Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El equipo de Azure Synapse Studio creó dos nuevas API de montaje y desmontaje en el paquete de utilidades de Microsoft para Spark (mssparkutils). Puede usar estas API para conectar almacenamiento remoto (Azure Blob Storage o Azure Data Lake Storage Gen2) a todos los nodos que están en funcionamiento (nodo de controlador y nodos de trabajo). Una vez implementado el almacenamiento, puede usar la API de archivos locales para acceder a los datos como si estuvieran almacenados en el sistema de archivos local. Para obtener más información, consulte Introducción a las utilidades de Spark para Microsoft.
En este artículo se muestra cómo usar las API de montaje y desmontaje en el área de trabajo. Aprenderá a realizar los siguientes procedimientos:
- Montaje de Data Lake Storage Gen2 o Blob Storage.
- Acceso a archivos en el punto de montaje con la API del sistema de archivos local.
- Acceso a archivos en el punto de montaje con la API
mssparkutils fs. - Acceso a archivos en el punto de montaje con la API de lectura de Spark.
- Desmontaje del punto de montaje.
Advertencia
El montaje de recursos compartidos de archivos de Azure está deshabilitado temporalmente. Puede usar el montaje de Data Lake Storage Gen2 o Azure Blob Storage en su lugar, como se describe en la siguiente sección.
No se admite el uso de Azure Data Lake Storage Gen1. Puede migrar a Data Lake Storage Gen2 siguiendo la guía de migración de Azure Data Lake Storage Gen1 a Gen2 antes de usar las API de montaje.
Montaje del almacenamiento
En esta sección se muestra cómo montar Data Lake Storage Gen2 paso a paso como ejemplo. El montaje de Blob Storage funciona de forma similar.
En el ejemplo se supone que tiene una cuenta de Data Lake Storage Gen2 denominada storegen2. La cuenta tiene un contenedor denominado mycontainer en el que quiere montar /test en el grupo de Spark.
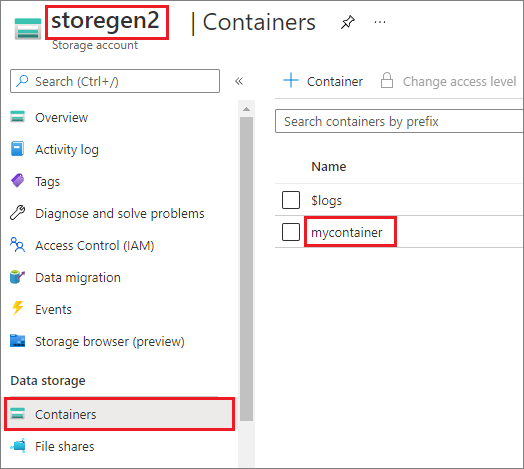
Para montar el contenedor mycontainer, mssparkutils debe comprobar primero si tiene permiso para acceder al contenedor. Actualmente, Azure Synapse Analytics admite tres métodos de autenticación para la operación de montaje de un desencadenador: linkedService, accountKeyy sastoken.
Montaje por medio de un servicio vinculado (recomendado)
Se recomienda montar un desencadenador a través de un servicio vinculado. Este método evita pérdidas de seguridad, ya que mssparkutils no almacena ningún secreto ni valores de autenticación. En su lugar, mssparkutils siempre captura los valores de autenticación del servicio vinculado para solicitar datos de blobs desde el almacenamiento remoto.
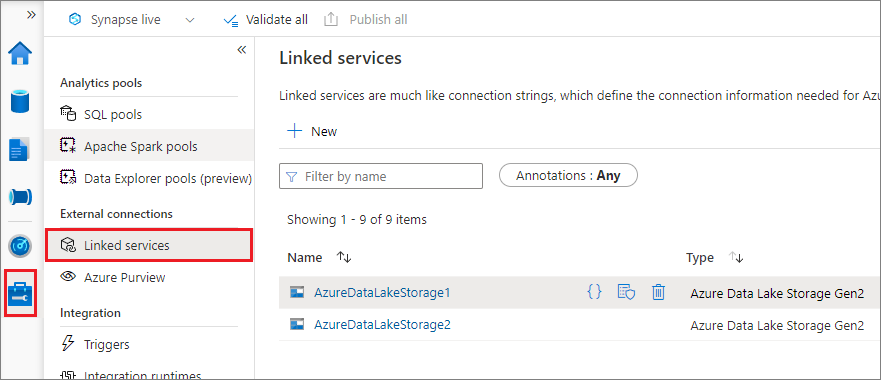
Puede crear un servicio vinculado para Data Lake Storage Gen2 o Blob Storage. Actualmente, Azure Synapse Analytics admite dos métodos de autenticación para crear un servicio vinculado:
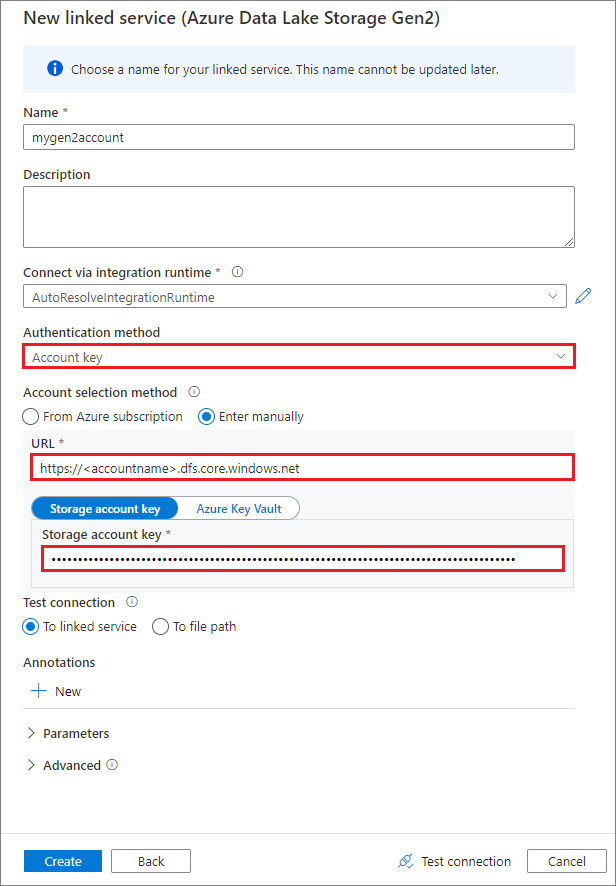
Creación de un servicio vinculado con una clave de cuenta
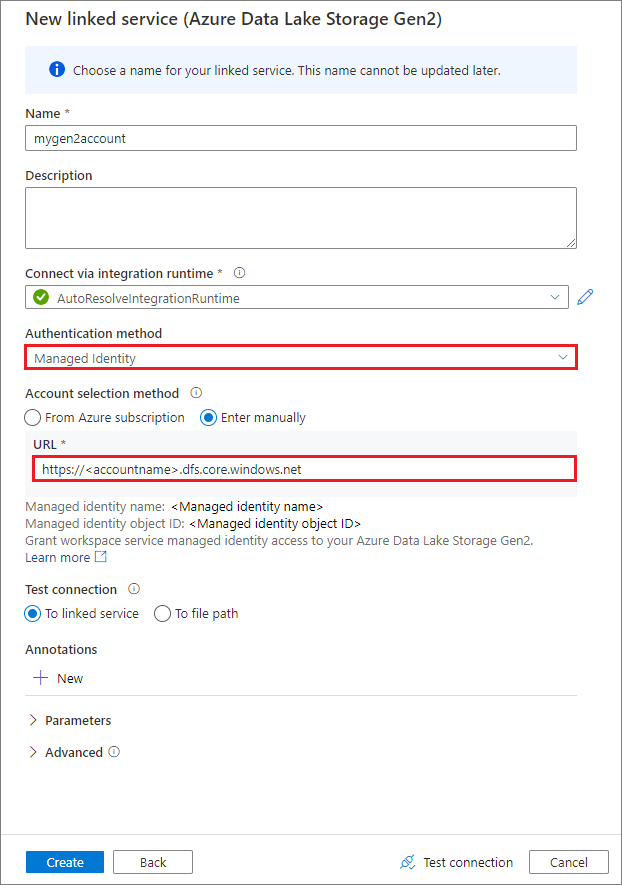
Creación de un servicio vinculado mediante una identidad administrada asignada por el sistema
Importante
- Si el servicio vinculado creado anteriormente para Azure Data Lake Storage Gen2 usa un punto de conexión privado administrado (con un URI dfs), es necesario crear otro punto de conexión privado administrado secundario mediante la opción Azure Blob Storage (con un URI de blob) para asegurarse de que el código de fsspec/adlfs interno puede conectarse mediante la interfaz BlobServiceClient.
- En caso de que el punto de conexión privado administrado secundario no esté configurado correctamente, verá un mensaje de error como ServiceRequestError: No se puede conectar al host [storageaccountname].blob.core.windows.net:443 ssl:True [Nombre o servicio no conocido]
Nota:
Si crea un servicio vinculado usando una identidad administrada como método de autenticación, asegúrese de que el archivo MSI del área de trabajo tiene el rol Colaborador de datos de Storage Blob en el contenedor montado.
Después de crear correctamente el servicio vinculado, puede montar fácilmente el contenedor en el grupo de Spark con el siguiente código de Python:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
Nota:
Puede ser necesario que importe mssparkutils si no está disponible:
from notebookutils import mssparkutils
No se recomienda montar una carpeta raíz, sea cual sea el método de autenticación que utilice.
Parámetros de montaje:
- fileCacheTimeout: los blobs se almacenarán en caché en la carpeta temporal local durante 120 segundos de forma predeterminada. Durante este tiempo, blobfuse no comprobará si el archivo está actualizado o no. El parámetro se puede establecer para cambiar el tiempo de espera predeterminado. Cuando varios clientes modifican archivos al mismo tiempo, para evitar incoherencias entre archivos locales y remotos, se recomienda acortar el tiempo de caché o incluso cambiarlo a 0 y obtener siempre los archivos más recientes del servidor.
- timeout: el tiempo de espera de la operación de montaje es de 120 segundos de forma predeterminada. El parámetro se puede establecer para cambiar el tiempo de espera predeterminado. Cuando hay demasiados ejecutores o cuando se agota el tiempo de espera de montaje, se recomienda aumentar el valor.
- scope: el parámetro scope se usa para especificar el ámbito del montaje. El valor predeterminado es "job." Si el ámbito se establece en "job", el montaje solo es visible para el clúster actual. Si el ámbito se establece en "workspace", el montaje es visible para todos los cuadernos del área de trabajo actual y el punto de montaje se crea automáticamente si no existe. Agregue los mismos parámetros a la API de desmontaje para desmontar el punto de montaje. El montaje de nivel de área de trabajo solo se admite para la autenticación del servicio vinculado.
Puede usar estos parámetros de la siguiente manera:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Montaje con un token de firma de acceso compartido o una clave de cuenta
Además del montaje a través de un servicio vinculado, mssparkutils admite pasar explícitamente una clave de cuenta o un token de firma de acceso compartido (SAS) como parámetro para montar el destino.
Por motivos de seguridad, se recomienda almacenar las claves de cuenta o los tokens de SAS en Azure Key Vault (como se muestra en la siguiente captura de pantalla de ejemplo). Después, puede recuperarlos con la API mssparkutil.credentials.getSecret. Para obtener más información, consulte Administración de claves de cuenta de almacenamiento con Key Vault y la CLI de Azure (heredado).
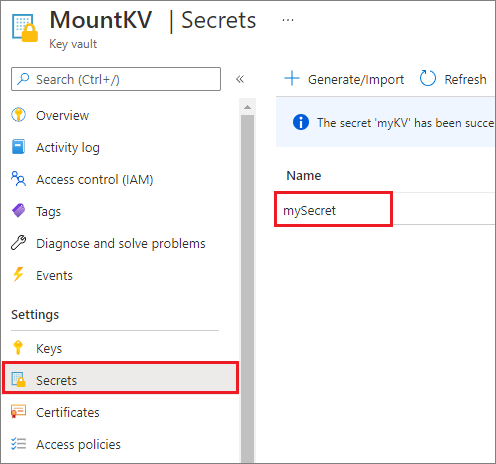
Este es el código de ejemplo:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Nota:
Por motivos de seguridad, no almacene las credenciales en el código.
Acceso a los archivos del punto de montaje por medio de la API mssparkutils fs
El objetivo principal de la operación de montaje es permitir a los clientes acceder a los datos almacenados en una cuenta de almacenamiento remoto usando una API del sistema de archivos local. También puede acceder a los datos por medio de la API mssparkutils fs con una ruta de acceso montada como parámetro. El formato de ruta de acceso que se usa aquí es un poco diferente.
Suponiendo que ha montado el contenedor mycontainer de Data Lake Storage Gen2 en /test mediante la API de montaje. Al acceder a los datos a través de una API del sistema de archivos local:
- Para las versiones de Spark menores o iguales que 3.3, el formato de ruta de acceso es
/synfs/{jobId}/test/{filename}. - Para las versiones de Spark mayores o iguales que 3.4, el formato de ruta de acceso es
/synfs/notebook/{jobId}/test/{filename}.
Se recomienda usar un mssparkutils.fs.getMountPath() para obtener la ruta de acceso precisa:
path = mssparkutils.fs.getMountPath("/test")
Nota:
Al montar el almacenamiento con workspace ámbito, el punto de montaje se crea en la /synfs/workspace carpeta . Y debe usar mssparkutils.fs.getMountPath("/test", "workspace") para obtener la ruta de acceso precisa.
Cuando desee acceder a los datos mediante la mssparkutils fs API, el formato de ruta de acceso es similar al siguiente: synfs:/notebook/{jobId}/test/{filename}. Puede ver que se usa synfs como esquema en este caso, en lugar de una parte de la ruta de acceso montada. Por supuesto, también puede usar el esquema del sistema de archivos local para acceder a los datos. Por ejemplo, file:/synfs/notebook/{jobId}/test/{filename}.
En los tres ejemplos siguientes se muestra cómo obtener acceso a un archivo con una ruta de acceso de punto de montaje usando mssparkutils fs.
Enumerar directorios:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')Leer el contenido de archivos:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')Crear un directorio:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Acceso a archivos en el punto de montaje con la API de lectura de Spark
Puede proporcionar un parámetro para acceder a los datos por medio de la API de lectura de Spark. El formato de ruta de acceso aquí es el mismo cuando se usa la mssparkutils fs API.
Lectura de un archivo de una cuenta de almacenamiento de Data Lake Storage Gen2 montada
En el ejemplo siguiente se supone que ya se ha montado una cuenta de almacenamiento de Data Lake Storage Gen2 y, después, se lee el archivo usando una ruta de acceso de montaje:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Nota:
Al montar el almacenamiento mediante un servicio vinculado, siempre debe establecer explícitamente la configuración del servicio vinculado de Spark antes de usar el esquema synfs para acceder a los datos. Consulte Almacenamiento de ADLS Gen2 con servicios vinculados para obtener más información.
Lectura de un archivo de una cuenta de Blob Storage montada
Si ha montado una cuenta de Blob Storage y quiere acceder a ella con mssparkutils o la API de Spark, debe configurar explícitamente el token de SAS en la configuración de Spark antes de intentar montar el contenedor con la API de montaje:
Para acceder a una cuenta de Blob Storage con
mssparkutilso la API de Spark después del montaje de un desencadenador, actualice la configuración de Spark como se muestra en el ejemplo de código siguiente. Puede omitir este paso si desea acceder a la configuración de Spark solo mediante la API de archivos locales después del montaje.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Cree el servicio vinculado
myblobstorageaccounty monte la cuenta de Blob Storage usando el servicio vinculado:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Monte el contenedor de Blob Storage y lea el archivo usando una ruta de acceso de montaje con la API de archivos locales:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Lea los datos del contenedor de Blob Storage montado por medio de la API de lectura de Spark:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
Desmontaje de un punto de montaje
Use el siguiente código para desmontar un punto de montaje (/test en este ejemplo):
mssparkutils.fs.unmount("/test")
Restricciones conocidas
El mecanismo de desmontaje no es automático. Cuando termine la ejecución de la aplicación, para desmontar el punto de montaje y liberar el espacio en disco, debe llamar explícitamente a una API de desmontaje en el código. De lo contrario, el punto de montaje seguirá existiendo en el nodo cuando termine la ejecución de la aplicación.
Por ahora no se admite el montaje de una cuenta de almacenamiento de Data Lake Storage Gen1.