Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Para detectar actividades malintencionadas, cada uno de los servicios en línea de Microsoft registra de forma centralizada eventos de seguridad y otros datos y realiza diversas técnicas analíticas para encontrar actividades anómalas o sospechosas. Los archivos de registro se recopilan de servidores de Microsoft servicios en línea y dispositivos de infraestructura y se almacenan en bases de datos centrales y consolidadas.
Microsoft adopta un enfoque basado en riesgos para detectar actividades malintencionadas. Usamos datos de incidentes e inteligencia sobre amenazas para definir y priorizar nuestras detecciones.
El empleo de un equipo de personas altamente experimentadas, competentes y cualificadas es uno de los pilares más importantes para el éxito en la fase de detección y análisis. Microsoft emplea varios equipos de servicio que incluyen empleados con competencias en todos los componentes de la pila, incluidos la red, enrutadores, firewalls, equilibradores de carga, sistemas operativos y aplicaciones.
Los mecanismos de detección de seguridad de Microsoft servicios en línea también incluyen notificaciones y alertas iniciadas por diferentes orígenes. Los equipos de respuesta de seguridad de Microsoft servicios en línea son los orquestadores clave del proceso de escalado de incidentes de seguridad. Estos equipos reciben todas las escalaciones y son responsables de analizar y confirmar la validez del incidente de seguridad.
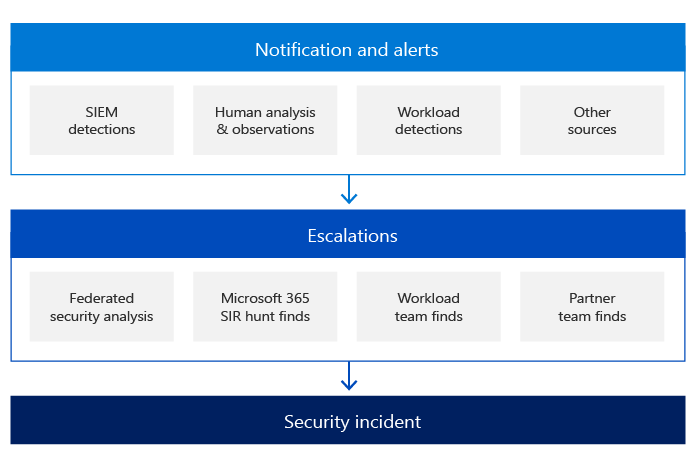
Uno de los pilares principales de la detección es la notificación:
- Cada equipo de servicio es responsable de registrar cualquier acción o evento dentro del servicio en función de los requisitos del equipo de seguridad del servicio en línea. Todos los registros creados por los distintos equipos de servicio se procesan mediante una solución de administración de eventos e información de seguridad (SIEM) con reglas de seguridad y detección predefinidas. Estas reglas evolucionan en función de las recomendaciones del equipo de seguridad, sobre la información obtenida de incidentes de seguridad anteriores, para determinar si hay alguna actividad sospechosa o malintencionada.
- Si un cliente determina que hay un incidente de seguridad en curso, puede abrir un caso de soporte técnico con Microsoft, que se asigna al equipo de comunicaciones de Microsoft y se convierte en una escalación a todos los equipos adecuados.
Los equipos de servicio de Azure, Dynamics 365 y Microsoft 365 también usan la inteligencia obtenida en el análisis de tendencias a través de la supervisión y el registro de seguridad para detectar anomalías en los sistemas de información de Microsoft servicios en línea que podrían indicar un ataque o un incidente de seguridad. Los sistemas de Microsoft servicios en línea agregan la salida de estos registros en el entorno de producción a servidores de registro centralizados. Desde estos servidores de registro centralizados, los registros se examinan para detectar tendencias en todo el entorno de producción. Los datos agregados en los servidores centralizados se transmiten de forma segura a un servicio de registro para realizar consultas avanzadas, compilar paneles y detectar actividades anómalas y malintencionadas. El servicio también usa el aprendizaje automático para detectar anomalías con la salida del registro.
Durante la fase de escalado y en función de la naturaleza del incidente de seguridad, los equipos de respuesta de seguridad pueden interactuar con uno o varios expertos en la materia de varios equipos de Microsoft:
- Equipo de seguridad y cumplimiento de Servicios en línea
- Centro de inteligencia sobre amenazas de Microsoft (MSTIC)
- Centro de respuesta de seguridad de Microsoft (MSRC)
- Asuntos Corporativos, Externos y Jurídicos (CELA)
- Seguridad de Azure
- Ingeniería de Microsoft 365 y otros.
Antes de que se produzca una escalación a cualquier equipo de respuesta de seguridad, el equipo de servicio es responsable de determinar y establecer el nivel de gravedad del incidente de seguridad en función de criterios definidos como:
- Privacidad
- Impacto
- Ámbito
- Número de inquilinos afectados
- Región
- Servicio
- Detalles del incidente
- Regulaciones específicas del sector de clientes o del mercado.
La priorización de incidentes se determina mediante distintos factores, incluidos, entre otros, el impacto funcional del incidente, el impacto informativo del incidente y la capacidad de recuperación del incidente.
Después de recibir una escalación sobre un incidente de seguridad, el equipo de seguridad organiza un equipo virtual (equipo virtual) compuesto por miembros del equipo de respuesta de seguridad del servicio en línea de Microsoft, los equipos de servicio y el equipo de comunicación de incidentes. A continuación, el equipo virtual debe confirmar la legitimidad del incidente de seguridad y eliminar los falsos positivos. La precisión de la información proporcionada por los indicadores determinados durante la fase de preparación es crítica. Mediante el análisis de esta información por categoría de ataque vectorial, el equipo virtual puede determinar si el incidente de seguridad es una preocupación legítima.
Al principio de la investigación, el equipo de respuesta a incidentes de seguridad registra toda la información sobre el incidente de acuerdo con nuestras directivas de administración de casos. A medida que avanza el caso, realizamos un seguimiento de las acciones en curso y seguimos los estándares de control de pruebas para recopilar, conservar y proteger estos datos a lo largo del ciclo de vida de los incidentes.
Algunos ejemplos de estas acciones incluyen:
- Un resumen, que es una breve descripción del incidente y su posible impacto
- La gravedad y prioridad del incidente, que se derivan mediante la evaluación del posible impacto
- Una lista de todos los indicadores identificados que condujeron a la detección del incidente
- Una lista de cualquier incidente relacionado
- Una lista de todas las acciones realizadas por el equipo virtual
- Cualquier evidencia recopilada, que también se conservará para el análisis post-mortem y futuras investigaciones forenses
- Acciones y pasos siguientes recomendados
Después de la confirmación del incidente de seguridad, los objetivos principales del equipo de respuesta de seguridad y del equipo de servicio adecuado son contener el ataque, proteger los servicios bajo ataque y evitar un mayor impacto global. Al mismo tiempo, los equipos de ingeniería adecuados trabajan para determinar la causa principal y preparar el primer plan de recuperación.
En la fase siguiente, el equipo de respuesta de seguridad identifica a los clientes afectados por el incidente de seguridad, si los hubiera. El ámbito de efecto puede tardar algún tiempo en determinar, en función de la región, el centro de datos, el servicio, la granja de servidores, el servidor, etc. La lista de clientes afectados la compilan el equipo de servicio y el equipo de comunicaciones de Microsoft correspondiente, que luego controlan el proceso de notificación del cliente dentro de las obligaciones contractuales y de cumplimiento.
Artículos relacionados
- Administración de incidentes de seguridad de Microsoft
- Administración de incidentes de seguridad de Microsoft: Preparación
- Administración de incidentes de seguridad de Microsoft: contención, erradicación y recuperación
- Administración de incidentes de seguridad de Microsoft: actividad posterior al incidente
- Registro de una incidencia de soporte técnico de eventos de seguridad
- Azure y Dynamics 365 notificación de infracciones bajo el GDPR