Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El 📦 paquete Microsoft.Extensions.DataIngestion proporciona bloques de creación fundamentales de .NET para la ingesta de datos. Permite a los desarrolladores leer, procesar y preparar documentos para flujos de trabajo de inteligencia artificial y aprendizaje automático, especialmente en escenarios de Retrieval-Augmented Generation (RAG).
Con estos bloques de creación, puede crear canalizaciones de ingesta de datos sólidas, flexibles e inteligentes adaptadas a sus necesidades de aplicación:
- Representación unificada del documento: Represente cualquier tipo de archivo (por ejemplo, PDF, Imagen o Microsoft Word) en un formato coherente que funcione bien con modelos de lenguaje grandes.
- Ingesta de datos flexible: Lea documentos tanto de servicios en la nube como de orígenes locales mediante varios lectores integrados, lo que facilita la incorporación de datos desde cualquier lugar donde resida.
- Mejoras integradas en la inteligencia artificial: Enriquecer automáticamente el contenido con resúmenes, análisis de sentimiento, extracción de palabras clave y clasificación, preparando los datos para flujos de trabajo inteligentes.
- Estrategias de fragmentación personalizables: Divida los documentos en fragmentos mediante enfoques basados en tokens, basados en secciones o con reconocimiento semántico, para que pueda optimizar las necesidades de recuperación y análisis.
- Almacenamiento listo para producción: Almacene fragmentos procesados en bases de datos vectoriales populares y almacenes de documentos, con compatibilidad para la generación de incrustaciones, lo que hace que las canalizaciones estén listas para escenarios reales.
- Composición de canalización de un extremo a otro: Encadene lectores, procesadores, fragmentadores y escritores con la IngestionPipeline<T> API, lo que reduce el código repetitivo y facilita la construcción, personalización y ampliación de flujos de trabajo completos.
- Rendimiento y escalabilidad: Diseñado para el procesamiento de datos escalable, estos componentes pueden controlar grandes volúmenes de datos de forma eficaz, por lo que son adecuados para aplicaciones de nivel empresarial.
Todos estos componentes están abiertos y extensibles por diseño. Puede agregar lógica personalizada y nuevos conectores y ampliar el sistema para admitir escenarios emergentes de inteligencia artificial. Al estandarizar cómo se representan, procesan y almacenan documentos, los desarrolladores de .NET pueden crear canalizaciones de datos confiables, escalables y fáciles de mantener sin "reinventar la rueda" para cada proyecto.
Construido sobre bases estables
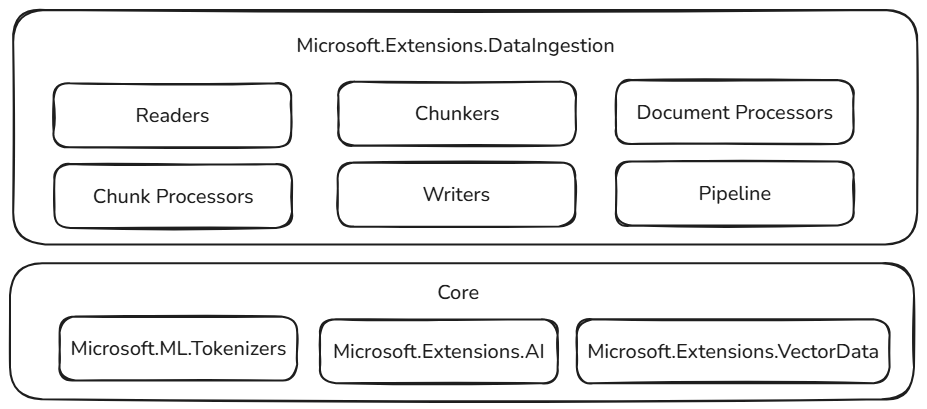
Estos bloques de creación de ingesta de datos se basan en componentes probados y extensibles en el ecosistema de .NET, lo que garantiza la confiabilidad, la interoperabilidad y la integración sin problemas con los flujos de trabajo de IA existentes:
- Microsoft.ML.Tokenizers: Los tokenizadores proporcionan la base para fragmentar documentos basados en tokens. Esto permite la división precisa del contenido, que es esencial para preparar datos para modelos de lenguaje grandes y optimizar las estrategias de recuperación.
- Microsoft.Extensions.AI: Este conjunto de bibliotecas potencia las transformaciones de enriquecimiento mediante modelos de lenguaje grandes. Permite características como el resumen, el análisis de sentimiento, la extracción de palabras clave y la generación de inserción, lo que facilita la mejora de los datos con información inteligente.
- Microsoft.Extensions.VectorData: Este conjunto de bibliotecas ofrece una interfaz coherente para almacenar fragmentos procesados en una amplia variedad de almacenes vectoriales, como Qdrant, Azure SQL, CosmosDB, MongoDB, ElasticSearch y muchos más. Esto garantiza que las canalizaciones de datos están listas para producción y se pueden escalar entre distintos back-end de almacenamiento.
Además de patrones y herramientas conocidos, estas abstracciones se basan en componentes ya extensibles. La funcionalidad del complemento y la interoperabilidad son primordiales, por lo que el resto del ecosistema de inteligencia artificial de .NET crece, también crecen las funcionalidades de los componentes de ingesta de datos. Este enfoque permite a los desarrolladores integrar fácilmente nuevos proveedores, enriquecimientos y opciones de almacenamiento, manteniendo sus canalizaciones listas para el futuro y adaptables a escenarios de inteligencia artificial en constante evolución.
Consulte también
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.