Replicación de máquinas virtuales de Azure que ejecutan Espacios de almacenamiento directo en otra región
En este artículo se describe cómo habilitar la recuperación ante desastres de VM de Azure que ejecutan Espacios de almacenamiento directo.
Nota:
Solo se admiten los puntos de recuperación coherentes frente a bloqueos para los clústeres de Espacios de almacenamiento directo.
Espacios de almacenamiento directo (S2D) es almacenamiento definido por software, que proporciona una manera de crear clústeres invitados en Azure. Un clúster invitado en Microsoft Azure es un clúster de conmutación por error formado por máquinas virtuales IaaS. Permite que las cargas de trabajo de VM hospedadas se conmuten por error a través de clústeres invitados para lograr SLA de mayor disponibilidad para las aplicaciones, en comparación con lo que puede proporcionar una sola VM de Azure. Resulta útil en escenarios donde la máquina virtual hospeda una aplicación crítica, como un servidor de archivo de escalabilidad horizontal o SQL.
Recuperación ante desastres con espacios de almacenamiento directo
En un escenario típico, puede tener el clúster de invitado de máquinas virtuales en Azure para lograr mayor resistencia de la aplicación, como servidor de archivos de escalabilidad horizontal. Si bien esto puede proporcionar mayor disponibilidad para las aplicaciones, le gustaría proteger estas aplicaciones mediante Site Recovery en caso de errores a nivel regional. Site Recovery replica los datos de una región a otra región de Azure, y trae el clúster en la región de recuperación ante desastres en caso de conmutación por error.
En el diagrama siguiente se muestra un clúster de conmutación por error de máquina virtual de Azure de dos nodos mediante Espacios de almacenamiento directo.

- Dos máquinas virtuales de Azure en un clúster de conmutación por error de Windows, y cada máquina virtual tienen dos o más discos de datos.
- S2D sincroniza los datos del disco de datos y presenta el almacenamiento sincronizado como grupo de almacenamiento.
- El grupo de almacenamiento se presenta como volumen compartido de clúster (CSV) al clúster de conmutación por error.
- El clúster de conmutación por error usa el CSV para las unidades de datos.
Consideraciones acerca de la recuperación ante desastres
- Cuando está configurando el testigo de la nube para el clúster, mantenga el testigo en la región de recuperación ante desastres.
- Si va a conmutar por error las máquinas virtuales a la subred en una región de recuperación ante desastres que es diferente de la región de origen, la dirección IP del clúster debe cambiarse después de la conmutación por error. Para cambiar la dirección IP del clúster, debe usar el script del plan de recuperación de Site Recovery.
Habilitación de Site Recovery para el clúster de S2D:
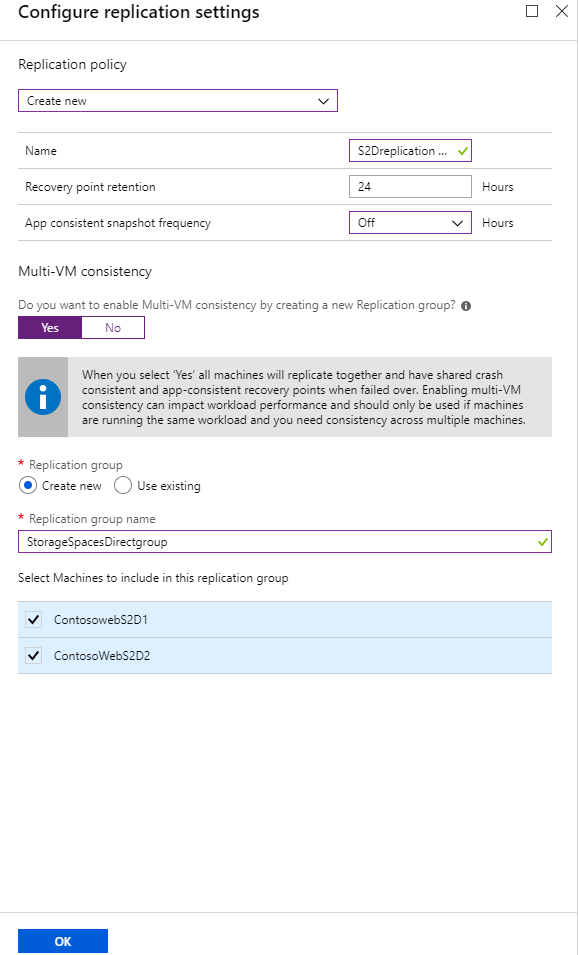
Dentro del almacén de los servicios de recuperación, seleccione + replicar
Seleccione todos los nodos del clúster y hágalos que sean parte de un grupo de coherencia de varias VM.
Seleccione la directiva de replicación con la coherencia de la aplicación desactivada* (solo está disponible la compatibilidad con coherencia frente a bloqueos).
Habilite la replicación.
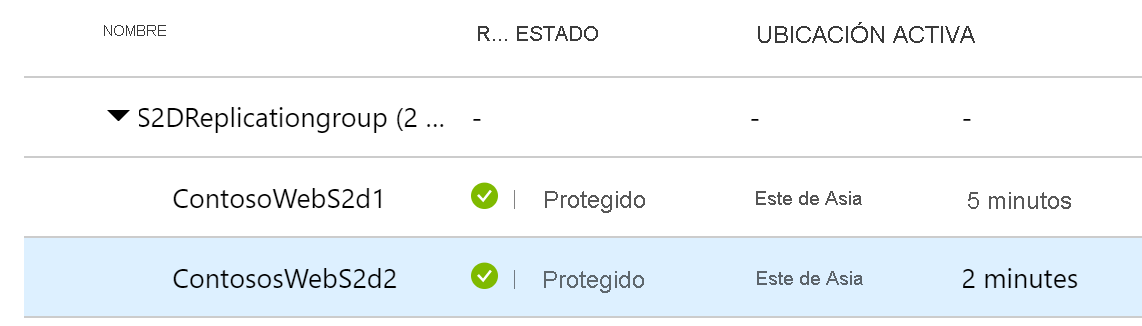
Vaya a los elementos replicados y podrá ver el estado de ambas máquinas virtuales.
Ambas máquinas virtuales están protegidas y también se muestran como parte del grupo de coherencia de varias VM.
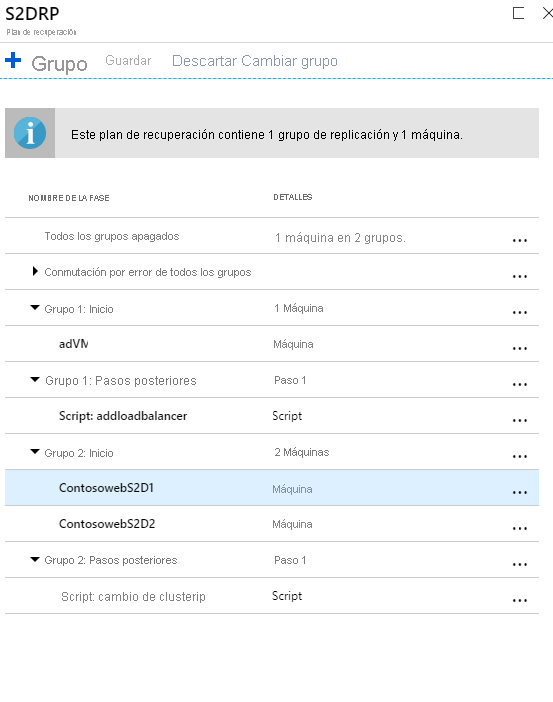
Creación de un plan de recuperación
Un plan de recuperación admite la secuenciación de distintas capas en una aplicación de varios niveles durante una conmutación por error. La secuenciación ayuda a mantener la coherencia de la aplicación. Cuando cree un plan de recuperación para una aplicación web de varios niveles, complete los pasos descritos en Creación de un plan de recuperación mediante Site Recovery.
Incorporación de máquinas virtuales a grupos de conmutación por error
- Cree un plan de recuperación agregando las máquinas virtuales.
- Seleccione Personalizar para agrupar las máquinas virtuales. De forma predeterminada, todas las máquinas virtuales forman parte de
Group 1.
Incorporación de scripts al plan de recuperación
Para que las aplicaciones funciones correctamente, es posible que tenga que realizar algunas operaciones en las máquinas virtuales de Azure después de la conmutación por error o durante una conmutación por error de prueba. Algunas de las operaciones posteriores a la conmutación por error se pueden automatizar. Por ejemplo, aquí se adjunta un equilibrador de carga y se cambia la dirección IP de clúster.
Conmutación por error de las máquinas virtuales
Los dos nodos de las máquinas virtuales se deben conmutar por error mediante el plan de recuperación de Site Recovery.
Ejecución de una conmutación por error de prueba
- En Azure Portal, seleccione el almacén de Recovery Services.
- Seleccione el plan de recuperación que creó.
- Seleccione Conmutación por error de prueba.
- Para iniciar el proceso de conmutación por error de prueba, seleccione el punto de recuperación y la red virtual de Azure.
- Cuando el entorno secundario esté activo, realice las validaciones.
- Cuando se completen las validaciones, seleccione Limpiar conmutación por error de prueba para limpiar el entorno de conmutación por error.
Para más información, consulte Conmutación por error de prueba a Azure en Site Recovery.
Ejecución de la conmutación por error
- En Azure Portal, seleccione el almacén de Recovery Services.
- Seleccione el plan de recuperación que creó para las aplicaciones SAP.
- Seleccione Failover (Conmutación por error).
- Para iniciar el proceso de conmutación por error, seleccione el punto de recuperación.
Para más información, consulte Conmutación por error en Site Recovery.
Pasos siguientes
- Más información sobre la ejecución de conmutaciones por recuperación.