Optimización de trabajos de Apache Spark en Azure Synapse Analytics
Aprenda a optimizar una configuración de los clústeres de Apache Spark para su carga de trabajo específica. La mayor dificultad es la presión de memoria, debido a las configuraciones inadecuadas (en especial, al tamaño incorrecto de los ejecutores), las operaciones de ejecución prolongada y las tareas que dan lugar a operaciones cartesianas. Los trabajos se pueden acelerar con el almacenamiento en caché adecuado y permitiendo la asimetría de datos. Para obtener el mejor rendimiento, supervise y revise las ejecuciones de trabajos de Spark de ejecución prolongada y que consumen muchos recursos.
En las siguientes secciones se describen las recomendaciones y optimizaciones comunes de trabajos de Spark.
Selección de la abstracción de datos
Las versiones anteriores de Spark usan RDD para abstraer datos; Spark 1.3 y 1.6 introdujeron DataFrames y DataSets, respectivamente. Tenga en cuenta las siguientes ventajas relativas:
- DataFrames
- La mejor opción en la mayoría de los casos.
- Proporciona optimización de consultas gracias a Catalyst.
- Generación de código en tiempo de ejecución.
- Acceso directo a memoria.
- Baja sobrecarga de recolección de elementos no utilizados (GC).
- No es tan sencillo para los desarrolladores como DataSets, dado que no hay comprobaciones en tiempo de compilación ni programación de objetos de dominio.
- DataSets
- Adecuado en canalizaciones ETL complejas en las que el impacto sobre el rendimiento es aceptable.
- No adecuado en agregaciones donde el impacto sobre el rendimiento puede ser considerable.
- Proporciona optimización de consultas gracias a Catalyst.
- Es sencillo de usar para los programadores al proporcionar programación de objetos de dominio y comprobaciones de tiempo de compilación.
- Agrega sobrecarga de serialización/deserialización.
- Gran sobrecarga de GC.
- Interrumpe la generación de código en tiempo de ejecución.
- RDD
- No es necesario usar RDD, a menos que deba crear un nuevo RDD personalizado.
- Sin optimización de consultas mediante Catalyst.
- Sin generación de código en tiempo de ejecución.
- Gran sobrecarga de GC.
- Se deben usar las API heredadas de Spark 1.x.
Uso del formato de datos óptimo
Spark admite muchos formatos, como csv, json, xml, parquet, orc y avro. Spark se puede ampliar para la compatibilidad con muchos más formatos con orígenes de datos externos; para más información, consulte los paquetes de Apache Spark.
El mejor formato para el rendimiento es parquet con compresión eficiente, que es el valor predeterminado en Spark 2.x. Parquet almacena datos en formato de columnas y está muy optimizado en Spark. Además, la compresión eficiente puede dar lugar a archivos más grandes que la compresión con GZIP. Debido a la naturaleza divisible de esos archivos, se descomprimen más rápido.
Uso de la caché
Spark proporciona sus propios mecanismos nativos de almacenamiento, que se pueden usar a través de diferentes métodos, como .persist(), .cache() y CACHE TABLE. Este almacenamiento en caché nativo es efectivo con pequeños conjuntos de datos, así como en canalizaciones ETL donde tenga que almacenar en caché los resultados intermedios. Sin embargo, el almacenamiento en caché nativo de Spark no funciona bien actualmente con la creación de particiones, dado que la tabla almacenada en caché no conserva los datos de la creación de particiones.
Uso eficiente de memoria
Spark funciona mediante la colocación de datos en memoria, por lo que administrar los recursos de memoria es un aspecto importante de la optimización de la ejecución de trabajos de Spark. Hay varias técnicas que puede aplicar para usar la memoria del clúster de manera eficaz.
Elija particiones de datos más pequeñas y tenga en cuenta el tamaño de los datos, los tipos y la distribución en su estrategia de creación de particiones.
En Synapse Spark (Runtime 3.1 o superior), la serialización de datos Kryo está habilitada de forma predeterminada.
Puede personalizar el tamaño del búfer del krioserializador mediante la configuración de Spark en función de los requisitos de carga de trabajo:
// Set the desired property spark.conf.set("spark.kryoserializer.buffer.max", "256m")Supervise y ajuste los valores de configuración de Spark.
Para que le sirva de referencia, en la imagen siguiente se muestran la estructura de memoria de Spark y algunos parámetros de memoria de ejecutores principales.
Consideraciones de memoria de Spark
Apache Spark en Azure Synapse emplea YARN (Apache Hadoop YARN); YARN controla la suma máxima de memoria usada por todos los contenedores de cada nodo de Spark. En el diagrama siguiente se muestran los objetos principales y sus relaciones.
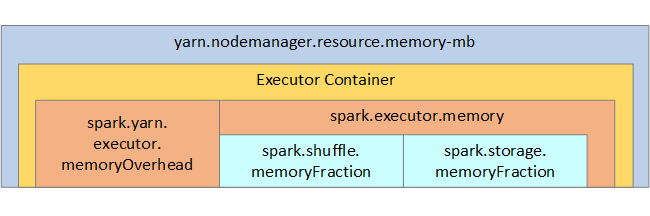
Para resolver los mensajes de falta de memoria, intente lo siguiente:
- Revise los órdenes aleatorios de administración de DAG. Reduzca en el lado de asignación, cree particiones previas (o depósitos) de los datos de origen, maximice los órdenes aleatorios únicos y disminuya la cantidad de datos enviados.
- Elija
ReduceByKey, con su límite fijo de memoria, antes queGroupByKey, que proporciona agregaciones, ventanas y otras funciones, pero que tiene un límite de memoria no enlazado. - Elija
TreeReduce, que realiza más trabajo en los ejecutores o particiones, antes queReduce, que hace todo el trabajo en el controlador. - Aproveche DataFrames en lugar de los objetos RDD de nivel inferior.
- Cree ComplexTypes que encapsulan acciones, como "N principales", diversas agregaciones u operaciones de ventanas.
Optimización de la serialización de datos
Los trabajos de Spark son distribuidos, así que es importante la serialización adecuada de los datos para obtener el mejor rendimiento. Hay dos opciones de serialización para Spark:
- Serialización de Java
- La serialización Kryo es la predeterminada. Es un formato más reciente y puede dar como resultado una serialización más rápida y compacta que la de Java. Kryo requiere que se registren las clases en el programa y aún no admite todos los tipos serializables.
Uso de la creación de depósitos
Crear depósitos es parecido a crear particiones de datos, pero cada depósito puede contener un conjunto de valores de columna en lugar de una sola. La creación de depósitos funciona bien cuando se crean particiones en números grandes de valores (millones o más), como es el caso de los identificadores de productos. Para determinar un depósito, se usa hash en la clave de depósito de la fila. Las tablas en depósitos ofrecen optimizaciones únicas porque almacenan metadatos sobre cómo se incluyeron en depósitos y se ordenaron.
Algunas características avanzadas de creación de depósitos son:
- Optimización de consultas basada en la creación de depósitos de información de metadatos.
- Agregaciones optimizadas.
- Combinaciones optimizadas.
Puede usar creación de particiones y creación de depósitos al mismo tiempo.
Optimización de combinaciones y órdenes aleatorios
Si tiene trabajos lentos en una combinación o un orden aleatorio, es probable que la causa sea la asimetría de datos en el trabajo. Por ejemplo, un trabajo de asignación puede tardar 20 segundos, pero ejecutar un trabajo donde los datos se combinan o se ordenan de forma aleatoria puede tardar horas. Para corregir la asimetría de los datos, debe usar el valor de salt en toda la clave o un valor de salt aislado únicamente para algunos subconjuntos de claves. Si usa un valor de salt aislado, debe filtrar adicionalmente para aislar el subconjunto de claves con el valor de salt en las combinaciones de asignación. Otra opción consiste en insertar una columna de depósito y primero agregarla en los depósitos.
Otro factor causante de las combinaciones lentas podría ser el tipo de combinación. De forma predeterminada, Spark usa el tipo de combinación SortMerge. Este tipo de combinación es más adecuada para conjuntos de datos grandes, pero tiene la desventaja de que es cara desde el punto de vista computacional porque primero debe ordenar los lados izquierdo y derecho de los datos antes de combinarlos.
Una combinación Broadcast es más adecuada para conjuntos de datos más pequeños o donde un lado de la combinación sea mucho más pequeño que el otro. Este tipo de combinación difunde un lado a todos los ejecutores y, por tanto, requiere en general más memoria para las difusiones.
Se puede cambiar el tipo de combinación en la configuración si establece spark.sql.autoBroadcastJoinThreshold, o puede establecer una sugerencia de combinación con las API de DataFrame (dataframe.join(broadcast(df2))).
// Option 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1*1024*1024*1024)
// Option 2
val df1 = spark.table("FactTableA")
val df2 = spark.table("dimMP")
df1.join(broadcast(df2), Seq("PK")).
createOrReplaceTempView("V_JOIN")
sql("SELECT col1, col2 FROM V_JOIN")
Si usa tablas en depósitos, tiene un tercer tipo de combinación, la combinación Merge. Un conjunto de datos particionado previamente y ordenado previamente de forma correcta omitirá la fase cara de ordenación de una combinación SortMerge.
El orden de las combinaciones importa, en especial en consultas más complejas. Comience con las combinaciones más selectivas. Además, mueva las combinaciones que aumentan el número de filas después de las agregaciones cuando sea posible.
Para administrar el paralelismo en el caso de las combinaciones cartesianas, puede agregar estructuras anidadas, ventanas y, quizás, omitir uno o varios pasos del trabajo de Spark.
Selección del tamaño correcto del ejecutor
A la hora de decidir la configuración del ejecutor, tenga en cuenta la sobrecarga de la recolección de elementos no utilizados (GC) de Java.
Factores para reducir el tamaño del ejecutor:
- Reduzca el tamaño del montón a por debajo de 32 GB para mantener la sobrecarga de GC < 10 %.
- Reduzca el número de núcleos para mantener la sobrecarga de GC < 10 %.
Factores para aumentar el tamaño del ejecutor:
- Reduzca la sobrecarga de comunicación entre los ejecutores.
- Reduzca el número de conexiones abiertas entre los ejecutores (N2) en clústeres más grandes (>100 ejecutores).
- Aumente el tamaño del montón para dar cabida a las tareas que consumen mucha memoria.
- Opcional: reduzca la sobrecarga de memoria previa al ejecutor.
- Opcional: aumente la utilización y la simultaneidad mediante la sobresuscripción de CPU.
Como norma general al seleccionar el tamaño del ejecutor:
- Comience con 30 GB por ejecutor y distribuya los núcleos de máquina disponibles.
- Aumente el número de núcleos de ejecutor para clústeres más grandes (> 100 ejecutores).
- Modifique el tamaño según las ejecuciones de prueba y los factores anteriores, como la sobrecarga de GC.
Al ejecutar consultas simultáneas, tenga en cuenta lo siguiente:
- Comience con 30 GB por ejecutor y todos los núcleos de la máquina.
- Cree varias aplicaciones de Spark paralelas mediante la sobresuscripción de CPU (mejora de la latencia en torno al 30 %).
- Distribuya las consultas entre aplicaciones paralelas.
- Modifique el tamaño según las ejecuciones de prueba y los factores anteriores, como la sobrecarga de GC.
Supervise el rendimiento de las consultas en busca de valores atípicos u otros problemas de rendimiento; puede usar para ello la vista de escala de tiempo, el gráfico SQL, las estadísticas de trabajos, etc. En ocasiones, uno o algunos de los ejecutores son más lentos que otros y las tareas tardan mucho más en ejecutarse. Esto sucede con frecuencia en clústeres más grandes (> 30 nodos). En este caso, divida el trabajo en un número de tareas más grande para que el programador pueda compensar las tareas lentas.
Por ejemplo, debe tener al menos dos veces tantas tareas como el número de núcleos de ejecutor en la aplicación. También puede habilitar la ejecución especulativa de tareas con conf: spark.speculation = true.
Optimización de la ejecución de trabajos
- Almacene en caché como sea necesario; por ejemplo, si usa los datos dos veces, almacénelos en caché.
- Difunda variables a todos los ejecutores. Las variables se serializan una sola vez, lo que da lugar a búsquedas más rápidas.
- Use el grupo de subprocesos en el controlador, lo que tendrá como resultado operaciones más rápidas para muchas tareas.
Esencial para el rendimiento de consultas de Spark 2.x es el motor de Tungsten, que depende de la generación de código whole stage. En algunos casos, se puede deshabilitar la generación de código whole stage.
Por ejemplo, si se usa un tipo no mutable (string) en la expresión de agregación, aparece SortAggregate en lugar de HashAggregate. Por ejemplo, para mejorar el rendimiento, pruebe lo siguiente y, a continuación, habilite de nuevo la generación de código:
MAX(AMOUNT) -> MAX(cast(AMOUNT as DOUBLE))
Pasos siguientes
- Más información sobre los entornos de ejecución de Azure Synapse para Apache Spark
- Ajuste de Apache Spark
- How to Actually Tune Your Apache Spark Jobs So They Work (Cómo ajustar realmente los trabajos de Spark para que funcionen)
- Serialización de Kryo
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de