Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Intelligent Cache funciona perfectamente en segundo plano y almacena en caché los datos para ayudar a acelerar la ejecución de Spark a medida que lee desde el lago de datos de ADLS Gen2. También detecta automáticamente los cambios en los archivos subyacentes y actualizará automáticamente los archivos de la memoria caché, lo que le proporcionará los datos más recientes y, cuando el tamaño de la caché alcance su límite, la memoria caché liberará automáticamente los datos menos leídos para hacer espacio para los datos más recientes. Esta característica reduce el costo total de propiedad mejorando el rendimiento hasta 65% en las lecturas posteriores de los archivos almacenados en la caché disponible para archivos Parquet y 50% para archivos CSV.
Al consultar un archivo o una tabla desde el lago de datos, el motor de Apache Spark en Synapse realizará una llamada al almacenamiento remoto de ADLS Gen2 para leer los archivos subyacentes. Con cada solicitud de consulta para leer los mismos datos, el motor de Spark debe realizar una llamada al almacenamiento remoto de ADLS Gen2. Este proceso redundante agrega latencia al tiempo total de procesamiento. Spark proporciona una característica de almacenamiento en caché que debe establecer manualmente la memoria caché y liberarla para minimizar la latencia y mejorar el rendimiento general. Sin embargo, esto puede hacer que los resultados tengan datos obsoletos si los datos subyacentes cambian.
Synapse Intelligent Cache simplifica este proceso almacenando en caché automáticamente cada lectura dentro del espacio de almacenamiento de caché asignado en cada nodo de Spark. Cada solicitud de un archivo comprobará si el archivo existe en la memoria caché y comparará la etiqueta del almacenamiento remoto para determinar si el archivo está obsoleto. Si el archivo no existe o si el archivo está obsoleto, Spark leerá el archivo y lo almacenará en la memoria caché. Cuando la caché se llena, el archivo con la hora de último acceso más antigua se expulsará de la memoria caché para permitir archivos más recientes.
La caché de Synapse es una sola caché por nodo. Si usa un nodo de tamaño mediano y se ejecuta con dos ejecutores pequeños en un único nodo de tamaño mediano, estos dos ejecutores compartirían la misma caché.
Habilitar o deshabilitar la memoria caché
El tamaño de caché se puede ajustar en función del porcentaje del tamaño total del disco disponible para cada grupo de Apache Spark. De forma predeterminada, la memoria caché está establecida en deshabilitada, pero es tan fácil como mover la barra deslizante de 0 (deshabilitada) al porcentaje deseado para que el tamaño de la caché lo habilite. Reservamos un mínimo de 20% de espacio en disco disponible para los orden aleatorios de datos. Para cargas de trabajo intensivas de orden aleatorio, puede minimizar el tamaño de la memoria caché o deshabilitar la memoria caché. Se recomienda comenzar con un tamaño de caché de 50% y ajustar según sea necesario. Es importante tener en cuenta que si la carga de trabajo requiere una gran cantidad de espacio en disco en la SSD local para el almacenamiento en caché de RDD o orden aleatorio, considere la posibilidad de reducir el tamaño de la memoria caché para reducir la posibilidad de error debido a un almacenamiento insuficiente. El tamaño real del almacenamiento disponible y el tamaño de caché de cada nodo dependerán de la familia de nodos y el tamaño del nodo.
Habilitación de la caché para nuevos grupos de Spark
Al crear un nuevo grupo de Spark, busque en la pestaña configuración adicional para encontrar el control deslizante caché inteligente que puede pasar al tamaño preferido para habilitar la característica.

Habilitación o deshabilitación de la caché para grupos de Spark existentes
En el caso de los grupos de Spark existentes, vaya a la configuración de escalado del grupo de Apache Spark que prefiera para habilitarlo, moviendo el control deslizante a un valor superior a 0 o deshabilítelo moviendo el control deslizante a 0.
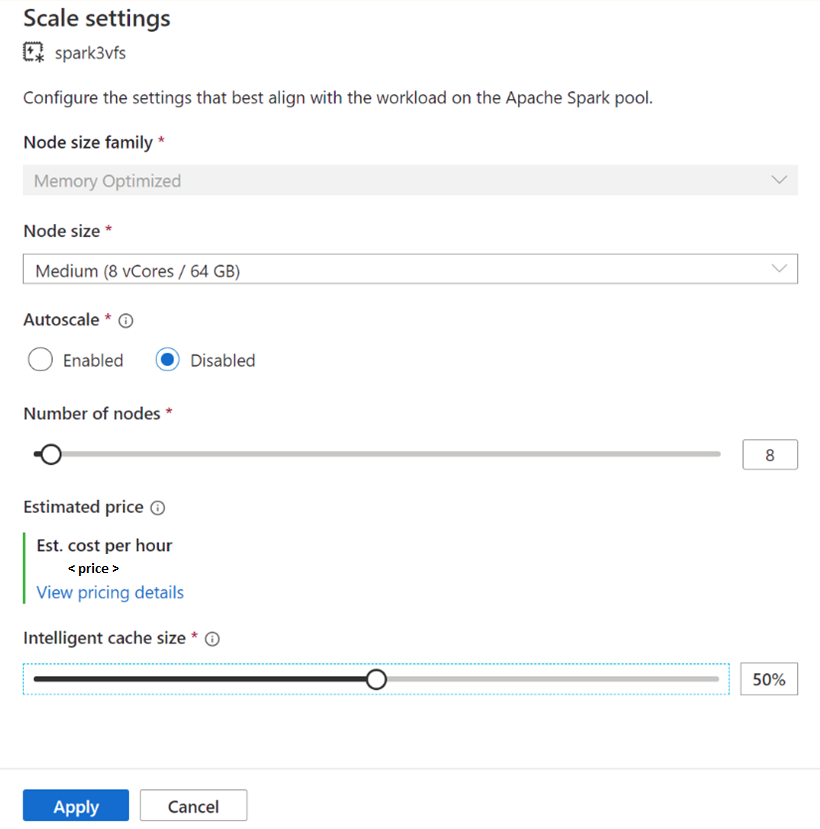
Cambio del tamaño de caché de los grupos de Spark existentes
Para cambiar el tamaño de caché inteligente de un grupo, debe forzar un reinicio si el grupo tiene sesiones activas. Si el grupo de Spark tiene una sesión activa, se mostrará Forzar nueva configuración. Haga clic en la casilla y seleccione Aplicar para reiniciar automáticamente la sesión.

Habilitación y deshabilitación de la memoria caché dentro de la sesión
Para deshabilitar fácilmente la caché inteligente en una sesión, ejecute el código siguiente en el cuaderno:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "false")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'false')
Y habilite mediante la ejecución de:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "true")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'true')
¿Cuándo usar la caché inteligente y cuándo no?
Esta característica le beneficiará si:
La carga de trabajo requiere leer el mismo archivo varias veces y el tamaño del archivo puede caber en la memoria caché.
La carga de trabajo usa tablas Delta, formatos de archivo parquet y archivos CSV.
Usa Apache Spark 3 o posterior en Azure Synapse.
No verá la ventaja de esta característica si:
Está leyendo un archivo que supere el tamaño de la caché porque el principio de los archivos se podría expulsar y las consultas posteriores tendrán que volver a capturar los datos desde el almacenamiento remoto. En este caso, no verá ninguna ventaja de Intelligent Cache y es posible que desee aumentar el tamaño de la memoria caché o el tamaño del nodo.
La carga de trabajo requiere grandes cantidades de orden aleatorio y, a continuación, deshabilitar la caché inteligente liberará espacio disponible para evitar que el trabajo produzca errores debido a un espacio de almacenamiento insuficiente.
Va a usar un grupo de Spark 3.3, deberá actualizar el grupo a la versión más reciente de Spark.
Aprende más
Para más información sobre Apache Spark, consulte los siguientes artículos:
- ¿Qué es Apache Spark?
- Conceptos básicos de Apache Spark
- Configuraciones y tamaños del grupo de Apache Spark
Para obtener información sobre cómo configurar las opciones de sesión de Spark
- Configuración de las opciones de sesión de Spark
- Establecimiento de configuraciones personalizadas de Spark/Pyspark
Pasos siguientes
Un grupo de Apache Spark proporciona funcionalidades de proceso de macrodatos de código abierto donde los datos se pueden cargar, modelar, procesar y distribuir para obtener información analítica más rápida. Para más información sobre cómo crear una para ejecutar las cargas de trabajo de Spark, visite los siguientes tutoriales: