Tutorial: Creación de una definición de trabajo de Apache Spark en Synapse Studio
En este tutorial se muestra cómo usar Synapse Studio para crear definiciones de trabajos de Apache Spark y enviarlas luego a un grupo de Apache Spark sin servidor.
En este tutorial se describen las tareas siguientes:
- Creación de una definición de trabajo de Apache Spark para PySpark (Python)
- Creación de una definición de trabajo de Apache Spark para Spark (Scala)
- Creación de una definición de trabajo de Apache Spark para .NET Spark (C#/F#)
- Creación de una definición de trabajo mediante la importación de un archivo JSON
- Exportación de un archivo de definición de trabajo de Apache Spark a local
- Envío de una definición de trabajo de Apache Spark como un trabajo por lotes
- Adición de una definición de trabajo de Apache Spark en la canalización
Requisitos previos
Antes de comenzar este tutorial, asegúrese de que se cumplen los requisitos siguientes:
- Un área de trabajo de Azure Synapse Analytics. Para obtener instrucciones, consulte Creación de un área de trabajo de Azure Synapse Analytics.
- Un grupo de Apache Spark sin servidor.
- Una cuenta de almacenamiento de ADLS Gen2. Debe tener el rol Colaborador de datos de Storage Blob en el sistema de archivos de ADLS Gen2 con el que quiere trabajar. Si no lo es, debe agregar el permiso manualmente.
- Si no desea usar el almacenamiento predeterminado del área de trabajo, vincule la cuenta de almacenamiento de ADLS Gen2 necesaria en Synapse Studio.
Creación de una definición de trabajo de Apache Spark para PySpark (Python)
En esta sección, creará una definición de trabajo de Apache Spark para PySpark (Python).
Abra Synapse Studio.
Puede ir a Sample files for creating Apache Spark job definitions (Archivos de ejemplo de creación de definiciones de trabajo en Apache Spark) para descargar archivos de ejemplo para python.zip; después, descomprima el paquete y extraiga los archivos wordcount.py y shakespeare.txt.
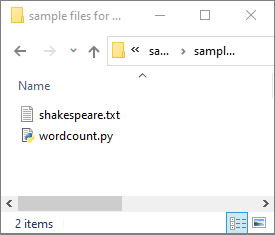
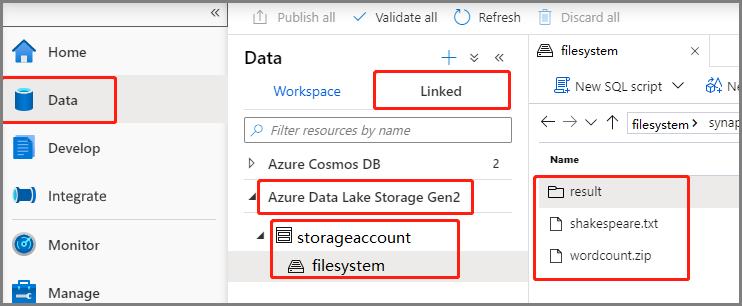
Seleccione Data ->Linked ->Azure Data Lake Storage Gen2 (Datos > Vinculados > Azure Data Lake Storage Gen2) y cargue wordcount.py y shakespeare.txt en el sistema de archivos de ADLS Gen2.
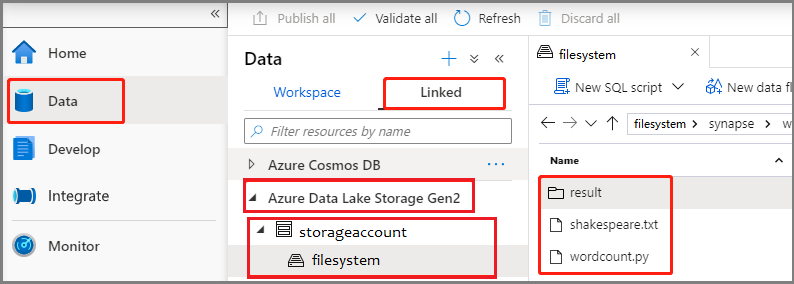
Seleccione el centro de conectividad Develop (Desarrollar), elija el icono "+" y seleccione Spark job definition (Definición de trabajo de Spark) para crear una definición de trabajo de Spark.
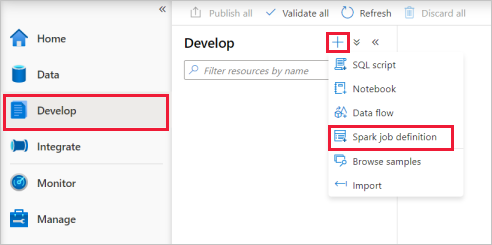
Seleccione PySpark (Python) en la lista desplegable de lenguajes de la ventana principal de definiciones de trabajos de Apache Spark.
Rellene la información de la definición de trabajo de Apache Spark.
Propiedad Descripción Job definition name (Nombre de la definición de trabajo) Proporcione un nombre para la definición de trabajo de Apache Spark. Este nombre se puede actualizar en cualquier momento hasta que se publique.
Ejemplo:job definition sampleMain definition file (Archivo de definición principal) Archivo principal usado para el trabajo. Seleccione un archivo PY en el almacenamiento. Puede seleccionar Upload file (Cargar archivo) para cargar un archivo en una cuenta de almacenamiento.
Ejemplo:abfss://…/path/to/wordcount.pyArgumentos de la línea de comandos Argumentos opcionales del trabajo.
Ejemplo:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Nota: Los argumentos de la definición de trabajo de ejemplo se separan mediante un espacio.Reference files (Archivos de referencia) Archivos adicionales usados como referencia en el archivo de definición principal. Puede seleccionar Upload file (Cargar archivo) para cargar un archivo en una cuenta de almacenamiento. Grupo de Spark El trabajo se enviará al grupo de Apache Spark seleccionado. Versión de Spark Versión de Apache Spark que ejecuta el grupo de Apache Spark. Ejecutores Número de ejecutores que se van a proporcionar en el grupo de Apache Spark especificado para el trabajo. Executor size (Tamaño del ejecutor) Número de núcleos y memoria que se van a usar para los ejecutores proporcionados en el grupo de Apache Spark especificado para el trabajo. Driver size (Tamaño del controlador) Número de núcleos y memoria que se van a usar para el controlador proporcionado en el grupo de Apache Spark especificado para el trabajo. Configuración de Apache Spark Personalice las configuraciones agregando las propiedades siguientes. Si no agrega ninguna propiedad, Azure Synapse usará el valor predeterminado cuando corresponda. 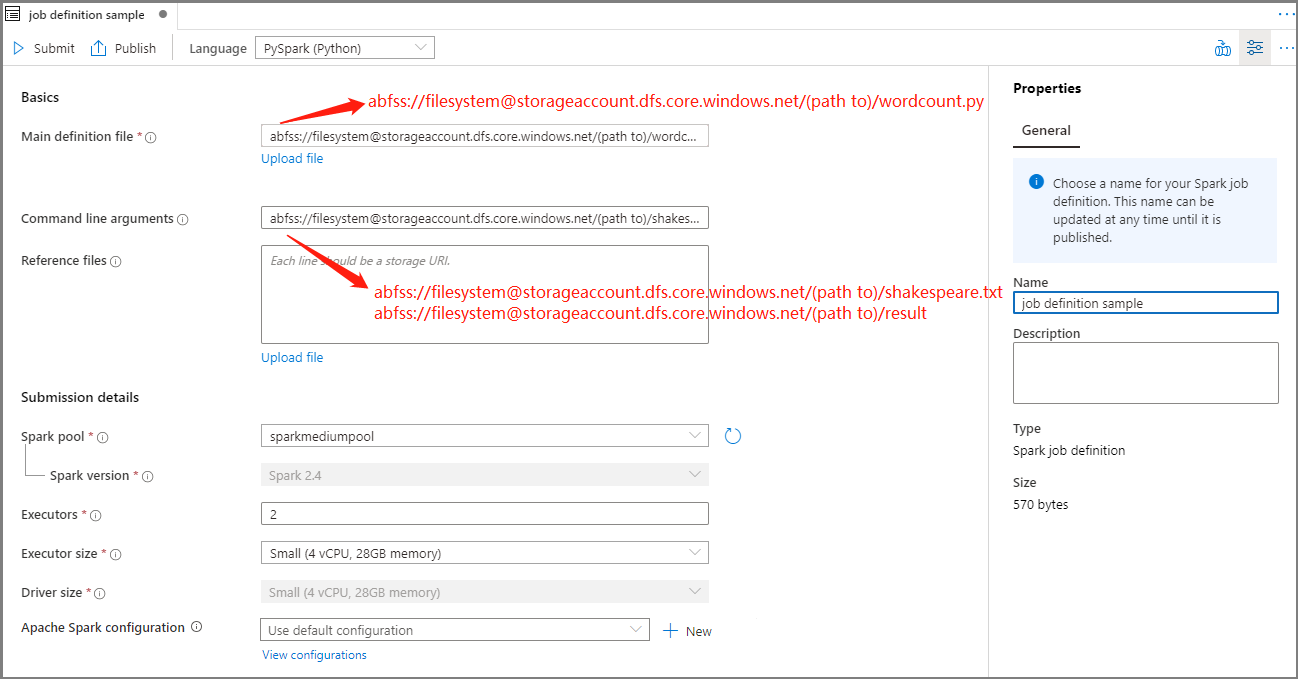
Seleccione Publicar para guardar la definición de trabajo de Apache Spark.

Creación de una definición de trabajo de Apache Spark para Apache Spark (Scala)
En esta sección, creará una definición de trabajo de Apache Spark para Apache Spark (Scala).
Abra Azure Synapse Studio.
Puede ir a Sample files for creating Apache Spark job definitions (Archivos de ejemplo de creación de definiciones de trabajo en Apache Spark) para descargar archivos de ejemplo para scala.zip; después, descomprima el paquete y extraiga los archivos wordcount.jar y shakespeare.txt.
Seleccione Data ->Linked ->Azure Data Lake Storage Gen2 (Datos > Vinculados > Azure Data Lake Storage Gen2) y cargue wordcount.jar y shakespeare.txt en el sistema de archivos de ADLS Gen2.
Seleccione el centro de conectividad Develop (Desarrollar), elija el icono "+" y seleccione Spark job definition (Definición de trabajo de Spark) para crear una definición de trabajo de Spark. (La imagen de ejemplo es la misma que la del paso 4 de Creación de una definición de trabajo de Apache Spark [Python] para PySpark).
Seleccione Spark (Scala) en la lista desplegable de lenguajes de la ventana principal de definiciones de trabajos de Apache Spark.
Rellene la información de la definición de trabajo de Apache Spark. Puede copiar la información de ejemplo.
Propiedad Descripción Job definition name (Nombre de la definición de trabajo) Proporcione un nombre para la definición de trabajo de Apache Spark. Este nombre se puede actualizar en cualquier momento hasta que se publique.
Ejemplo:scalaMain definition file (Archivo de definición principal) Archivo principal usado para el trabajo. Seleccione un archivo JAR del almacenamiento. Puede seleccionar Upload file (Cargar archivo) para cargar un archivo en una cuenta de almacenamiento.
Ejemplo:abfss://…/path/to/wordcount.jarNombre de clase principal Identificador completo o clase principal que se encuentra en el archivo de definición principal.
Ejemplo:WordCountArgumentos de la línea de comandos Argumentos opcionales del trabajo.
Ejemplo:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Nota: Los argumentos de la definición de trabajo de ejemplo se separan mediante un espacio.Reference files (Archivos de referencia) Archivos adicionales usados como referencia en el archivo de definición principal. Puede seleccionar Upload file (Cargar archivo) para cargar un archivo en una cuenta de almacenamiento. Grupo de Spark El trabajo se enviará al grupo de Apache Spark seleccionado. Versión de Spark Versión de Apache Spark que ejecuta el grupo de Apache Spark. Ejecutores Número de ejecutores que se van a proporcionar en el grupo de Apache Spark especificado para el trabajo. Executor size (Tamaño del ejecutor) Número de núcleos y memoria que se van a usar para los ejecutores proporcionados en el grupo de Apache Spark especificado para el trabajo. Driver size (Tamaño del controlador) Número de núcleos y memoria que se van a usar para el controlador proporcionado en el grupo de Apache Spark especificado para el trabajo. Configuración de Apache Spark Personalice las configuraciones agregando las propiedades siguientes. Si no agrega ninguna propiedad, Azure Synapse usará el valor predeterminado cuando corresponda. 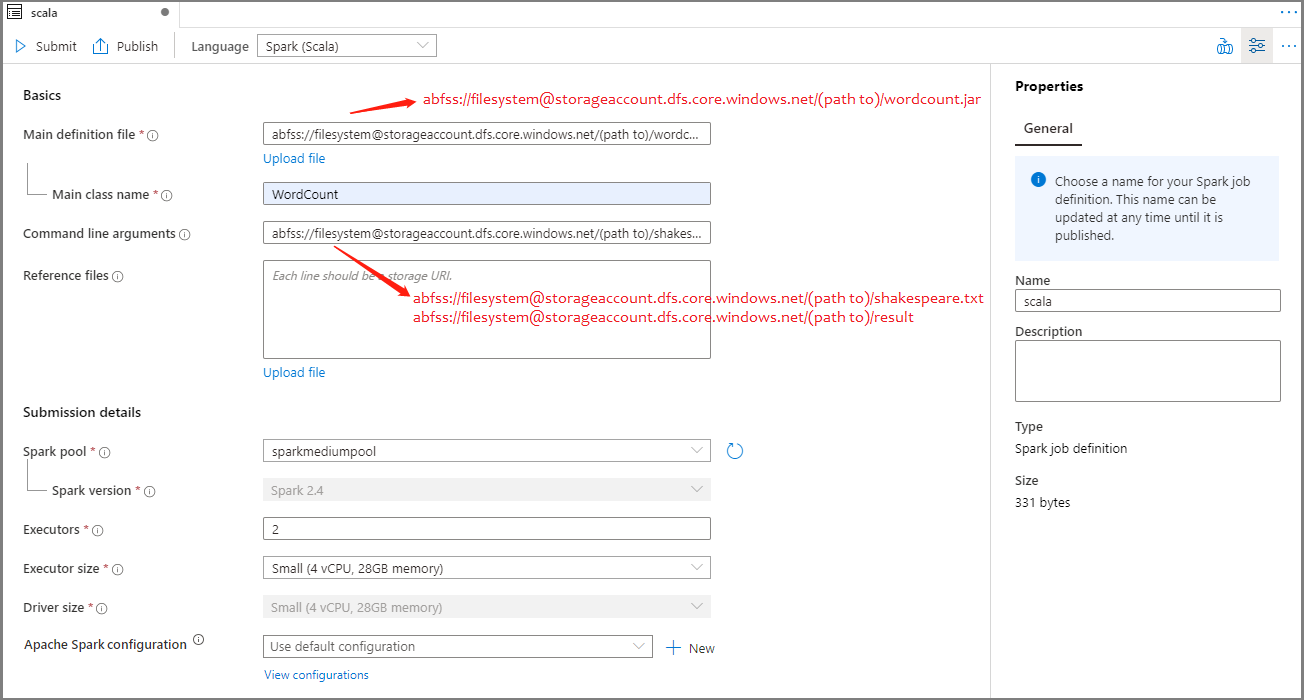
Seleccione Publicar para guardar la definición de trabajo de Apache Spark.

Creación de una definición de trabajo de Apache Spark para .NET Spark (C#/F#)
En esta sección, creará una definición de trabajo de Apache Spark para .NET Spark (C#/F#).
Abra Azure Synapse Studio.
Puede ir a Sample files for creating Apache Spark job definitions (Archivos de ejemplo de creación de definiciones de trabajo en Apache Spark) para descargar archivos de ejemplo para dotnet.zip; después, descomprima el paquete y extraiga los archivos wordcount.zip y shakespeare.txt.
Seleccione Data ->Linked ->Azure Data Lake Storage Gen2 (Datos > Vinculados > Azure Data Lake Storage Gen2) y cargue wordcount.zip y shakespeare.txt en el sistema de archivos de ADLS Gen2.
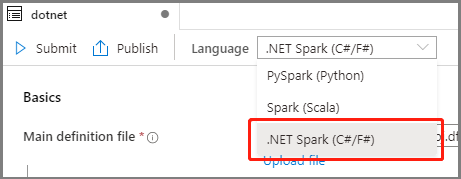
Seleccione el centro de conectividad Develop (Desarrollar), elija el icono "+" y seleccione Spark job definition (Definición de trabajo de Spark) para crear una definición de trabajo de Spark. (La imagen de ejemplo es la misma que la del paso 4 de Creación de una definición de trabajo de Apache Spark [Python] para PySpark).
Seleccione .NET Spark(C#/F#) en la lista desplegable de lenguajes de la ventana principal de definición de trabajos de Apache Spark.
Rellene la información de la definición de trabajo de Apache Spark. Puede copiar la información de ejemplo.
Propiedad Descripción Job definition name (Nombre de la definición de trabajo) Proporcione un nombre para la definición de trabajo de Apache Spark. Este nombre se puede actualizar en cualquier momento hasta que se publique.
Ejemplo:dotnetMain definition file (Archivo de definición principal) Archivo principal usado para el trabajo. Seleccione un archivo ZIP que contenga la aplicación .NET para Apache Spark (es decir, el archivo ejecutable principal, los archivos DLL que contienen las funciones definidas por el usuario y otros archivos necesarios) del almacenamiento. Puede seleccionar Upload file (Cargar archivo) para cargar un archivo en una cuenta de almacenamiento.
Ejemplo:abfss://…/path/to/wordcount.zipMain executable file (Archivo ejecutable principal) Archivo ejecutable principal del archivo ZIP de la definición principal.
Ejemplo:WordCountArgumentos de la línea de comandos Argumentos opcionales del trabajo.
Ejemplo:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
Nota: Los argumentos de la definición de trabajo de ejemplo se separan mediante un espacio.Reference files (Archivos de referencia) Archivos adicionales necesarios para que los nodos de trabajo ejecuten la aplicación de .NET para Apache Spark y que no se incluyen en el archivo ZIP de la definición principal (es decir, archivos JAR dependientes, archivos DLL adicionales de funciones definidas por el usuario y otros archivos de configuración). Puede seleccionar Upload file (Cargar archivo) para cargar un archivo en una cuenta de almacenamiento. Grupo de Spark El trabajo se enviará al grupo de Apache Spark seleccionado. Versión de Spark Versión de Apache Spark que ejecuta el grupo de Apache Spark. Ejecutores Número de ejecutores que se van a proporcionar en el grupo de Apache Spark especificado para el trabajo. Executor size (Tamaño del ejecutor) Número de núcleos y memoria que se van a usar para los ejecutores proporcionados en el grupo de Apache Spark especificado para el trabajo. Driver size (Tamaño del controlador) Número de núcleos y memoria que se van a usar para el controlador proporcionado en el grupo de Apache Spark especificado para el trabajo. Configuración de Apache Spark Personalice las configuraciones agregando las propiedades siguientes. Si no agrega ninguna propiedad, Azure Synapse usará el valor predeterminado cuando corresponda. 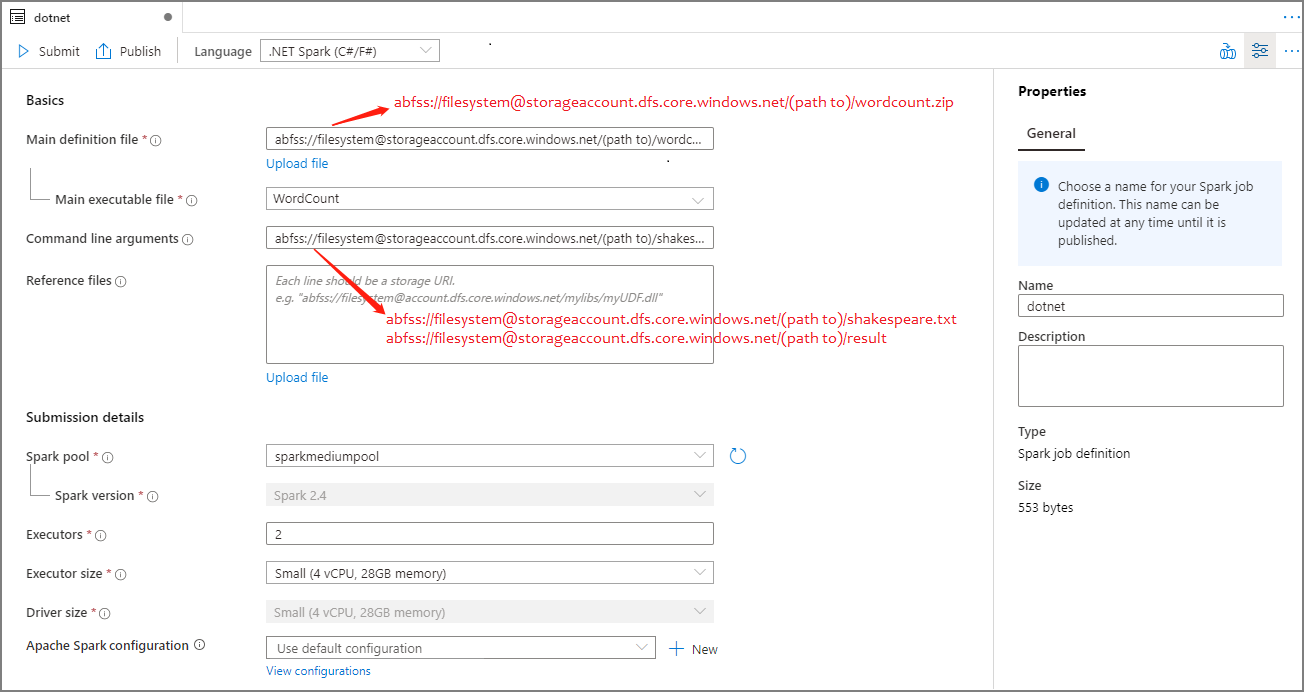
Seleccione Publicar para guardar la definición de trabajo de Apache Spark.

Nota
Para la configuración de Apache Spark, si la definición de trabajo de Apache Spark no hace nada especial, se usará la configuración predeterminada al ejecutar el trabajo.
Creación de una definición de trabajo de Apache Spark mediante la importación de un archivo JSON
Puede importar un archivo JSON local existente en el área de trabajo de Azure Synapse desde el menú Actions (Acciones) (...) del explorador de definiciones de trabajo de Apache Spark para crear una nueva definición de trabajo de Apache Spark.
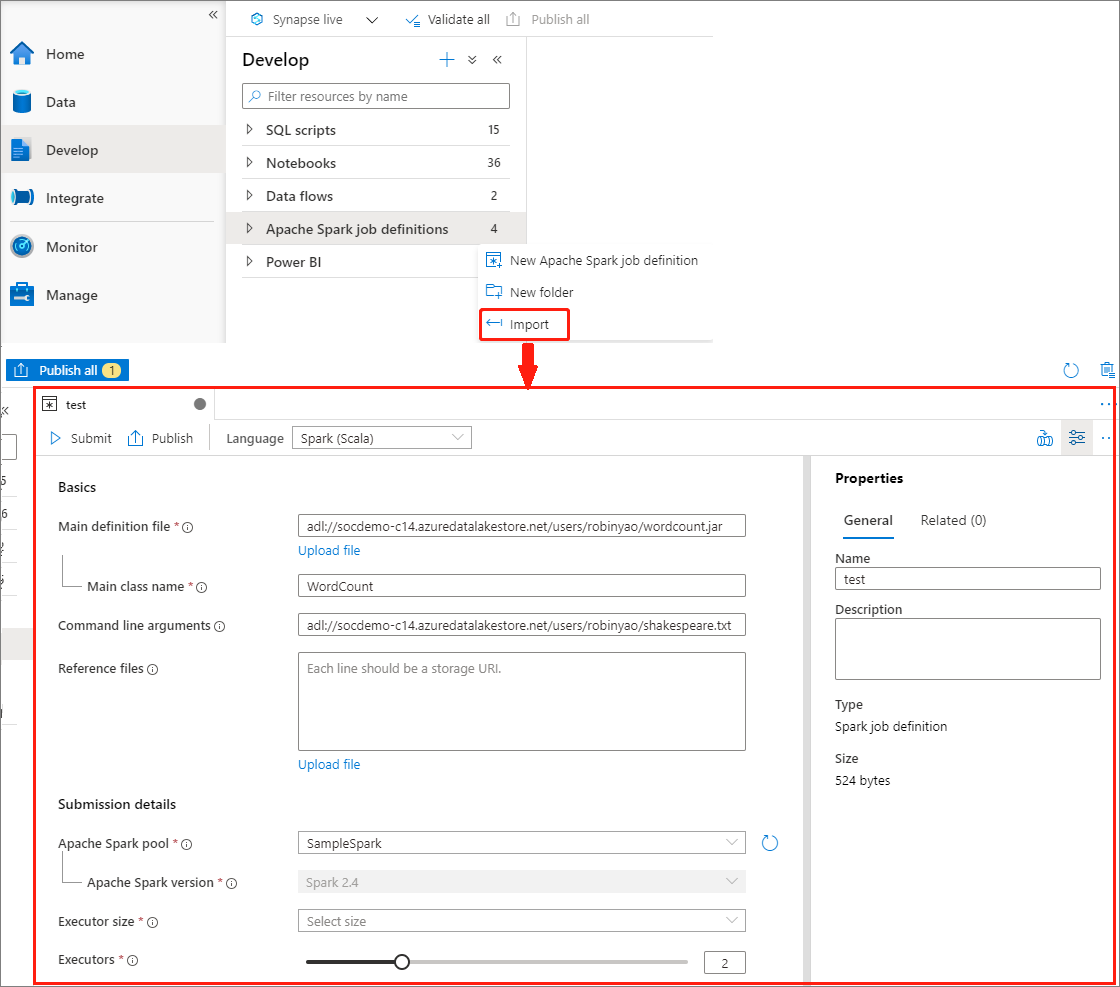
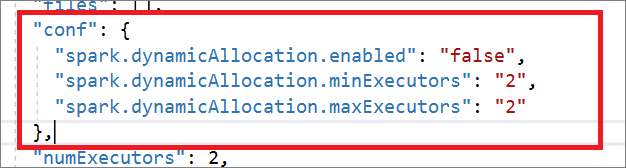
La definición de trabajo de Spark es totalmente compatible con Livy API. Puede agregar parámetros adicionales a otras propiedades de Livy (Documentos de Livy - AP REST [apache.org]) en el archivo JSON local. También puede especificar los parámetros relacionados con la configuración de Spark en la propiedad de configuración, como se muestra a continuación. Después, puede importar el archivo JSON de nuevo para crear una nueva definición de trabajo de Apache Spark para el trabajo por lotes. Ejemplo de JSON para la importación de definiciones de Spark:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
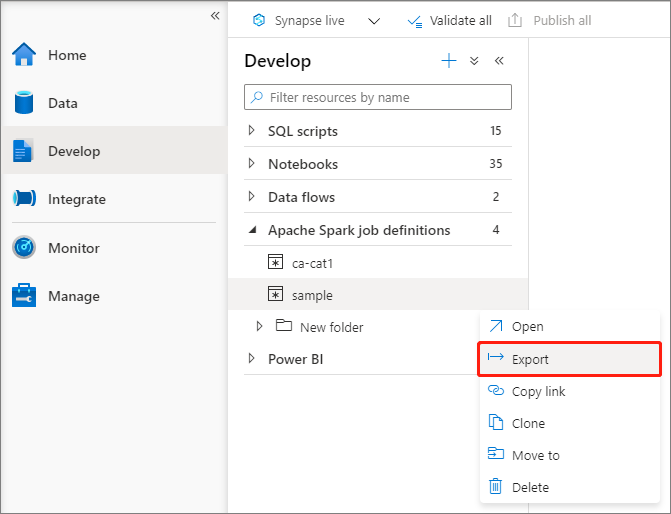
Abra una definición de trabajo de Apache Spark existente.
Puede exportar los archivos de definición de trabajo de Apache Spark existentes al menú local desde el menú Actions (Acciones) (...) del Explorador de archivos. Puede seguir actualizando el archivo JSON para las propiedades adicionales de Livy, e importarlo de nuevo para crear una nueva definición de trabajo si fuera necesario.
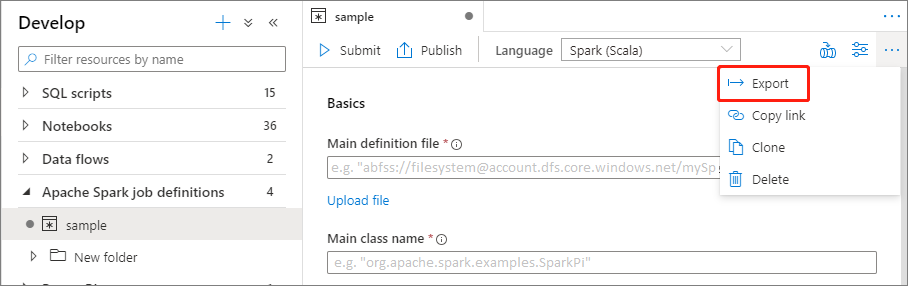
Envío de una definición de trabajo de Apache Spark como un trabajo por lotes
Después de crear una definición de trabajo de Apache Spark, puede enviarla a un grupo de Apache Spark. Asegúrese de tener el rol Colaborador de datos de Storage Blob en el sistema de archivos de ADLS Gen2 con el que quiere trabajar. Si no lo es, debe agregar el permiso manualmente.
Escenario 1: Envío de la definición de trabajo de Apache Spark
Seleccione una ventana de definición de trabajo de Apache Spark para abrirla.
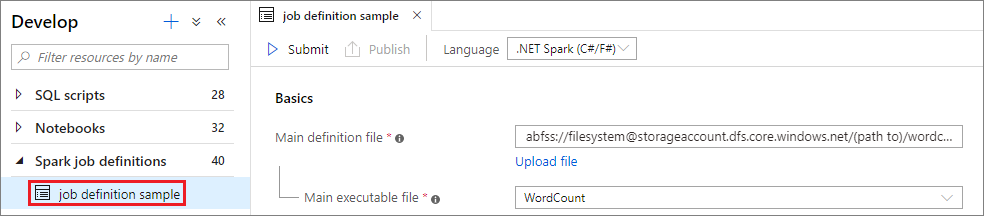
Seleccione el botón Enviar para enviar el proyecto al grupo de Apache Spark seleccionado. Puede seleccionar la pestaña Spark monitoring URL (Dirección URL de supervisión de Spark) para ver la consulta de registro de la aplicación de Apache Spark.
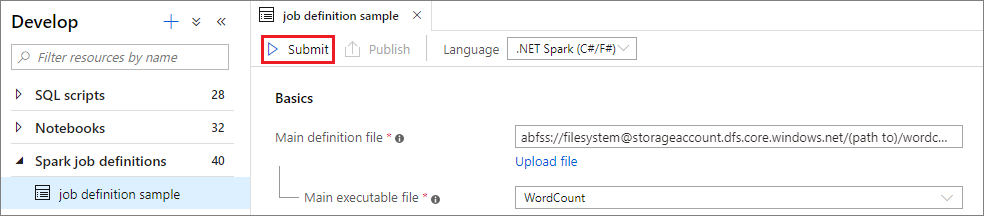
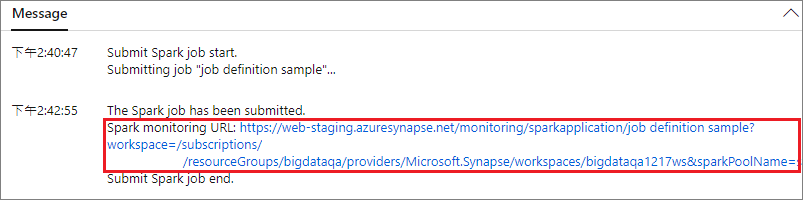
Escenario 2: Visualización del progreso de ejecución del trabajo de Apache Spark
Seleccione Monitor (Supervisar) y elija la opción Apache Spark applications (Aplicaciones de Apache Spark). Podrá encontrar la aplicación de Apache Spark enviada.
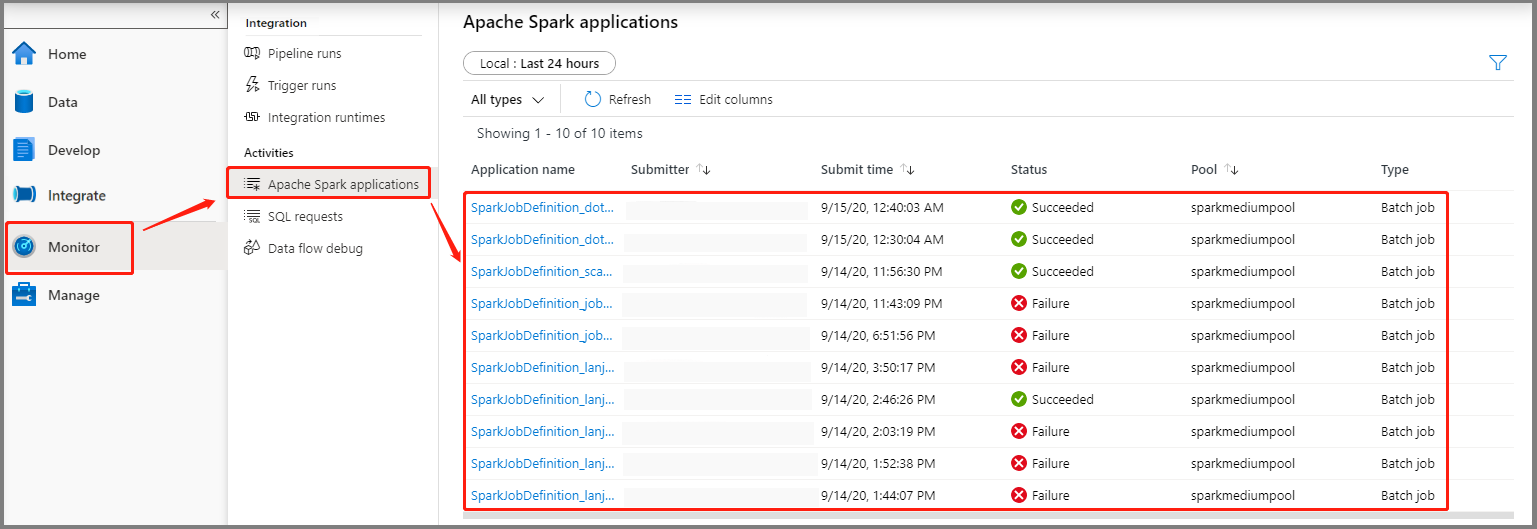
A continuación, haga clic en una aplicación de Apache Spark y se mostrará la ventana del trabajo SparkJobDefinition. Puede ver el progreso del trabajo desde aquí.
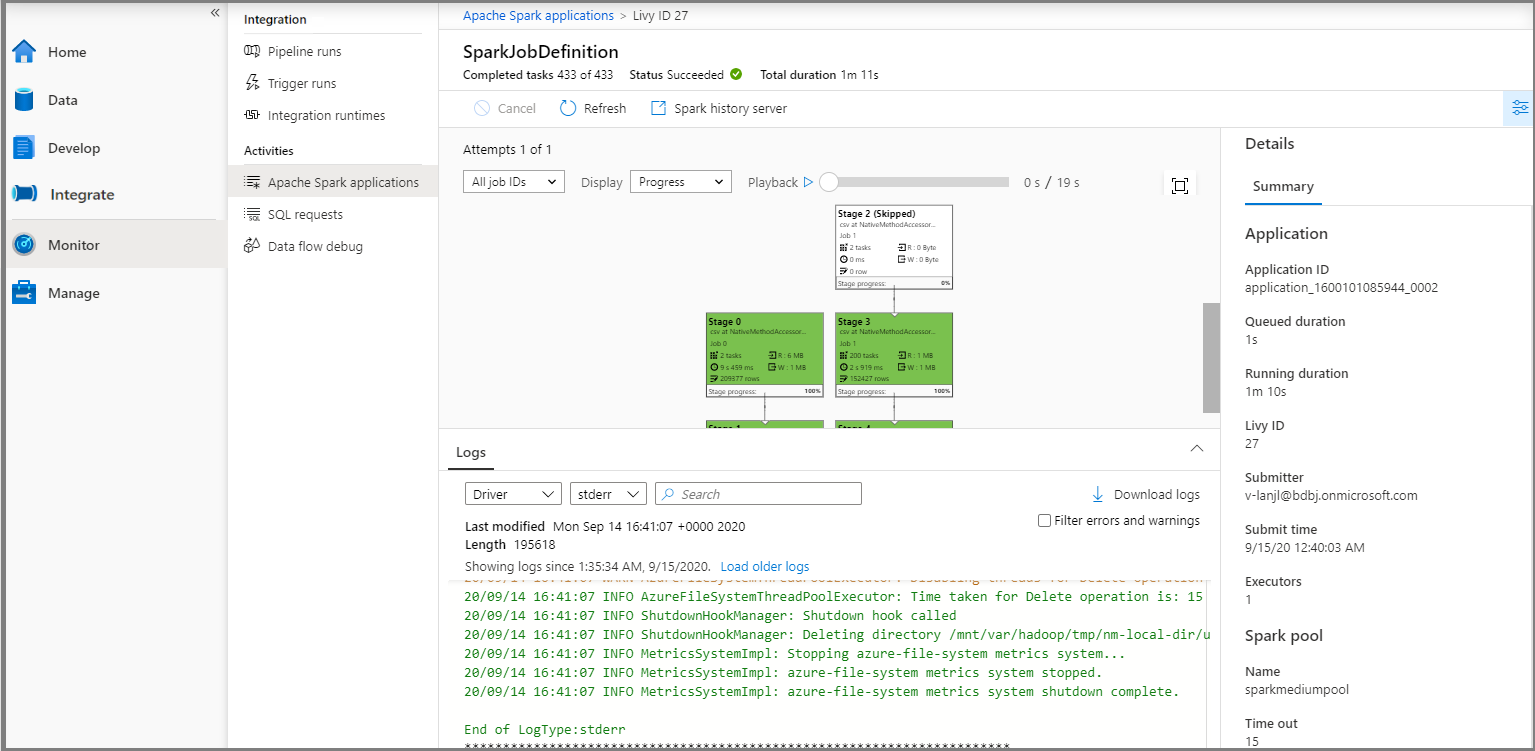
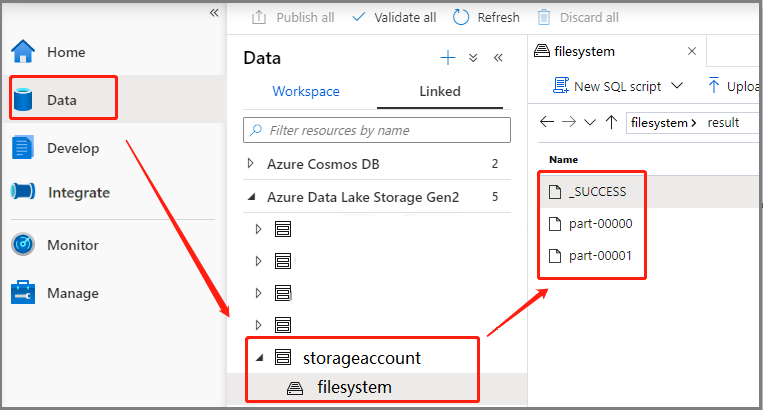
Escenario 3: Comprobación del archivo de salida
Seleccione Data ->Linked ->Azure Data Lake Storage Gen2 (Datos > Vinculados > Azure Data Lake Storage Gen2) (hozhaobdbj), abra la carpeta de resultados que se creó anteriormente. Podrá ir a esta carpeta y comprobar si se generó la salida.
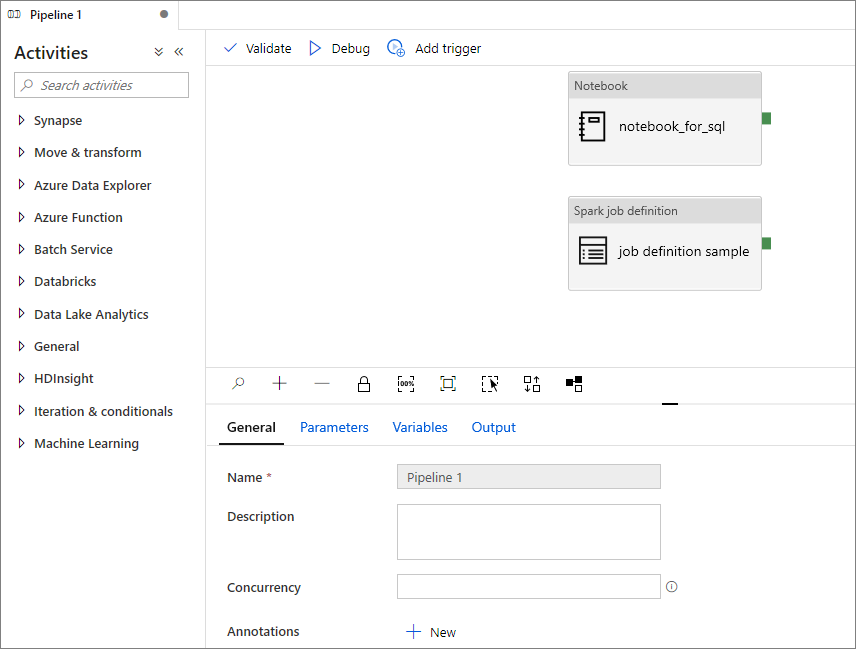
Adición de una definición de trabajo de Apache Spark en la canalización
En esta sección, agregará una definición de trabajo de Apache Spark en la canalización.
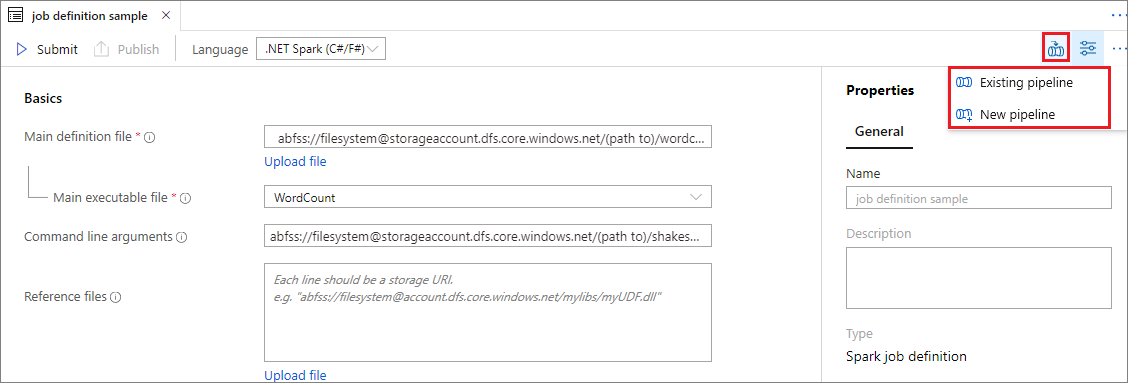
Abra una definición de trabajo de Apache Spark existente.
Seleccione el icono de la parte superior derecha de la definición de trabajo de Apache Spark, elija Existing Pipeline (Canalización existente) o New pipeline (Nueva canalización). Puede consultar la página Pipeline (Canalización) para más información.
Pasos siguientes
Luego, puede usar Azure Synapse Studio para crear conjuntos de datos de Power BI y administrar los datos de Power BI. Avance al artículo Vinculación de un área de trabajo de Power BI a un área de trabajo de Synapse para obtener más información.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de