Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, se proporcionan recomendaciones para trabajar con directorios que contienen un gran número de archivos. Normalmente, se recomienda reducir el número de archivos de un único directorio al distribuir los archivos en varios directorios. Sin embargo, hay situaciones en las que no se pueden evitar directorios grandes. Tenga en cuenta las siguientes sugerencias al trabajar con directorios grandes en recursos compartidos de archivos de Azure montados en clientes Linux.
Se aplica a
| Modelo de administración | Modelo de facturación | Nivel multimedia | Redundancia | Pequeñas y Medianas Empresas (PYME) | NFS |
|---|---|---|---|---|---|
| Microsoft.Storage | Aprovisionado v2 | HDD (estándar) | Local (LRS) |
|
|
| Microsoft.Storage | Aprovisionado v2 | HDD (estándar) | Zona (ZRS) |
|
|
| Microsoft.Storage | Aprovisionado v2 | HDD (estándar) | Geo (GRS) |
|
|
| Microsoft.Storage | Aprovisionado v2 | HDD (estándar) | GeoZone (GZRS) |
|
|
| Microsoft.Storage | Aprovisionado v1 | SSD (Premium) | Local (LRS) |
|
|
| Microsoft.Storage | Aprovisionado v1 | SSD (Premium) | Zona (ZRS) |
|
|
| Microsoft.Storage | Pago por uso | HDD (estándar) | Local (LRS) |
|
|
| Microsoft.Storage | Pago por uso | HDD (estándar) | Zona (ZRS) |
|
|
| Microsoft.Storage | Pago por uso | HDD (estándar) | Geo (GRS) |
|
|
| Microsoft.Storage | Pago por uso | HDD (estándar) | GeoZone (GZRS) |
|
|
Aumento del número de cubos de hash
La cantidad total de RAM presente en el sistema que realiza la enumeración influye en el trabajo interno de protocolos de sistemas de archivos como NFS y SMB. Incluso si los usuarios no experimentan un uso elevado de memoria, la cantidad de memoria disponible influye en el número de cubos de hash de inode que tiene el sistema, lo que afecta o mejora el rendimiento de la enumeración para directorios grandes. Puede modificar el número de cubos de hash de inode que tiene el sistema para reducir las colisiones de hash que pueden producirse durante cargas de trabajo de enumeración de gran tamaño.
Para aumentar el número de cubos hash de inode, modifique los valores de configuración de arranque:
Con un editor de texto, edite el archivo
/etc/default/grub.sudo vim /etc/default/grubAgregue al archivo
/etc/default/grubel texto siguiente. Este comando establece 128 MB como tamaño de tabla hash de inode, lo que aumenta el consumo de memoria del sistema en un máximo de 128 MB.GRUB_CMDLINE_LINUX="ihash_entries=16777216"Si
GRUB_CMDLINE_LINUXya existe, agregueihash_entries=16777216separado por un espacio, de la siguiente manera:GRUB_CMDLINE_LINUX="<previous commands> ihash_entries=16777216"Para aplicar los cambios, ejecute este comando:
sudo update-grub2Reinicie el sistema:
sudo rebootPara comprobar que los cambios son efectivos después del reinicio, compruebe los comandos de kernel cmdline:
cat /proc/cmdlineSi
ihash_entriesestá visible, el sistema ha aplicado la configuración y el rendimiento de la enumeración debe mejorar exponencialmente.También puede comprobar la salida de dmesg para ver si se aplicaron los comandos cmdline de kernel:
dmesg | grep "Inode-cache hash table" Inode-cache hash table entries: 16777216 (order: 15, 134217728 bytes, linear)
Opciones de montaje recomendadas
Las siguientes opciones de montaje son específicas de la enumeración y pueden reducir la latencia al trabajar con directorios grandes.
actimeo
La actimeo opción de montaje especifica el tiempo (en segundos) que el cliente almacena en caché los atributos de un archivo o directorio antes de solicitar información de atributo desde un servidor. Durante este período, los cambios que se producen en el servidor permanecen sin detectar hasta que el cliente vuelva a comprobar el servidor. Para los clientes SMB, el tiempo de espera de caché de atributos predeterminado se establece en 1 segundo.
En los clientes NFS, al especificar actimeo, se establecen los valores de acregmin, acregmax, acdirmin y acdirmax al mismo valor. Si no se especifica actimeo, el cliente usa los valores predeterminados para cada una de estas opciones.
Se recomienda establecer actimeo entre 30 y 60 segundos al trabajar con directorios grandes. Establecer un valor en este intervalo hace que los atributos permanezcan válidos durante un período de tiempo mayor en la caché de atributos del cliente, lo que permite que las operaciones obtengan atributos de archivo de la caché en lugar de capturarlos a través de la conexión. Esta configuración puede reducir la latencia en situaciones en las que expiran los atributos almacenados en caché mientras la operación sigue en ejecución.
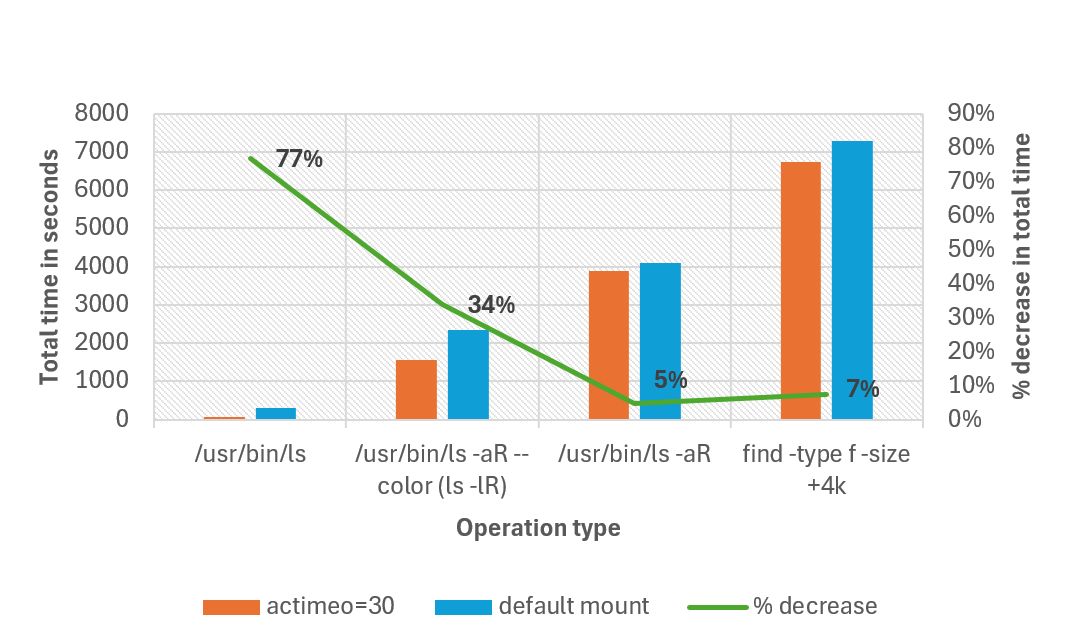
En el gráfico siguiente se compara el tiempo total necesario para finalizar diferentes operaciones con montaje predeterminado frente a establecer un valor actimeo de 30 para una carga de trabajo que tenga 1 millón de archivos en un único directorio. En nuestras pruebas, el tiempo total de finalización se redujo hasta un 77 % en algunas operaciones. Todas las operaciones se realizaron con ls sin alias.
NFS nconnect
NFS nconnect es una opción de montaje del lado cliente para recursos compartidos de archivos NFS que permite usar varias conexiones TCP entre el cliente y el recurso compartido de archivos NFS. Se recomienda la configuración óptima de nconnect=4 para reducir la latencia y mejorar el rendimiento. La característica nconnect puede ser especialmente útil para cargas de trabajo que usan E/S asincrónica o sincrónica desde varios subprocesos.
Más información.
Comandos y operaciones
La forma en que se especifican los comandos y operaciones también puede afectar al rendimiento. Un buen ejemplo es enumerar todos los archivos de un directorio grande mediante el comando ls.
Nota:
Algunas operaciones, como ls, find, y du recursivas necesitan nombres de archivo y atributos de archivo, por lo que combinan enumeraciones de directorio (para obtener las entradas) con estadísticas de cada entrada (para obtener los atributos). Se recomienda usar un valor mayor para actimeo en puntos de montaje en los que es probable que ejecute estos comandos.
Uso de ls sin alias
En algunas distribuciones de Linux, el shell establece automáticamente las opciones predeterminadas del comando ls, como ls --color=auto. Esto cambia cómo funciona ls mediante la conexión y agrega más operaciones a la ejecución de ls. Para evitar la degradación del rendimiento, se recomienda usar ls sin alias. Puede hacer una de tres cosas:
Como solución temporal que solo afecta a la sesión actual, puede quitar el alias mediante el comando
unalias ls.Para un cambio permanente, puede editar el alias de
lsen el archivobashrc/bash_aliasesdel usuario. En Ubuntu, edite~/.bashrcpara quitar el alias dels.En lugar de llamar a
ls, puede llamar directamente al binariols, por ejemplo,/usr/bin/ls. Esto le permite usarlssin ninguna opción que pueda estar en el alias. Para encontrar la ubicación del binario, puede ejecutar el comandowhich ls.
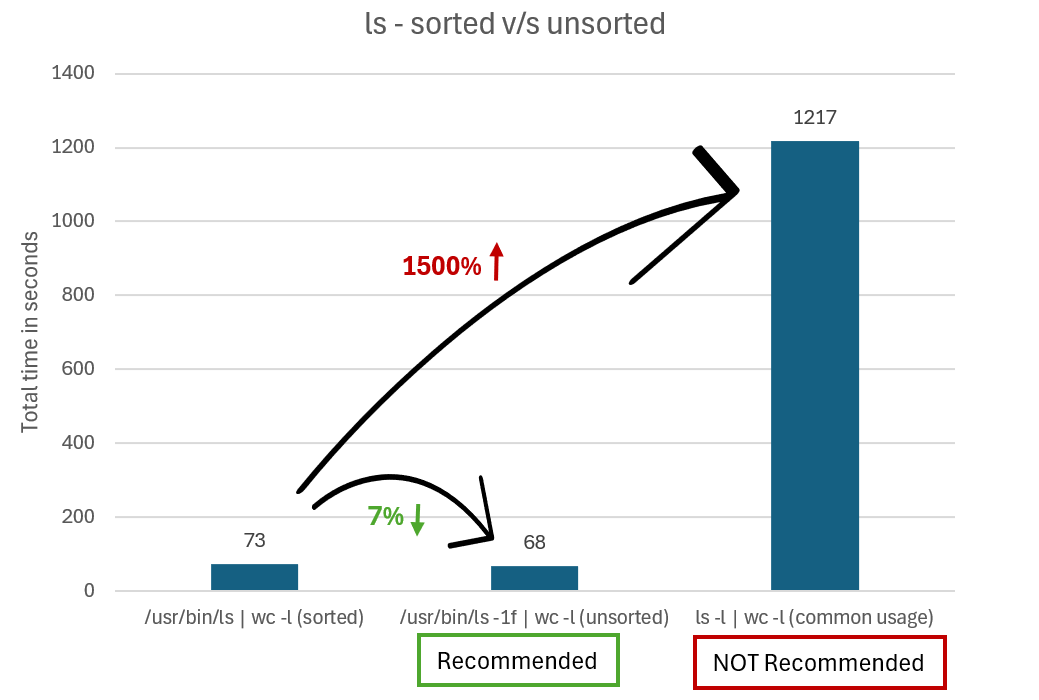
Impedir que ls ordene su salida
Al usar ls con otros comandos, puede mejorar el rendimiento si evita que ls ordene su salida en situaciones en las que no le importa el orden en que ls devuelve los archivos. La ordenación de la salida agrega una importante sobrecarga.
En lugar de ejecutar ls -l | wc -l para obtener el número total de archivos, puede usar las opciones -f o -U con ls para evitar que se ordene la salida. La diferencia es que -f también muestra archivos ocultos y -U no.
Por ejemplo, si llamara directamente al binario ls en Ubuntu, ejecutaría /usr/bin/ls -1f | wc -l o /usr/bin/ls -1U | wc -l.
En el gráfico siguiente se compara el tiempo que se tarda en generar los resultados con ls sin alias y sin ordenar frente a ls ordenado.
Operaciones de copia de seguridad y copia de archivos
Al copiar datos desde un recurso compartido de archivos o realizar una copia de seguridad de recursos compartidos de archivos en otra ubicación, se recomienda usar una instantánea de recurso compartido como origen en lugar del recurso compartido de archivos activo con E/S activa para mejorar el rendimiento. Las aplicaciones de copia de seguridad deben ejecutar comandos en la instantánea directamente. Para obtener más información, consulte Uso de instantáneas de recurso compartido con Azure Files.
Recomendaciones de nivel de aplicación
Al desarrollar aplicaciones que usan directorios grandes, siga estas recomendaciones.
Omita los atributos de archivo. Si la aplicación solo necesita el nombre de archivo y no los atributos de archivo, como el tipo de archivo o la hora de última modificación, puede usar varias llamadas a llamadas del sistema, como
getdents64con un buen tamaño de búfer para obtener las entradas en el directorio especificado sin el tipo de archivo, lo que hace que la operación sea más rápida evitando operaciones adicionales que no son necesarias.Intercale llamadas de estadísticas. Si la aplicación necesita atributos y el nombre de archivo, se recomienda intercalar las llamadas de estadísticas junto con
getdents64en lugar de obtener todas las entradas hasta el final del archivo congetdents64y, a continuación, realizar una operación statx en todas las entradas devueltas. Al intercalar las llamadas de estadísticas, se indica al cliente que solicite tanto el archivo como sus atributos a la vez, lo que reduce el número de llamadas al servidor. Cuando se combina con un valor deactimeoalto, las llamadas de estadísticas de intercalación pueden mejorar significativamente el rendimiento. Por ejemplo, en lugar de[ getdents64, getdents64, ... , getdents64, statx (entry1), ... , statx(n) ], coloque las llamadas statx después de cadagetdents64de esta manera:[ getdents64, (statx, statx, ... , statx), getdents64, (statx, statx, ... , statx), ... ].Aumente la capacidad de E/S. Si es posible, se recomienda configurar
nconnecten un valor distinto de cero (mayor que 1) y distribuir la operación entre varios subprocesos o usar E/S asincrónica. Esto permite que las operaciones que pueden ser asincrónicas se beneficien de varias conexiones simultáneas al recurso compartido de archivos.Fuerce el uso de la caché. Si la aplicación consulta los atributos de archivo de un recurso compartido de archivos que solo ha montado un cliente, use la llamada del sistema statx con la marca
AT_STATX_DONT_SYNC. Esta marca garantiza que los atributos almacenados en caché se recuperan de la caché sin sincronizarse con el servidor, lo que evita viajes adicionales de ida y vuelta de red para obtener los datos más recientes.