Implementación de un clúster de Azure Service Fabric en Availability Zones
Las zonas de disponibilidad de Azure son una función de alta disponibilidad que protege las aplicaciones y los datos frente a errores del centro de datos. Una zona de disponibilidad es una ubicación física única equipada con alimentación independiente, refrigeración y redes dentro de una región de Azure.
Para admitir clústeres que abarcan distintas instancias de Availability Zones, Azure Service Fabric proporciona los dos métodos de configuración que se describen en el artículo siguiente. Las zonas de disponibilidad solo se ofrecen en algunas regiones. Para más información, consulte la información general sobre las zonas de disponibilidad.
Hay plantillas de ejemplo disponibles en el repositorio de plantillas para uso entre zonas de disponibilidad de Service Fabric.
Topología para abarcar un tipo de nodo principal en diversas zonas de disponibilidad
Nota:
La ventaja de abarcar el tipo de nodo principal entre zonas de disponibilidad solo se ve para tres zonas y no solo dos.
- El nivel de confiabilidad del clúster ha de establecerse en
Platinum. - Un único recurso de IP pública que use la SKU Estándar.
- Un único recurso de Load Balancer que use la SKU Estándar.
- Un grupo de seguridad de red (NSG) referenciado por la subred en la que implementar los conjuntos de escalado de máquinas virtuales.
Nota:
La propiedad de grupo de selección única del conjunto de escalado de máquinas virtuales debe haberse establecido en true.
La siguiente lista de nodos de ejemplo muestra los formatos FD/UD en un conjunto de escalado de máquinas virtuales que expande zonas:
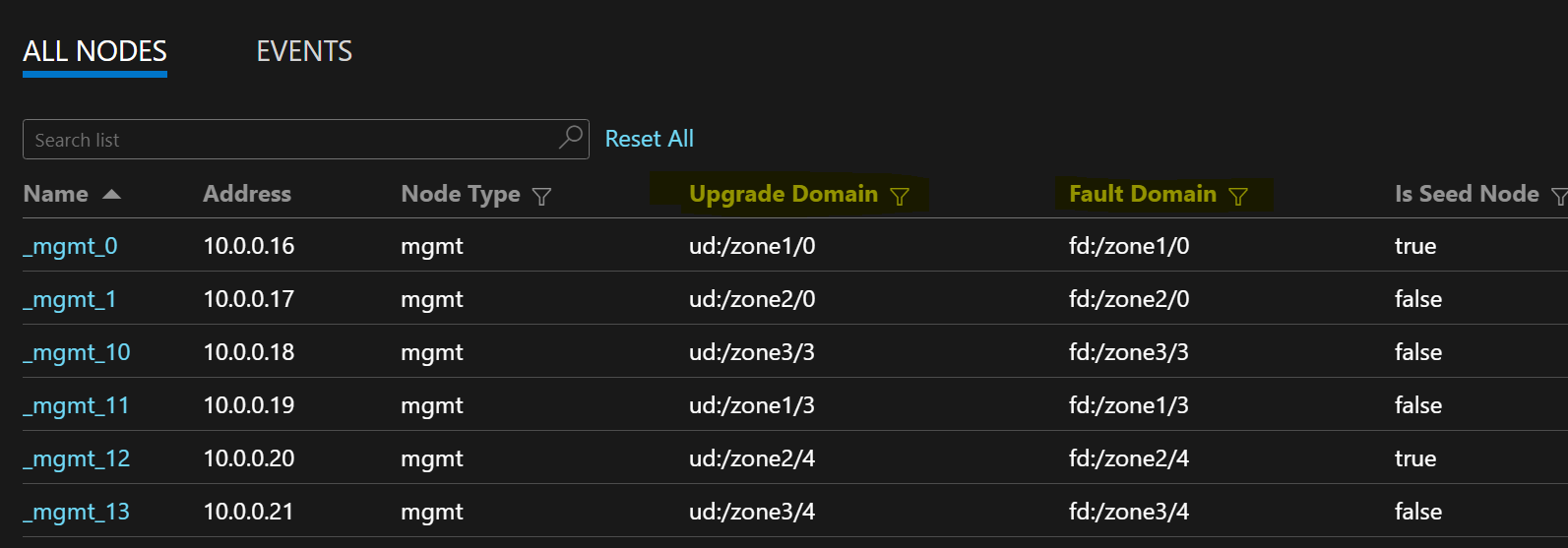
Distribución de réplicas de servicio entre zonas
Al implementar un servicio en los tipos de nodo que expanden Availability Zones, las réplicas se incluyen para garantizar que se encuentren en zonas independientes. Los dominios de error en los nodos de cada uno de estos tipos de nodo se configuran con la información de zona (es decir, FD = fd:/zone1/1, etc.). Por ejemplo, para cinco réplicas o instancias de servicio, la distribución es 2-2-1 y el entorno de ejecución intentará garantizar una distribución uniforme entre zonas.
Configuración de la réplica de servicio de usuario
Los servicios de usuario con estado implementados en los tipos de nodo entre Availability Zones deben configurarse de esta forma: número de réplicas con destino = 9, min = 5. Esta configuración permite que el servicio funcione incluso cuando una zona deje de estar disponible, ya que seguirán habiendo seis réplicas activas en las otras dos zonas. Una actualización de la aplicación en este escenario también tendrá éxito.
Elemento ReliabilityLevel del clúster
Este valor define el número de nodos raíz del clúster y el tamaño de réplica de los servicios del sistema. Una configuración entre zonas de disponibilidad tiene un mayor número de nodos, que se distribuyen entre zonas para habilitar la resistencia de zona.
Un valor ReliabilityLevel más elevado garantiza que haya presentes más nodos raíz y réplicas de servicio del sistema y se distribuyan uniformemente entre zonas, de tal manera que si se produce un error en una zona, el clúster y los servicios del sistema no se verán afectados. El valor ReliabilityLevel = Platinum (recomendado) garantiza que nueve nodos raíz se extiendan entre zonas del clúster, con tres valores en cada zona.
Escenario de zona fuera de servicio
Cuando una zona está fuera de servicio, todos los nodos y las réplicas de servicio de esa zona aparecen fuera de servicio. Como hay réplicas en las demás zonas, el servicio seguirá respondiendo. Las réplicas principales conmutan por error en las zonas funcionales. Los servicios están en estado de advertencia aparentemente porque el número de réplicas de destino aún no se ha alcanzado y el número de máquinas virtuales sigue siendo mayor que el tamaño mínimo de réplica de destino.
El equilibrador de carga de Service Fabric abrirá las réplicas en las zonas funcionales para que coincidan con el número de réplicas de destino. En este momento, los servicios aparecerán correctamente. Cuando la zona que estaba fuera de servicio vuelve a ser funcional, el equilibrador de carga redistribuye todas las réplicas de servicio uniformemente entre las zonas.
Próximas optimizaciones
- Para proporcionar actualizaciones de infraestructura confiables, Service Fabric requiere que la durabilidad del conjunto de escalado de máquinas virtuales se establezca al menos en Silver. Esto permite que el conjunto de escalado de máquinas virtuales subyacente y el entorno de ejecución de Service Fabric proporcionen actualizaciones confiables. Esto también requiere que cada zona tenga como mínimo 5 VM. Estamos trabajando para bajar este requisito a 3 y 2 VM por zona para los tipos de nodo principales y no principales, respectivamente.
- Todas las configuraciones mencionadas a continuación y el próximo trabajo proporcionan migración local a los clientes donde se puede actualizar el mismo clúster para usar la nueva configuración mediante la adición de nuevos elementos nodeTypes y la retirada de los antiguos.
Requisitos de red
Recurso de IP pública y equilibrador de carga
Para habilitar la propiedad zones en un recurso de conjunto de escalado de máquinas virtuales, el recurso de equilibrador de carga e IP referenciado por ese conjunto de escalado de máquinas virtuales deben utilizar una SKU Estándar. La creación de un equilibrador de carga o un recurso de IP sin la propiedad SKU da lugar a una SKU Básica, que no admite Availability Zones. De forma predeterminada, un equilibrador de carga de SKU Estándar bloquea todo el tráfico desde fuera. Para permitir el tráfico externo, implemente un NSG en la subred.
{
"apiVersion": "2018-11-01",
"type": "Microsoft.Network/publicIPAddresses",
"name": "[concat('LB','-', parameters('clusterName')]",
"location": "[parameters('computeLocation')]",
"sku": {
"name": "Standard"
}
}
{
"apiVersion": "2018-11-01",
"type": "Microsoft.Network/loadBalancers",
"name": "[concat('LB','-', parameters('clusterName')]",
"location": "[parameters('computeLocation')]",
"dependsOn": [
"[concat('Microsoft.Network/networkSecurityGroups/', concat('nsg', parameters('subnet0Name')))]"
],
"properties": {
"addressSpace": {
"addressPrefixes": [
"[parameters('addressPrefix')]"
]
},
"subnets": [
{
"name": "[parameters('subnet0Name')]",
"properties": {
"addressPrefix": "[parameters('subnet0Prefix')]",
"networkSecurityGroup": {
"id": "[resourceId('Microsoft.Network/networkSecurityGroups', concat('nsg', parameters('subnet0Name')))]"
}
}
}
]
},
"sku": {
"name": "Standard"
}
}
Nota:
No es posible hacer un cambio en contexto de SKU en los recursos de IP pública y equilibrador de carga. Si va a hacer una migración a partir de recursos existentes que tienen una SKU Básica, consulte la sección sobre migración en este artículo.
Reglas NAT para conjuntos de escalado de máquinas virtuales
Las reglas de traducción de direcciones de red (NAT) de entrada para el equilibrador de carga deben coincidir con los grupos NAT del conjunto de escalado de máquinas virtuales. Cada conjunto de escalado de máquinas virtuales debe tener un único grupo NAT de entrada.
{
"inboundNatPools": [
{
"name": "LoadBalancerBEAddressNatPool0",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "50999",
"frontendPortRangeStart": "50000",
"protocol": "tcp"
}
},
{
"name": "LoadBalancerBEAddressNatPool1",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "51999",
"frontendPortRangeStart": "51000",
"protocol": "tcp"
}
},
{
"name": "LoadBalancerBEAddressNatPool2",
"properties": {
"backendPort": "3389",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPortRangeEnd": "52999",
"frontendPortRangeStart": "52000",
"protocol": "tcp"
}
}
]
}
Reglas de salida para un equilibrador de carga de SKU Estándar
El equilibrador de carga y la IP pública de SKU Estándar presentan nuevas funciones y comportamientos diferentes para la conectividad de salida en comparación con el uso de SKU básicas. Si desea obtener conectividad de salida cuando trabaje con las SKU estándar, debe definirlas explícitamente con una dirección IP pública o un equilibrador de carga de SKU Estándar. Para más información, consulte Conexiones de salida y ¿Qué es Azure Load Balancer?
Nota:
La plantilla estándar hace referencia a un NSG que permite todo el tráfico saliente de forma predeterminada. El tráfico de entrada se limita a los puertos necesarios para las operaciones de administración de Service Fabric. Las reglas de NSG pueden modificarse para satisfacer sus requisitos.
Importante
Cada tipo de nodo de un clúster de Service Fabric que use un equilibrador de carga de SKU Estándar requiere una regla que permita el tráfico saliente en el puerto 443. Esto es necesario para completar la configuración del clúster. Cualquier implementación que no incluya esta regla generará un error.
1. Habilitación de varias zonas de disponibilidad en un único conjunto de escalado de máquinas virtuales
Esta solución permite a los usuarios abarcar tres instancias de Availability Zones en el mismo tipo de nodo. Se trata de la topología de implementación recomendada, ya que permite realizar la implementación entre zonas de disponibilidad mientras se mantiene un único conjunto de escalado de máquinas virtuales.
GitHub tiene una plantilla de ejemplo a su disposición.
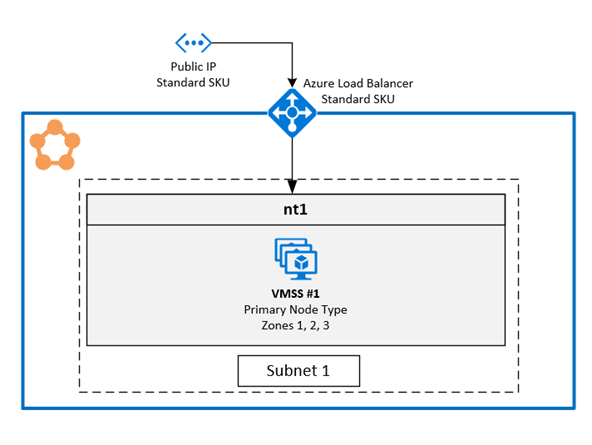
Configuración de zonas en un conjunto de escalado de máquinas virtuales
Para habilitar zonas en un conjunto de escalado de máquinas virtuales, incluya los tres valores siguientes en el recurso del conjunto de escalado de máquinas virtuales:
El primer valor es la propiedad
zones, que especifica las zonas de disponibilidad que están presentes en el conjunto de escalado de máquinas virtuales.El segundo valor es la propiedad
singlePlacementGroup, que se debe establecer entrue. El conjunto de escalado que se extiende entre tres zona de disponibilidad puede admitir hasta 300 máquinas virtuales incluso consinglePlacementGroup = true.El tercer valor es
zoneBalance, que garantiza el equilibrio de zona estricta. Este valor debe sertrue. Esto garantiza que las distribuciones de máquinas virtuales entre zonas no sean desiguales, lo cual significa que cuando una de las zonas deja de funcionar, las otras dos zonas disponen de suficientes máquinas virtuales para que el clúster sigue ejecutándose.Es posible que un clúster con una distribución desigual de máquinas virtuales no sobreviva a un escenario de zona fuera de servicio, ya que esa zona podría acaparar la mayoría de las máquinas virtuales. La distribución desigual de máquinas virtuales entre zonas también provoca problemas relacionados con la prestación de servicios y el bloqueo de las actualizaciones de infraestructura. Más información sobre zoneBalancing.
No es necesario configurar las invalidaciones FaultDomain y UpgradeDomain.
{
"apiVersion": "2018-10-01",
"type": "Microsoft.Compute/virtualMachineScaleSets",
"name": "[parameters('vmNodeType1Name')]",
"location": "[parameters('computeLocation')]",
"zones": [ "1", "2", "3" ],
"properties": {
"singlePlacementGroup": true,
"zoneBalance": true
}
}
Nota:
- Los clústeres de Service Fabric deben tener al menos un tipo principal de nodo. El nivel de durabilidad de los tipos de nodo principal debe ser Silver o superior.
- Una Azure Availability Zones de disponibilidad que extiende los conjuntos de escalado de máquinas virtuales debe configurarse con tres zona de disponibilidad como mínimo, independientemente del nivel de durabilidad.
- Una zona de disponibilidad que extienden conjuntos de escalado de máquinas virtuales con el nivel de durabilidad Silver o superior deben tener al menos 15 máquinas virtuales (5 por región).
- La zona de disponibilidad que abarca el conjunto de escalado de máquinas virtuales con durabilidad Bronze debe tener al menos 6 máquinas virtuales.
Habilitación de la compatibilidad con varias zonas en el tipo de nodo de Service Fabric
El tipo de nodo de Service Fabric debe estar habilitado para admitir varias zonas de disponibilidad.
El primer valor es
multipleAvailabilityZones, que se debe establecer entruepara el tipo de nodo.El segundo valor es
sfZonalUpgradeModey es opcional. Esta propiedad no se puede modificar si ya existe un tipo de nodo con varias zonas de disponibilidad en el clúster. Esta propiedad determina la agrupación lógica de máquinas virtuales en los dominios de actualización (UD).- Si este valor se establece en
Parallel, las máquinas virtuales del tipo de nodo se agrupan en UD y omiten la información de zona en cinco UD. Esta configuración hace que los UD de todas las zonas se actualicen al mismo tiempo. Este modo de implementación es más rápido para las actualizaciones. No se recomienda su uso, ya que se trata de instrucciones SDP que indican que las actualizaciones deben aplicarse en una zona cada vez. - Si el valor se omite o se establece en
Hierarchical, las máquinas virtuales se agruparán para reflejar la distribución de zonas en un máximo de 15 UD. Cada una de las tres zonas tiene cinco UD. De este modo, se garantiza que las zonas se actualicen de una en una y que solo se pase a la zona siguiente después de completar cinco UD en la primera zona. Este proceso de actualización es más seguro para el clúster y la aplicación de usuario.
La propiedad solo define el comportamiento de actualización de la aplicación Service Fabric y las actualizaciones de código. Las actualizaciones del conjunto subyacente de escalado de máquinas virtuales seguirán produciéndose simultáneamente en todas las zonas de disponibilidad. Esta propiedad no afecta a la distribución de UD para los tipos de nodo que no tengan habilitadas varias zonas.
- Si este valor se establece en
El tercer valor es
vmssZonalUpgradeMode, es opcional y se puede actualizar en cualquier momento. Esta propiedad define el esquema de actualización para que el conjunto de escalado de máquinas virtuales se pueda realizar en paralelo o secuencialmente en Availability Zones.- Si este valor se establece en
Parallel: todas las actualizaciones del conjunto de escalado se suceden en paralelo en todas las zonas. Este modo de implementación es más rápido para las actualizaciones. No se recomienda su uso, ya que se trata de instrucciones SDP que indican que las actualizaciones deben aplicarse en una zona cada vez. - Si este valor se omite o se establece en
Hierarchical: se garantiza que las zonas se actualicen de una en una y que solo se pase a la zona siguiente después de completar cinco UD en la primera zona. Este proceso de actualización es más seguro para el clúster y la aplicación de usuario.
- Si este valor se establece en
Importante
La versión de API del recurso de clúster de Service Fabric debe ser la 2020-12-01 (versión preliminar) o superior.
La versión del código del clúster debe ser 8.1.321 o posterior.
{
"apiVersion": "2020-12-01-preview",
"type": "Microsoft.ServiceFabric/clusters",
"name": "[parameters('clusterName')]",
"location": "[parameters('clusterLocation')]",
"dependsOn": [
"[concat('Microsoft.Storage/storageAccounts/', parameters('supportLogStorageAccountName'))]"
],
"properties": {
"reliabilityLevel": "Platinum",
"sfZonalUpgradeMode": "Hierarchical",
"vmssZonalUpgradeMode": "Parallel",
"nodeTypes": [
{
"name": "[parameters('vmNodeType0Name')]",
"multipleAvailabilityZones": true
}
]
}
}
Nota:
- Los recursos de IP pública y equilibrar la carga deben usar la SKU Estándar, tal como se describió anteriormente en el artículo.
- La propiedad
multipleAvailabilityZonesdel tipo de nodo solo se puede definir cuando se haya creado el tipo de nodo y no se podrá modificar más adelante. Los tipos de nodo existentes no se pueden configurar con esta propiedad. - Cuando
sfZonalUpgradeModese omite o se establece enHierarchical, las implementaciones de clúster y aplicación serán más lentas porque habrá más dominios de actualización en el clúster. Es importante ajustar correctamente los tiempos de inactividad de la directiva de actualización para tener en cuenta el tiempo de actualización necesario para 15 dominios de actualización. La directiva de actualización para la aplicación y el clúster debe actualizarse para garantizar que la implementación no supere el límite de tiempo de implementación de 12 horas de Azure Resource Service. Esto significa que la implementación no debe tardar más de 12 horas para 15 UD (es decir, no debe tardar más de 40 minutos con cada UD). - Establezca el nivel de confiabilidad del clúster en
Platinumpara garantizar que el clúster sobreviva al escenario con una zona fuera de servicio. - No se admite la actualización de DurabilityLevel para un tipo de nodo con multipleAvailabilityZones. En su lugar, cree un tipo de nodo con mayor durabilidad.
- SF solo admite tres AvailabilityZones. Por el momento, no se admite ningún número mayor.
Sugerencia
Se recomienda establecer sfZonalUpgradeMode en Hierarchical, o bien omitirlo. La implementación seguirá la distribución de zonas de las máquinas virtuales y afecta a un número más reducido de réplicas o instancias, por lo estas son más seguras.
Use sfZonalUpgradeMode establecido en Parallel si la velocidad de implementación es una prioridad o solo se ejecuta una carga de trabajo sin estado en el tipo de nodo con varias zonas de disponibilidad. Esto hará que el recorrido del dominio de actualización tenga lugar al mismo tiempo en todas las zonas de disponibilidad.
Migración al tipo de nodo con varias zonas de disponibilidad
En todos los escenarios de migración, es necesario agregar un nuevo tipo de nodo que admita varias zonas de disponibilidad. No se puede migrar un tipo de nodo existente para admitir varias zonas. El artículo Escalado vertical de un del tipo de nodo principal de un clúster de Service Fabric incluye pasos detallados para agregar un nuevo tipo de nodo y los demás recursos necesarios para el nuevo tipo de nodo, como los recursos de IP y equilibrador de carga. En el artículo se describe también cómo retirar el tipo de nodo existente después de agregar al clúster un nuevo tipo de nodo con varias zonas de disponibilidad.
Migración desde un tipo de nodo que usa recursos de equilibrador de carga e IP básicos. Este proceso ya se describe en una subsección posterior para la solución con un tipo de nodo por zona de disponibilidad.
Para el nuevo tipo de nodo, la única diferencia es que solo hay un conjunto de escalado de máquinas virtuales y un tipo de nodo para todas las zonas de disponibilidad, en lugar de uno por zona de disponibilidad.
Migración desde un tipo de nodo que usa los recursos de equilibrador de carga e IP de SKU Estándar con un NSG. Siga el procedimiento descrito anteriormente. Sin embargo, no es necesario agregar nuevos recursos de equilibrador de carga, IP y NSG. Se pueden reutilizar los mismos recursos en el nuevo tipo de nodo.
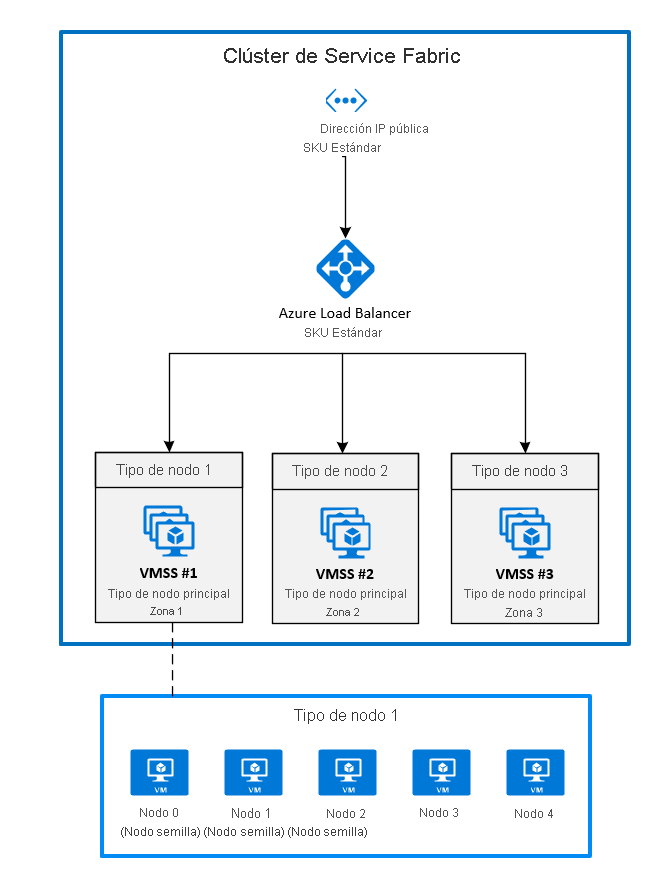
2. Implementación de zonas mediante el anclaje de un conjunto de escalado de máquinas virtuales a cada zona
Esta es la configuración disponible con carácter general en este momento. Para extender un clúster de Service Fabric entre Availability Zones, debe crear un tipo de nodo principal en cada zona de disponibilidad admitida por la región. De este modo, se distribuyen nodos raíz de manera uniforme entre todos los tipos de nodos principales.
La topología recomendada para el tipo de nodo principal requiere lo siguiente:
- Tres tipos de nodo deben marcarse como principales.
- Cada tipo de nodo debe asignarse a su propio conjunto de escalado de máquinas virtuales ubicado en distintas zonas.
- Cada conjunto de escalado de máquinas virtuales debe tener al menos cinco nodos (durabilidad Silver).
El diagrama siguiente muestra la arquitectura de la zona de disponibilidad de Azure Service Fabric.
Habilitación de zonas en un conjunto de escalado de máquinas virtuales
Para habilitar una zona en un conjuntos de escalado de máquinas virtuales, incluya estos tres valores en el recurso del conjunto de escalado de máquinas virtuales:
- El primer valor es la propiedad
zones, que especifica en qué zona de disponibilidad se implementará el conjunto de escalado de máquinas virtuales. - El segundo valor es la propiedad
singlePlacementGroup, que se debe establecer entrue. - El tercer valor es la propiedad
faultDomainOverrideen la extensión de conjunto de escalado de máquinas virtuales de Service Fabric. Esta propiedad debe incluir solo la zona en la que se incluirá este conjunto de escalado de máquinas virtuales. Ejemplo:"faultDomainOverride": "az1". Todos los recursos del conjunto de escalado de máquinas virtuales se deben incluir en la misma región porque los clústeres de Azure Service Fabric no ofrecen compatibilidad entre regiones.
{
"apiVersion": "2018-10-01",
"type": "Microsoft.Compute/virtualMachineScaleSets",
"name": "[parameters('vmNodeType1Name')]",
"location": "[parameters('computeLocation')]",
"zones": [
"1"
],
"properties": {
"singlePlacementGroup": true
},
"virtualMachineProfile": {
"extensionProfile": {
"extensions": [
{
"name": "[concat(parameters('vmNodeType1Name'),'_ServiceFabricNode')]",
"properties": {
"type": "ServiceFabricNode",
"autoUpgradeMinorVersion": false,
"publisher": "Microsoft.Azure.ServiceFabric",
"settings": {
"clusterEndpoint": "[reference(parameters('clusterName')).clusterEndpoint]",
"nodeTypeRef": "[parameters('vmNodeType1Name')]",
"dataPath": "D:\\\\SvcFab",
"durabilityLevel": "Silver",
"certificate": {
"thumbprint": "[parameters('certificateThumbprint')]",
"x509StoreName": "[parameters('certificateStoreValue')]"
},
"systemLogUploadSettings": {
"Enabled": true
},
"faultDomainOverride": "az1"
},
"typeHandlerVersion": "1.0"
}
}
]
}
}
}
Habilitación de varios tipos de nodos principales en el recurso de clúster de Service Fabric
Para establecer uno o más tipos de nodo como principales en un recurso de clúster, establezca la propiedad isPrimary en true. Al implementar un clúster de Service Fabric en Availability Zones, debe tener tres tipos de nodo en distintas zonas.
{
"reliabilityLevel": "Platinum",
"nodeTypes": [
{
"name": "[parameters('vmNodeType0Name')]",
"applicationPorts": {
"endPort": "[parameters('nt0applicationEndPort')]",
"startPort": "[parameters('nt0applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt0fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt0ephemeralEndPort')]",
"startPort": "[parameters('nt0ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt0fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt0InstanceCount')]"
},
{
"name": "[parameters('vmNodeType1Name')]",
"applicationPorts": {
"endPort": "[parameters('nt1applicationEndPort')]",
"startPort": "[parameters('nt1applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt1fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt1ephemeralEndPort')]",
"startPort": "[parameters('nt1ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt1fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt1InstanceCount')]"
},
{
"name": "[parameters('vmNodeType2Name')]",
"applicationPorts": {
"endPort": "[parameters('nt2applicationEndPort')]",
"startPort": "[parameters('nt2applicationStartPort')]"
},
"clientConnectionEndpointPort": "[parameters('nt2fabricTcpGatewayPort')]",
"durabilityLevel": "Silver",
"ephemeralPorts": {
"endPort": "[parameters('nt2ephemeralEndPort')]",
"startPort": "[parameters('nt2ephemeralStartPort')]"
},
"httpGatewayEndpointPort": "[parameters('nt2fabricHttpGatewayPort')]",
"isPrimary": true,
"vmInstanceCount": "[parameters('nt2InstanceCount')]"
}
]
}
Migración a Availability Zones desde un clúster mediante el equilibrador de carga y una IP de SKU Básica
Para migrar un clúster que usa una instancia de equilibrador de carga y una IP con una SKU Básica, primero deberá crear un recurso completamente nuevo de equilibrador de carga e IP mediante la SKU Estándar. No es posible actualizar estos recursos.
Haga referencia al nuevo equilibrador de carga e IP en los nuevos tipos de nodo entre zonas de disponibilidad que desea usar. En el ejemplo anterior, se agregaron tres nuevos recursos de conjunto de escalado de máquinas virtuales en las zonas 1, 2 y 3. Estos conjuntos de escalado de máquinas virtuales hacen referencia a al equilibrador de carga e IP recién creados y se identifican como tipos de nodo principal en el recurso de clúster de Service Fabric.
Para empezar, agregue los nuevos recursos a la plantilla existente de Azure Resource Manager. Estos recursos incluyen:
- Un recurso de IP pública que usa la SKU Estándar.
- Un recurso de equilibrador de carga que usa la SKU Estándar.
- Un NSG referenciado por la subred en la que se implementan los conjuntos de escalado de máquinas virtuales.
- Tres tipos de nodo deben marcarse como principales.
- Cada tipo de nodo debe asignarse a su propio conjunto de escalado de máquinas virtuales ubicado en distintas zonas.
- Cada conjunto de escalado de máquinas virtuales debe tener al menos cinco nodos (durabilidad Silver).
Puede encontrar un ejemplo de estos recursos en la plantilla de ejemplo.
New-AzureRmResourceGroupDeployment ` -ResourceGroupName $ResourceGroupName ` -TemplateFile $Template ` -TemplateParameterFile $ParametersUna vez que ha terminado la implementación de los recursos, puede deshabilitar los nodos en el tipo de nodo principal del clúster original. Cuando los nodos estén deshabilitados, los servicios del sistema se migrarán al nuevo tipo de nodo principal que implementó anteriormente.
Connect-ServiceFabricCluster -ConnectionEndpoint $ClusterName ` -KeepAliveIntervalInSec 10 ` -X509Credential ` -ServerCertThumbprint $thumb ` -FindType FindByThumbprint ` -FindValue $thumb ` -StoreLocation CurrentUser ` -StoreName My Write-Host "Connected to cluster" $nodeNames = @("_nt0_0", "_nt0_1", "_nt0_2", "_nt0_3", "_nt0_4") Write-Host "Disabling nodes..." foreach($name in $nodeNames) { Disable-ServiceFabricNode -NodeName $name -Intent RemoveNode -Force }Una vez que todos los nodos están deshabilitados, los servicios del sistema se ejecutarán en el tipo de nodo principal, que se extiende entre zonas. A continuación, puede quitar los nodos deshabilitados del clúster. Después de quitar los nodos, puede quitar los recursos de IP original, de equilibrador de carga y de conjunto de escalado de máquinas virtuales.
foreach($name in $nodeNames){ # Remove the node from the cluster Remove-ServiceFabricNodeState -NodeName $name -TimeoutSec 300 -Force Write-Host "Removed node state for node $name" } $scaleSetName="nt0" Remove-AzureRmVmss -ResourceGroupName $groupname -VMScaleSetName $scaleSetName -Force $lbname="LB-cluster-nt0" $oldPublicIpName="LBIP-cluster-0" $newPublicIpName="LBIP-cluster-1" Remove-AzureRmLoadBalancer -Name $lbname -ResourceGroupName $groupname -Force Remove-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname -ForceA continuación, quite las referencias a estos recursos de la plantilla de Resource Manager que se implementó.
Para finalizar, actualice el nombre DNS y la dirección IP pública.
$oldprimaryPublicIP = Get-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname
$primaryDNSName = $oldprimaryPublicIP.DnsSettings.DomainNameLabel
$primaryDNSFqdn = $oldprimaryPublicIP.DnsSettings.Fqdn
Remove-AzureRmLoadBalancer -Name $lbname -ResourceGroupName $groupname -Force
Remove-AzureRmPublicIpAddress -Name $oldPublicIpName -ResourceGroupName $groupname -Force
$PublicIP = Get-AzureRmPublicIpAddress -Name $newPublicIpName -ResourceGroupName $groupname
$PublicIP.DnsSettings.DomainNameLabel = $primaryDNSName
$PublicIP.DnsSettings.Fqdn = $primaryDNSFqdn
Set-AzureRmPublicIpAddress -PublicIpAddress $PublicIP
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de