Obtención de redundancia geográfica para trabajos de Azure Stream Analytics
Azure Stream Analytics no proporciona conmutación por error geográfica automática, pero puede lograr redundancia geográfica implementando trabajos de Stream Analytics idénticos en varias regiones de Azure. Cada trabajo se conecta a una entrada local y a orígenes de salida local. La aplicación es la responsable de enviar datos de entrada a las dos entradas regionales y de realizar la conciliación entre las dos salidas regionales. Los trabajos de Stream Analytics son dos entidades independientes.
En el diagrama siguiente se muestra una implementación de trabajo de Stream Analytics con redundancia geográfica con la entrada del centro de eventos y la salida de Azure Database.
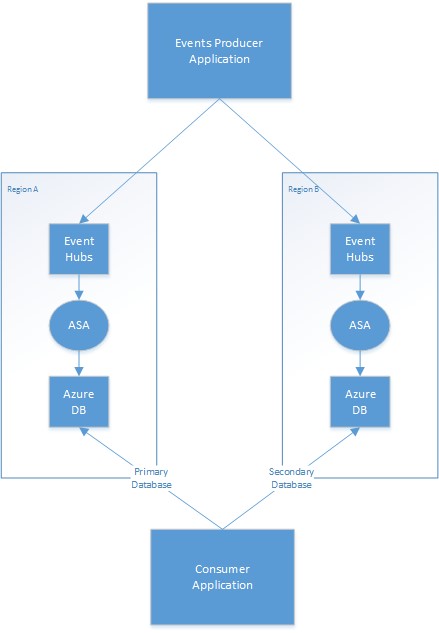
Estrategia primaria y secundaria
La aplicación necesita administrar qué base de datos de salida de la región se considera la principal y cuál se considera la secundaria. En un error en una región primaria, la aplicación cambia a la base de datos secundaria y comienza a leer las actualizaciones de esa base de datos. El mecanismo real que permite minimizar las lecturas duplicadas depende de la aplicación. Puede simplificar este proceso escribiendo información adicional en la salida. Por ejemplo, puede agregar una marca de tiempo o un identificador de secuencia a cada salida para que la omisión de filas duplicadas sea una operación trivial. Una vez que se restaure la región primaria, se pone al día con la base de datos secundaria mediante una mecánica similar.
Aunque los distintos tipos de entrada y salida permiten diferentes opciones de replicación geográfica, se recomienda usar el patrón que se describe en este artículo para lograr redundancia geográfica, ya que proporciona flexibilidad y control para los productores de eventos y los consumidores de eventos.