Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Service Fabric facilita la creación de aplicaciones escalables, al administrar los servicios, particiones y réplicas en los nodos de un clúster. La ejecución de muchas cargas de trabajo en el mismo hardware permite el uso máximo de recursos, pero también proporciona flexibilidad en cuanto a cómo elegir escalar las cargas de trabajo. Este vídeo de Channel 9 describe cómo puede crear aplicaciones de microservicios escalables:
El escalado en Service Fabric se realiza de varias maneras diferentes:
- Escalado mediante la creación o eliminación de instancias de servicio sin estado
- Escalado mediante la creación o eliminación de nuevos servicios con nombre
- Escalado mediante la creación o eliminación de nuevas instancias de aplicaciones con nombre
- Escalado mediante el uso de servicios particionados
- Escalado mediante la adición o eliminación de nodos desde el clúster
- Escalado mediante el uso de métricas de Cluster Resource Manager
Escalado mediante la creación o eliminación de instancias de servicio sin estado
Una de las maneras más sencillas de escalar dentro de Service Fabric funciona con los servicios sin estado. Cuando cree un servicio sin estado, obtendrá una oportunidad para definir un InstanceCount. InstanceCount define cuántas copias en ejecución del código de dicho servicio se crean cuando se inicia el servicio. Supongamos, por ejemplo, que hay 100 nodos del clúster. Supongamos también que se crea un servicio con un InstanceCount de 10. Durante el tiempo de ejecución, las 10 copias de ejecución del código podrían estar demasiado ocupadas (o podrían no estar lo suficientemente ocupadas). Una forma de escalar esa carga de trabajo es cambiar el número de instancias. Por ejemplo, un fragmento de código de supervisión o administración puede cambiar el número de instancias existente a 50, o a 5, dependiendo de si la carga de trabajo se debe reducir horizontalmente o escalarse horizontalmente según la carga.
C#:
StatelessServiceUpdateDescription updateDescription = new StatelessServiceUpdateDescription();
updateDescription.InstanceCount = 50;
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
PowerShell:
Update-ServiceFabricService -Stateless -ServiceName $serviceName -InstanceCount 50
Uso de recuento de instancias dinámicas
Específicamente para los servicios sin estado, Service Fabric ofrece un modo automático para cambiar el recuento de instancias. Esto permite que el servicio se escale dinámicamente con el número de nodos que están disponibles. La forma de optar por este comportamiento es establecer el recuento de instancias = -1. InstanceCount = -1 es una instrucción para Service Fabric que dice "Ejecutar este servicio sin estado en cada nodo". Si cambia el número de nodos, Service Fabric automáticamente el recuento de instancias para que coincida, asegurándose de que el servicio se ejecuta en todos los nodos válidos.
C#:
StatelessServiceDescription serviceDescription = new StatelessServiceDescription();
//Set other service properties necessary for creation....
serviceDescription.InstanceCount = -1;
await fc.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateless -PartitionSchemeSingleton -InstanceCount "-1"
Escalado mediante la creación o eliminación de nuevos servicios con nombre
Una instancia de servicio nombrada es una instancia específica de un tipo de servicio (consulte el Ciclo de vida de aplicaciones de Service Fabric) dentro de alguna instancia de aplicación nombrada en el clúster.
Las nuevas instancias de servicio con nombre se pueden crear (o quitar) a medida que los servicios estén más o menos ocupados. Esto permite que las solicitudes abarquen más instancias de servicio, lo que normalmente permite que la carga en los servicios existentes disminuya. Al crear servicios, Cluster Resource Manager de Service Fabric coloca los servicios en el clúster de manera distribuida. Las decisiones exactas se rigen por la métricas en el clúster y otras reglas de colocación. Los servicios se pueden crear de varias maneras diferentes, pero los más comunes son a través de acciones administrativas como alguien que llama a New-ServiceFabricService o mediante una llamada de código CreateServiceAsync. CreateServiceAsync puede incluso llamar desde dentro de otros servicios que se ejecutan en el clúster.
La creación de servicios dinámicamente puede usarse en todo tipo de escenarios y es un patrón común. Por ejemplo, considere la posibilidad de un servicio con estado que representa un flujo de trabajo determinado. Las llamadas que representan el trabajo van a ir mostrándose a este servicio y este servicio va a ejecutar los pasos necesarios para que el flujo de trabajo y el registro progresen.
¿Cómo realizaría esta escala del servicio determinado? El servicio podría ser de alguna forma de tipo multiinquilino y aceptar llamadas e iniciar los pasos para distintas instancias del mismo flujo de trabajo a la vez. Sin embargo, eso puede hacer que el código sea más complejo, ya que ahora tiene que preocuparse de distintas instancias del mismo flujo de trabajo, todo en distintas fases y de diferentes clientes. Además, administrar varios flujos de trabajo al mismo tiempo no soluciona el problema de escala. Esto es porque en algún momento este servicio usará demasiados recursos como para que quepan en una máquina determinada. En primer lugar, muchos servicios que no se crearon para este patrón también experimentan dificultades debido a algún cuello de botella inherente o a la ralentización del código. Estos tipos de problemas provocan que el servicio no funcione bien cuando aumenta el número de flujos de trabajo simultáneos que está realizando el seguimiento.
Una solución consiste en crear una instancia de este servicio para cada instancia diferente del flujo de trabajo de la que desea realizar un seguimiento. Esto es un patrón excelente y funciona si el servicio es con estado o sin estado. Para que este patrón funcione, hay normalmente otro servicio que actúa como un "servicio de administrador de cargas de trabajo". El trabajo de este servicio es recibir las solicitudes y enrutarlas a otros servicios. El administrador puede crear dinámicamente una instancia del servicio de carga de trabajo cuando recibe el mensaje y, a continuación, pasar las solicitudes a esos servicios. El servicio de administrador también podría recibir devoluciones de llamada cuando un servicio de flujo de trabajo determinado complete su trabajo. Si el administrador recibe estas devoluciones de llamada, podría eliminar esa instancia del servicio de flujo de trabajo o dejarla si se esperan más llamadas.
Las versiones avanzadas de este tipo de administrador pueden incluso crear grupos de los servicios que administra. El grupo ayuda a garantizar que, cuando llega una nueva solicitud, no tiene que esperar para que el servicio se ponga en marcha. En su lugar, el administrador puede elegir un servicio de flujo de trabajo que no esté ocupado actualmente desde el grupo o enrutarlo de forma aleatoria. El mantenimiento de un grupo de servicios disponible hace que la administración de nuevas solicitudes sea más rápida, ya que es menos probable que la solicitud tenga que esperar para que un nuevo servicio se ponga en marcha. La creación de nuevos servicios es rápida, pero no es libre o instantánea. El grupo ayuda a minimizar la cantidad de tiempo que la solicitud tiene que esperar antes de recibir servicio. A menudo verá este administrador y el patrón de grupo cuando los tiempos de respuesta tengan mayor importancia. Poner el cola la solicitud y crear el servicio en segundo plano y, a continuación, pasarlo también es un patrón de administrador popular, ya que se están creando y eliminando servicios basados en algún seguimiento de la cantidad de trabajo que el servicio tiene actualmente pendiente.
Escalado mediante la creación o eliminación de nuevas instancias de aplicaciones con nombre
La creación y eliminación de todas las instancias de aplicaciones es similar al patrón de creación y eliminación de servicios. Para este patrón, hay algún servicio de administrador que toma la decisión según las solicitudes que se visualizan y la información que se recibe de otros servicios dentro del clúster.
¿Cuándo se debe crear una nueva instancia de aplicación con nombre en lugar de crear nuevas instancias de servicio con nombre en alguna aplicación ya existente? Hay algunos casos:
- La nueva instancia de aplicación es para un cliente cuyo código debe ejecutarse en alguna identidad determinada o una configuración de seguridad.
- Service Fabric permite definir paquetes de código diferentes que se ejecuten bajo identidades determinadas. Para iniciar el mismo paquete de código con identidades diferentes, las activaciones tienen que producirse en instancias de aplicación diferentes. Considere la posibilidad de un caso en el que tenga cargas de trabajo implementadas de un cliente existente. Se pueden ejecutar bajo una identidad concreta para poder supervisar y controlar su acceso a otros recursos, como bases de datos remotas u otros sistemas. En este caso, cuando un nuevo cliente se registra, probablemente no desea activar su código en el mismo contexto (espacio de proceso). Mientras pueda, resulta más difícil para el código de servicio actuar dentro del contexto de una identidad concreta. Por lo general, debe tener más código de administración de identidad, aislamiento y seguridad. En lugar de usar diferentes instancias de servicio con nombre dentro de la misma instancia de aplicación y, por lo tanto, el mismo espacio de proceso, puede usar distintas instancias de Service Fabric Application con nombre. Esto facilita la definición de diferentes contextos de identidad.
- La nueva instancia de aplicación también actúa como un medio de configuración
- De forma predeterminada, todas las instancias de servicio con nombre de un tipo de servicio determinado dentro de una instancia de aplicación se ejecutarán en el mismo proceso en un nodo determinado. Esto significa que aunque puede configurar cada instancia de servicio de forma diferente, hacerlo es complicado. Los servicios deben tener algunos token que se usan para buscar su configuración dentro de un paquete de configuración. Normalmente es simplemente el nombre del servicio. Esto funciona correctamente, pero asocia la configuración a los nombres de las instancias de servicio con nombre individuales dentro de esa instancia de aplicación. Esto puede ser confuso y difícil de administrar, ya que la configuración es normalmente un artefacto de tiempo de diseño con valores específicos de la instancia de aplicación. La creación de más servicios siempre implica más actualizaciones de aplicaciones para cambiar la información dentro de los paquetes de configuración o implementar otras nuevas para que los nuevos servicios puedan buscar su información específica. A menudo resulta más fácil crear una nueva instancia de aplicación con nombre. A continuación, puede usar los parámetros de aplicación para establecer la configuración necesaria para los servicios. De este modo, todos los servicios que se crean dentro de esa instancia de aplicación con nombre pueden heredar valores de configuración determinados. Por ejemplo, en lugar de tener un único archivo de configuración con la configuración y las personalizaciones de todos los clientes, como secretos o según los límites de recursos del cliente, en su lugar tendría una instancia de aplicación diferente para cada cliente con esta configuración invalidada.
- La nueva aplicación actúa como un límite de actualización
- Dentro de Service Fabric, las instancias de aplicación con nombre diferentes actúan como límites para la actualización. Una actualización de una instancia de aplicación con nombre no afectará al código que está ejecutando otra instancia de aplicación con nombre. Las diferentes aplicaciones terminarán ejecutando versiones distintas del mismo código en los mismos nodos. Esto puede ser un factor cuando se necesita tomar una decisión de escalado porque puede elegir si el nuevo código debe seguir las mismas actualizaciones que otro servicio o no. Por ejemplo, supongamos que se recibe una llamada en el servicio de administrador que se encarga de la escala de cargas de trabajo de un cliente determinado mediante la creación y eliminación de los servicios de forma dinámica. Sin embargo, en este caso, la llamada es para una carga de trabajo asociada a un nuevo cliente. La mayoría de los clientes prefieren estar aislados de los demás no solo por los motivos de seguridad y configuración mencionados anteriormente, sino también porque ofrece mayor flexibilidad en cuanto a la ejecución de versiones específicas del software y a la elección de cuándo llevar a cabo la actualización. También puede crear una nueva instancia de aplicación y establecer ahí el servicio simplemente para realizar más particiones de la cantidad de servicios que tocará cada actualización. Las instancias de aplicaciones independientes proporcionan mayor granularidad al realizar las actualizaciones de aplicación y también permiten las pruebas A/B y las implementaciones Azul/Verde.
- La instancia de aplicación existente está llena
- En Service Fabric, la capacidad de la aplicación es un concepto que puede usar para controlar la cantidad de recursos disponibles para instancias de aplicación determinadas. Por ejemplo, puede decidir que un servicio determinado necesita tener otra instancia creada para realizar la escalación. Sin embargo, esta instancia de aplicación está fuera de su capacidad para una métrica determinada. Si a este cliente o carga de trabajo determinados se les debe seguir concediendo más recursos, podría aumentar la capacidad existente para esa aplicación o crear una nueva.
Ajuste de escala en el nivel de partición
Service Fabric es compatible con la creación de particiones. La partición divide un servicio en varias secciones lógicas y físicas, cada una de las cuales actúa independientemente. Esto resulta útil con los servicios con estado, ya que ningún otro conjunto de réplicas tiene que administrar todas las llamadas y manipular todo el estado al mismo tiempo. En la Información general de la creación de particiones se ofrece información sobre los tipos de esquemas de particiones que se admiten. Las réplicas de cada partición se reparten entre los nodos en un clúster, distribuyendo la carga de dicho servicio y garantizando que ni el servicio como un todo o cualquier partición tiene un único punto de error.
Considere la posibilidad de que un servicio que usa un esquema de particiones de intervalo con una clave baja de 0, una clave alta de 99 y un recuento de 4 particiones. En un clúster de 3 nodos, el servicio podría estar dispuesto con cuatro réplicas que comparten los recursos en cada nodo, como se muestra aquí.
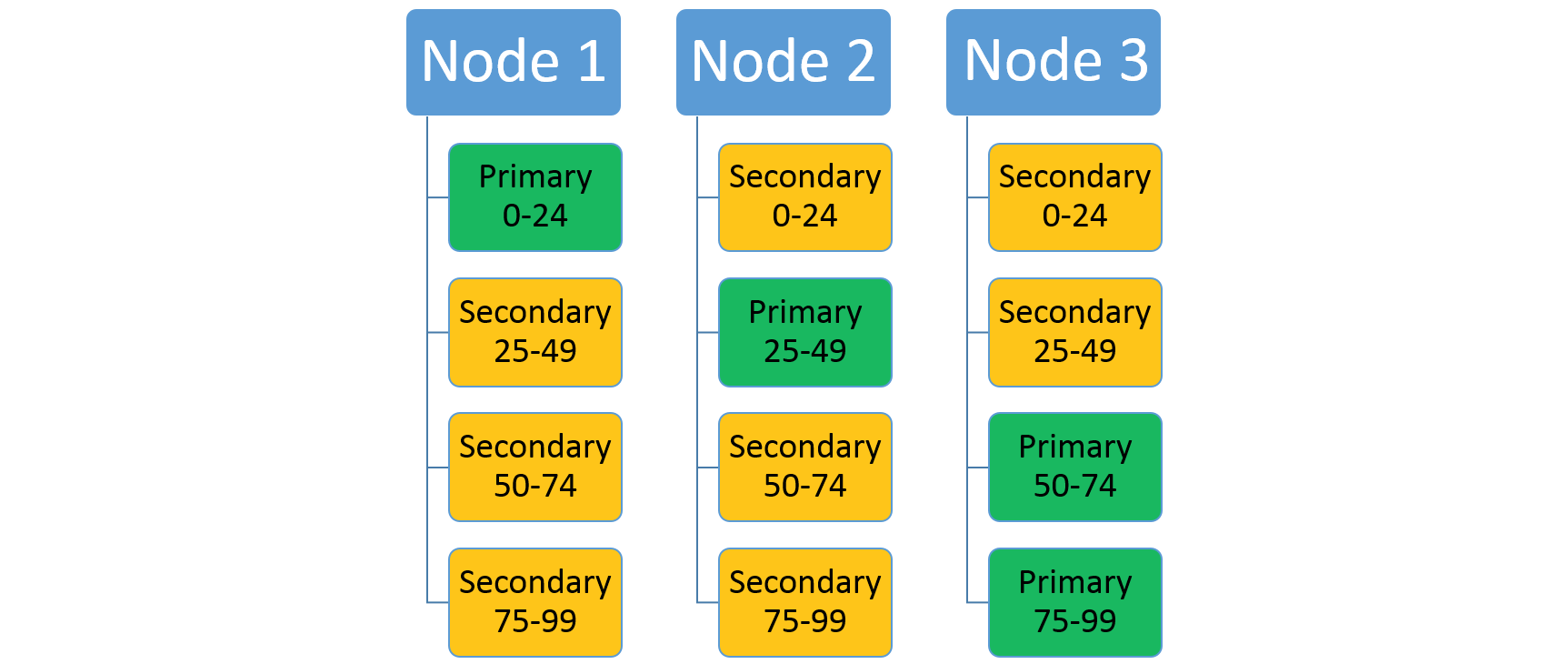
Si aumenta el número de nodos, Service Fabric moverá algunas de las réplicas existentes allí. Por ejemplo, digamos que el número de nodos aumenta a cuatro y las réplicas se redistribuyen. Ahora el servicio tiene tres réplicas que se ejecutan en cada nodo y cada uno de ellos pertenece a distintas particiones. Esto permite una mejor utilización de recursos, puesto que el nuevo nodo no está inactivo. Normalmente, también mejora el rendimiento, ya que cada servicio tiene más recursos a su disposición.
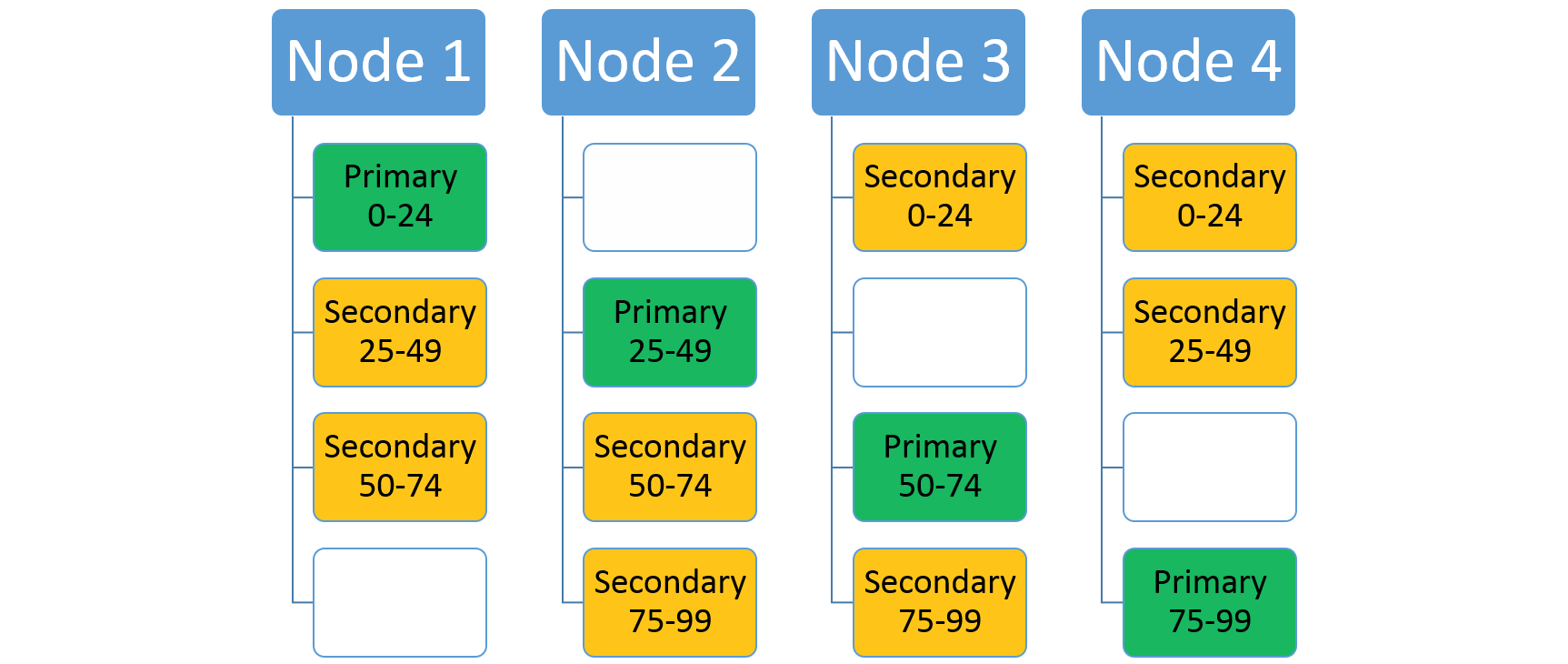
Escalado mediante el uso de Cluster Resource Manager de Service Fabric y métricas
Las métricas son cómo los servicios expresan su consumo de recursos a Service Fabric. El uso de métricas proporciona a Cluster Resource Manager una oportunidad para reorganizar y optimizar el diseño del clúster. Por ejemplo, puede haber una gran cantidad de recursos en el clúster, pero puede que no se asignen a los servicios que están realizando el trabajo actualmente. Usar las métricas permite que Cluster Resource Manager reorganice el clúster para asegurarse de que los servicios tienen acceso a los recursos disponibles.
Escalado mediante la adición o eliminación de nodos desde el clúster
Otra opción para el escalado con Service Fabric es cambiar el tamaño del clúster. Cambiar el tamaño del clúster significa agregar o quitar nodos en uno o varios de los tipos de nodos del clúster. Por ejemplo, considere un caso en el que todos los nodos del clúster estén activos. Esto significa que se han consumido casi todos los recursos del clúster. En este caso, agregar más nodos al clúster es la mejor forma de escalar. Una vez que los nuevos nodos se unan al clúster, Cluster Resource Manager de Service Fabric mueve servicios a ellos, lo que genera una carga total inferior en los nodos existentes. Para servicios sin estado con un recuento de instancias = -1, se crean automáticamente más instancias de servicio. Esto permite que algunas llamadas se muevan de los nodos existentes a los nuevos.
Para más información, consulte el artículo sobre el escalado de clústeres.
Elección de una plataforma
Debido a las diferencias de implementación entre los sistemas operativos, elegir si usar Service Fabric con Windows o Linux puede ser una parte fundamental del escalado de la aplicación. Una posible barrera es cómo se realiza el registro de almacenamiento provisional. Service Fabric en Windows usa un controlador de kernel para un registro individual por máquina, compartido entre réplicas de servicio con estado. Este registro tiene un tamaño de unos 8 GB. Por su parte, Linux usa un registro de almacenamiento provisional de 256 MB para cada réplica, lo que lo hace menos idóneo para aplicaciones que desean maximizar el número de réplicas de servicio ligero que se ejecutan en un nodo determinado. Estas diferencias en los requisitos de almacenamiento temporal podrían ayudar a decidir cuál es la plataforma deseada para la implementación de un clúster de Service Fabric.
Resumen
Tomemos todas las ideas que analizamos aquí y hablemos sobre un ejemplo. Considere el servicio siguiente: intenta crear un servicio que actúe como libreta de direcciones con nombres e información de contacto.
En principio, tiene una serie de preguntas relacionadas con la escala: ¿Cuántos usuarios tendrá? ¿Cuántos contactos almacenará cada usuario? Tratar de saber esta información cuando está configurado el servicio por primera vez es complicado. Supongamos que va a utilizar un servicio estático único con un número de particiones específico. Las consecuencias de elegir un recuento de particiones incorrecto podrían significar que tenga que escalar problemas más adelante. De forma similar, incluso si elige el número correcto, es posible que no disponga de toda la información que necesita. Por ejemplo, también tiene que decidir el tamaño del clúster previamente, en relación con el número de nodos y sus tamaños. Normalmente es difícil predecir la cantidad de recursos que va a consumir un servicio durante su vigencia. También puede ser difícil saber de antemano el patrón de tráfico que ve realmente el servicio. Por ejemplo, puede que haya personas que lo primero que haga en la mañana sea agregar y quitar sus contactos o puede que distribuya esta tarea de forma equitativa durante el transcurso del día. Según esta información, puede que necesite escalar o reducir horizontalmente. Quizá que puede aprender a predecir cuándo se va a necesitar realizar una escalación horizontal, pero, probablemente, en cualquier caso va a necesitar reaccionar ante el cambiante consumo de recursos del servicio. Esto puede implicar el cambio del tamaño del clúster con el fin de proporcionar más recursos cuando la reorganización del uso de los recursos existentes no sea suficiente.
Pero ¿por qué debería intentar incluso elegir un esquema de una partición para todos los usuarios? ¿Por qué limitarse a un servicio y a un clúster estático? La situación real es normalmente más dinámica.
Al realizar la compilación para la escala, considere el siguiente patrón dinámico. Es posible que tenga que adaptarlo a su situación:
- En lugar de intentar elegir un esquema de partición para todos por adelantado, cree un "servicio de administrador".
- El trabajo del servicio de administrador es observar la información del cliente cuando se registra en el servicio. Luego, en función de esa información, el servicio de administrador crea una instancia del servicio de almacenamiento de contactos realsolo para ese cliente. Si requieren una configuración específica, aislamiento o actualizaciones, también puede decidir poner en marcha una instancia de aplicación para este cliente.
Este patrón dinámico de creación implica muchas ventajas:
- No intenta adivinar el número de particiones correcto para todos los usuarios por adelantado ni crea un servicio único que sea infinitamente escalable por sí mismo.
- Los distintos usuarios no tiene que tener el mismo número de particiones, número de réplicas, restricciones de colocación, métricas, cargas predeterminadas, nombres de servicio, configuración DNS o cualquier otra propiedad especificada en el servicio o nivel de aplicación.
- Obtiene una segmentación de datos adicional. Cada cliente tiene su propia copia del servicio
- El servicio de cada cliente se puede configurar de forma distinta y se le puede conceder más o menos recursos, con más o menos particiones o réplicas según sea necesario en función de la escala esperada.
- Por ejemplo, digamos que el cliente ha pagado por el nivel "Oro". Podría obtener un número de particiones mayor o más réplicas, y posiblemente recursos dedicados a sus servicios a través de métricas y capacidades de aplicación.
- O supongamos que proporcionó información que indicaba que el número de contactos que necesitaba era "pequeño". En este caso, solo recibiría unas pocas particiones o podría incluso colocarse en un grupo de servicios compartido con otros clientes.
- El servicio de cada cliente se puede configurar de forma distinta y se le puede conceder más o menos recursos, con más o menos particiones o réplicas según sea necesario en función de la escala esperada.
- No está ejecutando un grupo de instancias de servicio o réplicas mientras espera que aparezcan los clientes
- Si se va algún cliente, quitar su información del servicio es tan simple como que el administrador elimine el servicio o aplicación que se creó.
Pasos siguientes
Para más información sobre los conceptos de Service Fabric, consulte los siguientes artículos: