Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
✔️ Se aplica a recursos compartidos de archivos clásicos SMB y NFS creados con el proveedor de recursos Microsoft.Storage
✔️ Se aplica a: Recursos compartidos de archivos creados con el proveedor de recursos Microsoft.FileShares (versión preliminar)
Azure Files puede satisfacer los requisitos de rendimiento de la mayoría de las aplicaciones y casos de uso. En este artículo se explican los distintos factores que pueden afectar al rendimiento del recurso compartido de archivos y cómo optimizar el rendimiento de los recursos compartidos de archivos de Azure para la carga de trabajo.
Glosario de rendimiento de almacenamiento
Antes de leer este artículo, resulta útil comprender algunos términos clave relacionados con el rendimiento del almacenamiento:
Operaciones de E/S por segundo (IOPS)
IOPS u operaciones de entrada/salida por segundo, mide el número de operaciones del sistema de archivos por segundo. En la documentación de Azure Files, el término "E/S" es un sinónimo de los términos "operación" y "transacción".
Tamaño de E/S
El tamaño de E/S, a veces denominado tamaño de bloque, es el tamaño de la solicitud que una aplicación usa para realizar una única operación de entrada/salida (E/S) en el almacenamiento. Dependiendo de la aplicación, el tamaño de E/S puede oscilar entre tamaños pequeños, como 4 KiB y tamaños mayores. El tamaño de E/S desempeña un papel importante en el rendimiento factible.
Rendimiento
El rendimiento mide el número de bits leídos o escritos en el almacenamiento por segundo y se mide en mebibytes por segundo (MiB/s). Para calcular el rendimiento, multiplique las IOPS por el tamaño de E/S. Por ejemplo, 10 000 IOPS _ 1 MiB de tamaño de E/S = 10 GiB/s, mientras que 10 000 IOPS _ 4 KiB de tamaño de E/S = 38 MiB/s.
Latencia
La latencia es un sinónimo de retraso y se mide en milisegundos (ms). Hay dos tipos de latencia: de un extremo a otro y del servicio. Para obtener más información, vea latencia.
Profundidad de la cola
La profundidad de la cola es el número de solicitudes de E/S pendientes que un recurso de almacenamiento puede controlar en cualquier momento. Para obtener más información, vea Profundidad de la cola.
Elección de un nivel multimedia basado en patrones de uso
Azure Files proporciona dos niveles de medios de almacenamiento que permiten equilibrar el rendimiento y el precio: SSD y HDD. Elige el nivel multimedia del recurso compartido de archivos en el nivel de cuenta de almacenamiento y, una vez creada una cuenta de almacenamiento en un nivel multimedia determinado, no se puede mover a la otra sin migrar manualmente a un nuevo recurso compartido de archivos.
Al elegir entre recursos compartidos de archivos SSD y HDD, es importante comprender los requisitos del patrón de uso esperado que planea ejecutar en Azure Files. Si necesita grandes cantidades de IOPS, velocidades de transferencia de datos rápidas o baja latencia, debe elegir recursos compartidos de archivos SSD.
En la tabla siguiente se resumen los objetivos de rendimiento esperados entre los recursos compartidos de archivos SSD y HDD. Para obtener más información, vea Objetivos de escalabilidad y rendimiento de Azure Files.
| Requisitos del patrón de uso | SSD | HDD |
|---|---|---|
| Latencia de escritura (milisegundos de un solo dígito) | Sí | Sí |
| Latencia de lectura (milisegundos de un solo dígito) | Sí | No |
Los recursos compartidos de archivos SSD ofrecen un modelo de aprovisionamiento que garantiza el siguiente perfil de rendimiento en función del tamaño del recurso compartido. Para obtener más información, consulte el modelo v1 aprovisionado.
Mejores prácticas de rendimiento
Tanto si va a evaluar los requisitos de rendimiento para una carga de trabajo nueva como existente, comprender los patrones de uso le ayuda a lograr un rendimiento predecible.
Sensibilidad de latencia: Las cargas de trabajo que son sensibles a la latencia de lectura y tienen una alta visibilidad para los usuarios finales son más adecuadas para los recursos compartidos de archivos SSD, lo que puede proporcionar latencia de un solo milisegundos para las operaciones de lectura y escritura (< 2 ms para un tamaño de E/S pequeño).
Requisitos de IOPS y rendimiento: Los recursos compartidos de archivos SSD admiten mayores límites de IOPS y rendimiento que los recursos compartidos de archivos HDD. Consulte Destinos de escalado de recursos compartidos de archivos para más información.
Duración y frecuencia de la carga de trabajo: Las cargas de trabajo cortas (minutos) y poco frecuentes (por hora) son menos probables para lograr los límites de rendimiento superiores de los recursos compartidos de archivos HDD en comparación con las cargas de trabajo que se producen con frecuencia. En los recursos compartidos de archivos SSD, la duración de la carga de trabajo resulta útil al determinar el perfil de rendimiento correcto que se va a usar en función del almacenamiento aprovisionado, las IOPS y el rendimiento. Un error común consiste en ejecutar pruebas de rendimiento solo unos minutos, lo que a menudo es engañoso. Para obtener una vista realista del rendimiento, asegúrese de probar con una frecuencia y una duración suficientemente altas.
Paralelización de cargas de trabajo: En el caso de las cargas de trabajo que realizan operaciones en paralelo, como a través de varios subprocesos, procesos o instancias de aplicación en el mismo cliente, los recursos compartidos de archivos SSD proporcionan una ventaja clara sobre los recursos compartidos de archivos HDD: SMB multicanal. Para más información, consulte Mejora del rendimiento del recurso compartido de archivos de SMB de Azure.
Distribución de operaciones de API: las cargas de trabajo intensivas de metadatos, como las cargas de trabajo que realizan operaciones de lectura en un gran número de archivos, son una mejor opción para los recursos compartidos de archivos SSD. Consulte Carga de trabajo pesada del espacio de nombres o los metadatos.
Ubicación zonal: use la ubicación zonal para seleccionar la zona de disponibilidad específica en la que reside la cuenta de almacenamiento. Esto le permite colocar las máquinas virtuales en la misma zona de disponibilidad que el almacenamiento, lo que puede reducir la latencia hasta el 30 %. Esta característica solo está disponible actualmente para las cuentas de almacenamiento SSD con almacenamiento con redundancia local (LRS) en regiones admitidas.
Latencia
Al pensar en la latencia, es importante comprender primero cómo se determina esta con Azure Files. Las medidas más comunes son la latencia asociada a las métricas de latencia de un extremo a otro y latencia del servicio. El uso de estas métricas de transacción puede ayudar a identificar problemas de latencia o de redes del lado cliente al determinar el tiempo que pasa el tráfico de la aplicación en tránsito hacia el cliente y desde este.
La latencia de un extremo a otro (SuccessE2ELatency) es el tiempo total que tarda una transacción en realizar un recorrido de ida y vuelta completo desde el cliente, por la red, al servicio Azure Files y de vuelta al cliente.
La latencia del servicio (SuccessServerLatency) es el tiempo que tarda una transacción en realizar un recorrido de ida y vuelta solo dentro de Azure Files. Esto no incluye ninguna latencia de red o cliente.
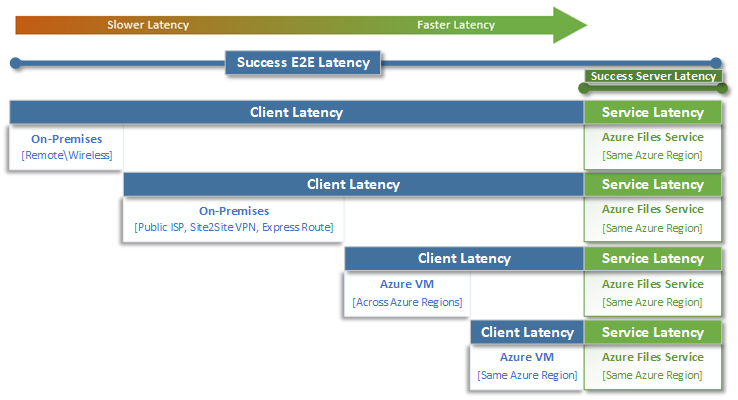
La diferencia entre los valores de SuccessE2ELatency y SuccessServerLatency es la latencia que probablemente provocan la red y el cliente.
Es habitual confundir la latencia del cliente con la latencia del servicio (en este caso, el rendimiento de Azure Files). Por ejemplo, si la latencia del servicio notifica baja latencia y la de un extremo a otro notifica una latencia muy alta para las solicitudes, eso sugiere que todo el tiempo se invierte en el tránsito hacia el cliente y desde este, y no en el servicio Azure Files.
Además, como se muestra en el diagrama, lo más alejado del servicio, cuanto más lenta sea la experiencia de latencia, más difícil será lograr límites de escala de rendimiento con cualquier servicio en la nube. Esto sucede especialmente al acceder a Azure Files desde el entorno local. Aunque las opciones como ExpressRoute son ideales para el entorno local, siguen sin coincidir con el rendimiento de una aplicación (proceso y almacenamiento) que se ejecuta exclusivamente en la misma región de Azure.
Sugerencia
El uso de una máquina virtual en Azure para probar el rendimiento entre el entorno local y Azure es una manera eficaz y práctica de establecer como base las capacidades de red de la conexión a Azure. Los circuitos ExpressRoute o las puertas de enlace de VPN de tamaño insuficiente o con un enrutamiento incorrecto pueden ralentizar considerablemente las cargas de trabajo que se ejecutan en Azure Files.
Profundidad de la cola
La profundidad de la cola es el número de solicitudes de E/S pendientes que un recurso de almacenamiento puede atender. A medida que los discos que usan los sistemas de almacenamiento han evolucionado de los ejes HDD (IDE, SATA, SAS) a los dispositivos de estado sólido (SSD, NVMe), también han evolucionado para admitir una mayor profundidad de cola. Un ejemplo de profundidad de cola baja consiste en una carga de trabajo que consta de un único cliente que interactúa en serie con un único archivo dentro de un conjunto de datos grande. Por el contrario, una carga de trabajo que admite paralelismo con varios subprocesos y varios archivos puede lograr fácilmente una profundidad de cola alta. Dado que Azure Files es un servicio de archivos distribuido que abarca miles de nodos de clúster de Azure y está diseñado para ejecutar cargas de trabajo a gran escala, se recomienda compilar y probar cargas de trabajo con una profundidad de cola alta.
La profundidad de cola alta se puede alcanzar de varias maneras diferentes en combinación con clientes, archivos y subprocesos. Para determinar la profundidad de cola de la carga de trabajo, multiplique el número de clientes por el número de archivos y por el número de subprocesos (clientes _ archivos _ subprocesos = profundidad de cola).
En la tabla siguiente se muestran las distintas combinaciones que puede usar para lograr una mayor profundidad de cola. Aunque puede superar la profundidad de cola óptima de 64, esta opción no se recomienda. Si lo hace, no observará más mejoras en el rendimiento y corre el riesgo de aumentar la latencia debido a la saturación de TCP.
| Clientes | Archivos | Subprocesos | Profundidad de la cola |
|---|---|---|---|
| 1 | 1 | 1 | 1 |
| 1 | 1 | 2 | 2 |
| 1 | 2 | 2 | 4 |
| 2 | 2 | 2 | 8 |
| 2 | 2 | 4 | 16 |
| 2 | 4 | 4 | 32 |
| 1 | 8 | 8 | 64 |
| 4 | 4 | 2 | 64 |
Sugerencia
Para lograr límites de rendimiento superiores, asegúrese de que la carga de trabajo o la prueba de punto de referencia sea de varios subprocesos con varios archivos.
Aplicaciones de un solo subproceso frente a varios subprocesos
Azure Files es más adecuado para aplicaciones de varios subprocesos. La manera más fácil de comprender el impacto en el rendimiento que tiene la opción de varios subprocesos en una carga de trabajo es recorrer el escenario con E/S. En el ejemplo siguiente, tenemos una carga de trabajo que necesita copiar 10 000 archivos pequeños lo antes posible hacia un recurso compartido de archivos de Azure o desde este.
En esta tabla se desglosa el tiempo necesario (en milisegundos) para crear un único archivo de 16 KiB en un recurso compartido de archivos de Azure, basado en una aplicación de un solo subproceso que escribe en tamaños de bloque de 4 KiB.
| Operación de E/S | Creación | Escritura de 4 KiB | Escritura de 4 KiB | Escritura de 4 KiB | Escritura de 4 KiB | Cerrar | Total |
|---|---|---|---|---|---|---|---|
| Subproceso 1 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
En este ejemplo, tardaría aproximadamente 14 ms en crear un único archivo de 16 KiB a partir de las seis operaciones. Si una aplicación de un solo subproceso quiere mover 10 000 archivos a un recurso compartido de archivos de Azure, esto supondría 140 000 ms (14 ms * 10 000) o 140 segundos, porque cada archivo se mueve secuencialmente de uno en uno. Tenga en cuenta que el tiempo de servicio de cada solicitud lo determina principalmente la proximidad entre el proceso y el almacenamiento, tal como se describe en la sección anterior.
Al usar ocho subprocesos en lugar de uno, la carga de trabajo anterior se puede reducir de 140 000 ms (140 segundos) hasta 17 500 ms (17,5 segundos). Tal como se muestra en la tabla siguiente, cuando se mueven ocho archivos en paralelo en lugar de hacerlo de uno en uno, puede mover la misma cantidad de datos empleando un 87,5 % menos de tiempo.
| Operación de E/S | Creación | Escritura de 4 KiB | Escritura de 4 KiB | Escritura de 4 KiB | Escritura de 4 KiB | Cerrar | Total |
|---|---|---|---|---|---|---|---|
| Subproceso 1 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Subproceso 2 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Subproceso 3 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Subproceso 4 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Subproceso 5 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Subproceso 6 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Subproceso 7 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |
| Subproceso 8 | 3 ms | 2 ms | 2 ms | 2 ms | 2 ms | 3 ms | 14 ms |