Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe cómo acceder a la base de datos de Azure Data Explorer desde Synapse Studio con Apache Spark para Azure Synapse Analytics.
Requisitos previos
- Cree de un clúster y de la base de datos de Azure Data Explorer.
- Debe tener un área de trabajo de Azure Synapse Analytics existente o crear una siguiendo los pasos descritos en Inicio rápido: Creación de un área de trabajo de Azure Synapse.
- Debe tener un grupo de Apache Spark existente o crear uno siguiendo los pasos descritos en Inicio rápido: Creación de un grupo de Apache Spark (versión preliminar).
- Crear una aplicación de Microsoft Entra mediante el aprovisionamiento de una aplicación de Microsoft Entra.
- Conceder a la aplicación de Microsoft Entra acceso a la base de datos siguiendo los pasos descritos en Administración de permisos de base de datos de Azure Data Explorer.
Ir a Synapse Studio
En un área de trabajo de Azure Synapse, seleccione Iniciar Synapse Studio. En la página principal de Synapse Studio, seleccione Datos para ir a Data Object Explorer (Explorador de objetos de datos).
Conexión de una base de datos de Azure Data Explorer a un área de trabajo de Azure Synapse
La conexión de una base de datos de Azure Data Explorer a un área de trabajo se realiza mediante un servicio vinculado. Con un servicio vinculado de Azure Data Explorer, puede examinar y explorar datos y leer y escribir en Apache Spark para Azure Synapse. También puede ejecutar trabajos de integración en una canalización.
En Azure Data Explorer, siga estos pasos para conectar directamente un clúster de Azure Data Explorer:
Seleccione el icono + junto a Datos.
Seleccione Conectar para conectarse a datos externos.
Seleccione Azure Data Explorer (Kusto) .
Seleccione Continuar.
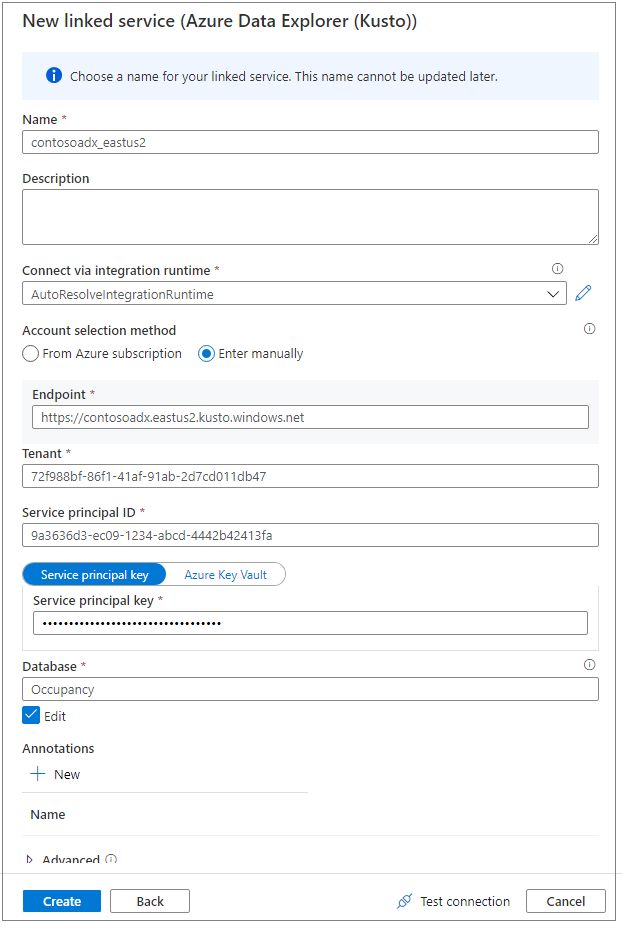
Use un nombre descriptivo para designar al servicio vinculado. El nombre aparecerá en Data Object Explorer (Explorador de objetos de datos) y se usará en los entornos de ejecución de Azure Synapse para conectarse a la base de datos.
Seleccione el clúster de Azure Data Explorer desde su suscripción o escriba el URI.
Escriba el identificador de la entidad de servicio y la clave de la entidad de servicio. Asegúrese de que esta entidad de servicio tenga acceso de vista en la base de datos para la operación de lectura y acceso de ingesta para la ingesta de datos.
Escriba el nombre de la base de datos de Azure Data Explorer.
Seleccione Probar conexión para asegurarse de que tiene los permisos adecuados
Seleccione Crear.
Nota:
(Opcional) La opción Probar conexión no valida el acceso de escritura. Asegúrese de que el identificador de la entidad de servicio tenga acceso de escritura a la base de datos de Azure Data Explorer.
Los clústeres y las bases de datos de Azure Data Explorer aparecen en la pestaña Vinculado de la sección Azure Data Explorer.
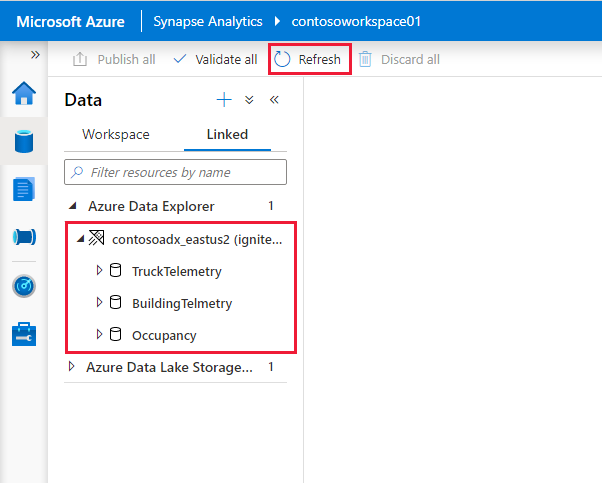
Para poder interactuar con el servicio vinculado desde un cuaderno, debe publicarse en el área de trabajo. Haga clic en Publicar en la barra de herramientas, revise los cambios pendientes y haga clic Aceptar.
Nota:
En la versión actual, los objetos de base de datos se rellenan en función de los permisos de las cuentas de Microsoft Entra en las bases de datos de Azure Data Explorer. Al ejecutar los cuadernos o los trabajos de integración de Apache Spark, se usará la credencial del servicio de vínculo (por ejemplo, la entidad de servicio).
Interacción rápida con las acciones generadas por el código
Al hacer clic con el botón derecho en una base de datos o en una tabla, aparece una lista de cuadernos de Spark de ejemplo. Seleccione una opción para leer o escribir datos en Azure Data Explorer o transmitirlos ahí.

A continuación, se muestra un ejemplo de lectura de datos. Asocie el cuaderno al grupo de Spark y ejecute la celda.

Nota:
La primera ejecución puede tardar más de tres minutos en iniciar la sesión de Spark, pero las siguientes serán mucho más rápidas.
Limitaciones
Actualmente, el conector de Azure Data Explorer no es compatible con redes virtuales de Azure Synapse.