Tutorial: Captura de datos de Event Hubs en formato Parquet y análisis con Azure Synapse Analytics
Este tutorial muestra cómo usar el editor sin código de Stream Analytics para crear un trabajo que capture los datos de Event Hubs en Azure Data Lake Storage Gen2 en formato Parquet.
En este tutorial, aprenderá a:
- Implementar un generador de eventos que envíe eventos de ejemplo al centro de eventos
- Crear un trabajo de Stream Analytics mediante el editor sin código
- Revisar los datos de entrada y el esquema
- Configurar Azure Data Lake Storage Gen2 para definir los datos del centro de eventos que se capturarán
- Ejecución del trabajo de Stream Analytics
- Usar Azure Synapse Analytics para consultar los archivos Parquet
Requisitos previos
Antes de empezar, asegúrese de que ha completado los pasos siguientes:
- Si no tiene una suscripción a Azure, cree una cuenta gratuita.
- Implemente la aplicación generador de eventos TollApp en Azure. Establezca el parámetro "intervalo" en 1 y use un nuevo grupo de recursos para este paso.
- Cree un área de trabajo de Azure Synapse Analytics con una cuenta de Data Lake Storage Gen2.
Uso del editor sin código para crear un trabajo de Stream Analytics
Busque el grupo de recursos en el que se implementó el generador de eventos de TollApp.
Seleccione el espacio de nombres de Azure Event Hubs.
En la página Espacio de nombres de Event Hubs, seleccione Event Hubs en Entidades en el menú de la izquierda.
Seleccione la instancia
entrystream.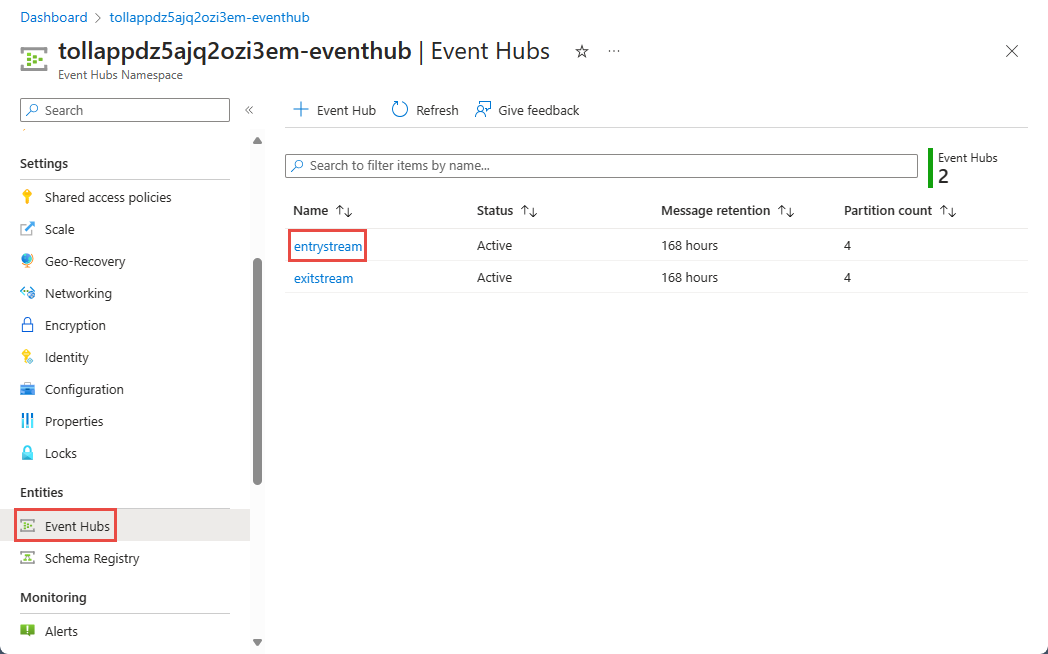
En la página Instancia de Event Hubs, seleccione Procesar datos en la sección Características del menú de la izquierda.
Seleccione Iniciar en el mosaico Capturar datos a ADLS Gen2 en formato Parquet.
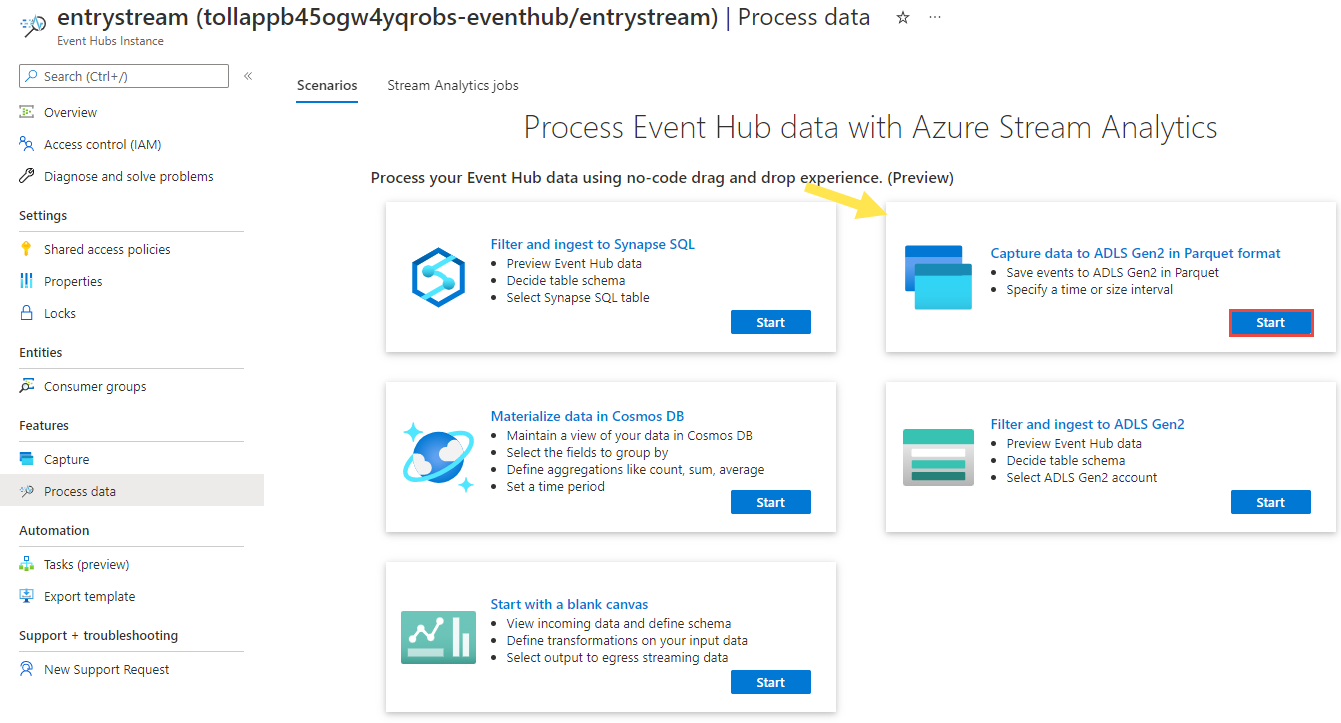
Asigne al trabajo el nombre
parquetcapturey seleccione Crear.
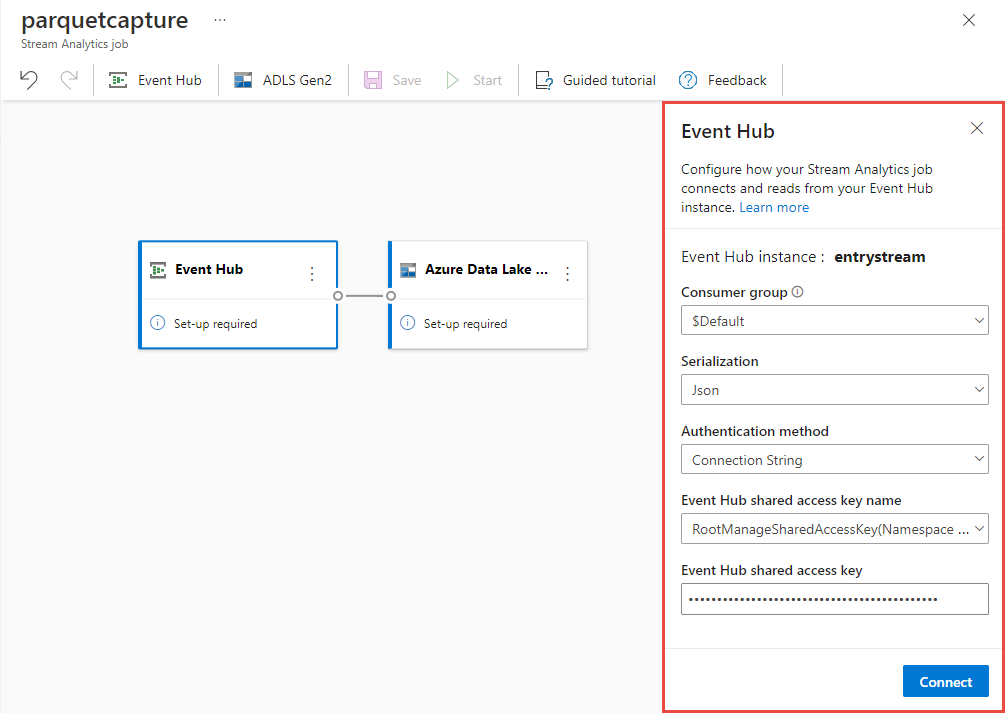
En la página de configuración del centro de eventos, confirme la siguiente configuración y, a continuación, seleccione Conectar.
Grupo de consumidores: valor predeterminado
Tipo de serialización de los datos de entrada: JSON
Modo de autenticación que el trabajo usará para conectarse al centro de eventos: Cadena de conexión.
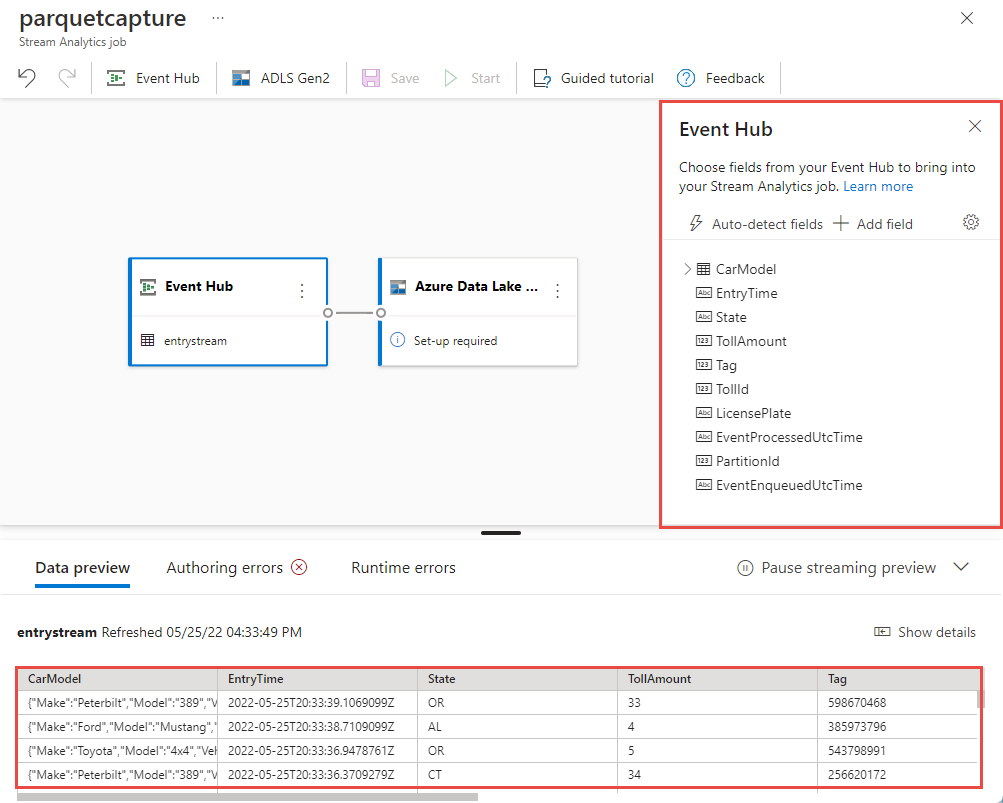
En pocos segundos, verá datos de entrada de ejemplo y el esquema. Puede elegir anular campos, cambiar su nombre o cambiar el tipo de datos.
Seleccione el mosaico de Azure Data Lake Storage Gen2 en el lienzo y especifique las configuraciones siguientes:
- Suscripción en la que se encuentra la cuenta de Azure Data Lake Gen2.
- Nombre de la cuenta de almacenamiento, que debe ser la misma cuenta de ADLS Gen2 que se usa con el área de trabajo de Azure Synapse Analytics creada en la sección Requisitos previos.
- Contenedor en el que se crearán los archivos Parquet.
- Patrón de ruta de acceso establecido en {date}/{time}.
- Patrón de fecha y hora como los valores predeterminados yyyy-mm-dd y HH.
- Seleccione Conectar.

Seleccione Guardar en la barra de herramientas superior para guardar el trabajo y, a continuación, seleccione Iniciar para ejecutar el trabajo. Una vez iniciado el trabajo, seleccione X en la esquina derecha para cerrar la página del trabajo de Stream Analytics.

A continuación, verá una lista de todos los trabajos de Stream Analytics creados con el editor sin código. Y en un plazo de dos minutos, el trabajo adoptará un estado En ejecución. Seleccione el botón Actualizar de la página para ver el estado cambiar de Creado -> Iniciando -> En ejecución.
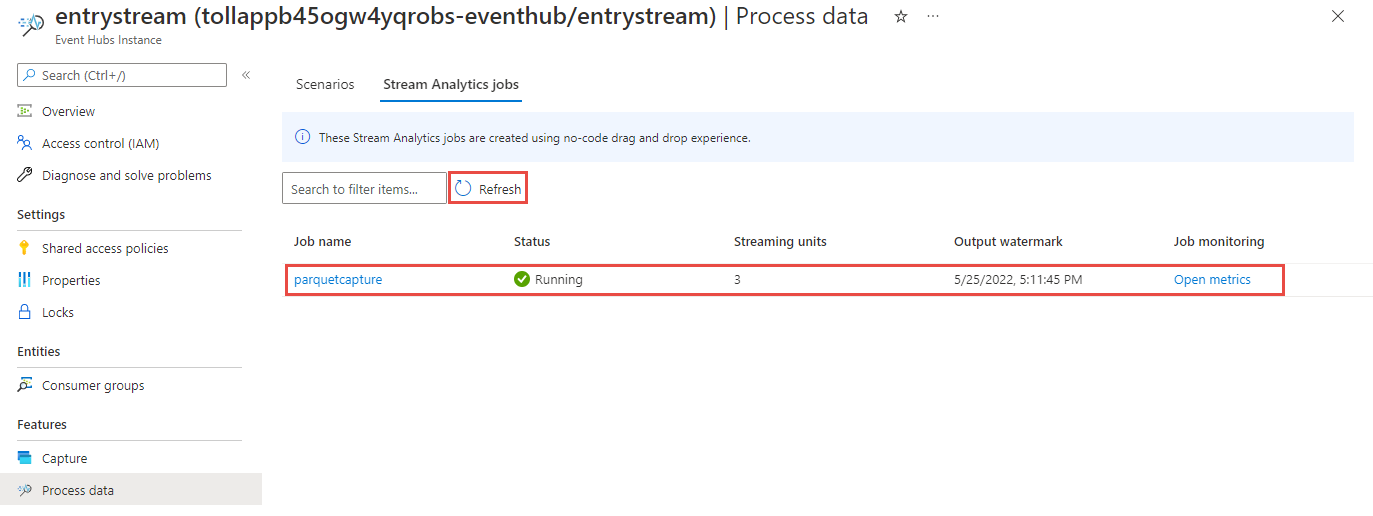








Visualización de la salida en la cuenta de Azure Data Lake Storage Gen2
Busque la cuenta de Azure Data Lake Storage Gen2 que usó en el paso anterior.
Seleccione el contenedor que usó en el paso anterior. Verá los archivos Parquet creados en función del patrón de ruta de acceso {date}/{time} usado en el paso anterior.
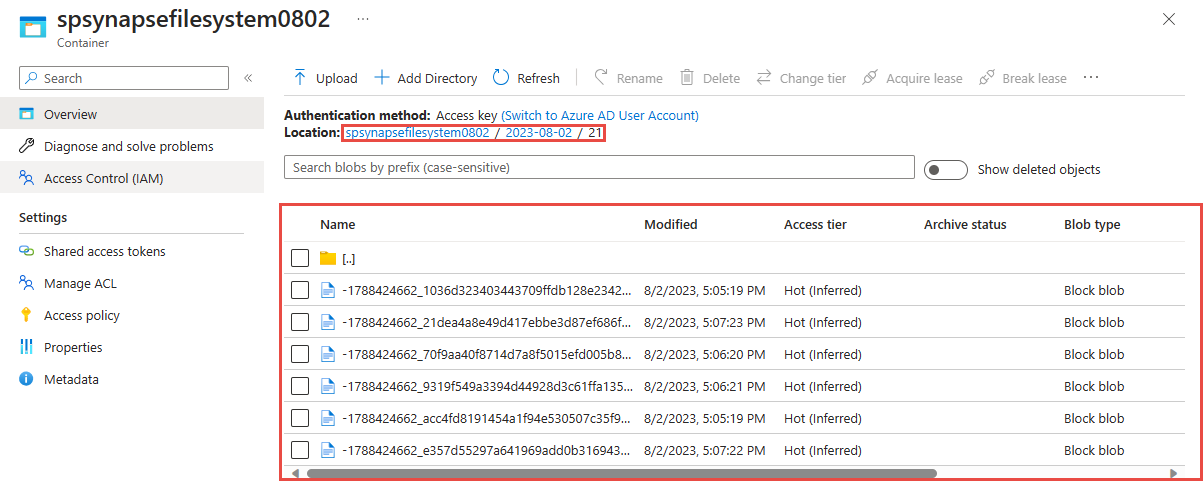
Consulta de datos capturados en formato Parquet con Azure Synapse Analytics
Consulta mediante Azure Synapse Spark
Busque el área de trabajo de Azure Synapse Analytics y abra Synapse Studio.
Cree un grupo de Apache Spark sin servidor en el área de trabajo si aún no existe ninguno.
En Synapse Studio, vaya al centro Desarrollo y cree un nuevo cuaderno.
Cree una nueva celda de código y pegue el código siguiente en ella. Reemplace container y adlsname por el nombre del contenedor y la cuenta de ADLS Gen2 que usó en el paso anterior.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()En Asociar a en la barra de herramientas, seleccione el grupo de Spark en la lista desplegable.
Seleccione Ejecutar todo para ver los resultados.


Consulta mediante SQL sin servidor de Azure Synapse
En el centro Desarrollo, cree un nuevo script de SQL.
Pegue el siguiente script y ejecútelocon el punto de conexión de SQL sin servidor integrado. Reemplace container y adlsname por el nombre del contenedor y la cuenta de ADLS Gen2 que usó en el paso anterior.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]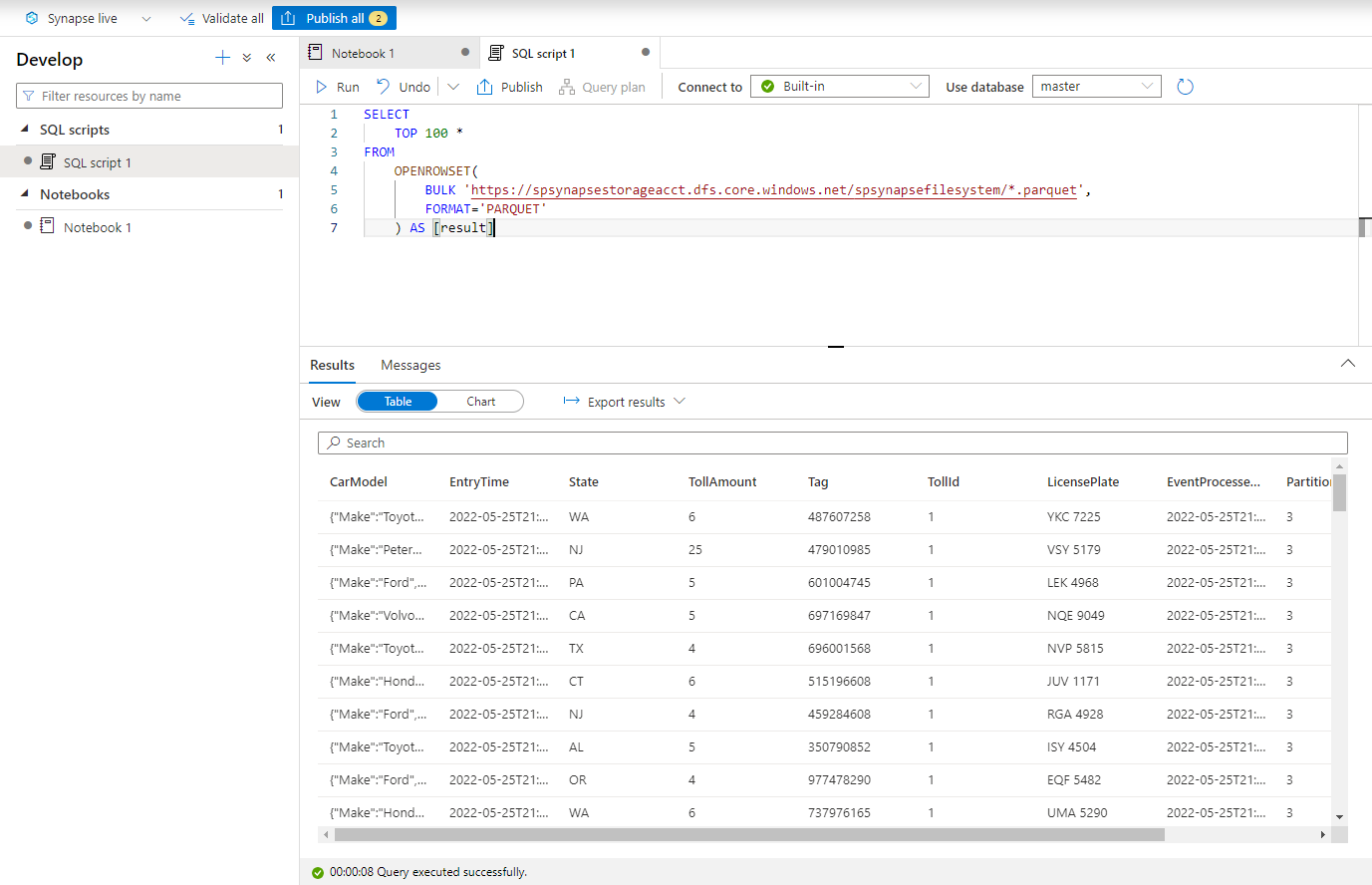

Limpieza de recursos
- Busque la instancia de Event Hubs y consulte la lista de trabajos de Stream Analytics en la sección Procesar datos. Detenga los trabajos que se estén ejecutando.
- Vaya al grupo de recursos que usó al implementar el generador de eventos de TollApp.
- Seleccione Eliminar grupo de recursos. Escriba el nombre del grupo de recursos para confirmar la eliminación.
Pasos siguientes
En este tutorial, ha aprendido a crear un trabajo de Stream Analytics con el editor sin código para capturar flujos de datos de Event Hubs en formato Parquet. Posteriormente, ha usado Azure Synapse Analytics para consultar los archivos Parquet mediante Synapse Spark y Synapse SQL.