Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Service Fabric está construido con subsistemas en capas. Este subsistema permiten escribir aplicaciones con las siguientes características:
- Alta disponibilidad
- Escalable
- Capacidad de administración
- Con capacidad de prueba
En el diagrama siguiente, se muestran los subsistemas principales de Service Fabric.
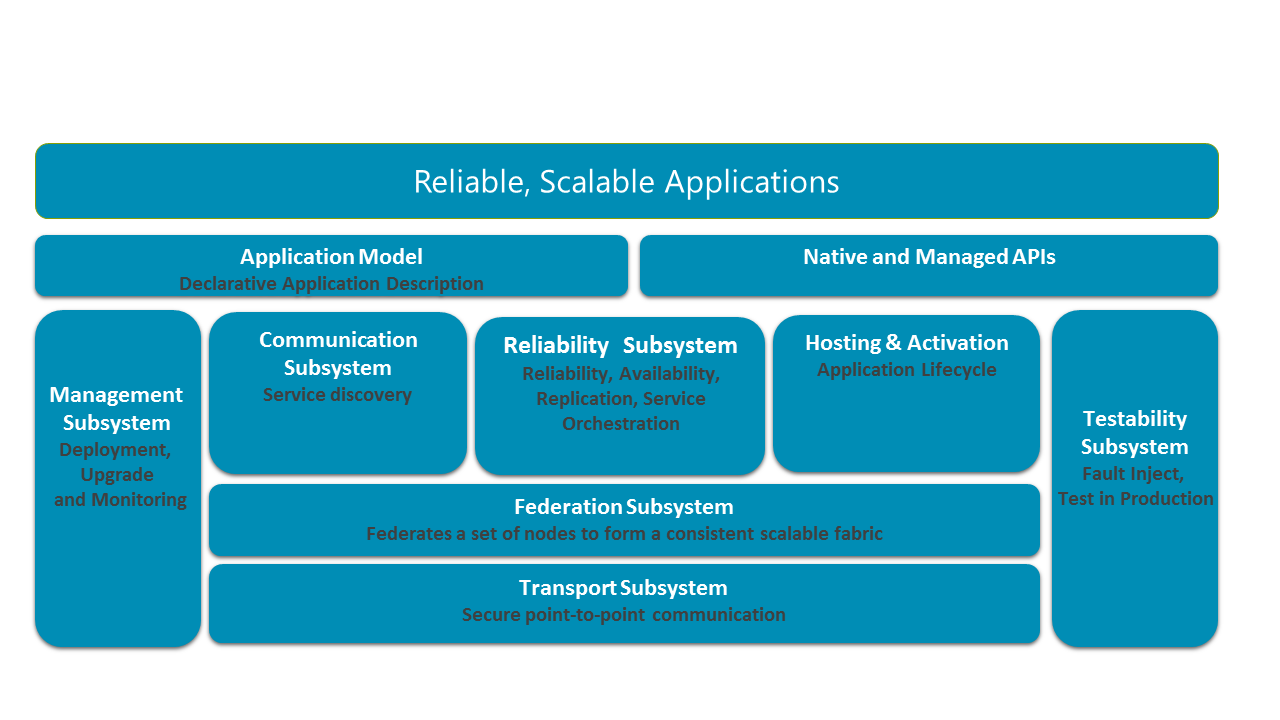
En un sistema distribuido, es fundamental que se puedan establecer comunicaciones seguras entre los nodos de un clúster. En la base de la pila está el subsistema de transporte, que proporciona una comunicación segura entre los nodos. Por encima del subsistema de transporte se encuentra el subsistema de federación, que agrupa los diferentes nodos en una entidad única (denominada "clústeres") para que Service Fabric pueda encontrar errores, realizar la elección del líder y ofrecer un enrutamiento coherente. El subsistema de confiabilidad, superpuesto encima del subsistema de federación, es responsable de la confiabilidad de los servicios de Service Fabric a través de mecanismos como la replicación, la administración de recursos y las conmutaciones por error. El subsistema de federación también es subyacente a los subsistemas de hospedaje y de activación, que administran el ciclo de vida de una aplicación en un nodo único. El subsistema de administración se encarga del ciclo de vida de las aplicaciones y los servicios. El subsistema de comprobación ayuda a los desarrolladores de aplicaciones a probar sus servicios a través de simulaciones de error antes y después de implementar aplicaciones y servicios en entornos de producción. Service Fabric permite resolver ubicaciones de servicio a través de su subsistema de comunicación. Los modelos de programación de aplicaciones expuestos a los desarrolladores se superponen encima de estos subsistemas junto con el modelo de aplicaciones para habilitar las herramientas.
Subsistema de transporte
El subsistema de transporte implementa un canal de comunicación de datagramas punto a punto. Este canal se usa para la comunicación dentro del clúster de Service Fabric y la comunicación entre los clientes y el clúster de Service Fabric. Admite un patrón de comunicación unidireccional y de solicitud-respuesta, que ofrece la base para la implementación de la difusión y la multidifusión en la capa de federación. El subsistema de transporte protege la comunicación mediante el uso de certificados X509 o la seguridad de Windows. Service Fabric usa este subsistema internamente, y los desarrolladores no pueden acceder a él directamente para programar aplicaciones.
Subsistema de federación
Para analizar un conjunto de nodos en un sistema distribuido, hay que tener una perspectiva coherente del sistema. El subsistema de federación usa los elementos primitivos de comunicación ofrecidos por el subsistema de transporte y une los diversos nodos en un solo clúster unificado que puede analizar. Ofrece los tipos primitivos de sistemas distribuidos necesarios por los demás subsistemas: detección de errores, elección de líder y enrutamiento coherente. El subsistema de federación se basa en tablas hash distribuidas con un espacio de token de 128 bits. El subsistema crea una topología en anillo en los nodos, donde a cada nodo del anillo se le asigna un subconjunto del espacio de token para la propiedad. Para la detección de errores, la capa usa un mecanismo de concesión basándose en el arbitraje y los latidos. El subsistema de federación también garantiza, a través de intricados protocolos de salida y de combinación que solo existe un propietario único de un token en cualquier momento. Esto nos permite elegir al líder y ofrece garantías de enrutamiento coherentes.
Subsistema de confiabilidad
El subsistema de confiabilidad ofrece el mecanismo para hacer que el estado de un servicio de Service Fabric tenga una disponibilidad alta mediante el uso del Replicador, el Administrador de conmutación por error y el Equilibrador de recursos.
- El Replicador garantiza que los cambios de estado de la réplica de servicio principal se replicarán automáticamente en las réplicas secundarias, manteniendo la coherencia entre las réplicas principal y secundaria en un conjunto de réplicas del servicio. El Replicador es responsable de la administración de cuórum entre las réplicas del conjunto de réplicas. Interactúa con la unidad de conmutación por error para obtener la lista de las operaciones que se van a replicar y el agente de reconfiguración la ofrece con la configuración del conjunto de réplicas. Dicha configuración indica en qué réplicas deben replicarse las operaciones. Service Fabric ofrece un replicador predeterminado denominado Replicador de Fabric, que puede usar la API del modelo de programación para hacer que el estado del servicio sea confiable y de alta disponibilidad.
- El Administrador de conmutación por error garantiza que, cuando los nodos se agregan al clúster o se eliminan de él, la carga se redistribuye automáticamente entre los nodos disponibles. Si se produce un error en un nodo del clúster, el clúster reconfigurará automáticamente las réplicas de servicio para mantener la disponibilidad.
- Resource Manager coloca las réplicas de servicio en todos los dominios de errores del clúster y garantiza que todas las unidades de conmutación por error estén operativas. Resource Manager también equilibra los recursos de los servicios a través del grupo compartido subyacente de nodos del clúster para lograr una distribución de carga óptima y uniforme.
Subsistema de administración
El subsistema de administración ofrece la administración del ciclo de vida de aplicaciones y servicios integral. Los cmdlets de PowerShell y las API administrativas permiten aprovisionar, implementar, aplicar revisiones, actualizar y desaprovisionar aplicaciones sin pérdida de disponibilidad. El subsistema de administración realiza esto a través de los siguientes servicios.
- Administrador de clústeres: se trata del servicio principal que interactúa con el Administrador de conmutación por error para colocar las aplicaciones en los nodos según las restricciones de posición del servicio. Resource Manager en el subsistema de conmutación por error garantiza que las restricciones no se interrumpen nunca. El administrador de clústeres administra el ciclo de vida de las aplicaciones desde el aprovisionamiento hasta el desaprovisionamiento. Se integra con el administrador de estado para garantizar que no se pierda la disponibilidad de las aplicaciones desde una perspectiva de estado semántica durante las actualizaciones.
- Administrador de estado: este servicio habilita la supervisión del mantenimiento de aplicaciones, servicios y entidades de clúster. Las entidades de clúster (como nodos, particiones de servicio y réplicas) pueden notificar la información de estado, que se agrega luego al almacén de estado centralizado. Esta información de estado ofrece una instantánea del estado general a un momento dado de los servicios y nodos distribuidos en varios nodos del clúster, lo que le permite realizar las acciones correctivas necesarias. Las API de consulta de estado permiten consultar los eventos de estado registrados en el subsistema de estado. Las API de consulta de estado devuelven los datos de estado sin procesar guardados en el almacén de estado o los datos de estado interpretados y agregados para una entidad de clúster específica.
- Almacén de imágenes: este servicio permite almacenar y distribuir los archivos binarios de la aplicación. Este servicio ofrece un almacén de archivos distribuido simple donde se cargan las aplicaciones y desde donde se descargan.
Subsistema de hospedaje
El administrador de clústeres informa al subsistema de hospedaje (que se ejecuta en cada nodo) de qué servicios necesita administrar para un nodo concreto. El subsistema de hospedaje administra después el ciclo de vida de la aplicación en ese nodo. Interactúa con los componentes de confiabilidad y mantenimiento para garantizar que las réplicas se colocan correctamente y que son correctas.
Subsistema de comunicación
Este subsistema ofrece mensajería confiable en la detección de clústeres y servicios a través del servicio de nombres. El servicio de nombres resuelve los nombres de servicio en una ubicación del clúster y permite a los usuarios administrar las propiedades y los nombres de servicio. Con el servicio de nombres, los clientes pueden comunicarse con seguridad con cualquier nodo del clúster para resolver un nombre de servicio y recuperar metadatos del servicio. Mediante una API de cliente de nomenclatura simple, los usuarios de Service Fabric pueden desarrollar servicios y clientes capaces de resolver la ubicación de red actual a pesar del dinamismo de los nodos o el cambio de tamaño del clúster.
Subsistema de capacidad de prueba
La capacidad de prueba es un conjunto de herramientas diseñadas de manera específica para probar los servicios de pruebas basados en Service Fabric. Las herramientas permiten al desarrollador provocar fácilmente errores significativos y ejecutar escenarios de prueba para ejercer y validar los numerosos estados y transiciones que experimentará un servicio durante su vigencia, y todo ello de forma segura y controlada. La comprobación también ofrece un mecanismo para ejecutar pruebas más largas que pueden iterar a través de varios errores posibles sin perder la disponibilidad. Esto le ofrece un entorno de producción en pruebas.