Tutorial: Uso de Pandas para leer y escribir datos de Azure Data Lake Storage Gen2 en un grupo de Apache Spark sin servidor en Synapse Analytics
Aprenda a usar Pandas para leer y escribir datos en Azure Data Lake Storage Gen2 (ADLS) mediante un grupo de Apache Spark sin servidor en Azure Synapse Analytics. En los ejemplos de este tutorial se muestra cómo leer datos CSV con Pandas en Synapse, así como archivos de Excel y Parquet.
En este tutorial, aprenderá a:
- Leer y escribir datos de ADLS Gen2 mediante Pandas en una sesión de Spark.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Prerrequisitos
Área de trabajo de Azure Synapse Analytics con una cuenta de almacenamiento de Azure Data Lake Storage Gen2 que esté configurada como almacenamiento predeterminado (o almacenamiento principal). Asegúrese de que es el colaborador de datos de Storage Blob en el sistema de archivos de Data Lake Storage Gen2 con el que trabaja.
Un grupo de Apache Spark sin servidor en el área de trabajo de Azure Synapse Analytics. Para más información, consulte el artículo sobre creación de un grupo de Spark en Azure Synapse.
Configure la cuenta secundaria de Azure Data Lake Storage Gen2 (que no es la predeterminada del área de trabajo de Synapse). Asegúrese de que es el colaborador de datos de Storage Blob en el sistema de archivos de Data Lake Storage Gen2 con el que trabaja.
Cree servicios vinculados: en Azure Synapse Analytics, un servicio vinculado define la información de conexión al servicio. En este tutorial, agregará un servicio vinculado de Azure Synapse Analytics y Azure Data Lake Storage Gen2.
- Abra Azure Synapse Studio y seleccione la pestaña Administrar.
- En Conexiones externas, seleccione Servicios vinculados.
- Para agregar un servicio vinculado, seleccione Nuevo.
- Seleccione el icono de Azure Data Lake Storage Gen2 de la lista y seleccione Continuar.
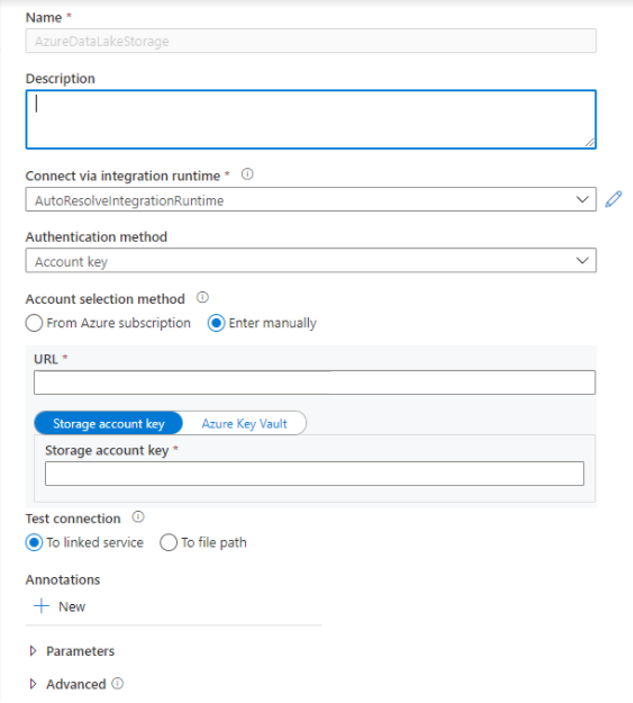
- Especifique las credenciales de autenticación. La clave de cuenta, la entidad de servicio (SP), las credenciales y la identidad de servicio administrada (MSI) son actualmente tipos de autenticación admitidos. Asegúrese de que el rol Colaborador de datos de Storage Blob esté asignado en el almacenamiento para SP y MSI antes de elegirlo para la autenticación. Pruebe la conexión para ver si las credenciales sean correctas. Seleccione Crear.
Importante
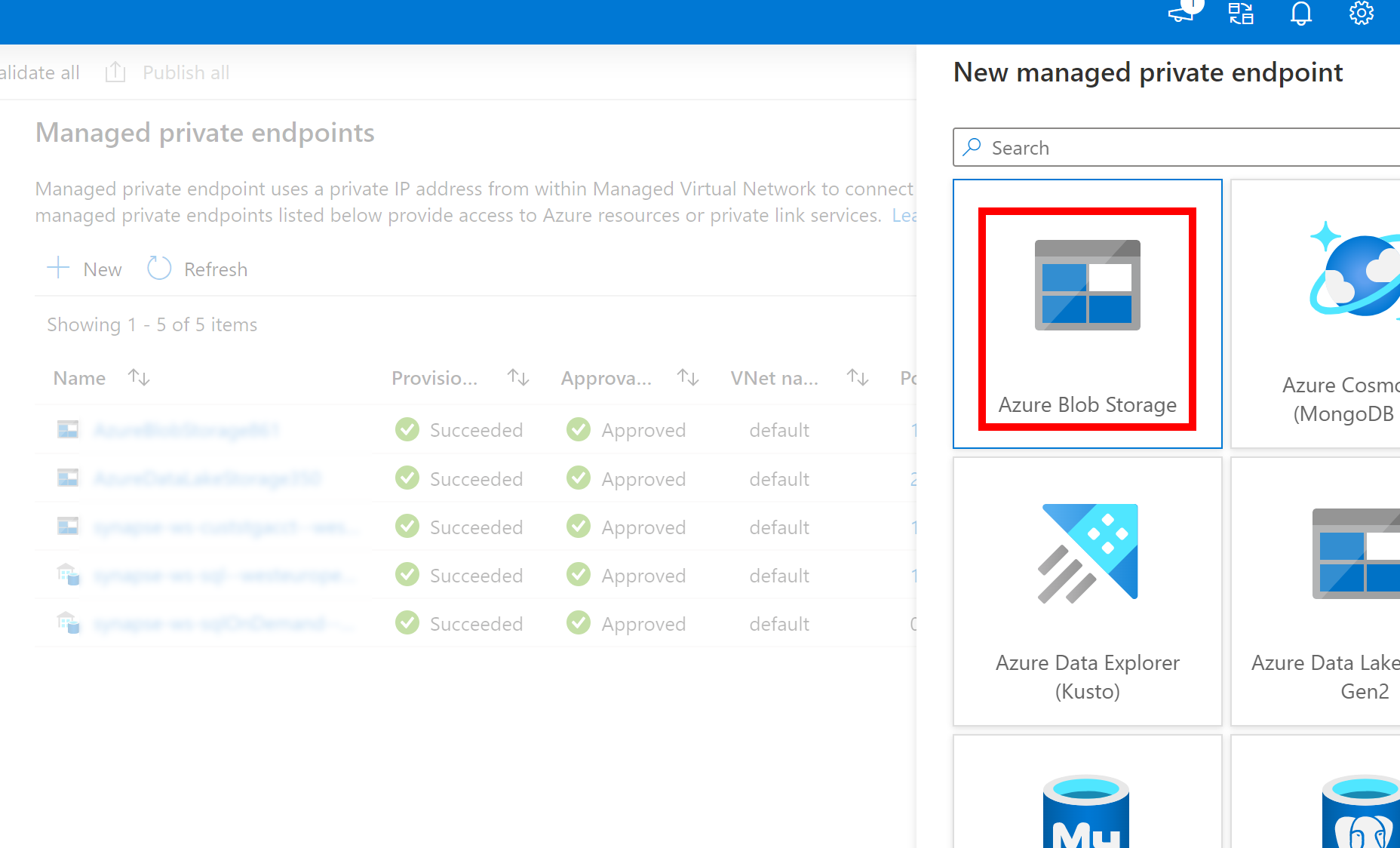
- Si el servicio vinculado creado anteriormente para Azure Data Lake Storage Gen2 usa un punto de conexión privado administrado (con un URI dfs), es necesario crear otro punto de conexión privado administrado secundario mediante la opción Azure Blob Storage (con un URI de blob) para asegurarse de que el código de fsspec/adlfs interno puede conectarse mediante la interfaz BlobServiceClient.
- En caso de que el punto de conexión privado administrado secundario no esté configurado correctamente, verá un mensaje de error como ServiceRequestError: No se puede conectar al host [storageaccountname].blob.core.windows.net:443 ssl:True [Nombre o servicio no conocido]
Nota:
- La característica de Pandas se admite en el grupo de Apache Spark para Python 3.8 y Spark3 sin servidor de Azure Synapse Analytics.
- Compatibilidad disponible con las siguientes versiones: pandas 1.2.3, fsspec 2021.10.0, adlfs 0.7.7
- Debe tener funcionalidades para admitir tanto el URI de Azure Data Lake Storage Gen2 (abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path) como la dirección URL corta de FSSPEC (abfs[s]://container_name/file_path).
Inicio de sesión en Azure Portal
Inicie sesión en Azure Portal.
Lectura y escritura de datos en la cuenta de almacenamiento de ADLS predeterminada del área de trabajo de Synapse
Pandas puede leer y escribir datos de ADLS especificando directamente la ruta de acceso del archivo.
Ejecute el código siguiente:
Nota
Actualice la dirección URL del archivo en este script antes de ejecutarlo.
#Read data file from URI of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://container_name/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path')
Lectura y escritura de datos mediante una cuenta secundaria de ADLS
Pandas puede leer y escribir datos de cuentas secundarias de ADLS:
- mediante el servicio vinculado (con opciones de autenticación: clave de cuenta de almacenamiento, entidad de servicio, identidad de servicio administrada y credenciales);
- mediante opciones de almacenamiento para pasar directamente el identificador de cliente y el secreto; la clave SAS, la clave de la cuenta de almacenamiento y la cadena de conexión.
Uso del servicio vinculado
Ejecute el código siguiente:
Nota
Actualice la dirección URL del archivo y el nombre del servicio vinculado de este script antes de ejecutarlo.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'linked_service' : 'linked_service_name'})
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
Uso de opciones de almacenamiento para pasar directamente el identificador y el secreto de cliente, la clave SAS, la clave de la cuenta de almacenamiento y la cadena de conexión.
Ejecute el código siguiente:
Nota
Actualice la dirección URL del archivo y storage_options en este script antes de ejecutarlo.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
Ejemplo de archivo Parquet de lectura y escritura
Ejecute el código siguiente:
Nota
Actualice la dirección URL del archivo en este script antes de ejecutarlo.
import pandas
#read parquet file
df = pandas.read_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
print(df)
#write parquet file
df.to_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
Ejemplo de archivo de Excel de lectura y escritura
Ejecute el código siguiente:
Nota
Actualice la dirección URL del archivo en este script antes de ejecutarlo.
import pandas
#read excel file
df = pandas.read_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ excel_file_path')
print(df)
#write excel file
df.to_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/excel_file_path')