Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, aprenderá a modificar una base de datos de lago ya existente en Azure Synapse mediante el diseñador de bases de datos. El diseñador de bases de datos le permite crear e implementar fácilmente una base de datos sin tener que escribir código.
Prerrequisitos
- Se requieren permisos de administrador o colaborador de Synapse en el área de trabajo de Synapse para crear una base de datos de lago.
- Los permisos de colaborador de datos de blobs de almacenamiento son necesarios en el lago de datos al usar la opción Desde el lago de datos de creación de tablas.
Modificación de las propiedades de la base de datos
Desde el centro de Inicio del área de trabajo de Azure Synapse Analytics, seleccione la pestaña Datos que tiene a la izquierda. Se abrirá la pestaña Datos, donde verá la lista de bases de datos que ya existen en el área de trabajo.
Pase el mouse por la sección Bases de datos, seleccione los puntos suspensivos ... junto a la base de datos que desea modificar y, a continuación, elija Abrir.
La pestaña del diseñador de bases de datos se abrirá con la base de datos seleccionada cargada en el lienzo.
El diseñador de bases de datos tiene un panel Propiedades que se puede abrir seleccionando el icono Propiedades situado en la esquina superior derecha de la pestaña.
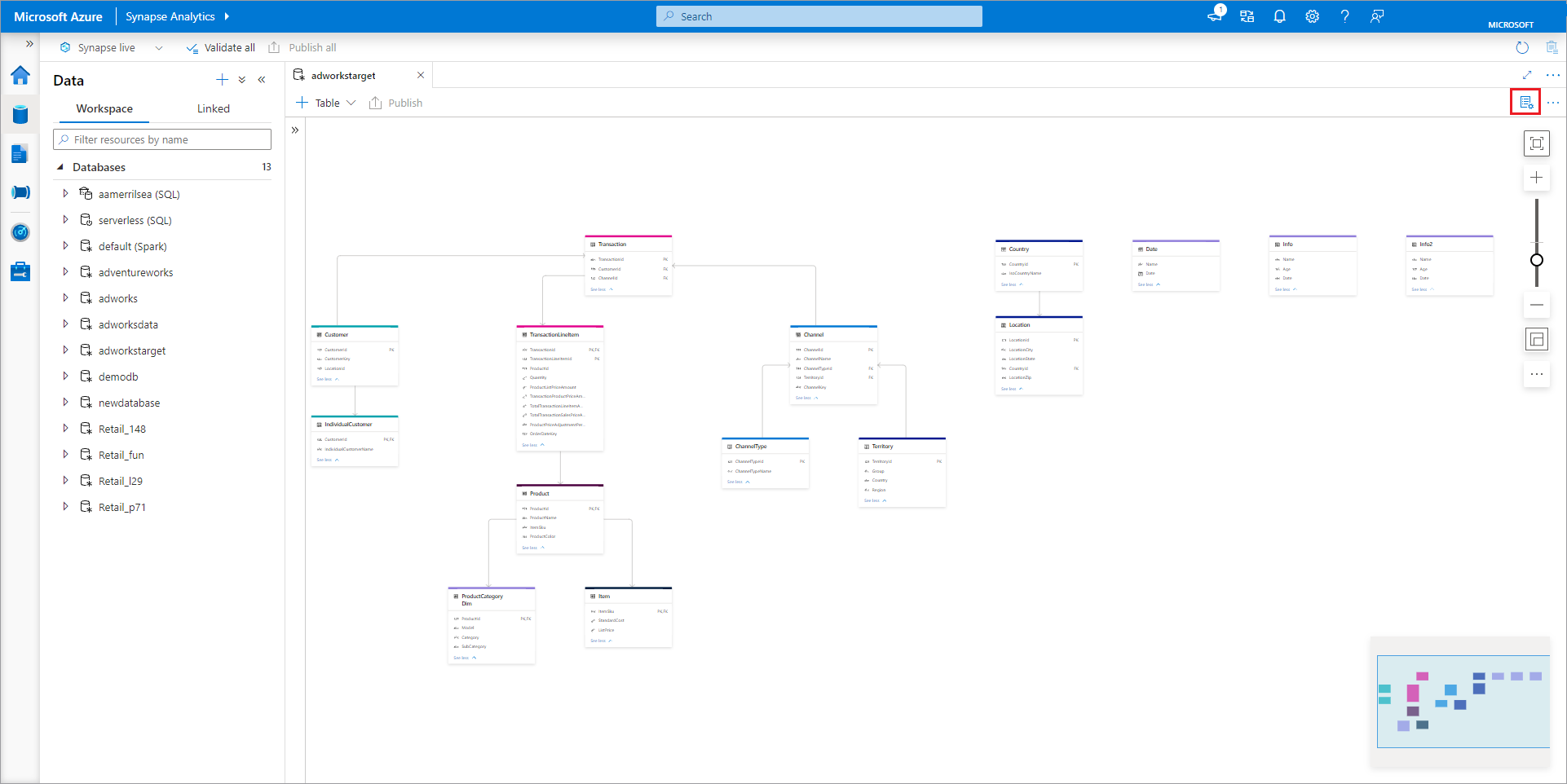
- Nombre: los nombres no se pueden editar después de publicar la base de datos, por lo que debe asegurarse de que el nombre que elija sea correcto.
- Descripción: proporcionar una descripción para la base de datos es opcional, pero esto permite a los usuarios comprender el propósito de la base de datos.
- La configuración de almacenamiento de la base de datos es una sección que contiene la información de almacenamiento predeterminada para las tablas de la base de datos. La configuración predeterminada se aplica a cada tabla de la base de datos, a menos que se invalide en la propia tabla.
- El servicio vinculado es el servicio vinculado predeterminado que se usa para almacenar los datos en Azure Data Lake Storage. Se mostrará el servicio vinculado predeterminado asociado al área de trabajo de Synapse, pero puede cambiar el servicio vinculado a cualquier cuenta de almacenamiento de ADLS que quiera.
- Carpeta de entrada Se usa para establecer la ruta de acceso predeterminada del contenedor y la carpeta de ese servicio vinculado mediante el explorador de archivos o editando manualmente la ruta de acceso con el icono de lápiz.
- Formato de datos: las bases de datos de lago en Azure Synapse admiten Parquet y texto delimitado como formatos de almacenamiento de datos.
Para agregar una tabla a la base de datos, seleccione el botón + Tabla.
- El valor Personalizado agregará una nueva tabla al lienzo.
- La opción Desde la plantilla abrirá la galería y podrá seleccionar una plantilla de base de datos que se usará al agregar una nueva tabla. Para obtener más información, consulte Creación de una base de datos de lago a partir de una plantilla de base de datos.
- La opción Desde el lago de datos le permite importar un esquema de tabla con datos que ya están en el lago.
seleccione Personalizada. Aparecerá una nueva tabla en el lienzo denominada Table_1.
A continuación, puede personalizar Table_1, incluidos el nombre de la tabla, la descripción, la configuración de almacenamiento, las columnas y las relaciones. Consulte la sección Personalización de las tablas de una base de datos más abajo.
Agregue una nueva tabla del lago de datos seleccionando + Tabla y, a continuación, Desde el lago de datos.
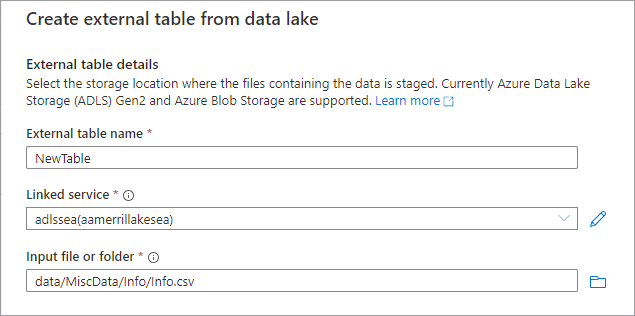
Aparecerá el panel Crear tabla externa a partir del lago de datos. Rellene el panel con los detalles siguientes y seleccione Continuar.
- Nombre de tabla externa: es el nombre que quiere darle a la tabla que está creando.
- Servicio vinculado: es el servicio vinculado que contiene la ubicación de Azure Data Lake Storage donde reside el archivo de datos.
-
Archivo o carpeta de entrada: use el explorador de archivos para navegar y seleccionar un archivo en su lago, para crear una tabla con él.
- En la siguiente pantalla, Azure Synapse obtendrá una vista previa del archivo y detectará el esquema.
- Accederá a la página Nueva tabla externa, donde puede actualizar cualquier configuración relacionada con el formato de datos y Vista previa de datos para verificar si Azure Synapse identificó el archivo correctamente.
- Cuando esté satisfecho con la configuración, seleccione Crear.
- Se agregará una nueva tabla con el nombre seleccionado al lienzo y la sección Configuración de Storage para la tabla mostrará el archivo que especificó.
Ahora que tiene la base de datos personalizada, es el momento de publicarla. Si usa la integración de Git con el área de trabajo de Synapse, debe confirmar los cambios y combinarlos en la rama de colaboración. Obtenga más información sobre el control de código fuente en Azure Synapse. Si usa el modo en directo de Synapse, puede seleccionar "publicar".
La base de datos se validará para ver si hay errores antes de su publicación. Los errores encontrados se mostrarán en la pestaña de notificaciones y tendrán instrucciones sobre cómo solucionar el error.
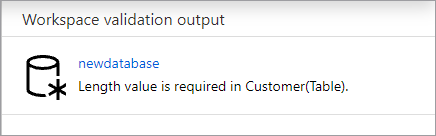
La publicación creará el esquema de base de datos en el Metastore de Azure Synapse. Después de la publicación, los objetos de base de datos y tabla serán visibles para otros servicios de Azure y permitirán que los metadatos de la base de datos fluyan a aplicaciones como Power BI o Microsoft Purview.
Personalización de las tablas de una base de datos
El diseñador de bases de datos permite personalizar completamente cualquiera de las tablas de la base de datos. Al seleccionar una tabla hay tres pestañas disponibles, y cada una de ellas contiene la configuración relacionada con el esquema o los metadatos de la tabla.
General
La pestaña General contiene información específica de la tabla en sí.
Nombre: nombre de la tabla. El nombre de la tabla se puede personalizar para reflejar cualquier valor único dentro de la base de datos. No se permiten varias tablas con el mismo nombre.
Heredado de (opcional): este valor estará presente si la tabla se creó a partir de una plantilla de base de datos. Este valor no se puede editar, e indica al usuario de qué plantilla deriva la tabla.
Descripción: descripción de la tabla. Si la tabla se creó a partir de una plantilla de base de datos, contendrá una descripción del concepto representado por esta tabla. Este campo es editable y se puede cambiar para que coincida con una descripción que encaje con sus requisitos empresariales.
La carpeta de visualización proporciona el nombre de la carpeta de área de negocio en la que esta tabla se ha agrupado como parte de la plantilla de base de datos. En el caso de las tablas personalizadas, este valor será "Otro".
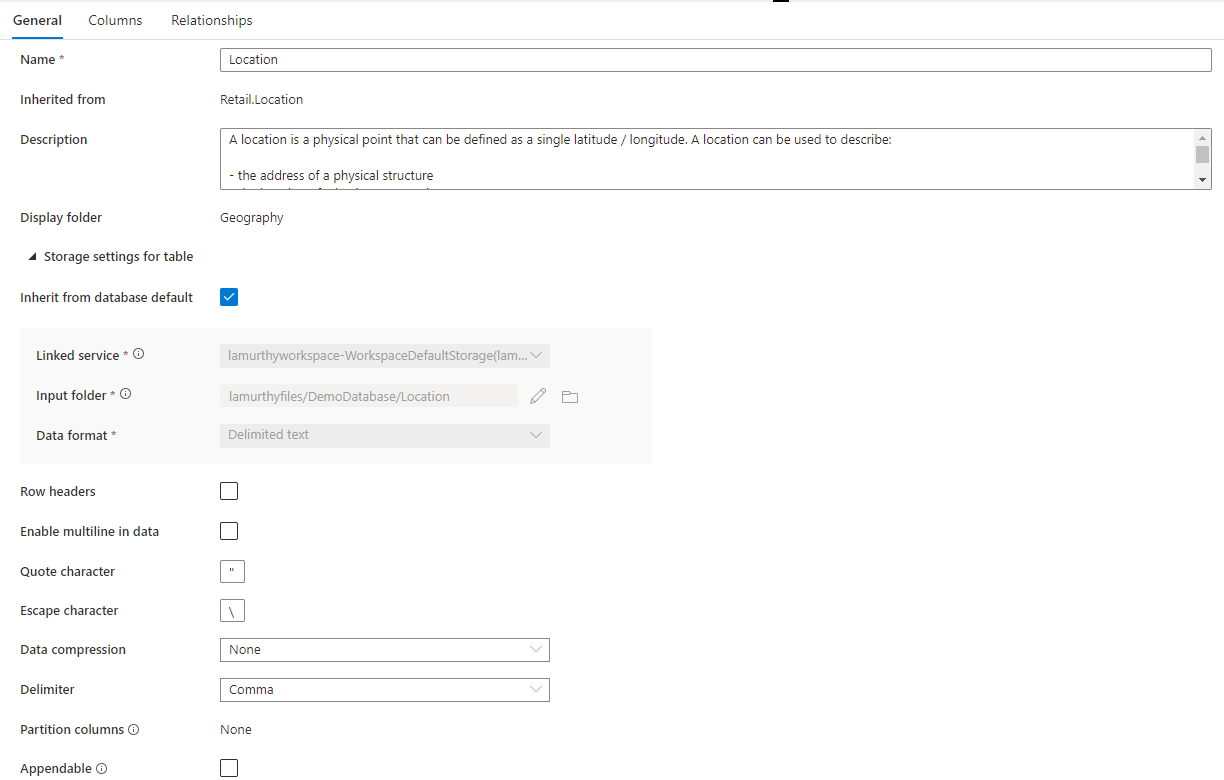
Aparte, hay una sección contraíble denominada Storage settings for table (Configuración de almacenamiento de la tabla) que proporciona opciones de configuración de la información de almacenamiento subyacente utilizada por la tabla.
Inherit from database default (Heredar de la base de datos predeterminada): casilla que determina si la configuración de almacenamiento siguiente se hereda de los valores establecidos en la pestaña Propiedades de la base de datos, o bien se establecen individualmente. Si desea personalizar los valores de almacenamiento, desactive esta casilla.
- El servicio vinculado es el servicio vinculado predeterminado que se usa para almacenar los datos en Azure Data Lake Storage. Cambie esta opción para elegir una cuenta de ADLS diferente.
- La carpeta de entrada es la carpeta de ADLS donde van a estar los datos cargados en esta tabla. Puede examinar la ubicación de la carpeta o editarla manualmente con el icono de lápiz.
- Formato de datos: el formato de datos de los datos contenidos en la carpeta de entrada de las bases de datos de lago en Azure Synapse admiten Parquet y texto delimitado como formatos de almacenamiento de datos. Si el formato de datos no coincide con los datos de la carpeta, se producirá un error en las consultas a la tabla.
En el caso de un formato de datos de texto delimitado, hay más opciones:
- Encabezados de fila: active esta casilla si los datos tienen encabezados de fila.
- Habilitación de texto multilínea en los datos Active esta casilla si los datos tienen varias líneas en una columna de cadena.
- Carácter de comillas Especifique el carácter de comillas personalizado para un archivo de texto delimitado.
- Carácter de escape Especifique el carácter de escape personalizado para un archivo de texto delimitado.
- Compresión de datos: tipo de compresión utilizado en los datos.
- Delimitador: delimitador de campo utilizado en los archivos de datos. Los valores admitidos son una coma (,), una tabulación (\t) y una barra vertical (|).
- Columnas de partición La lista de columnas de partición se mostrará aquí.
- Anexable Active esta casilla si consulta datos de Dataverse desde SQL sin servidor.
Para los datos de Parquet existe la siguiente configuración:
- Compresión de datos: tipo de compresión utilizado en los datos.
Columnas
La pestaña Columnas es donde se enumeran las columnas de la tabla, que se pueden modificar. En esta pestaña hay dos listas de columnas: Columnas estándar y Columnas de partición. Las columnas estándar son cualquier columna que almacene datos, es una clave principal. De lo contrario, no se usa para la creación de particiones de los datos. Las columnas de partición también almacenan datos, pero se usan para crear particiones de los datos subyacentes en carpetas en función de los valores contenidos en la columna. Cada columna tiene las siguientes propiedades.
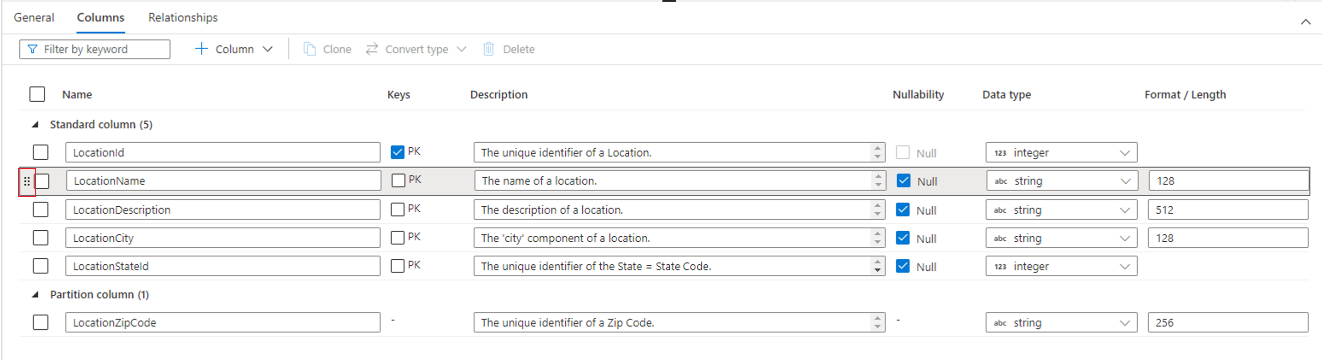
- Nombre: nombre de la columna. Debe ser único dentro de la tabla.
- Claves Indica si la columna es una clave principal (PK) o una clave externa (FK) de la tabla. No se aplica a las columnas de partición.
- Descripción: descripción de la columna. Si la columna se creó a partir de una plantilla de base de datos, se verá la descripción del concepto representado por esta columna. Este campo es editable y se puede cambiar para que coincida con una descripción que encaje con sus requisitos empresariales.
- La nulabilidad indica si puede haber valores nulos en esta columna. No se aplica a las columnas de partición.
- Tipo de datos: establece el tipo de datos de la columna en función de la lista disponible de tipos de datos de Spark.
- Formato/Longitud: permite personalizar el formato o la longitud máxima de la columna en función del tipo de datos. Los tipos de datos Date y Timestamp tienen listas desplegables de formato, mientras que otros tipos, como String, tienen un campo de longitud máxima. No todos los tipos de datos tienen un valor, ya que algunos tienen una longitud fija. Encima de la pestaña Columnas hay una barra de comandos que se puede usar para interactuar con las columnas.
- Filtrar por palabra clave: filtra la lista de columnas para mostrar los elementos que coinciden con la palabra clave especificada.
-
+ Columna: permite agregar una nueva columna. Hay tres opciones posibles.
- Nueva columna: crea una columna estándar personalizada desde cero.
- Desde la plantilla: abre el panel de exploración y permite identificar las columnas de una plantilla de base de datos que se incluirán en la tabla. Si la base de datos no se creó con una plantilla de base de datos, esta opción no aparecerá.
- Columna de partición: agrega una nueva columna de partición personalizada.
- Clonar: duplica la columna seleccionada. Las columnas clonadas siempre son del mismo tipo que la columna seleccionada.
- Convertir tipo: se usa para cambiar la columna estándar seleccionada por una columna de partición, y a la inversa. Esta opción aparecerá atenuada si ha seleccionado varias columnas de distintos tipos, o si la columna seleccionada no se puede convertir debido a una marca PK o de nulabilidad establecida en la columna.
- Eliminar: elimina las columnas seleccionadas de la tabla. Esta acción es irreversible.
También puede volver a organizar el orden de las columnas arrastrando y colocando con los puntos suspensivos verticales dobles que se muestran a la izquierda del nombre de columna al mantener el puntero sobre la columna o hacer clic en ella, como se muestra en la imagen anterior.
Columnas de partición
Las columnas de partición se usan para crear particiones de los datos físicos de la base de datos en función de los valores de esas columnas. Con las columnas de partición, los datos en disco se pueden distribuir fácilmente en fragmentos que tienen un mejor rendimiento. Las columnas de partición de Azure Synapse siempre están al final del esquema de tabla. Además, se usan de arriba a abajo al crear las carpetas de partición. Por ejemplo, si las columnas de partición fueran Year y Month, obtendríamos una estructura en ADLS como esta:
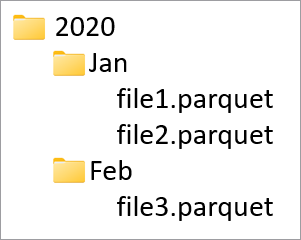
Aquí file1 y file2 contienen todas las filas donde los valores de Year y Month hayan sido "2020" y "Jan" respectivamente. Cuantas más columnas de partición se agreguen a una tabla, más archivos se irán agregando a esta jerarquía, lo que hace que el tamaño de archivo general de las particiones sea menor.
Azure Synapse no aplica ni crea esta jerarquía agregando columnas de partición a una tabla. Los datos deben cargarse en la tabla mediante Synapse Pipelines o un cuaderno de Spark para que se cree la estructura de particiones.
Relaciones
La pestaña Relaciones permite especificar relaciones entre las tablas de la base de datos. Las relaciones en el diseñador de bases de datos son informativas y no aplican ninguna restricción en los datos subyacentes. Otras aplicaciones de Microsoft las leen para acelerar las transformaciones o para proporcionar a los usuarios empresariales información sobre cómo se conectan las tablas. Las relaciones tienen la siguiente información.
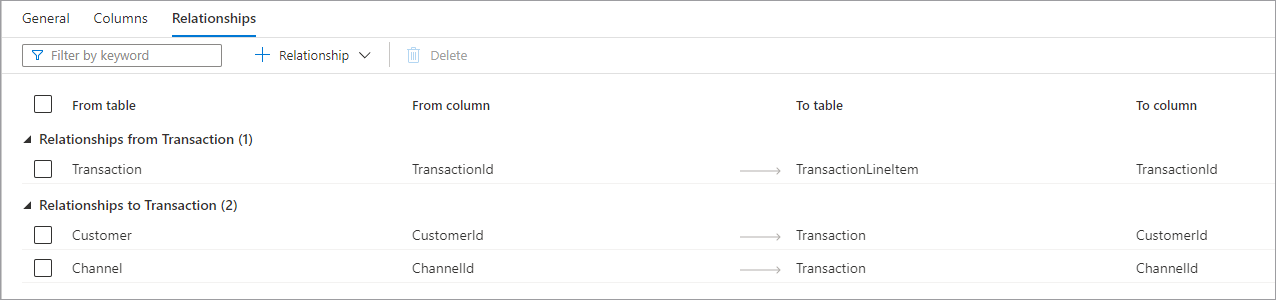
- Relationships from (Table) (Relaciones desde [tabla]): una o varias tablas tienen claves externas conectadas a esta tabla. A veces, esto se denomina relación primaria.
- Relationships to (Table) (Relaciones hacia [tabla]): una tabla que tiene una clave externa y que está conectada a otra tabla. A veces, esto se denomina relación secundaria.
- Ambos tipos de relación tienen las siguientes propiedades.
- Desde tabla: tabla principal de la relación, o lado "uno".
- Desde columna: columna de la tabla principal en la que se basa la relación.
- A tabla: tabla secundaria de la relación, o lado "varios".
- A columna: columna de la tabla secundaria en la que se basa la relación. Encima de la pestaña Relaciones hay una barra de comandos que se puede usar para interactuar con las relaciones.
- Filtrar por palabra clave: filtra la lista de columnas para mostrar los elementos que coinciden con la palabra clave especificada.
-
+ Relación: permite agregar una nueva relación. Hay dos opciones.
- Desde tabla: se crea una nueva relación entre la tabla con la que está trabajando y otra tabla.
- A tabla: se crea una nueva relación desde una tabla diferente a la tabla con la que está trabajando.
- Desde la plantilla: abre el panel de exploración y permite elegir entre las relaciones de la plantilla de base de datos que se incluirán en la base de datos. Si la base de datos no se creó con una plantilla de base de datos, esta opción no aparecerá.
Pasos siguientes
Siga explorando las funcionalidades del diseñador de bases de datos mediante los vínculos siguientes.