Directivas de red de Azure Kubernetes
Las directivas de red proporcionan microsegmentación para pods del mismo modo que los grupos de seguridad de red (NSG) proporcionan microsegmentación para máquinas virtuales. La implementación de Azure Network Policy Manager admite la especificación de directiva de red de Kubernetes estándar. Puede usar etiquetas para seleccionar un grupo de pods y definir una lista de reglas de entrada y salida para filtrar tanto el tráfico que llega a estos pods como el que sale de ellos. Obtenga más información sobre las directivas de red de Kubernetes en la documentación de Kubernetes.
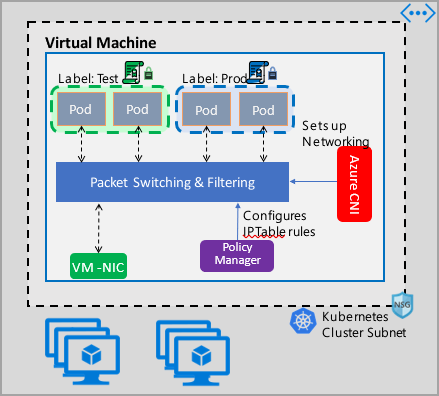
La implementación de Azure Network Policy Management funciona con Azure CNI que proporciona integración de red virtual para contenedores. Network Policy Manager es compatible con Linux y Windows Server. La implementación aplica el filtrado del tráfico mediante la configuración de reglas de IP de permiso y denegación basadas en las directivas definidas en Linux IPTables o ACLPolicies del servicio de red de host (HNS) para Windows Server.
Planeación de seguridad para el clúster de Kubernetes
Al implementar la seguridad del clúster, utilice grupos de seguridad red para filtrar el tráfico que entra y sale de la subred del clúster (tráfico de norte a sur). Use Azure Network Policy Manager para el tráfico entre los pods del clúster (tráfico de este a oeste).
Usar Azure Network Policy Manager
Azure Network Policy Manager puede usarse de las siguientes formas para proporcionar microsegmentación para los pods.
Azure Kubernetes Service (AKS)
Network Policy Manager está disponible de forma nativa en AKS y se puede habilitar en el momento de la creación del clúster.
Para más información, consulte Protección del tráfico entre pods mediante directivas de red en Azure Kubernetes Service (AKS).
Clústeres de Kubernetes personales (DIY) en Azure
En el caso de los clústeres DIY, en primer lugar, debe instalar el complemento de CNI y habilitarlo en todas las máquinas virtuales de un clúster. Para instrucciones detalladas, consulte Implementación del complemento para un clúster de Kubernetes que usted mismo haya implementado.
Una vez implementado el clúster, ejecute el siguiente comando kubectl para descargar y aplicar el daemonset de Azure Network Policy Manager en el clúster.
Para Linux:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
Para Windows:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
La solución también es de código abierto y el código está disponible en el repositorio de redes de Azure Container.
Supervisión y visualización de configuraciones de red con Azure NPM
Azure Network Policy Manager incluye métricas informativas de Prometheus que permiten supervisar y comprender mejor las configuraciones. Proporciona visualizaciones integradas en Azure Portal o en Grafana Labs. Puede empezar a recopilar estas métricas mediante Azure Monitor o un servidor de Prometheus.
Ventajas de las métricas de Azure Network Policy Manager
Anteriormente, los usuarios solo podían obtener información sobre su configuración de red con los comandos iptables y ipset, que se ejecutaban en un nodo de clúster, lo que genera una salida detallada y difícil de entender.
En general, las métricas proporcionan:
Recuentos de directivas, reglas de ACL, ipsets, entradas de ipset y entradas en cualquier ipset determinado
Tiempos de ejecución para llamadas individuales del sistema operativo y para controlar eventos de recursos de Kubernetes (mediana, percentil 90 y percentil 99)
Información de error para controlar eventos de recursos de Kubernetes (estos eventos de recursos generarán un error cuando se produzca un error en una llamada del sistema operativo)
Casos de uso de métricas de ejemplo
Alertas a través de AlertManager de Prometheus
Consulte una configuración para estas alertas a continuación.
Alerta cuando Network Policy Manager tiene un error con una llamada de sistema operativo o al traducir una directiva de red.
Alerta cuando el tiempo medio de aplicación de cambios para un evento de creación ha sido de más de 100 milisegundos.
Visualizaciones y depuración a través de nuestro panel de Grafana o libro de Azure Monitor
Vea cuántas reglas de IPTables crean las directivas (tener un gran número de reglas de IPTables puede aumentar ligeramente la latencia).
Correlacione los recuentos de clústeres (por ejemplo, ACL) con los tiempos de ejecución.
Obtenga el nombre descriptivo de un ipset en una regla IPTables determinada (por ejemplo,
azure-npm-487392representapodlabel-role:database).
Todas las métricas compatibles
A continuación se muestra una lista de métricas admitidas. Cualquier etiqueta quantile tiene los valores posibles 0.5, 0.9 y 0.99. Cualquier etiqueta had_error tiene los valores posibles false y true, que representa si la operación se realizó correctamente o no.
| Nombre de la métrica | Descripción | Tipo de métrica de Prometheus | Etiquetas |
|---|---|---|---|
npm_num_policies |
número de directivas de red | Indicador | - |
npm_num_iptables_rules |
número de reglas de IPTables | Indicador | - |
npm_num_ipsets |
número de IPSets | Indicador | - |
npm_num_ipset_entries |
número de entradas de dirección IP en todos los IPSets | Indicador | - |
npm_add_iptables_rule_exec_time |
runtime para agregar una regla IPTables | Resumen | quantile |
npm_add_ipset_exec_time |
runtime para agregar un IPSet | Resumen | quantile |
npm_ipset_counts (avanzado) |
número de entradas dentro de cada IPSet individual | GaugeVec | set_name & set_hash |
npm_add_policy_exec_time |
runtime para agregar una directiva de red | Resumen | quantile & had_error |
npm_controller_policy_exec_time |
runtime para actualizar o eliminar una directiva de red | Resumen | quantile y had_error y operation (con valores update o delete) |
npm_controller_namespace_exec_time |
runtime para crear, actualizar o eliminar un espacio de nombres | Resumen | quantile y had_error y operation (con valores create, update o delete) |
npm_controller_pod_exec_time |
runtime para crear, actualizar o eliminar un pod | Resumen | quantile y had_error y operation (con valores create, update o delete) |
Hay también las métricas "exec_time_count" y "exec_time_sum" para cada métrica de resumen "exec_time".
Las métricas se pueden extraer mediante Azure Monitor para contenedores o mediante Prometheus.
Configuración de Azure Monitor
El primer paso es habilitar Azure Monitor para contenedores para un clúster de Kubernetes. Los pasos se pueden encontrar en Introducción a Azure Monitor para contenedores. Una vez que Azure Monitor para contenedores está habilitado, configure ConfigMap de Azure Monitor para contenedores para habilitar la integración de Network Policy Manager y la recopilación de métricas de Network Policy Manager de Prometheus.
ConfigMap Azure Monitor para contenedores tiene una sección integrations con la configuración para recopilar métricas de Network Policy Manager.
Esta configuración está deshabilitada de forma predeterminada en ConfigMap. La habilitación de la configuración básica collect_basic_metrics = true recopila métricas básicas de Network Policy Manager. La habilitación de la configuración avanzada collect_advanced_metrics = true recopila métricas avanzadas, además de las métricas básicas.
Después de editar ConfigMap, guárdelo localmente y aplique ConfigMap al clúster como se indica a continuación.
kubectl apply -f container-azm-ms-agentconfig.yaml
El siguiente fragmento de código de ConfigMap de Azure Monitor para contenedores muestra la integración de Network Policy Manager habilitada con la recopilación de métricas avanzadas.
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
Las métricas avanzadas son opcionales y al activarlas, se activa automáticamente la recopilación de métricas básicas. Actualmente, las métricas avanzadas solo incluyen Network Policy Manager_ipset_counts.
Más información acerca de la configuración de la colección de la recopilación de Azure Monitor para contenedores en ConfigMap.
Opciones de visualización para Azure Monitor
Una vez habilitada la recopilación de métricas de Network Policy Manager, estas se pueden ver en Azure Portal mediante Container Insights o en Grafana.
Visualización en Azure Portal en la sección Información del clúster
Abra Azure Portal. Una vez en la sección Información del clúster, vaya a Libros y abra Configuración de Network Policy Manager (NPM).
Además de ver el libro, también puede consultar directamente las métricas de Prometheus en "Registros", en la sección Información. Por ejemplo, esta consulta devuelve todas las métricas que se recopilan.
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
También puede consultar las métricas directamente en Log Analytics. Para más información, vea Introducción a las consultas de Log Analytics.
Visualización en un panel de Grafana
Configure un servidor de Grafana y un origen de datos de Log Analytics como se describe aquí. Luego, importe el panel de Grafana con un back-end de Log Analytics en Grafana Labs.
El panel tiene objetos visuales similares al libro de Azure. Puede agregar paneles para crear gráficos y visualizar métricas de Network Policy Manager desde la tabla InsightsMetrics.
Configuración del servidor de Prometheus
Algunos usuarios pueden optar por recopilar métricas con un servidor de Prometheus, en lugar de con Azure Monitor para contenedores. Basta con agregar dos trabajos a la configuración de rechazo para recopilar métricas de Network Policy Manager.
Para instalar un servidor de Prometheus, agregue este repositorio de Helm al clúster:
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
luego agregue un servidor
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
donde prometheus-server-scrape-config.yaml consta de:
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
También puede reemplazar el trabajo azure-npm-node-metrics por el contenido que aparece a continuación, o bien incorporarlo a un trabajo existente para pods de Kubernetes:
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Configuración de alertas para AlertManager
Si usa un servidor de Prometheus, puede configurar AlertManager de este modo. Esta es una configuración de ejemplo para las dos reglas de alertas descritas anteriormente:
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
Opciones de visualización para Prometheus
Cuando se usa un servidor de Prometheus, solo se admite el panel de Grafana.
Si aún no lo ha hecho, configure el servidor de Grafana y, después, un origen de datos de Prometheus. Luego, importe nuestro panel de Grafana con un back-end de Prometheus en Grafana Labs.
Los objetos visuales de este panel son idénticos los del panel con back-end de información de Container Insights o Log Analytics.
Paneles de ejemplo
A continuación, encontrará un panel de ejemplo para las métricas de Network Policy Manager en Container Insights (CI) y Grafana.
Resumen de recuentos de CI
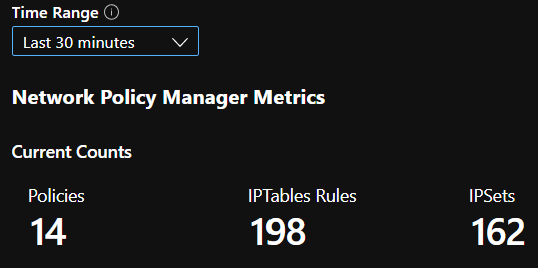
Recuentos de CI con el paso del tiempo

Entradas de IPSet de CI

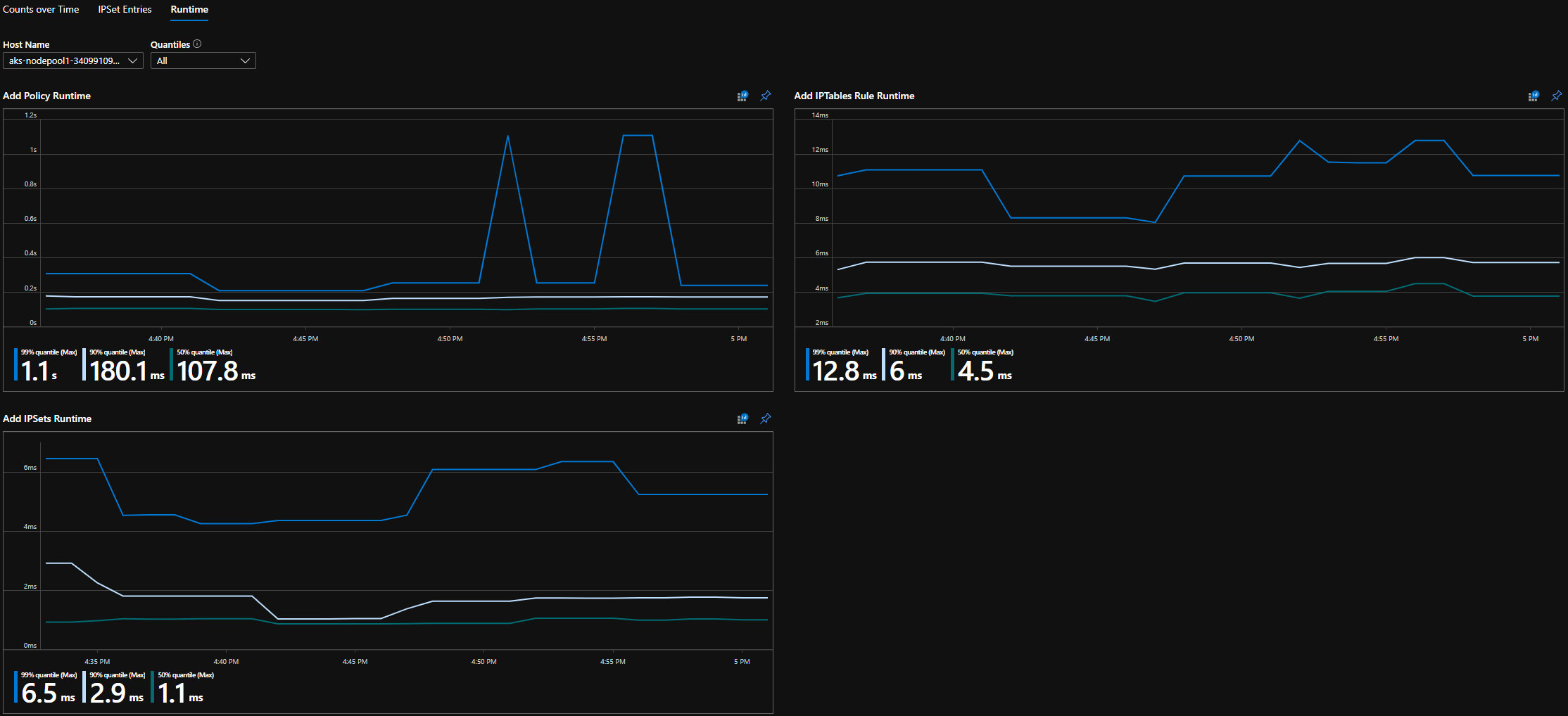
Cuantiles en tiempo de ejecución de CI
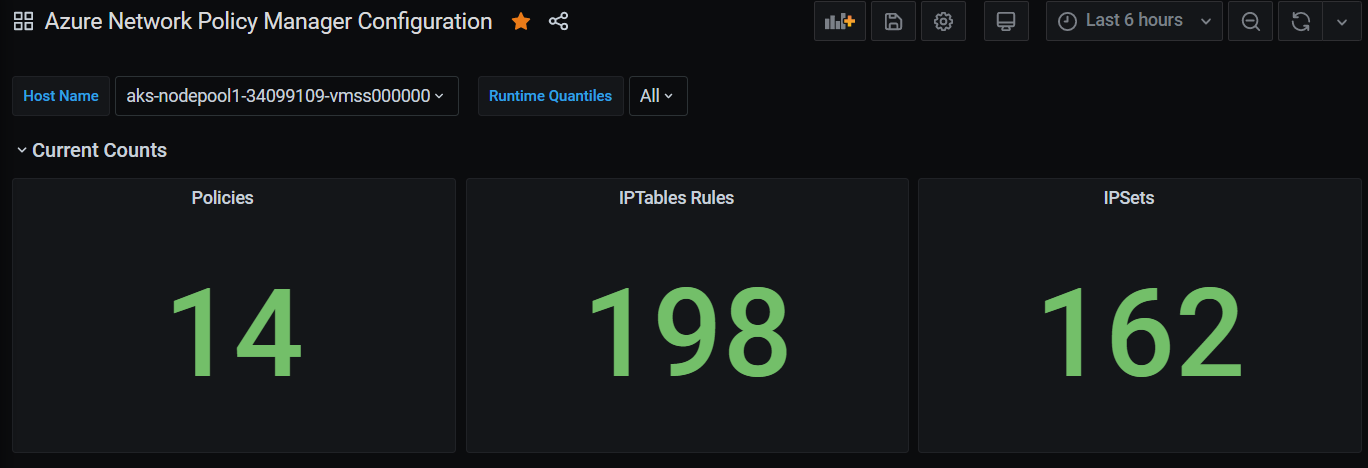
Resumen de recuentos del panel de Grafana
Recuentos del panel de Grafana a lo largo del tiempo

Entradas de IPSet del panel de Grafana

Cuantiles en tiempo de ejecución del panel de Grafana

Pasos siguientes
Obtenga más información acerca de Azure Kubernetes Service.
Obtenga más información acerca de redes de contenedores.
Implemente el complemento para clústeres de Kubernetes o contenedores de Docker.