Advisor de Apache Spark en Azure Synapse Analytics (versión preliminar)
Advisor de Apache Spark analiza los comandos y el código que ejecuta Spark, y muestra avisos en tiempo real para las ejecuciones de Notebook. Advisor de Spark tiene patrones integrados a fin de ayudar a los usuarios a evitar errores comunes, ofrecer recomendaciones para la optimización del código, realizar análisis de errores y localizar la causa principal de errores.
Avisos integrados
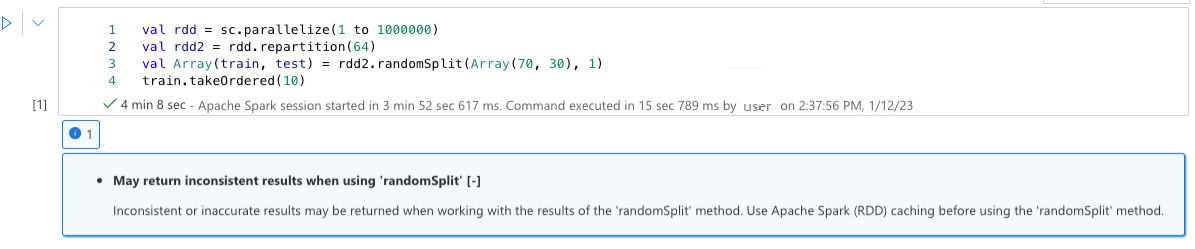
Puede devolver resultados incoherentes al usar "randomSplit"
Se pueden devolver resultados incoherentes o inexactos al trabajar con los resultados del método "randomSplit". Use el almacenamiento en caché de Apache Spark (RDD) antes de usar el método "randomSplit".
El método randomSplit() equivale a realizar sample() en el marco de datos varias veces, con cada captura de muestra, la creación de particiones y la ordenación del marco de datos dentro de las particiones. La distribución de datos entre particiones y criterio de ordenación es importante para randomSplit() y sample(). Si alguno cambia en la captura de datos, puede haber duplicados o faltar valores entre divisiones y el mismo ejemplo con la misma inicialización puede producir resultados diferentes.
Estas incoherencias pueden no producirse en cada ejecución, pero para eliminarlas por completo, almacene en caché el marco de datos, vuelva a particionar en una columna o aplique funciones de agregado como groupBy.
El nombre de la tabla/vista ya está en uso
Ya existe una vista con el mismo nombre que la tabla creada o ya existe una tabla con el mismo nombre que la vista creada. Cuando este nombre se usa en consultas o aplicaciones, solo se devolverá la vista, independientemente de cuál haya creado primero. Para evitar conflictos, cambie el nombre de la tabla o de la vista.
No se puede reconocer una sugerencia
La consulta seleccionada contiene una sugerencia que no se reconoce. Compruebe que el nombre de la sugerencia esté correctamente escrito.
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
No se pueden encontrar nombres de relación especificados
No se pueden encontrar las relaciones especificadas en la sugerencia. Compruebe que las relaciones están escritas correctamente y sean accesibles dentro del ámbito de la sugerencia.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Una sugerencia de la consulta impide que se aplique otra sugerencia
La consulta seleccionada contiene una sugerencia que impide que se aplique otra sugerencia.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Habilite "spark.advise.divisionExprConvertRule.enable" para reducir la propagación de errores de redondeo
Esta consulta contiene la expresión con tipo Double. Se recomienda habilitar la configuración "spark.advise.divisionExprConvertRule.enable", lo que puede ayudar a reducir las expresiones de división y reducir la propagación de errores de redondeo.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
Habilite "spark.advise.nonEqJoinConvertRule.enable" para mejorar el rendimiento de las consultas
Esta consulta contiene una combinación que consume mucho tiempo debido a la condición "Or" en la consulta. Se recomienda habilitar la configuración "spark.advise.nonEqJoinConvertRule.enable", lo cual puede ayudar a convertir la combinación desencadenada por la condición "Or" en SMJ o BHJ para acelerar esta consulta.
Optimización de la tabla delta con compactación de archivos pequeños
Esta consulta se encuentra en una tabla delta con muchos archivos pequeños. Para mejorar el rendimiento de las consultas, ejecute el comando OPTIMIZE en la tabla delta. En este artículo podrá encontrar más información.
Optimización de la tabla delta con ZOrder
Esta consulta se encuentra en una tabla delta y contiene un filtro muy selectivo. Para mejorar el rendimiento de las consultas, ejecute el comando OPTIMIZE ZORDER BY en la tabla delta. En este artículo podrá encontrar más información.
Experiencia del usuario
Advisor de Apache Spark muestra los avisos, incluida la información, las advertencias y los errores, en tiempo real de salida de la celda del cuaderno.
Información
Advertencia

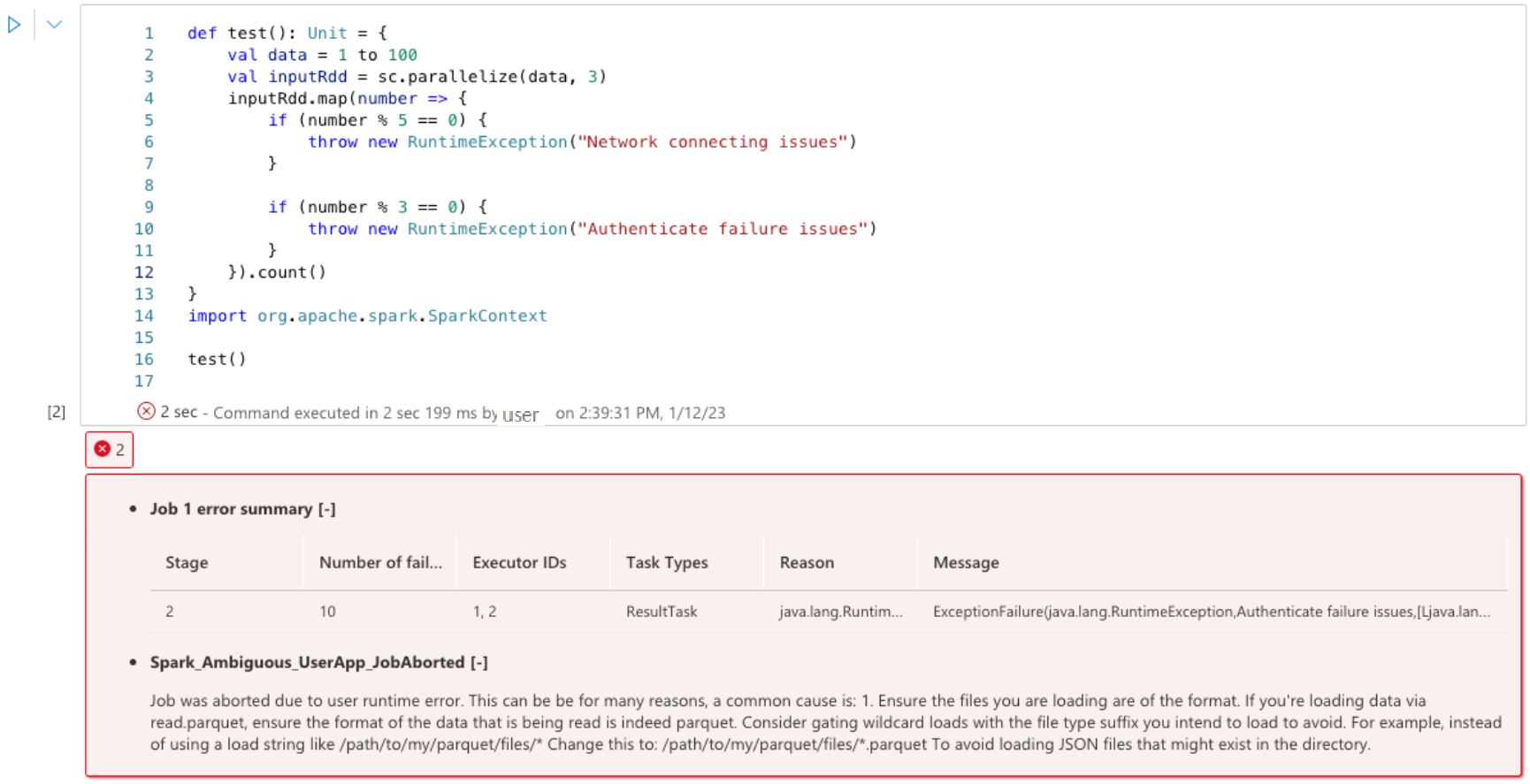
Errors
Pasos siguientes
Para más información sobre la supervisión de las aplicaciones de Apache Spark, consulte el artículo sobre la supervisión de aplicaciones de Apache Spark mediante Synapse Studio.
Para más información sobre cómo crear un cuaderno, consulte el artículo sobre el uso de cuadernos de Synapse.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de