Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se ofrece información general del ciclo de vida de réplicas de servicios con estado e instancias de servicios sin estado.
Instancias de servicios sin estado
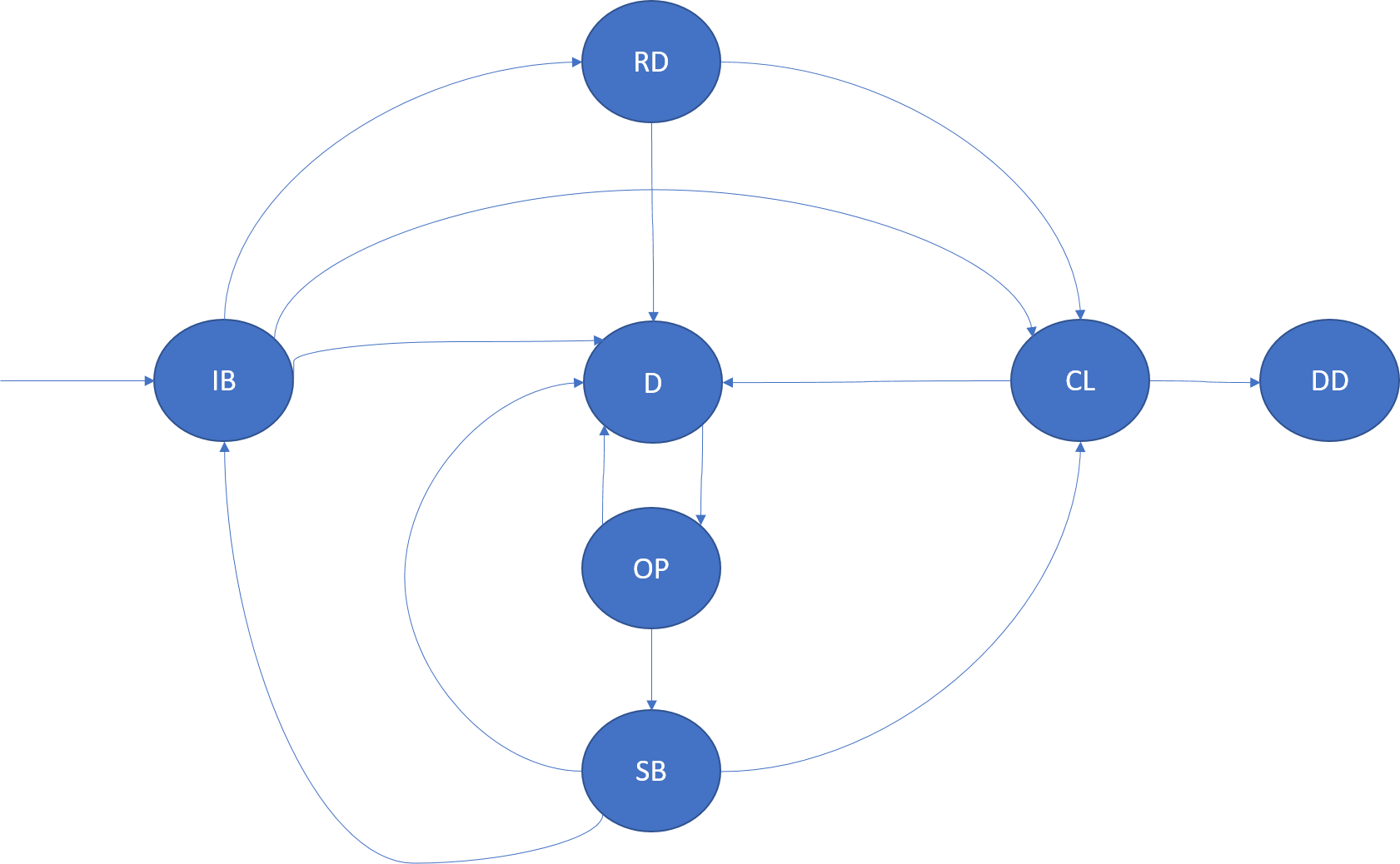
Una instancia de un servicio sin estado es una copia de la lógica de servicio que se ejecuta en uno de los nodos del clúster. Una instancia dentro de una partición solo se identifica mediante su InstanceId. El ciclo de vida de una instancia se puede modelar mediante el siguiente diagrama:
InBuild (IB)
Una vez que Cluster Resource Manager determina una ubicación para la instancia, entra en este estado del ciclo de vida. La instancia se inicia en el nodo. El host de aplicación se inicia, se crea la instancia y luego se abre. Una vez finalizado el inicio, la instancia realiza la transición al estado listo.
Si el host o nodo de aplicación para esta instancia se bloquea, realiza la transición al estado descartado.
Listo (Ready, RD)
En el estado listo, la instancia está en funcionamiento en el nodo. Si esta instancia es un servicio de confianza, RunAsync se ha invocado.
Si el host o nodo de aplicación para esta instancia se bloquea, realiza la transición al estado descartado.
Cierre (Closing, CL)
En el estado de cierre, Azure Service Fabric se encuentra en proceso de apagar la instancia de este nodo. Este apagado podría deberse a muchas razones: por ejemplo, la actualización de la aplicación, el equilibrio de carga o el servicio que se elimina. Una vez completado el apagado, realiza la transición al estado descartado.
Descartado (Dropped, DD)
En el estado descartado, la instancia ya no se ejecuta en el nodo. En este momento, Service Fabric mantiene los metadatos sobre esta instancia (que finalmente se elimina también).
Nota:
Es posible realizar la transición de cualquier estado al estado descartado mediante la opción ForceRemove en Remove-ServiceFabricReplica.
Réplicas de servicios con estado
Una réplica de un servicio con estado es una copia de la lógica de servicio que se ejecuta en uno de los nodos del clúster. Además, la réplica mantiene una copia del estado de ese servicio. Dos conceptos relacionados describen el ciclo de vida y el comportamiento de las réplicas con estado:
- Ciclo de vida de las réplicas
- Rol de réplica
En la siguiente explicación se describen servicios con estado persistentes. Para servicios con estado volátiles (o en memoria), los estados fuera de servicio o descartado son equivalentes.
InBuild (IB)
Una réplica InBuild es una réplica que se crea o prepara para unirse al conjunto de réplicas. Dependiendo del rol de réplica, IB tiene una semántica diferente.
Si el host de aplicación o el nodo para una réplica InBuild se bloquean, realizan la transición al estado fuera de servicio.
Réplicas InBuild Primary: InBuild principales son las primeras réplicas para una partición. Esta réplica suele producirse al crearse la partición. Las réplicas InBuild principales también surgen al reiniciarse todas las réplicas de una partición o descartarse.
Réplicas InBuild IdleSecondary: son nuevas réplicas que se crean mediante Cluster Resource Manager, o réplicas existentes que estaban fuera de servicio y se deben volver a agregar al conjunto. Estas réplicas se inicializan o crean mediante la principal antes de poder unirse al conjunto de réplicas como secundarias activas y participar en el reconocimiento cuórum de las operaciones.
Réplicas InBuild ActiveSecondary : este estado puede observarse en algunas consultas. Es una optimización donde el conjunto de réplicas no cambia, pero debe crearse una réplica. La propia réplica sigue las transacciones de máquina de estados normales (como se describe en la sección de roles de réplica).
Listo (Ready, RD)
Una réplica lista es una réplica que participa en la replicación y la confirmación del cuórum de las operaciones. El estado listo se puede aplicar a las réplicas principales y secundarias activas.
Si el host de aplicación o el nodo de una réplica lista se bloquean, realizan la transición al estado fuera de servicio.
Cierre (Closing, CL)
Una réplica especifica el estado de cierre en los siguientes escenarios:
Apagado del código para la réplica: puede que Service Fabric tenga que apagar el código en ejecución para una réplica. Este apagado podría suceder por muchas razones. Por ejemplo, debido a la actualización de una aplicación, un tejido o una infraestructura, o porque la réplica ha notificado un error. Cuando se completa el cierre de la réplica, esta realiza la transición al estado fuera de servicio. El estado persistente asociado a esta réplica que se almacena en disco no se limpia.
Eliminación de la réplica del clúster: es posible que Service Fabric tenga que quitar el estado persistente y apagar el código en ejecución para una réplica. Este apagado podría darse por diversos motivos, como por ejemplo, el equilibrio de carga.
Descartado (Dropped, DD)
En el estado descartado, la instancia ya no se ejecuta en el nodo. Tampoco se ha dejado ningún estado en el nodo. En este momento, Service Fabric mantiene los metadatos sobre esta instancia (que finalmente se elimina también).
Fuera de servicio (Down, D)
En el estado fuera de servicio, el código de réplica no se ejecuta, pero el estado persistente para esa réplica existe en ese nodo. Una réplica puede estar fuera de servicio por muchas razones, por ejemplo, el nodo que está fuera de servicio, los bloqueos en el código de réplica, la actualización de la aplicación o errores en la réplica.
Una réplica fuera de servicio se abre mediante Service Fabric según se necesite. Por ejemplo, cuando la actualización esté completa en el nodo.
El rol de réplica no es pertinente en el estado fuera de servicio.
Apertura (Opening, OP)
Una réplica fuera de servicio entra en estado de apertura si es necesario que Service Fabric traiga de nuevo la copia de seguridad de la réplica. Por ejemplo, este estado podría ser después de que una actualización del código de la aplicación finalice en un nodo.
Si el host de aplicación o el nodo de una réplica de apertura se bloquean, realizan la transición al estado fuera de servicio.
El rol de réplica no es pertinente en el estado de apertura.
Espera (StandBy, SB)
Una réplica de espera es una réplica de un servicio persistente que dejó de funcionar y se abrió a continuación. Esta réplica podría usarse mediante Service Fabric si debe agregar otra réplica al conjunto de réplicas (puesto que la réplica ya tiene parte del estado y el proceso de creación es más rápido). Tras expirar StandByReplicaKeepDuration, se descarta la réplica de espera.
Si el host de aplicación o el nodo de una réplica de espera se bloquean, realizan la transición al estado fuera de servicio.
El rol de réplica no es pertinente en el estado de espera.
Nota:
Se considera que aquellas réplicas que no están fuera de servicio ni se descartan se encuentran operativas.
Nota:
Es posible realizar la transición de cualquier estado al estado descartado mediante la opción ForceRemove en Remove-ServiceFabricReplica.
Rol de réplica
El rol de la réplica determina su función en el conjunto de réplicas:
- Primary (P) : hay una réplica principal en el conjunto de réplicas responsable de realizar operaciones de lectura y escritura.
- ActiveSecondary (S) : son réplicas que reciben actualizaciones de estado de la principal, las aplican y devuelven confirmaciones. Hay varias secundarias activas en el conjunto de réplicas. El número de estas secundarias activas determina el número de errores que el servicio puede controlar.
- IdleSecondary (I) : estas réplicas se crean mediante la principal. Van a recibir el estado de la principal antes de que se puedan promover a secundarias activas.
- None (N) : estas réplicas no tienen ninguna responsabilidad en el conjunto de réplicas.
- Unknown (U) : este es el rol inicial de una réplica antes de que reciba una llamada API ChangeRole de Service Fabric.
En el siguiente diagrama se muestran las transiciones de rol de réplica y algunos escenarios de ejemplo en los que se pueden producir:
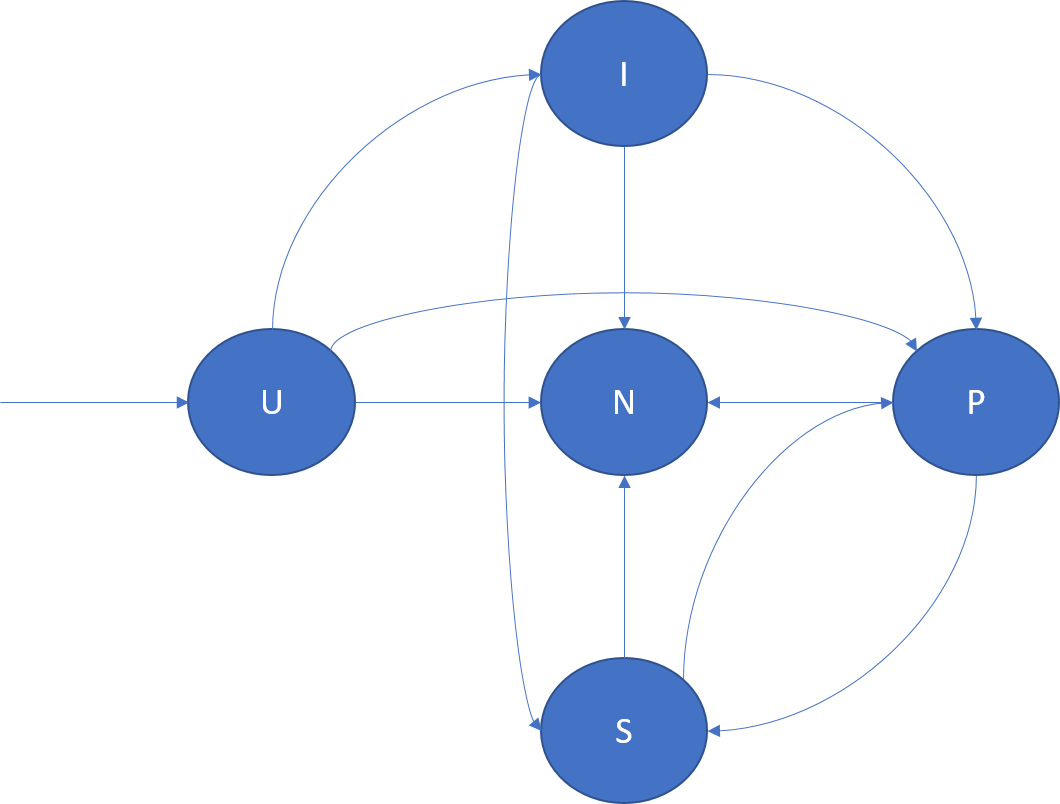
- U -> P: creación de una nueva réplica principal.
- U -> I: creación de una nueva réplica inactiva.
- U -> I: eliminación de una réplica de espera.
- I -> S: promoción de secundaria inactiva a secundaria activa de forma que sus confirmaciones contribuyan hacia el cuórum.
- I -> P: promoción de secundaria inactiva a principal. Esto puede ocurrir bajo reconfiguraciones especiales cuando la secundaria inactiva es la candidata correcta para ser principal.
- I -> N: eliminación de la réplica secundaria inactiva.
- I -> N: promoción de secundaria activa a principal. Esta situación puede deberse a la conmutación por error de la principal o al movimiento de una principal iniciado por Cluster Resource Manager. Por ejemplo, podría ser en respuesta a una actualización de la aplicación o al equilibrio de carga.
- S -> N: eliminación de la réplica secundaria activa.
- P -> S: degradación de la réplica principal. Esta situación puede deberse a un movimiento de la principal iniciado por Cluster Resource Manager. Por ejemplo, podría ser en respuesta a una actualización de la aplicación o al equilibrio de carga.
- P -> N: eliminación de la réplica principal.
Nota:
Los modelos de programación de nivel superior, como Reliable Actors y Reliable Services ocultan el concepto de roles de réplica del desarrollador. En Actors, la noción de un rol es innecesaria. En Services, está enormemente simplificada en la mayoría de los escenarios.
Pasos siguientes
Para más información sobre los conceptos de Service Fabric, consulte el siguiente artículo: