Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial, creará una aplicación MSTest para evaluar la respuesta de chat de un modelo de OpenAI. La aplicación de prueba usa el Microsoft. Extensions.AI.Evaluation bibliotecas para realizar las evaluaciones, almacenar en caché las respuestas del modelo y crear informes. En el tutorial se usan evaluadores integrados y personalizados. Evaluadores de calidad integrados (del paquete Microsoft.Extensions.AI.Evaluation.Quality) usan un LLM para realizar evaluaciones; el evaluador personalizado no usa IA.
Prerrequisitos
- .NET 8 o una versión posterior
- Visual Studio Code (opcional)
Configuración del servicio de IA
Para aprovisionar un Azure OpenAI service y un modelo mediante el portal de Azure, complete los pasos descritos en el artículo Crear e implementar un recurso de Azure OpenAI Service. En el paso "Implementar un modelo", seleccione el modelo gpt-5.
Creación de la aplicación de prueba
Complete los pasos siguientes para crear un proyecto de MSTest que se conecte a un modelo de IA.
En una ventana de terminal, vaya al directorio donde desea crear la aplicación y cree una aplicación MSTest con el
dotnet newcomando :dotnet new mstest -o TestAIWithReportingVaya al directorio
TestAIWithReportingy agregue los paquetes necesarios a la aplicación:dotnet add package Azure.AI.OpenAI dotnet add package Azure.Identity dotnet add package Microsoft.Extensions.AI.Abstractions dotnet add package Microsoft.Extensions.AI.Evaluation dotnet add package Microsoft.Extensions.AI.Evaluation.Quality dotnet add package Microsoft.Extensions.AI.Evaluation.Reporting dotnet add package Microsoft.Extensions.AI.OpenAI dotnet add package Microsoft.Extensions.Configuration dotnet add package Microsoft.Extensions.Configuration.UserSecretsEjecute los siguientes comandos para añadir secretos de aplicación para el punto de conexión de Azure OpenAI y el identificador de inquilino:
dotnet user-secrets init dotnet user-secrets set AZURE_OPENAI_ENDPOINT <your-Azure-OpenAI-endpoint> dotnet user-secrets set AZURE_TENANT_ID <your-tenant-ID>(Dependiendo de su entorno, es posible que no se necesite el identificador de inquilino. En ese caso, quítelo del código que crea una instancia de DefaultAzureCredential.
Abra la nueva aplicación en el editor que prefiera.
Adición del código de la aplicación de prueba
Cambie el nombre del archivo Test1.cs a MyTests.cs y, a continuación, abra el archivo y cambie el nombre de la clase a
MyTests. Elimine el método vacíoTestMethod1.Agregue las directivas necesarias
usinga la parte superior del archivo.using Azure.AI.OpenAI; using Azure.Identity; using Microsoft.Extensions.AI.Evaluation; using Microsoft.Extensions.AI; using Microsoft.Extensions.Configuration; using Microsoft.Extensions.AI.Evaluation.Reporting.Storage; using Microsoft.Extensions.AI.Evaluation.Reporting; using Microsoft.Extensions.AI.Evaluation.Quality;Agregue la TestContext propiedad a la clase .
// The value of the TestContext property is populated by MSTest. public TestContext? TestContext { get; set; }Agregue el
GetAzureOpenAIChatConfigurationmétodo , que crea el IChatClient que usa el evaluador para comunicarse con el modelo.private static ChatConfiguration GetAzureOpenAIChatConfiguration() { IConfigurationRoot config = new ConfigurationBuilder().AddUserSecrets<MyTests>().Build(); string endpoint = config["AZURE_OPENAI_ENDPOINT"]; string tenantId = config["AZURE_TENANT_ID"]; string model = "gpt-5"; // Get an instance of Microsoft.Extensions.AI's <see cref="IChatClient"/> // interface for the selected LLM endpoint. AzureOpenAIClient azureClient = new( new Uri(endpoint), new DefaultAzureCredential(new DefaultAzureCredentialOptions() { TenantId = tenantId })); IChatClient client = azureClient.GetChatClient(deploymentName: model).AsIChatClient(); // Create an instance of <see cref="ChatConfiguration"/> // to communicate with the LLM. return new ChatConfiguration(client); }Configure la funcionalidad de informes.
private string ScenarioName => $"{TestContext!.FullyQualifiedTestClassName}.{TestContext.TestName}"; private static string ExecutionName => $"{DateTime.Now:yyyyMMddTHHmmss}"; private static readonly ReportingConfiguration s_defaultReportingConfiguration = DiskBasedReportingConfiguration.Create( storageRootPath: "C:\\TestReports", evaluators: GetEvaluators(), chatConfiguration: GetAzureOpenAIChatConfiguration(), enableResponseCaching: true, executionName: ExecutionName);Nombre del escenario
El nombre del escenario se establece en el nombre completo del método de prueba actual. Sin embargo, puede establecerlo en cualquier cadena cuando llame a CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken). Tenga en cuenta estos factores al elegir un nombre de escenario:
- Al usar el almacenamiento basado en disco, el nombre del escenario se usa como nombre de la carpeta en la que se almacenan los resultados de evaluación correspondientes. Por lo tanto, es una buena idea mantener el nombre razonablemente corto y evitar los caracteres que no se permiten en los nombres de archivo y directorio.
- De forma predeterminada, el informe de evaluación generado divide los nombres de los escenarios en
.para que los resultados se muestren en una vista jerárquica con la agrupación, el anidamiento y la agregación adecuadas. La vista jerárquica es especialmente útil cuando el nombre del escenario es el nombre completo del método de prueba correspondiente, ya que agrupa los resultados por espacios de nombres y nombres de clase en la jerarquía. Sin embargo, también puede aprovechar esta característica mediante la inclusión de puntos (.) en sus propios nombres de escenario personalizados para crear una jerarquía de informes que funcione mejor en sus escenarios.
Nombre de ejecución
El nombre de ejecución se usa para agrupar los resultados de evaluación que forman parte de la misma ejecución de evaluación (o ejecución de prueba) cuando se almacenan los resultados de la evaluación. Si no proporciona un nombre de ejecución al crear un ReportingConfiguration, todas las ejecuciones de evaluación usan el mismo nombre de ejecución predeterminado de
Default. En este caso, los resultados de una ejecución se sobrescriben mediante la siguiente y se pierde la capacidad de comparar los resultados entre distintas ejecuciones.En este ejemplo se usa una marca de tiempo como nombre de ejecución. Si tiene más de una prueba en el proyecto, asegúrese de que los resultados se agrupan correctamente mediante el mismo nombre de ejecución en todas las configuraciones de informes usadas en las pruebas.
En una situación más real, también podría querer compartir el mismo nombre de ejecución en las pruebas de evaluación que residen en varios ensamblados y se ejecutan en distintos procesos de prueba. En tales casos, podría usar un script para actualizar una variable de entorno con un nombre de ejecución adecuado (como el número de compilación actual asignado por el sistema de CI/CD) antes de ejecutar las pruebas. O bien, si el sistema de compilación genera versiones de archivo de ensamblado que aumentan de forma monotónica, puede leer el elemento AssemblyFileVersionAttribute desde dentro del código de prueba y usarlo como nombre de ejecución para comparar los resultados en distintas versiones del producto.
Configuración de informes
Un ReportingConfiguration identifica:
- Conjunto de evaluadores que se deben invocar para cada uno de los ScenarioRun creados mediante una llamada a CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken).
- Punto de conexión de LLM que deben usar los evaluadores (consulte ReportingConfiguration.ChatConfiguration).
- Cómo y dónde se deben almacenar los resultados de las ejecuciones del escenario.
- Cómo se deben almacenar en caché las respuestas de LLM relacionadas con las ejecuciones del escenario.
- Nombre de ejecución que se debe usar al notificar los resultados de las ejecuciones del escenario.
Esta prueba usa una configuración de informes basada en disco.
En un archivo independiente, agregue la
WordCountEvaluatorclase , que es un evaluador personalizado que implementa IEvaluator.using System.Text.RegularExpressions; using Microsoft.Extensions.AI; using Microsoft.Extensions.AI.Evaluation; namespace TestAIWithReporting; public class WordCountEvaluator : IEvaluator { public const string WordCountMetricName = "Words"; public IReadOnlyCollection<string> EvaluationMetricNames => [WordCountMetricName]; /// <summary> /// Counts the number of words in the supplied string. /// </summary> private static int CountWords(string? input) { if (string.IsNullOrWhiteSpace(input)) { return 0; } MatchCollection matches = Regex.Matches(input, @"\b\w+\b"); return matches.Count; } /// <summary> /// Provides a default interpretation for the supplied <paramref name="metric"/>. /// </summary> private static void Interpret(NumericMetric metric) { if (metric.Value is null) { metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unknown, failed: true, reason: "Failed to calculate word count for the response."); } else { if (metric.Value <= 100 && metric.Value > 5) metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Good, reason: "The response was between 6 and 100 words."); else metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unacceptable, failed: true, reason: "The response was either too short or greater than 100 words."); } } public ValueTask<EvaluationResult> EvaluateAsync( IEnumerable<ChatMessage> messages, ChatResponse modelResponse, ChatConfiguration? chatConfiguration = null, IEnumerable<EvaluationContext>? additionalContext = null, CancellationToken cancellationToken = default) { // Count the number of words in the supplied <see cref="modelResponse"/>. int wordCount = CountWords(modelResponse.Text); string reason = $"This {WordCountMetricName} metric has a value of {wordCount} because " + $"the evaluated model response contained {wordCount} words."; // Create a <see cref="NumericMetric"/> with value set to the word count. // Include a reason that explains the score. var metric = new NumericMetric(WordCountMetricName, value: wordCount, reason); // Attach a default <see cref="EvaluationMetricInterpretation"/> for the metric. Interpret(metric); return new ValueTask<EvaluationResult>(new EvaluationResult(metric)); } }WordCountEvaluatorCuenta el número de palabras presentes en la respuesta. A diferencia de algunos evaluadores, no se basa en la inteligencia artificial. ElEvaluateAsyncmétodo devuelve un EvaluationResult que incluye un NumericMetric que contiene el recuento de palabras.El
EvaluateAsyncmétodo también asocia una interpretación predeterminada a la métrica. La interpretación predeterminada considera que la métrica es buena (aceptable) si el recuento de palabras detectado está comprendido entre 6 y 100. De lo contrario, la métrica se considera errónea. El autor de la llamada puede invalidar esta interpretación predeterminada si es necesario.De nuevo en
MyTests.cs, agregue un método para recopilar los evaluadores que se van a usar en la evaluación.private static IEnumerable<IEvaluator> GetEvaluators() { IEvaluator relevanceEvaluator = new RelevanceEvaluator(); IEvaluator coherenceEvaluator = new CoherenceEvaluator(); IEvaluator wordCountEvaluator = new WordCountEvaluator(); return [relevanceEvaluator, coherenceEvaluator, wordCountEvaluator]; }Agregue un método para agregar un símbolo del sistema ChatMessage, defina las opciones de chat y pida al modelo una respuesta a una pregunta determinada.
private static async Task<(IList<ChatMessage> Messages, ChatResponse ModelResponse)> GetAstronomyConversationAsync( IChatClient chatClient, string astronomyQuestion) { const string SystemPrompt = """ You're an AI assistant that can answer questions related to astronomy. Keep your responses concise and under 100 words. Use the imperial measurement system for all measurements in your response. """; IList<ChatMessage> messages = [ new ChatMessage(ChatRole.System, SystemPrompt), new ChatMessage(ChatRole.User, astronomyQuestion) ]; var chatOptions = new ChatOptions { Temperature = 0.0f, ResponseFormat = ChatResponseFormat.Text }; ChatResponse response = await chatClient.GetResponseAsync(messages, chatOptions); return (messages, response); }La prueba de este tutorial evalúa la respuesta de LLM a una pregunta de astronomía. Dado que el ReportingConfiguration tiene habilitado el almacenamiento en caché de respuestas, y dado que el IChatClient suministrado siempre se obtiene del ScenarioRun creado mediante la configuración de este informe, la respuesta del LLM para la prueba se almacena en caché y se reutiliza. La respuesta se reutiliza hasta que expire la entrada de caché correspondiente (en 14 días de forma predeterminada) o hasta que cambie cualquier parámetro de solicitud, como el punto de conexión LLM o la pregunta formulada.
Agregue un método para validar la respuesta.
/// <summary> /// Runs basic validation on the supplied <see cref="EvaluationResult"/>. /// </summary> private static void Validate(EvaluationResult result) { // Retrieve the score for relevance from the <see cref="EvaluationResult"/>. NumericMetric relevance = result.Get<NumericMetric>(RelevanceEvaluator.RelevanceMetricName); Assert.IsFalse(relevance.Interpretation!.Failed, relevance.Reason); Assert.IsTrue(relevance.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the score for coherence from the <see cref="EvaluationResult"/>. NumericMetric coherence = result.Get<NumericMetric>(CoherenceEvaluator.CoherenceMetricName); Assert.IsFalse(coherence.Interpretation!.Failed, coherence.Reason); Assert.IsTrue(coherence.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the word count from the <see cref="EvaluationResult"/>. NumericMetric wordCount = result.Get<NumericMetric>(WordCountEvaluator.WordCountMetricName); Assert.IsFalse(wordCount.Interpretation!.Failed, wordCount.Reason); Assert.IsTrue(wordCount.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); Assert.IsFalse(wordCount.ContainsDiagnostics()); Assert.IsTrue(wordCount.Value > 5 && wordCount.Value <= 100); }Sugerencia
Las métricas incluyen una
Reasonpropiedad que explica el razonamiento de la puntuación. El motivo se incluye en el informe generado y se puede ver haciendo clic en el icono de información de la tarjeta de la métrica correspondiente.Por último, agregue el propio método de prueba .
[TestMethod] public async Task SampleAndEvaluateResponse() { // Create a <see cref="ScenarioRun"/> with the scenario name // set to the fully qualified name of the current test method. await using ScenarioRun scenarioRun = await s_defaultReportingConfiguration.CreateScenarioRunAsync( ScenarioName, additionalTags: ["Moon"]); // Use the <see cref="IChatClient"/> that's included in the // <see cref="ScenarioRun.ChatConfiguration"/> to get the LLM response. (IList<ChatMessage> messages, ChatResponse modelResponse) = await GetAstronomyConversationAsync( chatClient: scenarioRun.ChatConfiguration!.ChatClient, astronomyQuestion: "How far is the Moon from the Earth at its closest and furthest points?"); // Run the evaluators configured in <see cref="s_defaultReportingConfiguration"/> against the response. EvaluationResult result = await scenarioRun.EvaluateAsync(messages, modelResponse); // Run some basic validation on the evaluation result. Validate(result); }Este método de prueba:
Crea el objeto ScenarioRun.
await usinggarantiza la eliminación correcta deScenarioRuny la persistencia correcta de los resultados de evaluación en el almacén de resultados.Obtiene la respuesta del LLM a una pregunta de astronomía específica. La prueba pasa el mismo IChatClient que se usa para la evaluación al método
GetAstronomyConversationAsyncpara obtener el almacenamiento en caché de respuestas de la principal respuesta LLM que se está evaluando. (Al pasar el mismo cliente, también se habilita el almacenamiento en caché de respuestas para los cambios de LLM que los evaluadores utilizan para realizar sus evaluaciones de forma interna) Con el almacenamiento en caché de respuestas, la respuesta del LLM se recupera de una de estas dos formas:- Directamente desde el punto de conexión LLM en la primera ejecución de la prueba actual o en ejecuciones posteriores si la entrada almacenada en caché ha expirado (14 días, de forma predeterminada).
- Desde la caché de respuestas (basada en disco) configurada en
s_defaultReportingConfigurationen ejecuciones posteriores de la prueba.
Ejecuta los evaluadores en la respuesta. Al igual que la respuesta LLM, las ejecuciones posteriores capturan la evaluación de la caché de respuesta (basada en disco) configurada en
s_defaultReportingConfiguration.Ejecuta alguna validación básica en el resultado de la evaluación.
Este paso es opcional y principalmente para fines de demostración. En las evaluaciones reales, es posible que no quiera validar resultados individuales porque las respuestas de LLM y las puntuaciones de evaluación pueden cambiar con el tiempo a medida que evoluciona el producto (y los modelos usados). Es posible que no desee que cada una de las pruebas de evaluación "genere errores" y bloquee las compilaciones en las canalizaciones de CI/CD cuando cambien los resultados. En vez de eso, podría ser mejor confiar en el informe generado y realizar un seguimiento de las tendencias generales de las puntuaciones de evaluación en diferentes escenarios a lo largo del tiempo (y solo se generarán errores en compilaciones concretas si hay las puntuaciones de evaluación caen considerablemente en varias pruebas diferentes). Dicho esto, hay algunos matices aquí y la elección de si validar resultados individuales o no puede variar en función del caso de uso específico.
Cuando el método finaliza, el objeto
scenarioRunse elimina y el resultado de la evaluación se almacena en el almacén de resultados en disco configurado ens_defaultReportingConfiguration.
Ejecución de la prueba o evaluación
Ejecute la prueba mediante el flujo de trabajo de prueba preferido, por ejemplo, mediante el comando dotnet test de la CLI o mediante el Explorador de pruebas.
Generación de un informe
Instale el Microsoft. Extensions.AI.Evaluation.Console .NET herramienta ejecutando el siguiente comando desde una ventana de terminal:
dotnet tool install --create-manifest-if-needed Microsoft.Extensions.AI.Evaluation.ConsoleGenere un informe mediante la ejecución del comando siguiente:
dotnet tool run aieval report --path <path\to\your\cache\storage> --output report.htmlAbra el archivo
report.html. El informe es similar a la captura de pantalla siguiente.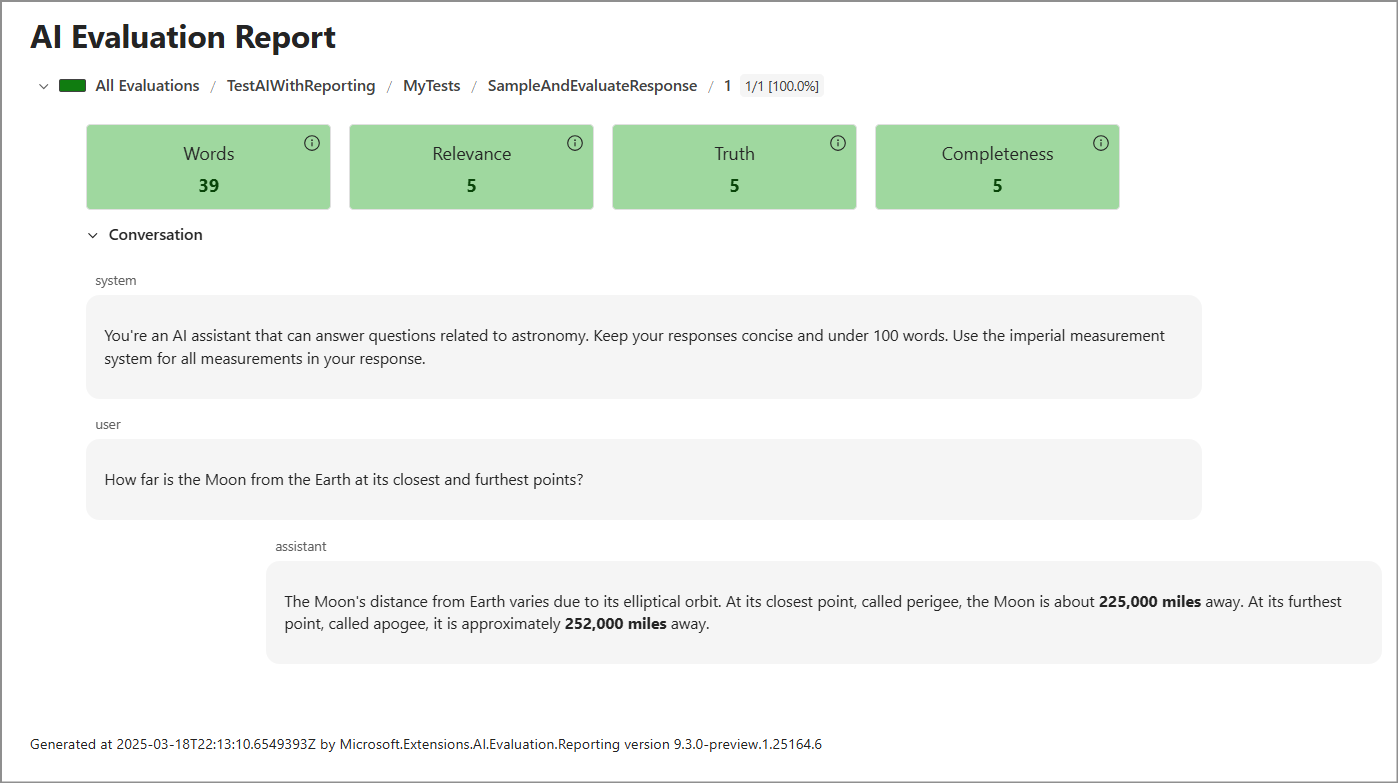
Pasos siguientes
- Vaya al directorio donde se almacenan los resultados de la prueba (que es
C:\TestReports, a menos que haya modificado la ubicación al crear el ReportingConfiguration). En elresultssubdirectorio, observe que hay una carpeta para cada ejecución de prueba denominada con una marca de tiempo (ExecutionName). Dentro de cada una de esas carpetas hay una carpeta para cada nombre de escenario; en este caso, solo el método de prueba único en el proyecto. Esa carpeta contiene un archivo JSON con todos los datos, incluidos los mensajes, la respuesta y el resultado de evaluación. - Expanda la evaluación. Estas son un par de ideas:
- Agregue otro evaluador personalizado, como un evaluador que use ia para determinar el sistema de medición que se usa en la respuesta.
- Agregue otro método de prueba, por ejemplo, un método que evalúe varias respuestas de LLM. Dado que cada respuesta puede ser diferente, es bueno muestrear y evaluar al menos algunas respuestas a una pregunta. En este caso, especifique un nombre de iteración cada vez que llame a CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken).
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.