Tamaños de las máquinas virtuales de la serie HBv2
Se aplica a: ✔️ Máquinas virtuales Linux ✔️ Máquinas virtuales Windows ✔️ Conjuntos de escalado flexibles ✔️ Conjuntos de escalado uniformes
Se han realizado varias pruebas de rendimiento en las máquinas virtuales de los tamaños de la serie HBv2. Estos son algunos de los resultados de esta prueba.
| Carga de trabajo | HBv2 |
|---|---|
| STREAM Triad | 350 GB/s (21-23 GB/s por CCX) |
| High-Performance Linpack (HPL) | 4 TeraFLOPS (Rpeak, FP64), 8 TeraFLOPS (Rmax, FP32) |
| Latencia y ancho de banda de RDMA | 1,2 microsegundos; 190 Gb/s |
| FIO en SSD NVMe local | 2,7 GB/s lecturas, 1,1 GB/s escrituras; lecturas de IOPS de 102 k, 115 escrituras de IOPS |
| IOR en 8 * SSD Premium de Azure (P40 Managed Disks, RAID0)** | 1,3 GB/s lecturas, 2,5 GB/escrituras; lecturas de IOPS de 101 k, escrituras de IOPS de 105 k |
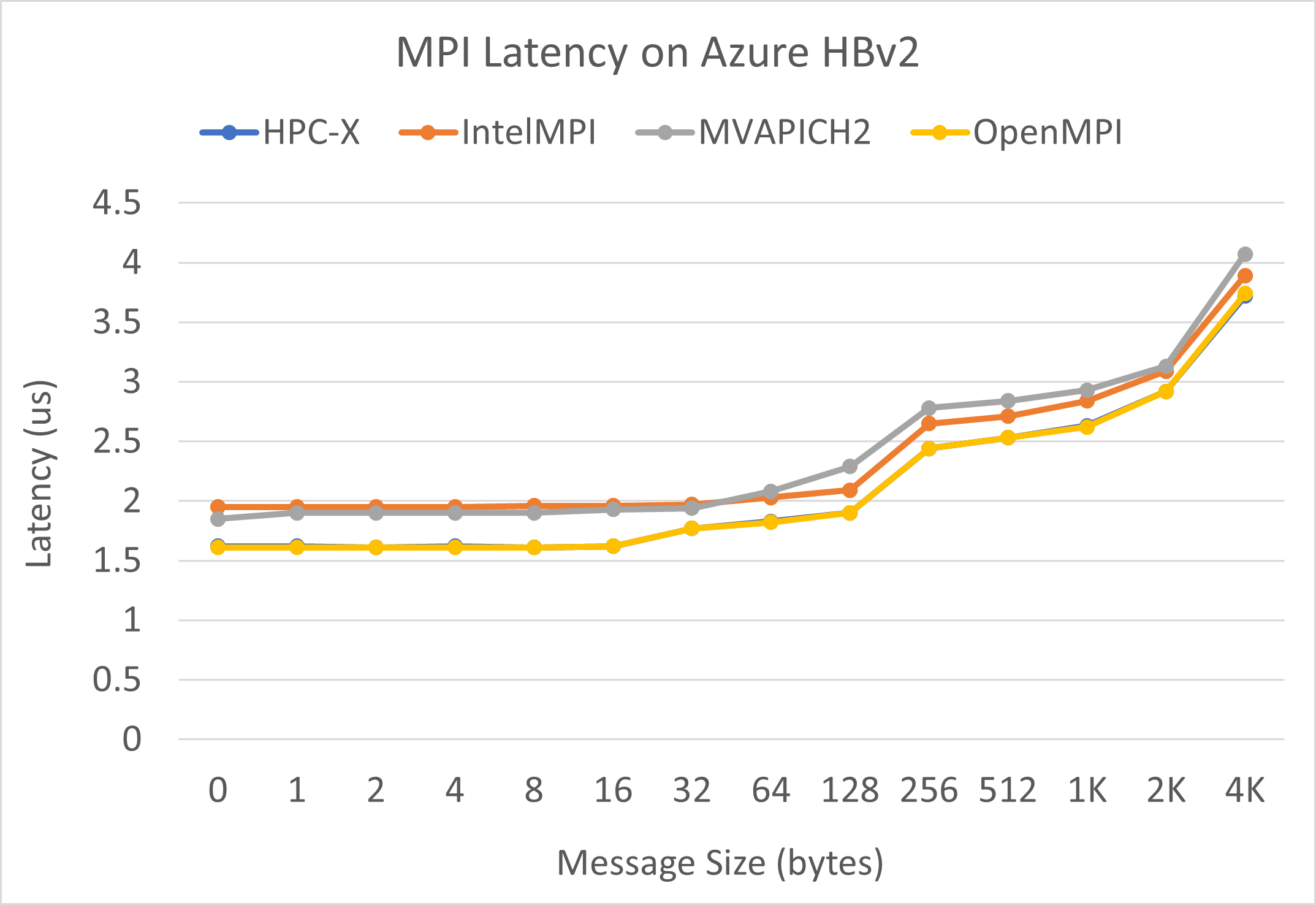
Latencia de MPI
Se ejecuta la prueba de latencia de MPI del conjunto de pruebas OSU de microrrealización. Los scripts de ejemplo se encuentran en GitHub.
./bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./osu_latency
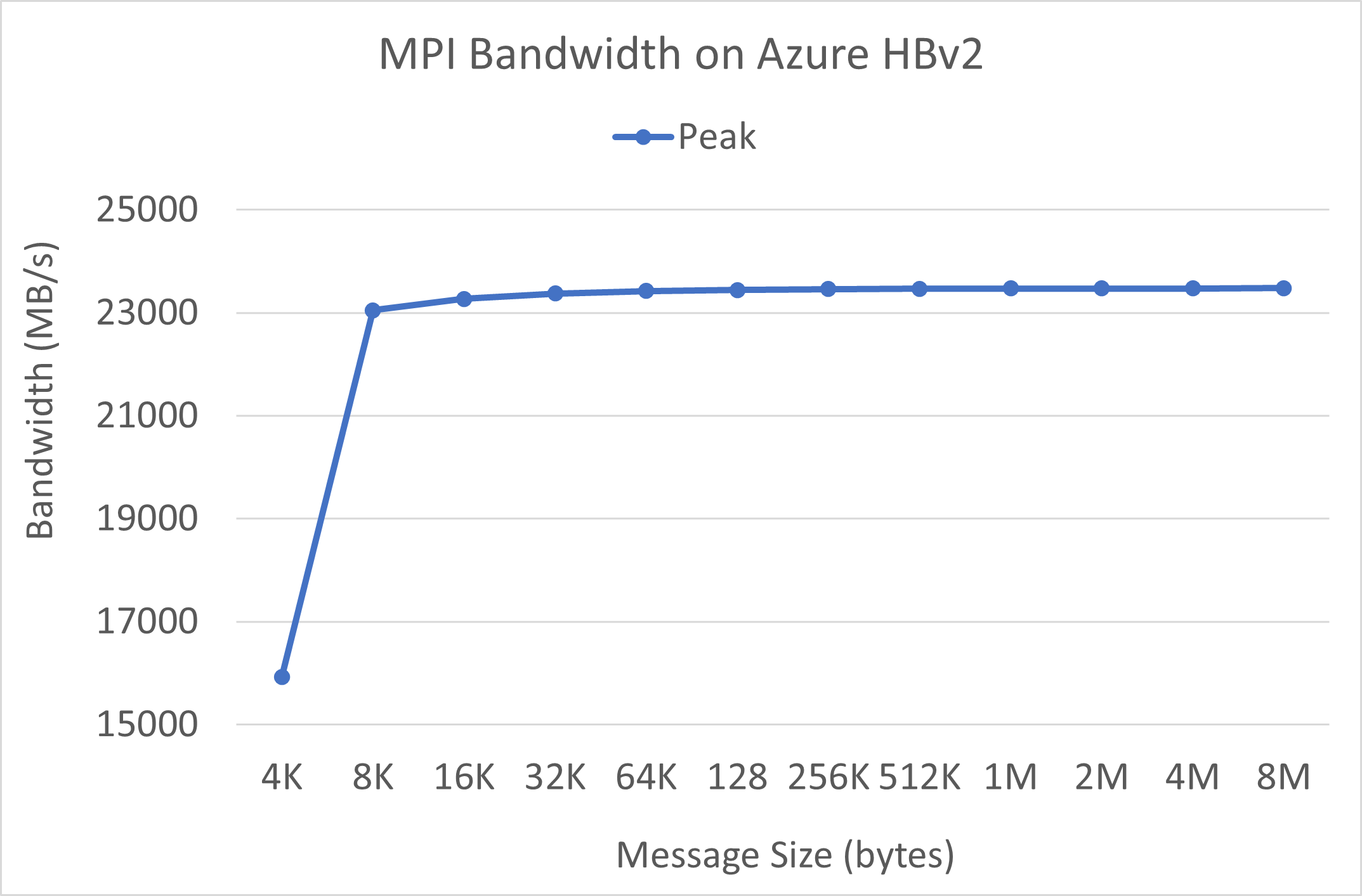
Ancho de banda de MPI
Se ejecuta la prueba de ancho de banda de MPI del conjunto de pruebas OSU de microrrealización. Los scripts de ejemplo se encuentran en GitHub.
./mvapich2-2.3.install/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./mvapich2-2.3/osu_benchmarks/mpi/pt2pt/osu_bw
Mellanox Perftest
El paquete Mellanox Perftest tiene muchas pruebas de InfiniBand, como la de latencia (ib_send_lat) y la de ancho de banda (ib_send_bw). El siguiente es un ejemplo de comando.
numactl --physcpubind=[INSERT CORE #] ib_send_lat -a
Pasos siguientes
- En los blogs de Azure Compute Community Tech, encontrará los anuncios más recientes, ejemplos de la carga de trabajo HPC y resultados de HPC.
- Si quiere una visión general de la arquitectura de la ejecución de cargas de trabajo de HPC, consulte Informática de alto rendimiento (HPC) en Azure.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de