Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
La validación de entrada es una técnica que se usa para proteger la lógica de consulta principal frente a eventos con formato incorrecto o inesperados. La consulta se actualiza a fin de procesar y comprobar registros explícitamente para que no puedan interrumpir la lógica principal.
Para implementar la validación de entrada, se agregan dos pasos iniciales a una consulta. En primer lugar, se asegura de que el esquema enviado a la lógica de negocios principal coincida con sus expectativas. Después, se evalúan las prioridades de las excepciones y, opcionalmente, se enrutan los registros no válidos a una salida secundaria.
Una consulta con validación de entrada se estructurará de la siguiente manera:
WITH preProcessingStage AS (
SELECT
-- Rename incoming fields, used for audit and debugging
field1 AS in_field1,
field2 AS in_field2,
...
-- Try casting fields in their expected type
TRY_CAST(field1 AS bigint) as field1,
TRY_CAST(field2 AS array) as field2,
...
FROM myInput TIMESTAMP BY myTimestamp
),
triagedOK AS (
SELECT -- Only fields in their new expected type
field1,
field2,
...
FROM preProcessingStage
WHERE ( ... ) -- Clauses make sure that the core business logic expectations are satisfied
),
triagedOut AS (
SELECT -- All fields to ease diagnostic
*
FROM preProcessingStage
WHERE NOT (...) -- Same clauses as triagedOK, opposed with NOT
)
-- Core business logic
SELECT
...
INTO myOutput
FROM triagedOK
...
-- Audit output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- To a storage adapter that doesn't require strong typing, here blob/adls
FROM triagedOut
Para ver un ejemplo completo de una consulta configurada con validación de entrada, vea la sección: Ejemplo de consulta con validación de entrada.
En este artículo se muestra cómo implementar esta técnica.
Contexto
Los trabajos de Azure Stream Analytics (ASA) procesan datos procedentes de flujos. Los flujos son secuencias de datos sin procesar que se transmiten serializados (CSV, JSON, AVRO...). Para leer desde una transmisión, una aplicación deberá conocer el formato de serialización específico utilizado. En ASA, el formato de serialización de eventos debe definirse al configurar una entrada de streaming.
Una vez que se deserializan los datos, es necesario aplicar un esquema para darle significado. Por esquema nos referimos a la lista de campos del flujo y sus respectivos tipos de datos. Con ASA, no es necesario establecer el esquema de los datos entrantes en el nivel de entrada. En su lugar, ASA admite esquemas de entrada dinámicos de forma nativa. Espera que la lista de campos (columnas) y sus tipos cambie entre eventos (filas). ASA también deducirá los tipos de datos cuando no se proporciona ninguno explícitamente e intentará convertir implícitamente los tipos cuando sea necesario.
El control dinámico de esquemas es una característica eficaz, clave para el procesamiento de flujos. Los flujos de datos suelen contener datos de varios orígenes, con varios tipos de eventos, cada uno con un esquema único. Para enrutar, filtrar y procesar eventos en tales flujos, ASA tiene que ingerirlos todos independientemente de su esquema.
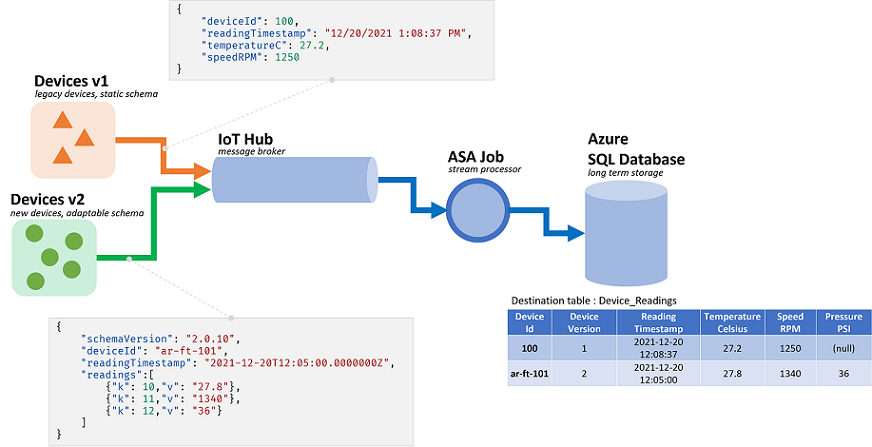
Pero las capacidades que ofrece el control dinámico de esquemas tienen un posible inconveniente. Los eventos inesperados pueden fluir mediante la lógica de consulta principal e interrumpirla. Por ejemplo, podemos usar ROUND en un campo de tipo NVARCHAR(MAX). ASA lo convertirá implícitamente en float para que coincida con la firma de ROUND. Aquí pretendemos, o esperamos, que este campo contendrá siempre valores numéricos. Pero cuando recibimos un evento con el campo establecido en "NaN", o si falta todo el campo, el trabajo puede producir un error.
Con la validación de entrada, se agregan pasos preliminares a nuestra consulta para controlar estos eventos con formato incorrecto. Usaremos principalmente WITH y TRY_CAST para implementarla.
Escenario: validación de entrada para productores de eventos no confiables
Crearemos un trabajo de ASA que ingerirá datos de un único centro de eventos. Como suele ocurrir, no somos responsables de los productores de datos. Aquí los productores son dispositivos IoT que venden varios proveedores de hardware.
Al reunirnos con las partes interesadas, acordamos un formato de serialización y un esquema. Todos los dispositivos insertarán estos mensajes en un centro de eventos común, entrada del trabajo de ASA.
El contrato de esquema se define de la siguiente manera:
| Nombre del campo | Tipo de campo | Descripción del campo |
|---|---|---|
deviceId |
Entero | Identificador único de dispositivo. |
readingTimestamp |
Datetime | Hora del mensaje, generada por una puerta de enlace central |
readingStr |
String | |
readingNum |
Numeric | |
readingArray |
Matriz de cadena |
Lo que, a su vez, nos proporciona el mensaje de ejemplo siguiente en serialización de JSON:
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7,
"readingArray" : ["A","B"]
}
Ya podemos ver una discrepancia entre el contrato de esquema y su implementación. En el formato JSON, no hay ningún tipo de datos para datetime. Se transmitirá como una cadena (vea readingTimestamp más arriba). ASA puede solucionar fácilmente el problema, pero muestra la necesidad de validar y convertir explícitamente los tipos. Más todavía para los datos serializados en CSV, ya que todos los valores se transmiten como cadena.
Hay otra discrepancia. ASA usa su propio sistema de tipos que no coincide con el de entrada. Si ASA tiene tipos integrados para enteros (bigint), datetime, cadena (nvarchar(max)) y matrices, solo admitirá valores numéricos mediante float. Este error de coincidencia no supone un problema para la mayoría de las aplicaciones. Pero en ciertos casos perimetrales, podría provocar ligeros desfases en la precisión. En este caso, convertiríamos el valor numérico como cadena en un campo nuevo. Después, en sentido descendente, usaríamos un sistema que admita decimales fijos para detectar y corregir posibles desfases.
De vuelta a nuestra consulta, aquí se pretende lo siguiente:
- Pasar
readingStra un UDF de Javascript - Contar el número de registros de la matriz
- Redondear
readingNuma la segunda posición decimal - Insertar los datos en una tabla SQL
La tabla SQL de destino tiene el esquema siguiente:
CREATE TABLE [dbo].[readings](
[Device_Id] int NULL,
[Reading_Timestamp] datetime2(7) NULL,
[Reading_String] nvarchar(200) NULL,
[Reading_Num] decimal(18,2) NULL,
[Array_Count] int NULL
) ON [PRIMARY]
Una buena práctica consiste en asignar lo que sucede a cada campo a medida que pasa por el trabajo:
| Campo | Entrada (JSON) | Tipo heredado (ASA) | Salida (Azure SQL) | Comentario |
|---|---|---|---|---|
deviceId |
number | bigint | integer | |
readingTimestamp |
string | nvarchar(MAX) | datetime2 | |
readingStr |
string | nvarchar(MAX) | nvarchar(200) | usado por la UDF |
readingNum |
number | FLOAT | decimal (18,2) | que se va a redondear |
readingArray |
array(string) | matriz de nvarchar(MAX) | integer | que se va a contar |
Requisitos previos
Desarrollaremos la consulta en Visual Studio Code con la extensión Herramientas de ASA. Los primeros pasos de este tutorial le guiarán por la instalación de los componentes necesarios.
En VS Code, usaremos ejecuciones locales con entrada/salida local para no incurrir en ningún costo y acelerar el bucle de depuración. No es necesario configurar un centro de eventos ni una instancia de Azure SQL Database.
Consulta base
Empecemos con una implementación básica, sin validación de entrada. Se agregará en la sección siguiente.
En VS Code, crearemos un proyecto de ASA.
En la carpeta input, crearemos un archivo JSON denominado data_readings.json y le agregaremos los registros siguientes:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingStr" : "Another String",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : -4.85436,
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : ["G","G"]
}
]
Después, definiremos una entrada local denominada readings, que hace referencia al archivo JSON que hemos creado anteriormente.
Una vez configurado, debería tener este aspecto:
{
"InputAlias": "readings",
"Type": "Data Stream",
"Format": "Json",
"FilePath": "data_readings.json",
"ScriptType": "InputMock"
}
Con los datos de vista previa, podemos observar que nuestros registros se cargan correctamente.
Crearemos una UDF de JavaScript denominada udfLen haciendo clic con el botón derecho en la carpeta Functions y seleccionando ASA: Add Function. El código que usaremos es el siguiente:
// Sample UDF that returns the length of a string for demonstration only: LEN will return the same thing in ASAQL
function main(arg1) {
return arg1.length;
}
En las ejecuciones locales, no es necesario definir salidas. Ni siquiera es necesario usar INTO a menos que haya más de una salida. En el archivo .asaql, podemos reemplazar la consulta existente por lo siguiente:
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
FROM readings AS r TIMESTAMP BY r.readingTimestamp
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
Veamos rápidamente la consulta que hemos enviado:
- Para contar el número de registros de cada matriz, en primer lugar es necesario desempaquetarlos. Usaremos CROSS APPLY y GetArrayElements() (puede obtener más ejemplos aquí).
- Al hacerlo, se exponen dos conjuntos de datos en la consulta: la entrada original y los valores de la matriz. Para asegurarse de que no se mezclan campos, se definen alias (
AS r) y se usan en todas partes. - Después, para usar
COUNTcon los valores de la matriz, es necesario agregar con GROUP BY. - Para ello, debemos definir una ventana de tiempo. Aquí, dado que no necesitamos una para nuestra lógica, la ventana de instantánea es la opción adecuada.
- Al hacerlo, se exponen dos conjuntos de datos en la consulta: la entrada original y los valores de la matriz. Para asegurarse de que no se mezclan campos, se definen alias (
- También tenemos que usar
GROUP BYen todos los campos y proyectarlos todos enSELECT. La proyección explícita de campos es un procedimiento recomendado, ya queSELECT *permitirá que los errores fluyan de la entrada a la salida.- Si definimos una ventana de tiempo, es posible que quiera definir una marca de tiempo con TIMESTAMP BY. Aquí no es necesario que nuestra lógica funcione. Para ejecuciones locales, sin
TIMESTAMP BYtodos los registros se cargan en una sola marca de tiempo, la hora de inicio de la ejecución.
- Si definimos una ventana de tiempo, es posible que quiera definir una marca de tiempo con TIMESTAMP BY. Aquí no es necesario que nuestra lógica funcione. Para ejecuciones locales, sin
- Usamos la UDF para filtrar las lecturas en las que
readingStrtiene menos de dos caracteres. Aquí deberíamos haber usado LEN. Estamos usando una UDF solo con fines de demostración.
Podemos iniciar una ejecución y observar los datos que se están procesando:
| deviceId | readingTimestamp | readingStr | readingNum | arrayCount |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Una cadena | 1,71 | 2 |
| 2 | 2021-12-10T10:01:00 | Otra cadena | 2,38 | 1 |
| 3 | 2021-12-10T10:01:20 | Una tercera cadena | -4,85 | 3 |
| 1 | 2021-12-10T10:02:10 | Una cuarta cadena | 1.21 | 2 |
Ahora que sabemos que la consulta funciona, vamos a probarla con más datos. Reemplace el contenido de data_readings.json por los registros siguientes:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : "NaN",
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : {}
}
]
Aquí podemos ver los problemas siguientes:
- El dispositivo n.º 1 ha hecho todo correcto.
- El dispositivo n.º 2 ha olvidado incluir un elemento
readingStr. - Dispositivo n.º 3 ha enviado
NaNcomo un número. - El dispositivo n.º 4 ha enviado un registro vacío en lugar de una matriz.
La ejecución del trabajo ahora no debería terminar bien. Aparecerá uno de los mensajes de error siguientes:
El dispositivo 2 nos dará lo siguiente:
[Error] 12/22/2021 10:05:59 PM : **System Exception** Function 'udflen' resulted in an error: 'TypeError: Unable to get property 'length' of undefined or null reference' Stack: TypeError: Unable to get property 'length' of undefined or null reference at main (Unknown script code:3:5)
[Error] 12/22/2021 10:05:59 PM : at Microsoft.EventProcessing.HostedRuntimes.JavaScript.JavaScriptHostedFunctionsRuntime.
El dispositivo 3 nos dará lo siguiente:
[Error] 12/22/2021 9:52:32 PM : **System Exception** The 1st argument of function round has invalid type 'nvarchar(max)'. Only 'bigint', 'float' is allowed.
[Error] 12/22/2021 9:52:32 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Arithmetics.Round(CompilerPosition pos, Object value, Object length)
El dispositivo 4 nos dará lo siguiente:
[Error] 12/22/2021 9:50:41 PM : **System Exception** Cannot cast value of type 'record' to type 'array' in expression 'r . readingArray'. At line '9' and column '30'. TRY_CAST function can be used to handle values with unexpected type.
[Error] 12/22/2021 9:50:41 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Cast.ToArray(CompilerPosition pos, Object value, Boolean isUserCast)
Cada vez que se permitía que los registros con formato incorrecto fluyeran desde la entrada a la lógica de consulta principal sin validarse. Ahora nos damos cuenta del valor de la validación de entrada.
Implementación de la validación de entrada
Vamos a ampliar la consulta para validar la entrada.
El primer paso de la validación de entrada consiste en definir las expectativas de esquema de la lógica de negocios principal. Al volver al requisito original, nuestra lógica principal es la siguiente:
- Pasar
readingStra un UDF de Javascript para medir su longitud - Contar el número de registros de la matriz
- Redondear
readingNuma la segunda posición decimal - Insertar los datos en una tabla SQL
Para cada punto, podemos mostrar una lista de las expectativas:
- La UDF requiere un argumento de tipo string (nvarchar(max) aquí) que no puede ser NULL.
GetArrayElements()requiere un argumento de tipo array o un valor NULL.Roundrequiere un argumento de tipo bigint o float, o un valor NULL.- En lugar de confiar en la conversión implícita de ASA, debemos hacerlo nosotros mismos y controlar los conflictos de tipos en la consulta.
Una manera de trabajar es adaptar la lógica principal para tratar con estas excepciones. Pero en este caso, creemos que nuestra lógica principal es perfecta. Por lo tanto, vamos a validar los datos de entrada en su lugar.
En primer lugar, vamos a usar WITH para agregar una capa de validación de entrada como primer paso de la consulta. Usaremos TRY_CAST para convertir campos a su tipo esperado y establecerlos en NULL si se produce un error en la conversión:
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
)
-- For debugging only
SELECT * FROM readingsValidated
Con el último archivo de entrada que hemos usado (el que tiene errores), esta consulta devolverá el conjunto siguiente:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Una cadena | 1,7145 | ["A", "B"] | 1 | 2021-12-10T10:00:00Z | Una cadena | 1,7145 | ["A", "B"] |
| 2 | 2021-12-10T10:01:00 | NULL | 2,378 | ["C"] | 2 | 2021-12-10T10:01:00Z | NULL | 2,378 | ["C"] |
| 3 | 2021-12-10T10:01:20 | Una tercera cadena | NaN | ["D","E","F"] | 3 | 2021-12-10T10:01:20Z | Una tercera cadena | NULL | ["D","E","F"] |
| 4 | 2021-12-10T10:02:10 | Una cuarta cadena | 1,2126 | {} | 4 | 2021-12-10T10:02:10Z | Una cuarta cadena | 1,2126 | NULL |
Ya podemos ver el planteamiento de dos de nuestros errores. Hemos transformado NaN y {} en NULL. Ahora tenemos la seguridad de que estos registros se insertarán correctamente en la tabla SQL de destino.
Ahora tenemos que decidir cómo abordar los registros con valores que faltan o que no son válidos. Después de debatirlo, decidimos rechazar los registros con un elemento readingArray vacío o no válido, o con un elemento readingStr que falta.
Por lo tanto, agregamos una segunda capa que evaluará la prioridad de los registros entre la validación y la lógica principal:
WITH readingsValidated AS (
...
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- For debugging only
SELECT * INTO Debug1 FROM readingsToBeProcessed
SELECT * INTO Debug2 FROM readingsToBeRejected
Es conveniente escribir una sola cláusula WHERE para ambas salidas y usar NOT (...) en la segunda. De este modo, no se podrá excluir ningún registro de ambas salidas ni perderse en estas.
Ahora se obtienen dos salidas. Debug1 tiene los registros que se enviarán a la lógica principal:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00Z | Una cadena | 1,7145 | ["A", "B"] |
| 3 | 2021-12-10T10:01:20Z | Una tercera cadena | NULL | ["D","E","F"] |
Debug2 tiene los registros que se rechazarán:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-12-10T10:01:00 | NULL | 2,378 | ["C"] | 2 | 2021-12-10T10:01:00Z | NULL | 2,378 | ["C"] |
| 4 | 2021-12-10T10:02:10 | Una cuarta cadena | 1,2126 | {} | 4 | 2021-12-10T10:02:10Z | Una cuarta cadena | 1,2126 | NULL |
El último paso consiste en volver a agregar la lógica principal. También agregaremos la salida que recopila los rechazos. Aquí es mejor usar un adaptador de salida que no exija el tipado fuerte, como una cuenta de almacenamiento.
La consulta completa se puede encontrar en la última sección.
WITH
readingsValidated AS (...),
readingsToBeProcessed AS (...),
readingsToBeRejected AS (...)
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
SELECT
*
INTO BlobOutput
FROM readingsToBeRejected
Lo que nos dará el conjunto siguiente para SQLOutput, sin ningún error posible:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00Z | Una cadena | 1,7145 | 2 |
| 3 | 2021-12-10T10:01:20Z | Una tercera cadena | NULL | 3 |
Los otros dos registros se envían a BlobOutput para una revisión humana y su procesamiento posterior. Nuestra consulta ahora es segura.
Ejemplo de consulta con validación de entrada
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- Core business logic
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
-- Rejected output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- to a storage adapter that doesn't require strong typing, here blob/adls
FROM readingsToBeRejected
Ampliación de la validación de entrada
GetType se puede usar para comprobar explícitamente si hay un tipo. Funciona bien con CASE en la proyección o con WHERE en el nivel establecido. GetType también se puede usar para comprobar dinámicamente el esquema de entrada en un repositorio de metadatos. El repositorio se puede cargar mediante un conjunto de datos de referencia.
Las pruebas unitarias son un procedimiento recomendado para garantizar que nuestra consulta sea resistente. Vamos a crear una serie de pruebas que constan de archivos de entrada y su salida esperada. Nuestra consulta tendrá que coincidir con la salida que genera para pasar. En ASA, las pruebas unitarias se realizan mediante el módulo asa-streamanalytics-cicd. Los casos de prueba que tengan varios eventos con formato incorrecto deben crearse y probarse en la canalización de implementación.
Por último, podemos realizar algunas pruebas ligeras de integración en VS Code. Podemos insertar registros en la tabla SQL mediante una ejecución local en una salida activa.
Obtención de soporte técnico
Para más ayuda, pruebe nuestra página de preguntas y respuestas de Microsoft sobre Azure Stream Analytics.
Pasos siguientes
- Configuración de canalizaciones de CI/CD y pruebas unitarias mediante el paquete npm
- Información general sobre las ejecuciones de Stream Analytics locales en Visual Studio Code con herramientas de ASA
- Prueba de consultas de Stream Analytics localmente con datos de ejemplo mediante Visual Studio Code
- Prueba de las consultas de Stream Analytics localmente en una entrada de streaming en vivo con Visual Studio Code
- Exploración de trabajos de Azure Stream Analytics con Visual Studio Code (versión preliminar)