
'''
"properties": {
'''
"zonalResiliency": true,
"zonalUpdateMode": "fast",
...
}
}]
Agregue un nodo a un clúster mediante el comando az sf cluster node add PowerShell.
Quite un nodo de un clúster mediante el comando az sf cluster node remove PowerShell.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de