Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, aprenderá los pasos básicos para cargar y analizar datos con Data Explorer para Azure Synapse.
Crear un grupo de Data Explorer
En Synapse Studio, en el panel izquierdo, seleccione Administrar>Grupos exploradores de datos.
Seleccione Nuevo y, luego, escriba los siguientes detalles en la pestaña Aspectos básicos:
Configuración Valor sugerido Descripción Nombre del grupo del Explorador de datos contosodataexplorer Este es el nombre que tendrá el grupo del Explorador de datos. Carga de trabajo Proceso optimizado Esta carga de trabajo proporciona una mayor proporción de almacenamiento de CPU a SSD. Tamaño del nodo Pequeña (4 núcleos) Establézcalo en el menor tamaño para reducir los costos de este artículo de inicio rápido Importante
Tenga en cuenta que existen limitaciones específicas para los nombres que los grupos del Explorador de datos pueden usar. Los nombres solo deben contener letras minúsculas y números, deben tener entre 4 y 15 caracteres y deben empezar por una letra.
Seleccione Revisar y crear>Crear. El grupo de Data Explorer iniciará el proceso de aprovisionamiento.
Creación de una base de datos de Data Explorer
En Synapse Studio, en el panel izquierdo, seleccione Datos.
Seleccione + (Agregar un recurso nuevo) >Base de datos de Data Explorer y pegue la información siguiente:
Configuración Valor sugerido Descripción Nombre del grupo contosodataexplorer Nombre del grupo de Data Explorer que se usará. Name TestDatabase El nombre de la base de datos debe ser único dentro del clúster. Período de retención predeterminado 365 El intervalo de tiempo (en días) para el que se garantiza que los datos se mantengan disponibles para consultarlos. El intervalo de tiempo se mide desde el momento en que se ingieren los datos. Período de caché predeterminado 31 El intervalo de tiempo (en días) durante el que los datos consultados con frecuencia se van a mantener disponibles en el almacenamiento SSD o en la RAM, en lugar de en el almacenamiento a largo plazo. Seleccione Crear para crear la base de datos. Normalmente se tarda menos de un minuto.
Ingesta de datos de ejemplo y análisis con una consulta simple
Una vez implementado el grupo, en Synapse Studio, en el panel izquierdo, seleccione Desarrollar.
Seleccione + (Agregar nuevo recurso) >Script de KQL. En el panel derecho, puede asignar un nombre al script.
En el menú Conectarse a, seleccione contosodataexplorer.
En el menú Use database (Usar base de datos), seleccione TestDatabase.
Pegue el siguiente comando y seleccione Ejecutar para crear una tabla de StormEvents.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Sugerencia
Compruebe que la tabla se creó correctamente. En el panel izquierdo, seleccione Datos, elija contosodataexplorer en el menú Más y seleccione Actualizar. En contosodataexplorer, expanda Tablas y asegúrese de que la tabla StormEvents aparece en la lista.
Pegue el siguiente comando y seleccione Ejecutar para ingerir datos en la tabla de StormEvents.
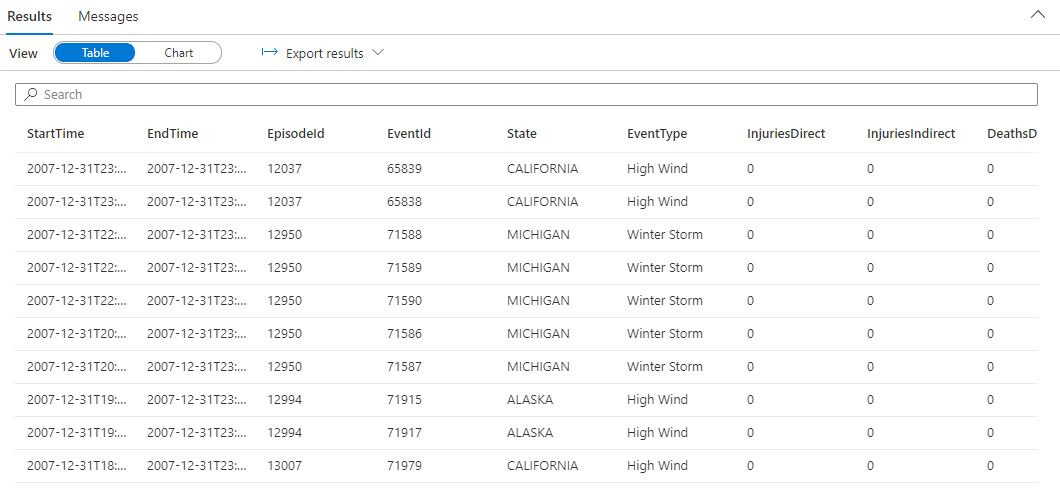
.ingest into table StormEvents 'https://kustosamples.blob.core.windows.net/samplefiles/StormEvents.csv' with (ignoreFirstRecord=true)Una vez finalizada la ingesta, pegue la siguiente consulta, seleccione la consulta en la ventana y haga clic en Ejecutar.
StormEvents | sort by StartTime desc | take 10La consulta devuelve los siguientes resultados de los datos de ejemplo ingeridos.