Implementación de DBMS de Azure Virtual Machines de SQL Server para la carga de trabajo de SAP NetWeaver
En este documento se describen las diferentes áreas que se deben tener en cuenta al implementar SQL Server para la carga de trabajo de SAP en IaaS de Azure. Como condición previa a este documento, debe haber leído el documento Consideraciones para la implementación de DBMS de Azure Virtual Machines para la carga de trabajo de SAP y otras guías de la documentación de carga de trabajo de SAP en Azure.
Importante
El ámbito de este documento es la versión de Windows en SQL Server. SAP no es compatible con la versión de Linux de SQL Server con ningún software de SAP. En el documento no se habla de Microsoft Azure SQL Database, que es la oferta de plataforma como servicio de Microsoft Azure. En este documento se aborda la ejecución del producto SQL Server tal cual para implementaciones locales en Azure Virtual Machines, con lo que se aprovecha la funcionalidad de infraestructura como servicio. Las funcionalidades de bases de datos de estas dos ofertas son diferentes y no deben combinarse. Para obtener más información, consulte Azure SQL Database.
En general, debería considerar usar las versiones más recientes de SQL Server para ejecutar la carga de trabajo de SAP en IaaS de Azure. Las versiones más recientes de SQL Server ofrecen una mejor integración en algunos de los servicios y funcionalidades de Azure o disponer de cambios que optimicen las operaciones en una infraestructura de IaaS de Azure.
En estos artículos encontrará documentación general sobre la ejecución de SQL Server en máquinas virtuales de Azure:
- SQL Server en Azure Virtual Machines (Windows)
- Automatización de la administración con la extensión del Agente de IaaS de Windows SQL Server
- Configuración de la integración de Azure Key Vault para SQL Server en máquinas virtuales de Azure (Resource Manager)
- Lista de comprobación: Procedimientos recomendados de SQL Server en máquinas virtuales de Azure
- Almacenamiento: procedimientos recomendados de rendimiento de SQL Server en VM de Azure
- Procedimientos recomendados para la configuración de HADR (SQL Server en Azure Virtual Machines)
No todo el contenido y las instrucciones incluidos en la documentación general sobre SQL Server en Azure Virtual Machines se aplican a la carga de trabajo de SAP. Sin embargo, la documentación da una buena visión sobre los principios. Un ejemplo de funcionalidad no compatible con la carga de trabajo de SAP es el uso de clústeres de FCI.
Antes de continuar debe conocer cierta información específica sobre SQL Server en IaaS:
- Compatibilidad con la versión de SQL: incluso con la nota de SAP #1928533 que indica que la versión de SQL Server mínima admitida es SQL Server 2008 R2, la ventana de versiones de SQL Server admitidas en Azure también está determinada por el ciclo de vida de SQL Server. El mantenimiento extendido de SQL Server 2012 finalizó a mediados de 2022. Como resultado, la versión mínima actual para los sistemas recién implementados es SQL Server 2014. Cuanto más reciente, mejor. Las versiones más recientes de SQL Server ofrecen una mejor integración en algunos de los servicios y funcionalidades de Azure o disponer de cambios que optimicen las operaciones en una infraestructura de IaaS de Azure.
- Uso de imágenes de Azure Marketplace: la forma más rápida de implementar una nueva máquina virtual de Microsoft Azure es utilizando una imagen de Azure Marketplace. Hay imágenes en Azure Marketplace que contienen las versiones más recientes de SQL Server. Las imágenes donde ya se ha instalado SQL Server no se pueden utilizar inmediatamente para aplicaciones de SAP NetWeaver. El motivo es que la intercalación de SQL Server predeterminada está instalada en esas imágenes y no la que requieren los sistemas SAP NetWeaver. Para usar estas imágenes, consulte los pasos que se explican en el capítulo Uso de imágenes de SQL Server desde Microsoft Azure Marketplace.
- Compatibilidad con varias instancias de SQL Server en una sola máquina virtual de Azure: se admite este método de implementación. Sin embargo, tenga en cuenta las limitaciones de los recursos, sobre todo las que afectan al ancho de banda de red y del almacenamiento del tipo de máquina virtual que usa. Puede encontrar información detallada en el artículo Tamaños de las máquinas virtuales en Azure. Estas limitaciones de cuota tal vez no le permitan implementar la misma arquitectura de varias instancias que puede implementar en los entornos locales. En cuanto a la configuración y la interferencia de compartir los recursos disponibles dentro de una sola máquina virtual, se deben tener en cuenta las mismas consideraciones que en los entornos locales.
- Varias bases de datos de SAP en una sola instancia de SQL Server en una sola máquina virtual: se admiten configuraciones como estas. Las consideraciones sobre varias bases de datos de SAP que comparten los recursos de una sola instancia de SQL Server son las mismas que para las implementaciones en entornos locales. Tenga en cuenta otros límites, como el número de discos que se pueden conectar a un tipo de máquina virtual específico. O los límites de cuota de red y almacenamiento de tipos de máquina virtual específicos como tamaños detallados para máquinas virtuales en Azure.
Recomendaciones sobre la estructura de máquina virtual y VHD para SAP relacionadas con las implementaciones de SQL Server
Según la descripción general, el sistema operativo, los archivos ejecutables de SQL Server y los archivos ejecutables de SAP se deben ubicar o instalar en discos de Azure independientes. Normalmente, la carga de trabajo de SAP NetWeaver no utiliza en gran medida la mayoría de las bases de datos de sistema de SQL Server. No obstante, las bases de datos del sistema de SQL Server deben estar, junto con los demás directorios de SQL Server, en un disco de Azure independiente. tempdb de SQL Server debe encontrarse en la unidad D:\ no persistente o en un disco independiente.
- Con todos los tipos de máquina virtual certificados de SAP (consulte la nota de SAP 1928533), los datos de tempdb y los archivos de registro se pueden colocar en la unidad D:\ no persistente.
- En el caso de las versiones de SQL Server, donde SQL Server instala tempdb con un archivo de datos de forma predeterminada, se recomienda usar varios archivos de datos de tempdb. Tenga en cuenta que los volúmenes de la unidad D:\ tendrán un tamaño y unas funcionalidades diferentes en función del tipo de máquina virtual. Para saber cuáles son los tamaños exactos de la unidad D:\ de las distintas máquinas virtuales, consulte el artículo Tamaños de las máquinas virtuales Windows en Azure.
Estas configuraciones permiten que tempdb consuma más espacio y, lo que es más importante, más operaciones de E/S por segundo (IOPS) y ancho de banda de almacenamiento del que la unidad del sistema puede proporcionar. La unidad D:\ no persistente también ofrece una mejor latencia y rendimiento de E/S. Para determinar el tamaño correcto de tempdb, puede comprobar los tamaños de tempdb en los sistemas existentes.
Nota
En el caso de que coloque los archivos de datos de tempdb y el archivo de registro en una carpeta de la unidad D:\ que haya creado, deberá asegurarse de que la carpeta existe después de reiniciar la máquina virtual. Dado que la unidad D:\ se puede inicializar después de reiniciar la máquina virtual, se podrían borrar todas las estructuras de archivos y directorios. En este artículo se documenta una posibilidad de volver a crear estructuras de directorios finales en la unidad D:\ antes de iniciar el servicio SQL Server.
Una configuración de máquina virtual que ejecuta SQL Server con una base de datos de SAP donde el archivo de registro de tempdb y el de datos se colocan en la unidad D:\ y el almacenamiento premium de Azure v1 o v2 tendría el siguiente aspecto:
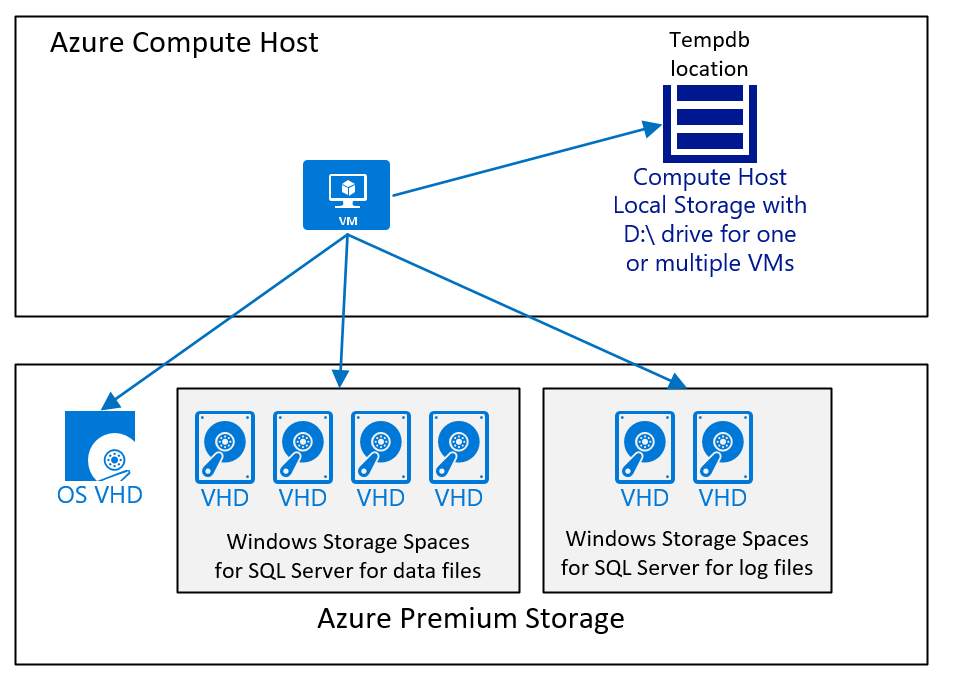
En el diagrama se muestra un caso sencillo. Como se menciona en el artículo Consideraciones para la implementación de DBMS de Azure Virtual Machines para la carga de trabajo de SAP, el tipo de almacenamiento de Azure, el número y el tamaño de los discos dependen de varios factores, pero en general se recomienda lo siguiente:
- Para implementaciones más pequeñas y medianas, con un volumen grande, que contiene los archivos de datos de SQL Server. El motivo de esta configuración es que es más fácil tratar con diferentes cargas de trabajo de E/S en caso de que los archivos de datos de SQL Server no tengan el mismo espacio libre. En cambio, en implementaciones de gran tamaño, especialmente en las implementaciones en las que el cliente se trasladó con una migración de base de datos heterogénea a SQL Server en Azure, se usaron discos independientes y, a continuación, se distribuyeron los archivos de datos entre esos discos. Esta arquitectura solo se realiza correctamente cuando cada disco tiene el mismo número de archivos de datos, todos los archivos de datos tienen el mismo tamaño y tienen aproximadamente el mismo espacio libre.
- Usar la unidad D:\ para tempdb mientras el rendimiento sea lo suficientemente bueno. Si el rendimiento de la carga de trabajo global está limitado porque tempdb se encuentra en la unidad D:\, puede que deba trasladar tempdb a discos de Azure Storage Premium v1 o v2 o Ultra, como se recomienda en este artículo.
El mecanismo de relleno proporcional de SQL Server distribuye las lecturas y escrituras en todos los archivos de datos uniformemente siempre que todos los archivos de datos SQL Server tengan el mismo tamaño y el mismo espacio libre. SAP en SQL Server ofrece el mejor rendimiento cuando las lecturas y escrituras se distribuyen uniformemente entre todos los archivos de datos disponibles. Si una base de datos tiene demasiados archivos de datos o los archivos de datos existentes están muy desequilibrados, el mejor método para corregir es una exportación e importación de R3load. Una exportación e importación de R3load implica tiempo de inactividad y solo debe realizarse si hay un problema de rendimiento obvio que debe resolverse. Si los archivos de datos solo tienen tamaños moderadamente diferentes, aumente todos los archivos de datos al mismo tamaño y SQL Server volverá a equilibrar los datos con el tiempo. SQL Server aumentará automáticamente los archivos de datos de forma uniforme si se establece que el valor de la marca de seguimiento sea 1117 o si se utiliza SQL Server 2016, o cualquier versión superior.
Aspectos especiales para las máquinas virtuales de la serie M
Para la máquina virtual de Azure de la serie M, se puede reducir la latencia de escritura en el registro de transacciones, en comparación con el rendimiento de Azure Premium Storage v1, cuando se usa el Acelerador de escritura de Azure. Si la latencia proporcionada por Premium Storage v1 limita la escalabilidad de la carga de trabajo de SAP, el disco que almacena el archivo de registro de transacciones de SQL Server se puede habilitar para el Acelerador de escritura. En el documento Acelerador de escritura se pueden leer los detalles. El Acelerador de escritura de Azure no funciona con Azure Premium Storage v2 y discos Ultra. En ambos casos, la latencia es mejor que la que ofrece Azure Premium Storage v1.
Aplicar formato a los discos
Para SQL Server, el tamaño de bloque NTFS de los discos que contienen los archivos de registro y de datos de SQL Server deben tener un tamaño de 64 KB. No es necesario formatear la unidad D:\, ya que este proceso se ha realizado previamente.
Para impedir que la restauración o la creación de bases de datos inicialice los archivos de datos llenando con ceros el contenido de los archivos, asegúrese de que el servicio de SQL Server que se ejecuta en el contexto de usuario tiene el derecho de usuario Realizar tareas de mantenimiento del volumen. Para obtener más información, consulte Inicialización instantánea de archivos de la base de datos.
SQL Server 2014 y versiones más recientes: almacenamiento de archivos de base de datos directamente en Azure Blob Storage
SQL Server 2014 y versiones posteriores ofrecen la posibilidad de almacenar archivos de base de datos directamente en el almacén de blobs de Azure sin necesidad de usar el contenedor de un disco duro virtual en ellos. Esta funcionalidad se diseñó para abordar las deficiencias del almacenamiento en bloques de Azure años atrás. Actualmente, no se recomienda usar este método de implementación y, en su lugar, se recomienda elegir Azure Premium Storage v1, Premium Storage v2 o discos Ultra. Depende de los requisitos.
Extensión de grupo de búferes de SQL Server 2014
SQL Server 2014 incorporó una nueva característica denominada Extensión del grupo de búferes. Esta funcionalidad, si bien se ha probado en cargas de trabajo de SAP en Azure, no ha proporcionado mejoras en la carga de trabajo de hospedaje. Por lo tanto, no se debe tener en cuenta.
Consideraciones de copia de seguridad y recuperación en SQL Server
Al implementar SQL Server en Azure, debe revisar la arquitectura de copia de seguridad. Aunque no se trate de un sistema de producción, es preciso realizar periódicamente una copia de seguridad de la base de datos de SAP hospedada por SQL Server. Como Azure Storage mantiene tres imágenes, una copia de seguridad es menos importante para compensar un bloqueo de almacenamiento. El principal motivo para mantener un plan de copia de seguridad y recuperación adecuado es más que poder compensar los errores lógicos o manuales proporcionando funcionalidades de recuperación a un momento dado. El objetivo es usar las copias de seguridad para restaurar la base de datos a un momento dado. O bien, usar las copias de seguridad en Azure para inicializar otro sistema copiando la base de datos existente.
Hay varias maneras de realizar copias de seguridad y restaurar bases de datos de SQL Server en Azure. Para obtener la mejor información general y detalles, lea el documento Copia de seguridad y restauración de SQL Server en máquinas virtuales de Azure. En este artículo se describen varias posibilidades.
Uso de imágenes de SQL Server desde Microsoft Azure Marketplace
Microsoft ofrece en Azure Marketplace máquinas virtuales que ya contienen versiones de SQL Server. Para los clientes de SAP que requieran licencias de SQL Server y Windows, el uso de estas imágenes podría ser una oportunidad para cubrir la necesidad de licencias activando las máquinas virtuales con SQL Server ya instalado. Para poder utilizar dichas imágenes para SAP, deben tenerse en cuenta las siguientes consideraciones:
- Las versiones de SQL Server que no son de evaluación incurren en costos más elevados que una máquina virtual exclusivamente con Windows implementada desde Azure Marketplace. Para comparar los precios, consulte Precios de máquinas virtuales Windows y Precios de máquinas virtuales SQL Server Enterprise.
- Solo se pueden usar las versiones de SQL Server compatibles con SAP.
- La intercalación de la instancia de SQL Server que está instalada en las máquinas virtuales que se ofrecen en Azure Marketplace no es la que requiere SAP NetWeaver para ejecutar la instancia de SQL Server. Puede cambiar la intercalación, aunque debe seguir las instrucciones de la sección que encontrará a continuación.
Modificación de la intercalación de SQL Server de una máquina virtual de Windows o SQL Server
Como las imágenes de SQL Server en Azure Marketplace no están configuradas para usar la intercalación, algo que necesitan las aplicaciones de SAP NetWeaver, debe modificarse inmediatamente después de llevar a cabo la implementación. Para SQL Server, este cambio de intercalación se puede efectuar siguiendo estos pasos en cuanto se haya implementado la máquina virtual y un administrador pueda iniciar sesión en la máquina virtual implementada:
- Abra una ventana de comandos de Windows como administrador.
- Cambie el directorio a C:\Archivos de programa\Microsoft SQL Server\110\Setup Bootstrap\SQLServer2012.
- Ejecute el comando: Setup.exe /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=MSSQLSERVER /SQLSYSADMINACCOUNTS=
<local_admin_account_name> /SQLCOLLATION=SQL_Latin1_General_Cp850_BIN2<local_admin_account_name> es la cuenta, que se definió como cuenta de administrador la primera vez que se implementó la máquina virtual por medio de la galería.
Este proceso solo debe llevar unos minutos. Para asegurarse de que obtiene el resultado correcto, realice los pasos siguientes:
- Abra SQL Server Management Studio.
- Abra una ventana de consulta.
- Ejecute el comando sp_helpsort en la base de datos maestra de SQL Server.
El resultado deberá ser similar al que se muestra a continuación:
Latin1-General, binary code point comparison sort for Unicode Data, SQL Server Sort Order 40 on Code Page 850 for non-Unicode Data
Si el resultado es diferente, DETENGA cualquier implementación e investigue por qué el comando de instalación no funcionó como se esperaba. Para implementaciones de NetWeaver, NO se admite la implementación de aplicaciones de SAP NetWeaver en la instancia de SQL Server con páginas de códigos de SQL Server distintas de la mencionada.
Alta disponibilidad de SQL Server para SAP en Azure
Si usa SQL Server en implementaciones de IaaS de Azure para SAP, dispondrá de distintas posibilidades para implementar la capa de DBMS de alta disponibilidad. Azure proporciona diferentes acuerdos de nivel de servicio en tiempo de disponibilidad para una sola máquina virtual mediante diferentes almacenamientos en bloques de Azure, un par de máquinas virtuales implementadas en un conjunto de disponibilidad de Azure o un par de máquinas virtuales implementadas en Azure Availability Zones. En el caso de los sistemas de producción, esperamos implementar un par de máquinas virtuales dentro de un conjunto de escalado de máquinas virtuales con orquestación flexible en dos zonas de disponibilidad. Consulte comparación de diferentes tipos de implementación para la carga de trabajo de SAP para obtener más información. Una máquina virtual ejecutará la instancia activa de SQL Server. La otra máquina virtual ejecutará la instancia pasiva.
Clústeres de SQL Server mediante el servidor de archivos de escalabilidad horizontal de Windows o un disco compartido de Azure
Con Windows Server 2016, Microsoft introdujo los espacios de almacenamiento directo. En función de la implementación de Espacios de almacenamiento directo, se admite la agrupación en clústeres de FCI de SQL Server en general. Azure también ofrece discos compartidos de Azure que podrían usarse para la agrupación en clústeres de Windows. En el caso de la carga de trabajo de SAP, no se admiten estas opciones de alta disponibilidad.
Trasvase de registros de SQL Server
Una funcionalidad de alta disponibilidad es el trasvase de registros de SQL Server. Si las máquinas virtuales que participan en la configuración de alta disponibilidad tienen resolución de nombres de trabajo, no hay ningún problema. La configuración en Azure no difiere de ninguna configuración que se realice localmente relacionada con la configuración del trasvase de registros y los principios en torno al trasvase de registros. En el artículo Acerca del trasvase de registros (SQL Server) encontrará información detallada sobre el trasvase de registros de SQL Server.
La funcionalidad de trasvase de registros de SQL Server apenas se usó en Azure para lograr una alta disponibilidad dentro de una región de Azure. En cambio, en los escenarios siguientes, los clientes de SAP usaban el trasvase de registros adecuadamente con Azure:
- Escenarios de recuperación ante desastres de una región de Azure a otra
- Configuración de la recuperación ante desastres de una ubicación local a una región de Azure
- Escenarios de migración de una ubicación local a Azure. En esos casos, se usa el trasvase de registros para sincronizar la nueva implementación de DBMS en Azure con el sistema de producción actual a nivel local. En el momento de la migración, el sistema de producción se apaga y se garantiza que las copias de seguridad del registro de transacciones más recientes se hayan transferido a la implementación del sistema de administración de bases de datos de Azure. Después, la implementación de DBMS de Azure se abre para producción.
SQL Server AlwaysOn
Como Always On se admite en el entorno local de SAP (consulte la nota de SAP #1772688), se puede usar en combinación con SAP en Azure. Hay algunas consideraciones especiales acerca de la implementación de la escucha de grupo de disponibilidad de SQL Server (no debe confundirse con el conjunto de disponibilidad de Azure). Por lo tanto, se necesitan algunos pasos de instalación diferentes.
Estas son algunas de las consideraciones que hay que tener en cuenta al usar un agente de escucha de grupo de disponibilidad:
- Solo se puede usar un agente de escucha de grupo de disponibilidad con Windows Server 2012 o posterior como SO invitado de la máquina virtual. Para Windows Server 2012, asegúrese de que se ha aplicado la actualización para habilitar Agentes de escucha del grupo de disponibilidad de SQL Server en Microsoft Azure Virtual Machines basada en Windows Server 2008 R2 y Windows Server 2012.
- Para Windows Server 2008 R2, esta revisión no existe. En este caso, Always On tendría que usarse de la misma manera que la creación de reflejo de la base de datos. Al especificar un asociado de conmutación por error en la cadena de conexiones (a través del parámetro de SAP default.pfl dbs/mss/server, consulte la nota de SAP #965908).
- Cuando se utiliza una escucha de grupo de disponibilidad, las máquinas virtuales de la base de datos tienen que conectarse a un equilibrador de carga dedicado. Debe asignar direcciones IP estáticas a las interfaces de red de esas máquinas virtuales en la configuración de Always On (la definición de una dirección IP estática se describe en este artículo). Las direcciones IP estáticas en comparación con DHCP impiden la asignación de nuevas direcciones IP en casos en los que ambas máquinas virtuales se pueden detener.
- Hay que realizar algunos pasos especiales al crear la configuración del clúster WSFC: el clúster necesita una dirección IP especial, ya la funcionalidad actual de Azure asignaría el nombre del clúster a la misma dirección IP que el nodo donde se ha creado dicho clúster. Este comportamiento significa que se debe realizar un paso manual para asignar una dirección IP diferente a la del clúster.
- El agente de escucha de grupo de disponibilidad se va a crear en Azure con puntos de conexión TCP/IP asignados a las máquinas virtuales que ejecutan las réplicas principal y secundarias del grupo de disponibilidad.
- Puede que haya que proteger estos puntos de conexión con ACL.
A continuación encontrará documentación detallada sobre cómo implementar AlwaysOn con SQL Server en máquinas virtuales de Azure:
- Introducción a los grupos de disponibilidad Always On de SQL Server en Azure Virtual Machines.
- Configuración de un grupo de disponibilidad AlwaysOn en máquinas virtuales de Azure en distintas regiones.
- Configuración de un equilibrador de carga para un grupo de disponibilidad AlwaysOn en Azure.
- Procedimientos recomendados para la configuración de HADR (SQL Server en Azure Virtual Machines)
Nota
Cuando lea Introducción a los grupos de disponibilidad Always On de SQL Server en Azure Virtual Machines, obtendrá información sobre el cliente de escucha Direct Network Name (DNN) de SQL Server. Esta funcionalidad nueva se introdujo con SQL Server 2019 CU8. Esta funcionalidad nueva hace que el uso de un equilibrador de carga de Azure que controle la dirección IP virtual del cliente de escucha del grupo de disponibilidad quede obsoleto.
SQL Server AlwaysOn es la funcionalidad de alta disponibilidad y de recuperación ante desastres de uso más común en Azure para las implementaciones de carga de trabajo de SAP. La mayoría de los clientes usan AlwaysOn para la alta disponibilidad en una única región de Azure. Si la implementación está restringida a solo dos nodos, tiene dos opciones de conectividad:
- Usar el agente de escucha de grupo de disponibilidad. Con la escucha del grupo de disponibilidad, deberá implementar una instancia de Azure Load Balancer.
- Con SQL Server 2016 SP3, SQL Server 2017 CU 25 o SQL Server 2019 CU8 o versiones más recientes de SQL Server en Windows Server 2016 o posterior, puede usar el agente de escucha de Nombre de red directa (DNN) en lugar de un equilibrador de carga de Azure. DNN elimina el requisito de usar un equilibrador de carga de Azure.
El uso de los parámetros de conectividad de la creación de reflejo de la base de datos de SQL Server solo debe tenerse en cuenta para la ronda de investigación de problemas con los otros dos métodos. En este caso, deberá configurar la conectividad de las aplicaciones de SAP de manera que se denominen ambos nombres de nodo. En la nota de SAP #965908 se documenta la información exacta de dicha configuración de SAP. Con esta opción no tendría que configurar ningún agente de escucha del grupo de disponibilidad Y con eso no hay equilibrador de carga de Azure y con eso podría investigar los problemas de esos componentes. Pero debe recordar que esta opción solo funciona si restringe el grupo de disponibilidad para que abarque dos instancias.
La mayoría de los clientes usan la funcionalidad AlwaysOn de SQL Server para la funcionalidad de recuperación ante desastres entre regiones de Azure. Muchos clientes también usan la capacidad de realizar copias de seguridad desde una réplica secundaria.
Cifrado de datos transparente de SQL Server
Muchos clientes usan el Cifrado de datos transparente (TDE) de SQL Server al implementar sus bases de datos de SQL Server de SAP en Azure. La funcionalidad de TDE de SQL Server es totalmente compatible con SAP (consulte la nota de SAP 1380493 #).
Aplicar el TDE de SQL Server
En los casos en que se efectúe una migración heterogénea desde otro DBMS, que se ejecuta en un entorno local, a Windows o SQL Server, que se ejecuta en Azure, se debería crear de antemano una base de datos de destino vacía en SQL Server. Como paso siguiente, aplicaría la funcionalidad TDE de SQL Server en esta base de datos vacía. El motivo de seguir esta secuencia es que el proceso de cifrado de la base de datos vacía puede tardar bastante. Luego, los procesos de importación SAP importarían los datos a la base de datos cifrada durante la fase de tiempo de inactividad. La sobrecarga de la importación a una base de datos cifrada tiene un impacto temporal mucho menor de manera que el cifrado de la base de datos después de la fase de exportación en la fase de tiempo de inactividad. Se han dado experiencias negativas al intentar aplicar TDE con la carga de trabajo de SAP en ejecución en la base de datos. Por lo tanto, se recomienda tratar la implementación de TDE como una actividad que debe llevarse a cabo con poca o ninguna carga de trabajo de SAP en la base de datos concreta. A partir de SQL Server 2016, puede detener y reanudar el examen de TDE que realiza el cifrado inicial. El documento Cifrado de datos transparente (TDE) describe el comando y los detalles.
En casos en los que se mueven bases de datos de SQL Server de SAP desde una ubicación local hasta Azure, se recomienda probar en qué infraestructura se puede aplicar con mayor rapidez el cifrado. Para esta caso, debe tener en cuenta estos factores:
- No puede definir la cantidad de subprocesos que se usan para aplicar el cifrado de datos a la base de datos. El número de subprocesos depende principalmente del número de volúmenes de disco por los que se distribuyen los datos y los archivos de registro de SQL Server. Significa que, cuantos más diferentes sean los volúmenes (letras de unidad), más subprocesos se ocuparán en paralelo para realizar el cifrado. Esta configuración se contradice un poco con una sugerencia anterior sobre la configuración de disco según la cual se crea uno o unos pocos espacios de almacenamiento para los archivos de base de datos de SQL Server en las máquinas virtuales de Azure. Una configuración con pocos volúmenes provocaría que unos pocos subprocesos ejecutaran el cifrado. Un cifrado de un único subproceso lee extensiones de 64 KB, las cifra y, después, escribe un registro en el archivo de registro de transacciones indicando que se ha cifrado la extensión. Como resultado, la carga en el registro de transacciones es moderada.
- En las versiones anteriores de SQL Server, la compresión de copia de seguridad ya no implicaba eficacia alguna al cifrar la base de datos de SQL Server. Este comportamiento podría convertirse en un problema si su idea era cifrar la base de datos de SQL Server de forma local y, después, copiar una copia de seguridad en Azure para restaurar la base de datos en Azure. La compresión de copia de seguridad de SQL Server puede generar una razón de compresión de factor 4.
- Con SQL Server 2016, SQL Server introdujo una nueva funcionalidad que también permite comprimir la copia de seguridad de bases de datos cifradas de una forma eficiente. Consulte este blog para obtener información detallada.
Uso de Azure Key Vault
Azure ofrece el servicio de un almacén de claves para almacenar claves de cifrado. Por otro lado, SQL Server ofrece un conector para usar Azure Key Vault como almacén para los certificados de TDE.
A continuación tiene más información detallada sobre cómo usar Azure Key Vault para el TDE de SQL Server:
- Configure la integración de Azure Key Vault para SQL Server en máquinas virtuales de Azure (Resource Manager).
- Más preguntas de los clientes sobre el cifrado de datos transparente de SQL Server – TDE + Azure Key Vault.
Importante
Con TDE de SQL Server, sobre todo con Azure Key Vault, se recomienda usar las revisiones más recientes de SQL Server 2014, SQL Server 2016 y SQL Server 2017. El motivo es que, a partir de los comentarios de los clientes, se aplicaron optimizaciones y correcciones al código. A modo de ejemplo, compruebe KBA #4058175.
Configuraciones de implementación mínimas
En esta sección, se sugiere un conjunto de configuraciones mínimas para diferentes tamaños de bases de datos en la carga de trabajo de SAP. Es demasiado difícil evaluar si estos tamaños se ajustan a su carga de trabajo específica. En algunos casos, podríamos ser generosos en la memoria en comparación con el tamaño de la base de datos. Por otro lado, el ajuste de tamaño del disco podría ser demasiado bajo para algunas de las cargas de trabajo. Por lo tanto, estas configuraciones deben tratarse como lo que son. Son configuraciones que deben proporcionarle un punto con el que empezar. Configuraciones para ajustar los requisitos específicos de carga de trabajo y rentabilidad.
Un ejemplo de una configuración para una instancia de SQL Server pequeña con un tamaño de base de datos de entre 50 GB y 250 GB podría ser similar a lo siguiente:
| Configuración | la máquina virtual DBMS | Comentarios |
|---|---|---|
| Tipo de máquina virtual | E4s_v3/v4/v5 (4 vCPU/32 GiB RAM) | |
| Redes aceleradas | Habilitar | |
| Versión de SQL Server | SQL Server 2019 o más reciente | |
| Número de archivos de datos | 4 | |
| Número de archivos de registro | 1 | |
| Número de archivos de datos temporales | 4 o valor predeterminado desde SQL Server 2016 | |
| Sistema operativo | Windows Server 2019 o más reciente | |
| Agregación de discos | Espacios de almacenamiento si se desea | |
| Sistema de archivos | NTFS | |
| Tamaño de bloque de formato | 64 KB | |
| N.º y tipo de discos de datos | Premium Storage v1: 2 x P10 (RAID0) Premium Storage v2: 2 x 150 GiB (RAID0): IOPS y rendimiento predeterminados |
Caché = solo lectura para Premium Storage v1 |
| N.º y tipo de discos de registro | Premium storage v1: 1 x P20 Premium Storage v2: 1 x 128 GiB: IOPS y rendimiento predeterminados |
Caché = NONE |
| Parámetro de memoria máxima de SQL Server | 90 % de RAM física | Suponiendo una sola instancia |
Un ejemplo de una configuración para una instancia de SQL Server pequeña con un tamaño de base de datos de entre 250 y 750 GB, como el sistema SAP Business Suite más pequeño, podría ser similar a lo siguiente:
| Configuración | la máquina virtual DBMS | Comentarios |
|---|---|---|
| Tipo de máquina virtual | E16s_v3/v4/v5 (16 vCPU/128 GiB RAM) | |
| Redes aceleradas | Habilitar | |
| Versión de SQL Server | SQL Server 2019 o más reciente | |
| Número de archivos de datos | 8 | |
| Número de archivos de registro | 1 | |
| Número de archivos de datos temporales | 8 o valor predeterminado desde SQL Server 2016 | |
| Sistema operativo | Windows Server 2019 o más reciente | |
| Agregación de discos | Espacios de almacenamiento si se desea | |
| Sistema de archivos | NTFS | |
| Tamaño de bloque de formato | 64 KB | |
| N.º y tipo de discos de datos | Premium Storage v1: 4 x P20 (RAID0) Premium Storage v2: 4 x 100 GiB - 200 GiB (RAID0): IOPS y 25 MB/s de rendimiento adicional por disco predeterminados |
Caché = solo lectura para Premium Storage v1 |
| N.º y tipo de discos de registro | Premium storage v1: 1 x P20 Premium Storage v2: 1 x 200 GiB: IOPS y rendimiento predeterminados |
Caché = NONE |
| Parámetro de memoria máxima de SQL Server | 90 % de RAM física | Suponiendo una sola instancia |
Un ejemplo de una configuración para una instancia de SQL Server mediana con un tamaño de base de datos entre 750 y 2000 GB, como un sistema SAP Business Suite mediano, podría ser similar a lo siguiente:
| Configuración | la máquina virtual DBMS | Comentarios |
|---|---|---|
| Tipo de máquina virtual | E64s_v3/v4/v5 (64 vCPU/432 GiB RAM) | |
| Redes aceleradas | Habilitar | |
| Versión de SQL Server | SQL Server 2019 o más reciente | |
| N.º de dispositivos de datos | 16 | |
| N.º de dispositivos de registro | 1 | |
| Número de archivos de datos temporales | 8 o valor predeterminado desde SQL Server 2016 | |
| Sistema operativo | Windows Server 2019 o más reciente | |
| Agregación de discos | Espacios de almacenamiento si se desea | |
| Sistema de archivos | NTFS | |
| Tamaño de bloque de formato | 64 KB | |
| N.º y tipo de discos de datos | Premium Storage v1: 4 x P30 (RAID0) Premium Storage v2: 4 x 250 GiB - 500 GiB - más 2000 IOPS y 75 MB/s de rendimiento por disco |
Caché = solo lectura para Premium Storage v1 |
| N.º y tipo de discos de registro | Premium storage v1: 1 x P20 Premium Storage v2: 1 x 400 GiB: IOPS y rendimiento adicional de 75 MB/s predeterminados |
Caché = NONE |
| Parámetro de memoria máxima de SQL Server | 90 % de RAM física | Suponiendo una sola instancia |
Un ejemplo de una configuración para una instancia de SQL Server más grande con un tamaño de base de datos entre 2000 y 4000 GB, como un sistema SAP Business Suite más grande, podría ser similar a lo siguiente:
| Configuración | la máquina virtual DBMS | Comentarios |
|---|---|---|
| Tipo de máquina virtual | E96(d)s_v5 (96 vCPU/672 GiB RAM) | |
| Redes aceleradas | Habilitar | |
| Versión de SQL Server | SQL Server 2019 o más reciente | |
| N.º de dispositivos de datos | 24 | |
| N.º de dispositivos de registro | 1 | |
| Número de archivos de datos temporales | 8 o valor predeterminado desde SQL Server 2016 | |
| Sistema operativo | Windows Server 2019 o más reciente | |
| Agregación de discos | Espacios de almacenamiento si se desea | |
| Sistema de archivos | NTFS | |
| Tamaño de bloque de formato | 64 KB | |
| N.º y tipo de discos de datos | Premium Storage v1: 4 x P30 (RAID0) Premium Storage v2: 4 x 500 GiB - 800 GiB - más 2500 IOPS y 100 MB/s de rendimiento por disco |
Caché = solo lectura para Premium Storage v1 |
| N.º y tipo de discos de registro | Premium storage v1: 1 x P20 Premium Storage v2: 1 x 400 GiB - más 1000 IOPS y 75 MB/s de rendimiento adicional |
Caché = NONE |
| Parámetro de memoria máxima de SQL Server | 90 % de RAM física | Suponiendo una sola instancia |
Un ejemplo de una configuración para una instancia de SQL Server grande con un tamaño de base de datos de más de 4 TB, como un sistema SAP Business Suite grande usado ampliamente, podría ser similar a lo siguiente:
| Configuración | la máquina virtual DBMS | Comentarios |
|---|---|---|
| Tipo de máquina virtual | Serie M (de 1,0 a 4,0 TB de RAM) | |
| Redes aceleradas | Habilitar | |
| Versión de SQL Server | SQL Server 2019 o más reciente | |
| N.º de dispositivos de datos | 32 | |
| N.º de dispositivos de registro | 1 | |
| Número de archivos de datos temporales | 8 o valor predeterminado desde SQL Server 2016 | |
| Sistema operativo | Windows Server 2019 o más reciente | |
| Agregación de discos | Espacios de almacenamiento si se desea | |
| Sistema de archivos | NTFS | |
| Tamaño de bloque de formato | 64 KB | |
| N.º y tipo de discos de datos | Premium Storage v1: 4+ x P40 (RAID0) Premium Storage v2: 4+ x 1000 GiB - 4000 GiB - más 4500 IOPS y 125 MB/s de rendimiento por disco |
Caché = solo lectura para Premium Storage v1 |
| N.º y tipo de discos de registro | Premium storage v1: 1 x P30 Premium Storage v2: 1 x 500 GiB - más 2000 IOPS y 125 MB/s de rendimiento |
Caché = NONE |
| Parámetro de memoria máxima de SQL Server | 90 % de RAM física | Suponiendo una sola instancia |
Por ejemplo, esta configuración es la configuración de máquina virtual de DBMS de SAP Business Suite en SQL Server. Esta máquina virtual hospeda la base de datos de 30 TB de la única instancia global de SAP Business Suite de una empresa global con unos ingresos anuales de más de 200 000 millones de dólares y más de 200 000 empleados a tiempo completo. El sistema ejecuta todo el procesamiento financiero, las ventas y el procesamiento de distribución y muchos más procesos empresariales de distintas áreas, incluidas las nóminas de Norteamérica. El sistema se ejecuta en Azure desde principios de 2018 mediante máquinas virtuales de la serie M de Azure como máquinas virtuales de DBMS. Como alta disponibilidad, el sistema usa Always On con una réplica sincrónica en otra zona de disponibilidad de la misma región de Azure y otra réplica asincrónica en otra región de Azure. El nivel de aplicación de NetWeaver se implementa en máquinas virtuales Ev4.
| Configuración | la máquina virtual DBMS | Comentarios |
|---|---|---|
| Tipo de máquina virtual | M192dms_v2 (192 vCPU/4,196 GiB RAM) | |
| Redes aceleradas | habilitado | |
| Versión de SQL Server | SQL Server 2019 | |
| Número de archivos de datos | 32 | |
| Número de archivos de registro | 1 | |
| Número de archivos de datos temporales | 8 | |
| Sistema operativo | Windows Server 2019 | |
| Agregación de discos | Espacios de almacenamiento | |
| Sistema de archivos | NTFS | |
| Tamaño de bloque de formato | 64 KB | |
| N.º y tipo de discos de datos | Premium Storage v1: 16 x P40 | Caché = Solo lectura |
| N.º y tipo de discos de registro | Premium Storage v1: 1 x P60 | Uso del Acelerador de escritura |
| Número y tipo de discos tempdb | Premium Storage v1: 1 x P30 | Sin almacenamiento en caché |
| Parámetro de memoria máxima de SQL Server | 90 % de RAM física |
Resumen general de SQL Server para SAP en Azure
En esta guía se ofrecen muchas recomendaciones: le sugerimos que la lea más de una vez antes de planear la implementación de Azure. En general, asegúrese de seguir las principales recomendaciones específicas de DBMS en Azure:
- Use la versión de DBMS más reciente, como SQL Server 2019, que presenta la mayoría de las ventajas de Azure.
- Planee cuidadosamente el panorama del sistema SAP en Azure para equilibrar el diseño del archivo de datos y las restricciones de Azure:
- No disponga de un número de discos demasiado elevado, solo el suficiente para asegurarse de que puede alcanzar los IOPS necesarios.
- Cree secciones en los discos solo si necesita obtener un mayor rendimiento.
- No disponga de un número de discos demasiado elevado, solo el suficiente para asegurarse de que puede alcanzar los IOPS necesarios.
- Nunca instale software ni coloque los archivos que requieren persistencia en la unidad D:\, ya que no es permanente y todos los datos que albergue se pueden perder tras reiniciar Windows o la máquina virtual.
- Utilice la solución de alta disponibilidad o recuperación ante desastres de su proveedor de DBMS para replicar datos de base de datos.
- Use siempre la resolución de nombres, no confíe exclusivamente en las direcciones IP.
- Con el TDE de SQL Server, aplique las revisiones más recientes de SQL Server.
- Tenga cuidado al utilizar imágenes de SQL Server de Azure Marketplace. Si lo hace, debe cambiar la intercalación de la instancia antes de instalar cualquier sistema SAP NetWeaver en ella.
- Instale y configure la funcionalidad de supervisión de hosts de SAP para Azure tal y como se describe en la Guía de implementación.
Pasos siguientes
Lea el artículo