Descripción de un clúster de Service Fabric con Cluster Resource Manager
La característica Cluster Resource Manager de Azure Service Fabric proporciona varios mecanismos para describir un clúster:
- Dominios de error
- Dominios de actualización
- Propiedades del nodo
- Capacidades de nodo
Durante el tiempo de ejecución, Cluster Resource Manager usa esta información para garantizar la alta disponibilidad de los servicios que se ejecutan en el clúster. Al aplicar estas reglas importantes, también intenta optimizar el consumo de recursos del clúster.
Dominios de error
Un dominio de error es cualquier área de error coordinado. Una única máquina constituye un dominio de error. Esto se debe a que ella sola puede dejar de funcionar por muchas razones diferentes, desde errores en el sistema de alimentación hasta unidades averiadas o un firmware de NIC defectuoso.
Hay varias máquinas conectadas al mismo conmutador Ethernet que se encuentran en el mismo dominio de error. Por lo tanto, son máquinas que comparten una única fuente de alimentación o una sola ubicación.
Debido a que es natural que coincidan averías de hardware, los dominios de error son intrínsecamente jerárquicos. Se representan como URI en Service Fabric.
Es importante que los dominios de error se configuren correctamente porque Service Fabric usa esta información para colocar servicios de forma segura. Service Fabric no quiere volver a colocar los servicios de forma que la pérdida de un dominio de error (causado por la avería de algún componente) provoque que un servicio deje de funcionar.
En el entorno de Azure, Service Fabric aprovecha la información sobre dominios de error que proporciona dicho entorno para configurar automáticamente correctamente los nodos del clúster. En el caso de las instancias independientes de Service Fabric, los dominios de error se definen en el momento en que se configura el clúster.
Advertencia
Es importante que la información de dominio de error proporcionada a Service Fabric sea precisa. Por ejemplo, supongamos que los nodos del clúster de Service Fabric se ejecutan dentro de 10 máquinas virtuales, en 5 hosts físicos. En este caso, a pesar de que hay 10 máquinas virtuales, hay solo 5 dominios de error diferentes (nivel superior). Compartir el mismo host físico hace que las VM compartan el mismo dominio de error de raíz, dado que las máquinas virtuales experimentan un error coordinado si se produce un error en su host físico.
Service Fabric espera que el dominio de error de un nodo no cambie. Otros mecanismos que garantizan la alta disponibilidad de las VM, como HA-VM, pueden causar conflictos con Service Fabric. Estos mecanismos usan la migración transparente de VM desde un host a otro. Estos no reconfiguran ni notifican el código de ejecución dentro de la VM. Por lo tanto, no se admiten como entornos para ejecutar clústeres de Service Fabric.
Service Fabric debe ser la única tecnología de alta disponibilidad empleada. Los mecanismos como la migración en vivo de VM y SAN no son necesarios. Si estos mecanismos se usan junto con Service Fabric, reducen la confiabilidad y la disponibilidad de las aplicaciones. El motivo es que agregan una complejidad adicional, agregan orígenes centralizados de errores y usan estrategias de confiabilidad y disponibilidad que entran en conflicto con las de Service Fabric.
En el siguiente gráfico, se muestran coloreadas todas las entidades que contribuyen a la generación de dominios de error y todos los que se crean. En este ejemplo, tenemos centros de datos (DC), bastidores (R) y servidores blade (B). Si cada servidor blade contiene más de una máquina virtual, podría haber otra capa en la jerarquía de dominios de error.
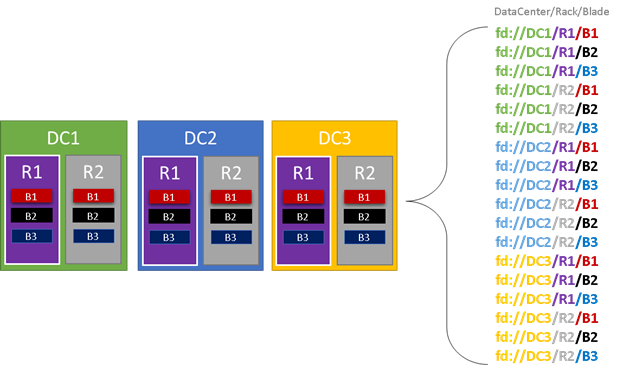
Durante el tiempo de ejecución, la utilidad Cluster Resource Manager de Service Fabric tiene en cuenta los dominios de error del clúster y planea diseños. Las réplicas con estado o las instancias sin estado de un servicio se distribuyen de manera que estén en dominios de error independientes. La distribución del servicio en dominios de errores garantiza que la disponibilidad del servicio no se ve comprometida cuando se produce un fallo del dominio de error en cualquier nivel de la jerarquía.
Cluster Resource Manager no tiene en cuenta cuántos niveles hay en la jerarquía de dominios de error. Sin embargo, sí que trata de asegurarse de que la pérdida de cualquier parte de la jerarquía no afecte a los servicios que se ejecutan en ella.
Es mejor si hay el mismo número de nodos en cada nivel de profundidad de la jerarquía de dominios de error. Si el "árbol" de dominios de error no está equilibrado en el clúster, Cluster Resource Manager tendrá más complicado determinar la mejor asignación de servicios. Los diseños de dominios de error desequilibrados provocan que la pérdida de algunos dominios afecte más a la disponibilidad de los servicios que otros dominios. Como resultado, Cluster Resource Manager se debate entre dos objetivos:
- Quiere usar las máquinas de ese dominio "pesado" colocando servicios en ellas.
- Quiere colocar servicios en otros dominios para que la pérdida de un dominio no cause problemas.
¿Qué aspecto tienen los dominios desequilibrados? En el siguiente diagrama se muestran dos diseños diferentes de clúster. En el primero, los nodos se distribuyen uniformemente entre los dominios de error. En el segundo ejemplo, un dominio de error tiene muchos más nodos que los demás dominios de error.
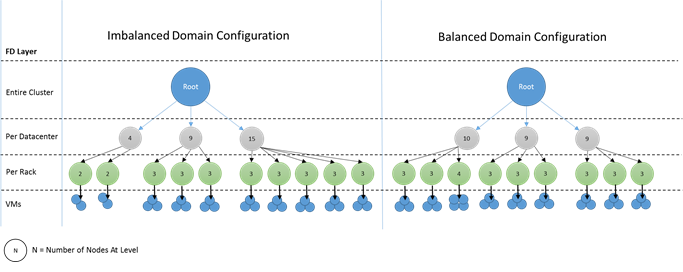
En Azure, será su responsabilidad elegir qué dominio de error contendrá un nodo. Sin embargo, dependiendo del número de nodos que se aprovisionen, puede seguir obteniendo dominios de error con más nodos que otros.
Por ejemplo, supongamos que tiene cinco dominios de error en el clúster, pero aprovisiona siete nodos para un determinado nodo (NodeType). En este caso, los dos primeros dominios de error acaban con más nodos. Si trata de implementar más instancias de NodeType con solo dos instancias, el problema será más grave. Por esta razón, se recomienda que el número de nodos en cada tipo de nodo sea un múltiplo del número de dominios de error.
Dominios de actualización
Los dominios de actualización son otra característica que ayuda a la utilidad Resource Manager Cluster de Service Fabric a comprender el diseño del clúster. Estos definen conjuntos de nodos que se actualizan al mismo tiempo. Los dominios de actualización ayudan a Cluster Resource Manager a entender y coordinar las operaciones de administración como las actualizaciones.
Los dominios de actualización son muy similares a los dominios de error, pero con algunas diferencias clave. En primer lugar, las áreas de los errores de hardware coordinados definen los dominios de error. Por otro lado, los dominios de actualización se definen mediante la directiva. Podrá decidir cuántos quiere, en lugar de permitir que el entorno dicte el número. Puede tener tantos dominios de actualización como ocurre con los nodos. Otra diferencia entre los dominios de error y los dominios de actualización es que los dominios de actualización no son jerárquicos. En su lugar, son más parecidos a una etiqueta sencilla.
En el siguiente diagrama se muestran tres dominios de actualización divididos en tres dominios de error. También se muestra una posible selección de ubicación de tres réplicas diferentes de un servicio con estado, donde cada una de ellas terminan con diferentes dominios de error y de actualización. Esta selección de ubicación permite perder un dominio de error en el transcurso de una actualización de servicio y seguir teniendo una copia del código y los datos.
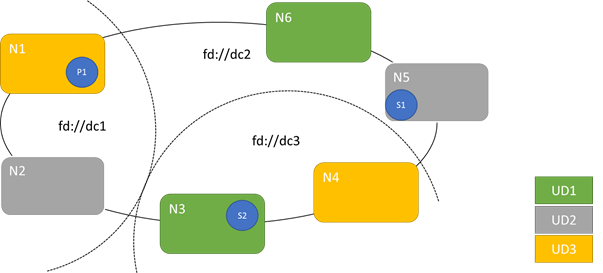
Tener un gran número de dominios de actualización tiene ventajas y desventajas. Disponer de más dominios de actualización implica que cada paso de la actualización sea más granular y afecte a un número menor de nodos o servicios. Como consecuencia, hay que mover menos servicios a la vez, lo que reduce la actividad en el sistema. Esto suele mejorar la confiabilidad general, ya que los problemas afectarán a una proporción menor del servicio durante la actualización. Si tiene más dominios de actualización, también necesitará menos búfer disponible en otros nodos para controlar el impacto de la actualización.
Por ejemplo, si dispone de cinco dominios de actualización, los nodos de cada uno de ellos controlarán aproximadamente el 20 % del tráfico. Si necesita desactivar ese dominio de actualización para realizar una actualización, la carga normalmente debe ir a otro lado. Puesto que tiene cuatro dominios de actualización restantes, cada uno debe tener un espacio aproximado del 25 % del tráfico total. Disponer de más dominios de actualización implica que necesita menos búfer en los nodos en el clúster.
Por ejemplo, considere si había 10 dominios de actualización en su lugar. En ese caso, cada dominio de actualización ocupa aproximadamente solo el 10 % del tráfico total. Cuando se realiza una actualización en el clúster, cada dominio solo tendría que tener espacio para aproximadamente un 11 % del tráfico total. Disponer de más dominios de actualización le permite normalmente ejecutar nodos con una utilización mayor, ya que necesita una capacidad de reserva menor. Lo mismo ocurre con los dominios de error.
El inconveniente de tener muchos dominios de actualización es que las actualizaciones suelen tardar más tiempo. Service Fabric espera un breve período después de que se complete un dominio de actualización y realiza comprobaciones antes de iniciar la actualización del siguiente. Estos retrasos permiten detectar problemas introducidos por la actualización antes de continuar con la actualización. El compromiso es aceptable, ya que impide que los cambios incorrectos afecten a una proporción excesiva del servicio a la vez.
La presencia de pocos dominios de actualización tiene muchos efectos secundarios negativos. Mientras que cada dominio de actualización esté inactivo y actualizándose, una gran parte de la capacidad general no estará disponible. Por ejemplo, si solo dispone de tres dominios de actualización, estará inactiva un tercio de la capacidad general del servicio o del clúster al mismo tiempo. Tener una gran parte del servicio sin actividad al mismo tiempo no es recomendable, ya que hay que contar con suficiente capacidad en el resto del clúster para controlar la carga de trabajo. Mantener el búfer implica que durante el funcionamiento normal, los nodos se carguen menos de lo que deberían. Esto aumenta el costo de ejecución del servicio.
No existe ningún límite real en el número total de dominios de error o de actualización en un entorno ni tampoco restricciones a la forma en que se superponen. Sin embargo, hay patrones comunes:
- Asignación 1:1 de dominios de error y de actualización
- Un dominio de actualización por nodo (instancia del sistema operativo física o virtual)
- Un modelo "seccionado" o "de matriz", donde los dominios de error y de actualización forman una matriz con máquinas que se ejecutan abajo de las diagonales.
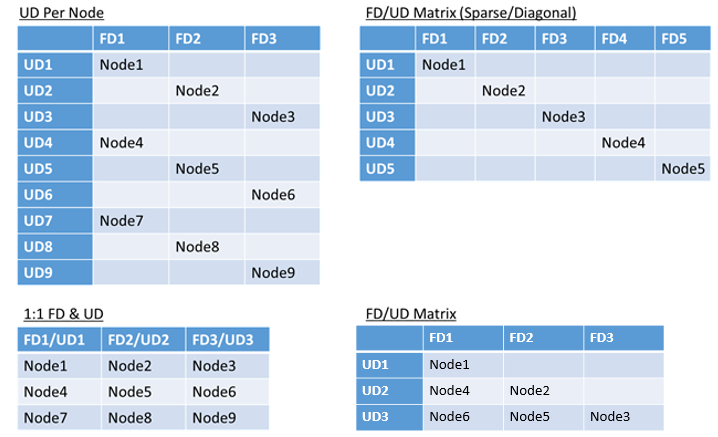
No hay una respuesta perfecta sobre qué diseño elegir. Cada una tiene ventajas y desventajas. Por ejemplo, el modelo 1FD:1UD es fácil de configurar. El modelo de un dominio de actualización por nodo es el más utilizado por los usuarios. Durante las actualizaciones, cada nodo se actualiza de forma independiente. Esto es similar a cómo se actualizaban manualmente los conjuntos pequeños de máquinas en el pasado.
El modelo más habitual es la matriz FD/UD, en la que los dominios de error y los dominios de actualización forman una tabla donde los nodos se colocan empezando por la diagonal. Este es el modelo que se utiliza de forma predeterminada en clústeres de Service Fabric en Azure. Para los clústeres con muchos nodos, todo tiene un aspecto parecido a un patrón de matriz denso.
Nota:
Los clústeres de Service Fabric hospedados en Azure no admiten el cambio de la estrategia predeterminada. Solo los clústeres independientes ofrecen esa personalización.
Restricciones de dominio de error y de actualización y el comportamiento resultante
Enfoque predeterminado
De forma predeterminada, Cluster Resource Manager mantiene los servicios equilibrados en los dominios de error y actualización. Esto se modela como una restricción. Restricciones para los estados de dominios de error y actualización: "en una partición de servicio específica, nunca debería haber una diferencia mayor que uno en el número de objetos de servicio (instancias de servicio sin estado o réplicas de servicios con estado) entre dos dominios cualesquiera en el mismo nivel de jerarquía".
Digamos que esta restricción proporciona una garantía de "diferencia máxima". La restricción para dominios de error y actualización impide ciertos movimientos o disposiciones que infringen la regla.
Por ejemplo, supongamos que tenemos un clúster con 6 nodos, configurado con 5 dominios de error y 5 dominios de actualización.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N3 | ||||
| UD3 | N4 | ||||
| UD4 | N5 |
Ahora supongamos que creamos un servicio con un valor TargetReplicaSetSize (o, para un servicio sin estado, un valor InstanceCount) de cinco. Las réplicas se dirigen a N1-N5. De hecho, nunca se usará N6, independientemente del número de servicios como este que cree. Pero ¿por qué? Echemos un vistazo a la diferencia entre el diseño actual y lo que sucedería si se elige N6.
Este es el diseño que obtuvimos y el número total de las réplicas por dominio de error y de actualización:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | 1 | ||||
| UD3 | R4 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Este diseño se equilibra en términos de nodos por dominio de error y de actualización. También está equilibrado en cuanto al número de réplicas por dominios de error y de actualización. Cada dominio tiene el mismo número de nodos y el mismo número de réplicas.
Ahora, echemos un vistazo a lo que sucedería si hubiéramos utilizado N6 en lugar de N2. ¿Cómo se distribuirían las réplicas entonces?
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R5 | 1 | ||||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 2 | 0 | 1 | 1 | 1 | - |
Este diseño no cumple la definición de garantía de "diferencia máxima" para la restricción de dominio de error. FD0 tiene dos réplicas, mientras que FD1 no tiene ninguna. Por lo que la diferencia entre FD0 y FD1 es 2, que es mayor que la diferencia máxima de 1. Como se ha infringido la restricción, el Cluster Resource Manager no permite este tipo de disposición.
De forma similar, si se ha seleccionado N2 y N6 (en lugar de N1 y N2), obtendríamos lo siguiente:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | 0 | |||||
| UD1 | R5 | R1 | 2 | |||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Este diseño se equilibra en cuanto a dominios de error. Sin embargo, ahora infringe la restricción de dominio de actualización porque UD0 tiene cero réplicas, y UD1 tiene dos. Por lo tanto, este diseño tampoco es válido y Cluster Resource Manager no puede seleccionarlo.
Este enfoque para la distribución de réplicas con estado o instancias sin estado proporciona la mejor tolerancia a errores posible. Si un dominio deja de funcionar, se pierde el número mínimo de instancias o réplicas.
Por otro lado, este enfoque puede ser demasiado estricto y no permite que el clúster use todos los recursos. Para determinadas configuraciones de clúster, no se pueden usar determinados nodos. Esto puede provocar que Service Fabric no coloque sus servicios, lo que da lugar a mensajes de advertencia. En el ejemplo anterior, no se pueden usar algunos de los nodos del clúster (N6 en el ejemplo). Aunque agregase nodos a ese clúster (N7-N10), las réplicas o instancias solo se colocarían en N1-N5 debido a restricciones de dominio de error y de actualización.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | N10 | |||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N9 | N5 |
Enfoque alternativo
Cluster Resource Manager admite otra versión de la restricción de dominios de error y actualización. Permite la colocación al mismo tiempo que garantiza un nivel mínimo de seguridad. La restricción alternativa puede declararse de la manera siguiente: "en una partición de servicio específica, la distribución de réplicas entre dominios debe garantizar que la partición no sufra una pérdida de cuórum". Digamos que esta restricción proporciona una garantía de "seguridad de cuórum".
Nota:
Para un servicio con estado, definimos pérdida de cuórum en una situación en que la mayoría de las réplicas de la partición están inactivas al mismo tiempo. Por ejemplo, si el valor de TargetReplicaSetSize es cinco, un conjunto de tres réplicas cualesquiera representará el cuórum. De forma similar, si el valor de TargetReplicaSetSize es seis, se necesitarán cuatro réplicas para el cuórum. En ambos casos, no pueden estar inactivas más de dos réplicas al mismo tiempo si quiere que la partición continúe funcionando con normalidad.
En un servicio sin estado, no hay nada parecido a pérdida de quórum. Los servicios sin estado continúan funcionando con normalidad incluso si una mayoría de instancias dejan de funcionar al mismo tiempo. Por lo tanto, nos centraremos en los servicios con estado en el resto del artículo.
Volvamos al ejemplo anterior Con la versión de "seguridad de cuórum" de la restricción, los tres diseños serían válidos. Incluso si no se pudo usar FD0 en el segundo diseño o UD1 no se pudo usar en el tercer diseño, la partición seguiría teniendo cuórum. (La mayoría de las réplicas seguirán funcionando.) Con esta versión de la restricción, N6 puede usarse casi siempre.
El enfoque de "seguridad de cuórum" proporciona más flexibilidad que el enfoque de "diferencia máxima". El motivo es que resulta más fácil encontrar distribuciones de réplicas válidas en casi cualquier topología de clúster. Sin embargo, este enfoque no garantiza las mejores características de tolerancia a errores porque algunos errores son peores que otros.
En el peor de los casos, podría perderse una mayoría de las réplicas con el error de un dominio y una réplica adicional. Por ejemplo, en lugar de los 3 errores que se requieren para perder el cuórum con 5 réplicas o instancias, ahora podría perder una mayoría con solo dos errores.
Enfoque adaptable
Dado que ambos enfoques tienen ventajas y desventajas, hemos presentado un enfoque adaptable que combina estas dos estrategias.
Nota:
Este será el comportamiento predeterminado a partir de la versión 6.2. de Service Fabric.
El enfoque adaptable utiliza la lógica de "diferencia máxima" de forma predeterminada y activa la lógica de "seguridad de cuórum" solo si es necesario. Cluster Resource Manager automáticamente averigua cuál es la estrategia necesaria examinando cómo se configuran los servicios y el clúster.
Cluster Resource Manager debe usar la lógica "basada en cuórum" para un servicio para el cual ambas condiciones son true:
- El valor de TargetReplicaSetSize para el servicio es divisible uniformemente entre el número de dominios de error y el número de dominios de actualización.
- El número de nodos es menor o igual al número de dominios de error multiplicado por el número de dominios de actualización.
Tenga en cuenta que Cluster Resource Manager usará este enfoque para los servicios sin estado y con estado, a pesar de que la pérdida de cuórum no es aplicable a los servicios sin estado.
Volvamos al ejemplo anterior y supongamos que un clúster tiene ahora ocho nodos. El clúster todavía está configurado con cinco dominios de error y cinco dominios de actualización y el valor de TargetReplicaSetSize de un servicio hospedado en ese clúster continúa siendo cinco.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N5 |
Dado que se cumplen todas las condiciones necesarias, Cluster Resource Manager usará la lógica "basada en cuórum" para la distribución del servicio. Esto habilita el uso de N6 a N8. En este caso, una distribución posible para los servicios podría tener el aspecto siguiente:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | 0 | |||||
| UD4 | R5 | 1 | ||||
| FDTotal | 2 | 1 | 1 | 0 | 1 | - |
Si el valor de TargetReplicaSetSize de su servicio se reduce a cuatro (por ejemplo), Cluster Resource Manager observará ese cambio. Se reanudará con la lógica de "diferencia máxima" porque TargetReplicaSetSize no se puede dividir entre el número de dominios de error ni de dominios de actualización. Como resultado, se producen ciertos movimientos de réplica para distribuir las cuatro réplicas restantes en los nodos del N1 al N5. De este modo, no se infringe la versión "diferencia máxima" de la lógica del dominio de actualización ni del dominio de error.
En el diseño anterior, si el valor de TargetReplicaSetSize es cinco y N1 se quita del clúster, el número de dominios de actualización es igual a cuatro. De nuevo, Cluster Resource Manager comienza a usar una lógica de "diferencia máxima", ya que el número de dominios de actualización ya no puede dividir de manera uniforme el valor de TargetReplicaSetSize del servicio. Como resultado, la réplica R1, cuando se compila de nuevo, debe llegar a N4 para no infringir la restricción de dominio de error y de actualización.
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | N/D | N/D | N/D | N/D | N/D | N/D |
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | R1 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Configuración de dominios de error y de actualización
En las implementaciones de Service Fabric hospedadas en Azure, la definición de dominios de error y de actualización se realiza automáticamente. Service Fabric se limita a recopilar la información sobre el entorno de Azure.
Si va a crear su propio clúster (o quiere ejecutar una determinada topología en desarrollo), puede proporcionar la información de dominios de error y de actualización. En este ejemplo, definimos un clúster de desarrollo local de nueve nodos que abarca tres centros de datos (cada uno con tres bastidores). Este clúster también tiene tres dominios de actualización seccionados en esos tres centros de datos. Este es un ejemplo de la configuración de ClusterManifest.xml:
<Infrastructure>
<!-- IsScaleMin indicates that this cluster runs on one box/one single server -->
<WindowsServer IsScaleMin="true">
<NodeList>
<Node NodeName="Node01" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType01" FaultDomain="fd:/DC01/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node02" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType02" FaultDomain="fd:/DC01/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node03" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType03" FaultDomain="fd:/DC01/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node04" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType04" FaultDomain="fd:/DC02/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node05" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType05" FaultDomain="fd:/DC02/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node06" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType06" FaultDomain="fd:/DC02/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node07" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType07" FaultDomain="fd:/DC03/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node08" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType08" FaultDomain="fd:/DC03/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node09" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType09" FaultDomain="fd:/DC03/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
</NodeList>
</WindowsServer>
</Infrastructure>
En este ejemplo se usa ClusterConfig.json para implementaciones independientes:
"nodes": [
{
"nodeName": "vm1",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm2",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm3",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm4",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm5",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm6",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm7",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm8",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm9",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD3"
}
],
Nota:
Al definir los clústeres a través de Azure Resource Manager, Azure asigna dominios de error y dominios de actualización. Por lo tanto, la definición de los tipos de nodos y los conjuntos de escalado de máquinas virtuales en la plantilla de Azure Resource Manager no incluye información del dominio de error o de actualización.
Restricciones de ubicación y propiedades de nodo
A veces (de hecho, la mayor parte del tiempo) le va a interesar asegurarse de que ciertas cargas de trabajo solo se ejecuten en determinados tipos de nodos en el clúster. Por ejemplo, algunas cargas de trabajo pueden requerir GPU o SSD, al contrario que otras.
Un buen ejemplo de esto es prácticamente cualquier arquitectura de n niveles. Determinadas máquinas sirven de front-end o lado de la aplicación a la API y se exponen a los clientes o a Internet. Otras máquinas, a menudo con recursos de hardware diferentes, se encargan del trabajo de las capas de proceso o almacenamiento. Estas no se suelen exponer directamente a los clientes o a Internet.
Service Fabric espera que haya casos en que se deban ejecutar cargas de trabajo concretas en configuraciones de hardware específicas. Por ejemplo:
- una aplicación de n niveles existente se ha transferido "tal cual" a un entorno de Service Fabric;
- se debe ejecutar una carga de trabajo en un hardware específico por motivos de rendimiento, escala o aislamiento de seguridad.
- Una carga de trabajo debe estar aislada de otras por una directiva o a causa del consumo de recursos.
Para admitir estos tipos de configuraciones, Service Fabric incluye etiquetas que se pueden aplicar a los nodos. Estas etiquetas se denominan propiedades del nodo. Las restricciones de ubicación son las instrucciones adjuntas a los servicios individuales que se seleccionan para una o más propiedades de nodo. Las restricciones de posición definen dónde deben ejecutarse los servicios. El conjunto de restricciones es extensible. Puede funcionar cualquier par clave/valor.
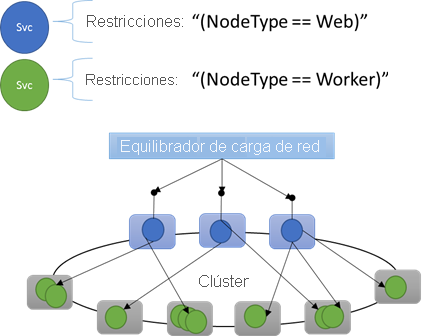
Propiedades del nodo integradas
Además, Service Fabric define algunas propiedades del nodo predeterminadas que se pueden usar automáticamente sin que el usuario tenga que definirlas. Las propiedades predeterminadas definidas en cada nodo son NodeType y NodeName.
Por ejemplo, podría escribir una restricción de ubicación como "(NodeType == NodeType03)". NodeType es una propiedad frecuente. Es útil, ya que corresponde a 1:1 con un tipo de una máquina. Cada tipo de máquina corresponde a un tipo de carga de trabajo en una aplicación de n niveles tradicional.
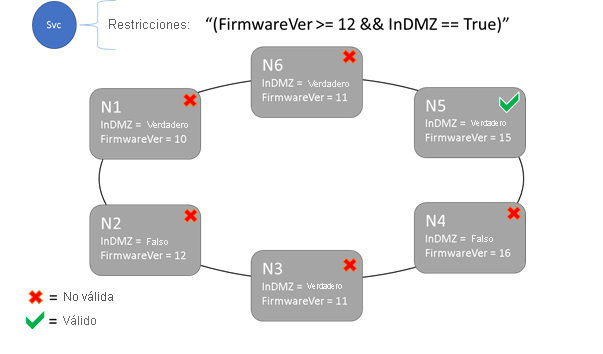
Restricciones de ubicación y sintaxis de propiedades de nodo
El valor especificado en la propiedad de nodo puede ser una cadena, un booleano ni de tipo Long con signo. La instrucción en el servicio se denomina "restricción de ubicación", ya que limita el lugar del clúster donde puede ejecutarse el servicio. La restricción puede ser cualquier instrucción booleana que opera en las propiedades del nodo en el clúster. Los selectores válidos de estas instrucciones booleanas son los siguientes:
Comprobaciones condicionales para crear instrucciones concretas:
. Sintaxis "equal to" "==" "not equal to" "!=" "greater than" ">" "greater than or equal to" ">=" "less than" "<" "less than or equal to" "<=" Instrucciones booleanas para operaciones lógicas y de agrupación:
. Sintaxis "and" "&&" "or" "||" "not" "!" "group as single statement" "()"
Estos son algunos ejemplos de instrucciones de restricción básicas:
"Value >= 5""NodeColor != green""((OneProperty < 100) || ((AnotherProperty == false) && (OneProperty >= 100)))"
El servicio se puede colocar solo en los nodos donde la instrucción de restricción de colocación general se evalúa como "True". Los nodos que no tengan definida ninguna propiedad no coinciden con ninguna restricción de colocación que contenga esa propiedad.
Supongamos que se definieron las siguientes propiedades de nodo para un tipo de nodo en ClusterManifest.xml:
<NodeType Name="NodeType01">
<PlacementProperties>
<Property Name="HasSSD" Value="true"/>
<Property Name="NodeColor" Value="green"/>
<Property Name="SomeProperty" Value="5"/>
</PlacementProperties>
</NodeType>
En el ejemplo siguiente se muestran las propiedades del nodo definidas a través de ClusterConfig.json para las implementaciones independientes o Template.json para los clústeres hospedados en Azure.
Nota:
En la plantilla de Azure Resource Manager se parametriza normalmente el tipo de nodo. Tendría un aspecto similar a "[parameters('vmNodeType1Name')]" en lugar de NodeType01.
"nodeTypes": [
{
"name": "NodeType01",
"placementProperties": {
"HasSSD": "true",
"NodeColor": "green",
"SomeProperty": "5"
},
}
],
Puede crear restricciones de ubicación para un servicio de la siguiente manera:
FabricClient fabricClient = new FabricClient();
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
serviceDescription.PlacementConstraints = "(HasSSD == true && SomeProperty >= 4)";
// Add other required ServiceDescription fields
//...
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceType -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementConstraint "HasSSD == true && SomeProperty >= 4"
Si todos los nodos de NodeType01 son válidos, también puede seleccionar el tipo de nodo con la restricción "(NodeType == NodeType01)".
Las restricciones de ubicación de un servicio se pueden actualizar dinámicamente durante el tiempo de ejecución. Si es necesario, puede mover un servicio por el clúster, agregar y quitar requisitos, etc. Service Fabric asegura que el servicio siempre esté en funcionamiento y disponible incluso cuando se estén produciendo estos tipos de cambios.
StatefulServiceUpdateDescription updateDescription = new StatefulServiceUpdateDescription();
updateDescription.PlacementConstraints = "NodeType == NodeType01";
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Update-ServiceFabricService -Stateful -ServiceName $serviceName -PlacementConstraints "NodeType == NodeType01"
Las restricciones de ubicación se especifican para cada instancia de servicio con nombre. Las actualizaciones siempre asumen el lugar o sobrescriben lo que se especificó antes.
La definición del clúster define las propiedades en un nodo. Cambiar las propiedades de un nodo requiere una actualización de la configuración del clúster. Actualizar las propiedades de un nodo requiere que cada nodo afectado se reinicie para informar sobre sus nuevas propiedades. Service Fabric administra estas actualizaciones sucesivas.
Descripción y administración de recursos de clúster
Uno de los trabajos más importantes de cualquier organizador es ayudar a administrar el consumo de recursos del clúster. La administración de recursos de clúster puede significar un par de cosas diferentes.
En primer lugar, hay es asegurarse de que las máquinas no estén sobrecargadas. Esto significa asegurarse de que las máquinas no estén ejecutando más servicios de los que puede administrar.
En segundo lugar, hay equilibrio y optimización, que son esenciales para que la ejecución funcione de forma eficaz. Las ofertas de servicios que tienen en cuenta en rendimiento o la rentabilidad no pueden permitir que algunos nodos se activen cuando otros estén inactivos. Los nodos activos provocan la contención de recursos y un rendimiento deficiente. Por otro lado, los nodos inactivos representan recursos desperdiciados y mayores costos.
Service Fabric representa los recursos como Métricas. Las métricas son cualquier recurso físico o lógico que desee describir a Service Fabric. Algunos ejemplos de métricas son elementos como "WorkQueueDepth" o "MemoryInMb". Para obtener información acerca de los recursos físicos que puede administrar Service Fabric en los nodos, vea la gobernanza de recursos. Para información sobre las métricas predeterminadas que se usan en Cluster Resource Manager y cómo configurar las métricas personalizadas, consulte este artículo.
Las métricas se diferencian de las restricciones de ubicación y de las propiedades de nodo. Las propiedades de nodo son descriptores estáticos de los nodos por sí mismos. Las métricas describen recursos que tienen nodos y que los servicios usan cuando se ejecutan en un nodo. Una propiedad de nodo podría ser HasSSD y tener un valor de True o False. La cantidad de espacio disponible en ese SSD y la cantidad consumida por los servicios sería una métrica como "DriveSpaceInMb".
Al igual que para las restricciones de ubicación y las propiedades de nodo, la utilidad Cluster Resource Manager de Service Fabric no comprende lo que significan los nombres de las métricas, ya que son simplemente cadenas. Se recomienda declarar las unidades como parte de los nombres de métricas que cree cuando puedan ser ambiguos.
Capacity
Si desactivó todo el equilibriode recursos, la utilidad Cluster Resource Manager de Service Fabric aún podría asegurarse de que ningún nodo terminara superando su capacidad. Es posible administrar saturaciones de capacidad, a no ser que el clúster esté demasiado lleno o la carga de trabajo sea mayor que cualquier nodo. La capacidad es otra restricción que utiliza Cluster Resource Manager para entender cuánto de un recurso tiene un nodo. También se realiza un seguimiento de la capacidad restante en el clúster.
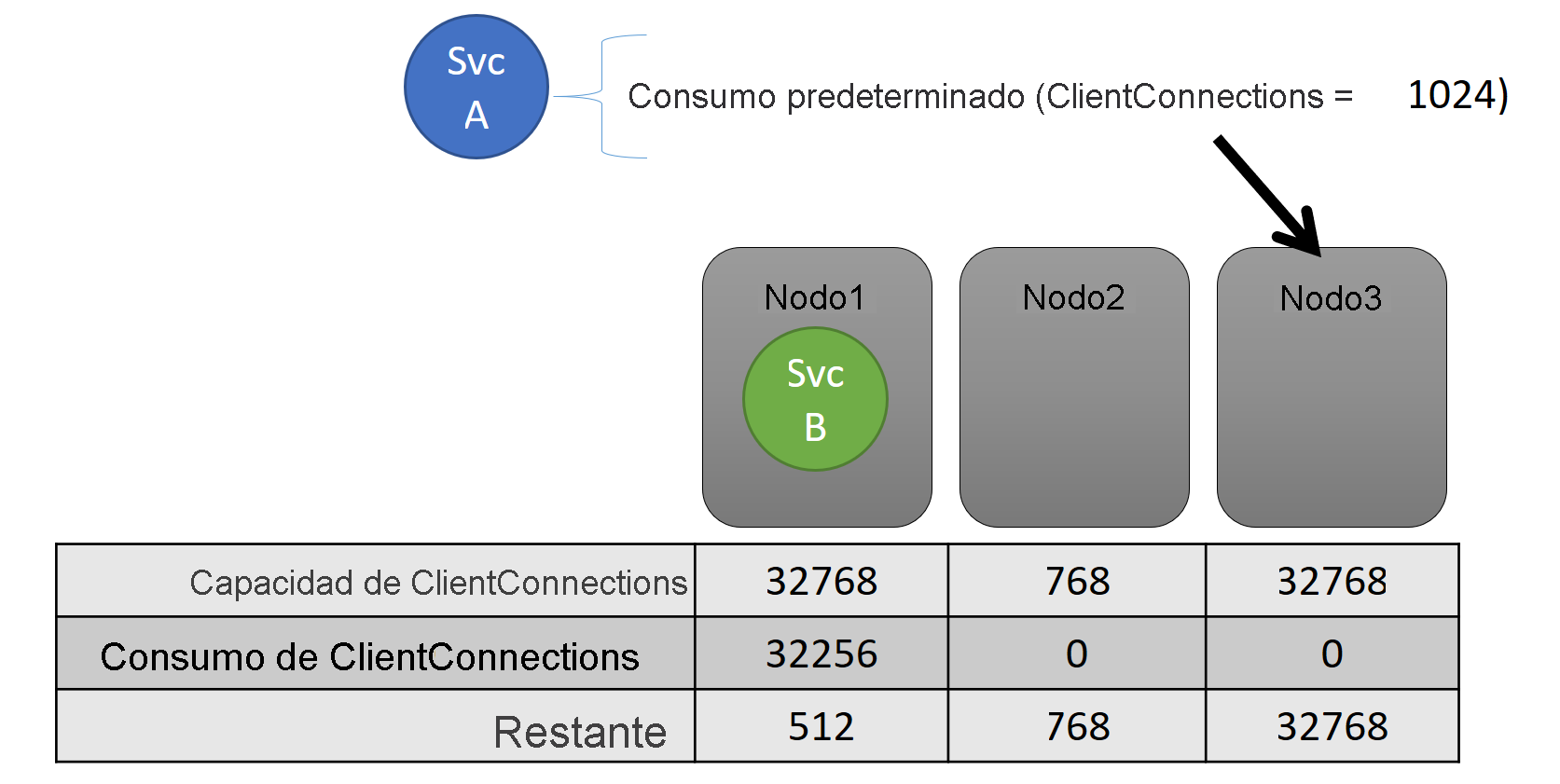
Tanto la capacidad como el consumo en el nivel de servicio se expresan con métricas. Por ejemplo, la métrica podría ser "ClientConnections", y un nodo puede tener una capacidad "ClientConnections" de 32,768. Otros nodos pueden tener otros límites. Algún servicio que se ejecuta en ese nodo puede decir que está actualmente consumiendo 32,256 de la métrica "ClientConnections".
Durante el tiempo de ejecución, Cluster Resource Manager realiza un seguimiento de capacidad restante del clúster y en los nodos. Para realizar un seguimiento de la capacidad, Cluster Resource Manager resta el uso de cada servicio de la capacidad del nodo donde se ejecuta el servicio. Con esta información, la utilidad Cluster Resource Manager puede averiguar dónde colocar o mover las réplicas para que los nodos no superen su capacidad.
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
ServiceLoadMetricDescription metric = new ServiceLoadMetricDescription();
metric.Name = "ClientConnections";
metric.PrimaryDefaultLoad = 1024;
metric.SecondaryDefaultLoad = 0;
metric.Weight = ServiceLoadMetricWeight.High;
serviceDescription.Metrics.Add(metric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ClientConnections,High,1024,0)
Puede ver las capacidades definidas en el manifiesto de clúster. Este es un ejemplo de ClusterManifest.xml:
<NodeType Name="NodeType03">
<Capacities>
<Capacity Name="ClientConnections" Value="65536"/>
</Capacities>
</NodeType>
En el ejemplo siguiente se muestran las capacidades definidas a través de ClusterConfig.json para las implementaciones independientes o Template.json para los clústeres hospedados en Azure:
"nodeTypes": [
{
"name": "NodeType03",
"capacities": {
"ClientConnections": "65536",
}
}
],
Normalmente, una carga de un servicio cambia de forma dinámica. Supongamos que la carga de la réplica de "ClientConnections" cambió de 1,024 a 2,048. El nodo que se estaba ejecutando tenía una capacidad restante de 512 para esa métrica. Ahora, esa selección de ubicación de la instancia o réplica no es válida porque no hay suficiente espacio en ese nodo. Cluster Resource Manager tiene que reducir el uso de capacidad del nodo. Reduce la carga en el nodo que está por encima de la capacidad moviendo una o más réplicas o instancias de ese nodo a otros nodos.
Cluster Resource Manager trata de minimizar el costo del movimiento de las réplicas. Puede obtener más información acerca del costo del movimiento y acerca de las reglas y estrategias de reequilibrio.
Capacidad del clúster
¿Cómo Cluster Resource Manager de Service Fabric evita que el clúster general se llene demasiado? Con la carga dinámica no hay mucho que pueda hacer, ya que los servicios pueden tener un pico de carga con independencia de las acciones que realice Resource Manager. Como resultado, un clúster con espacio de sobra hoy puede quedarse corto cuando haya un pico mañana.
Los controles de Cluster Resource Manager ayudan a evitar problemas. Lo primero que se puede hacer es evitar la creación de nuevas cargas de trabajo que harían que el clúster se llenara.
Supongamos que crea un servicio sin estado y tiene cierta carga asociado a él, y que el servicio se ocupa de la métrica "DiskSpaceInMb". El servicio va a consumir 5 unidades de "DiskSpaceInMb" para cada instancia del servicio. Quiere crear 3 instancias del servicio. Eso significa que necesitamos 15 unidades de "DiskSpaceInMb" en el clúster para poder crear estas instancias de servicio.
Cluster Resource Manager calcula continuamente la capacidad y el consumo de cada métrica, por lo que puede determinar la capacidad restante del clúster. Si no hay espacio suficiente, Cluster Resource Manager rechaza la llamada para crear un servicio.
Dado que el requisito es solo que haya 15 unidades disponibles, puede asignar este espacio de muchas maneras diferentes. Por ejemplo, podría ser una unidad de capacidad restante en 15 nodos diferentes o las tres unidades de capacidad que quedan en 5 nodos diferentes. Si Cluster Resource Manager puede reorganizarlo todo para que haya cinco unidades disponibles en tres nodos, podrá colocar el servicio. La reorganización del clúster es normalmente posible a no ser que el clúster esté casi lleno o los servicios existentes no puedan consolidarse por alguna razón.
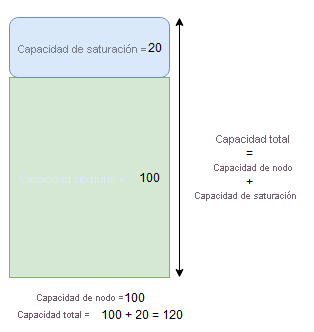
Capacidad de saturación y del búfer del nodo
Si se especifica la capacidad de un nodo para una métrica, Cluster Resource Manager nunca colocará réplicas en un nodo y tampoco las moverá a este si la carga total está por encima de la capacidad del nodo especificada. A veces, esto puede impedir la selección de ubicación de nuevas réplicas o el reemplazo de réplicas con error si el clúster está a punto de alcanzar la capacidad total y se debe colocar, reemplazar o cambiar una réplica con una carga de gran tamaño.
Con el fin de proporcionar más flexibilidad, puede especificar la capacidad de saturación o del búfer del nodo. Cuando se especifique la capacidad de saturación o del búfer del nodo de una métrica, Cluster Resource Manager intentará colocar o trasladar las réplicas de forma que la capacidad de saturación o del búfer no se use, pero permitirá que se use dicha capacidad si es necesario para las acciones que aumentan la disponibilidad del servicio, por ejemplo:
- Nueva selección de ubicación de réplicas o reemplazo de réplicas con error
- Selección de ubicación durante las actualizaciones
- Corrección de infracciones de restricción suaves y estrictas
- Desfragmentación
La capacidad del búfer del nodo representa una parte reservada de la capacidad por debajo de la capacidad del nodo especificada, mientras que la capacidad de saturación representa una parte de la capacidad adicional por encima de la capacidad del nodo especificada. En ambos casos, Cluster Resource Manager intentará mantener la disponibilidad de esta capacidad.
Por ejemplo, si un nodo tiene una capacidad especificada para la métrica CpuUtilization de 100 y el porcentaje del búfer del nodo de esa métrica se establece en un 20 %, la capacidad total y la no almacenada en búfer serán de 100 y 80, respectivamente, y Cluster Resource Manager no colocará más de 80 unidades de carga en el nodo en circunstancias normales.

Deberá usar el búfer del nodo cuando quiera reservar una parte de la capacidad del nodo que solo se utilizará para las acciones que aumentan la disponibilidad del servicio mencionada anteriormente.
Por otro lado, si se usa el porcentaje de saturación del nodo y se establece en un 20 %, la capacidad total y la no almacenada en búfer serán de 120 y 100, respectivamente.
Debe usar la capacidad de saturación cuando quiera permitir que Cluster Resource Manager coloque las réplicas en un nodo, aunque el uso total de recursos supere la capacidad. Se puede usar para proporcionar disponibilidad adicional para los servicios a costa del rendimiento. Si se usa la saturación, la lógica de aplicación del usuario debe poder funcionar con menos recursos físicos de los que podría necesitar.
Si se especifican las capacidades de saturación o del búfer del nodo, Cluster Resource Manager no moverá ni colocará las réplicas si la carga total en el nodo de destino supera la capacidad total (capacidad del nodo en el caso del búfer del nodo y capacidad del nodo + capacidad de saturación en el caso de la saturación).
También se puede especificar la capacidad de saturación para que sea infinita. En este caso, Cluster Resource Manager intentará mantener la carga total del nodo por debajo de la capacidad del nodo especificada, pero puede colocar una carga mucho mayor en el nodo, lo que podría provocar una degradación del rendimiento grave.
No se pueden especificar las capacidades de saturación y del búfer del nodo a la vez para una métrica.
A continuación, se muestra un ejemplo de cómo especificar las capacidades de saturación y del nodo del búfer en ClusterManifest.xml:
<Section Name="NodeBufferPercentage">
<Parameter Name="SomeMetric" Value="0.15" />
</Section>
<Section Name="NodeOverbookingPercentage">
<Parameter Name="SomeOtherMetric" Value="0.2" />
<Parameter Name=”MetricWithInfiniteOverbooking” Value=”-1.0” />
</Section>
En el ejemplo siguiente se muestra cómo especificar las capacidades de saturación y del búfer del nodo a través de ClusterConfig.json para las implementaciones independientes o de Template.json para los clústeres hospedados en Azure:
"fabricSettings": [
{
"name": "NodeBufferPercentage",
"parameters": [
{
"name": "SomeMetric",
"value": "0.15"
}
]
},
{
"name": "NodeOverbookingPercentage",
"parameters": [
{
"name": "SomeOtherMetric",
"value": "0.20"
},
{
"name": "MetricWithInfiniteOverbooking",
"value": "-1.0"
}
]
}
]
Pasos siguientes
- Para obtener más información sobre el flujo de información y la arquitectura de Cluster Resource Manager, vea Información general de la arquitectura de Cluster Resource Manager.
- Definir las métricas de desfragmentación es una manera de consolidar la carga en los nodos en lugar de distribuirla. Para obtener información sobre cómo configurar la desfragmentación, vea Desfragmentación de métricas y carga en Service Fabric.
- Empiece desde el principio y obtenga una introducción a Cluster Resource Manager de Service Fabric.
- Para más información sobre cómo Cluster Resource Manager administra y equilibra la carga en el clúster, vea Equilibrio del clúster de Service Fabric.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de