Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Este contenido es un extracto del libro electrónico, Arquitectura de aplicaciones .NET nativas de nube para Azure, disponible en .NET Docs o como un PDF descargable gratuito que se puede leer sin conexión.

El lema favorito de los consultores de software es responder a "Depende" de cualquier pregunta planteada. No se debe a que los consultores de software están encantados de no tomar una posición. Es porque no hay ninguna respuesta verdadera a ninguna pregunta en el software. No hay ningún derecho absoluto y incorrecto, sino un equilibrio entre los opuestos.
Por ejemplo, las dos principales escuelas de desarrollo de aplicaciones web: Aplicaciones de página única (SPA) frente a aplicaciones del lado servidor. Por un lado, la experiencia del usuario tiende a ser mejor con las SPA y la cantidad de tráfico al servidor web se puede minimizar, lo que permite hospedarlos en algo tan sencillo como el hospedaje estático. Por otro lado, las SPA tienden a ser más lentas para desarrollarse y ser más difíciles de probar. ¿Cuál es la opción correcta? Depende de tu situación.
Las aplicaciones nativas de la nube no son inmunes a esa misma dictomía. Tienen ventajas claras en términos de velocidad de desarrollo, estabilidad y escalabilidad, pero administrarlas puede ser bastante más difícil.
Hace años, no era raro que el proceso de mover una aplicación de desarrollo a producción tarde un mes o incluso más. Las empresas lanzaron software durante un período de 6 meses o incluso cada año. No hay más que fijarse en Microsoft Windows para hacerse una idea de la cadencia de las versiones que eran aceptables antes de que llegara la estabilidad de Windows 10. Cinco años pasaron entre Windows XP y Vista, tres más entre Vista y Windows 7.
Ahora está bastante bien establecido que ser capaz de lanzar software rápidamente ofrece a las empresas de movimiento rápido una gran ventaja de mercado sobre sus competidores más ranurados. Por ese motivo, las actualizaciones principales de Windows 10 ahora son aproximadamente cada seis meses.
Los patrones y prácticas que permiten versiones más rápidas y confiables para ofrecer valor a la empresa se conocen colectivamente como DevOps. Constan de una amplia gama de ideas que abarcan todo el ciclo de vida de desarrollo de software, desde la especificación de una aplicación hasta la entrega y el funcionamiento de esa aplicación.
DevOps surgió antes de los microservicios y es probable que el movimiento hacia servicios más pequeños y más adecuados para propósitos no hubiera sido posible sin DevOps para facilitar la publicación y el funcionamiento no solo de una sino muchas aplicaciones en producción.
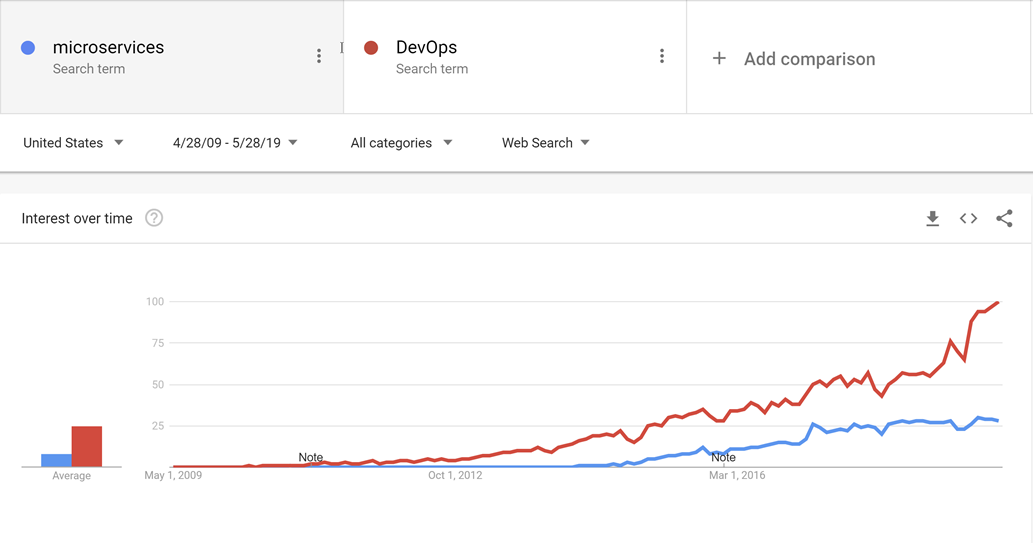
Figura 10-1 : DevOps y microservicios.
Gracias a unos procedimientos adecuados de DevOps, se puede disfrutar de las ventajas de las aplicaciones nativas de nube sin verse inundado por un aluvión de trabajo para poner en marcha las aplicaciones.
No hay ningún martillo dorado cuando se trata de DevOps. Nadie puede vender una solución completa y integral para lanzar y operar aplicaciones de alta calidad. Esto se debe a que cada aplicación es muy diferente de todas las demás. Sin embargo, hay herramientas que pueden hacer que DevOps sea una propuesta mucho menos intimidante. Una de estas herramientas se conoce como Azure DevOps.
Azure DevOps
Azure DevOps tiene un pedigrí largo. Sus inicios se remontan a cuando Team Foundation Server pasó al modo en línea por primera vez, y se ha sometido a distintos cambios de nombre: Visual Studio Online y Visual Studio Team Services. Con los años, sin embargo, se ha convertido en algo mucho más que sus predecesores.
Azure DevOps se divide en cinco componentes principales:

Figura 10-2 : Azure DevOps.
Azure Repos — administración de código fuente que admite el veterano Team Foundation Version Control (TFVC) y el favorito del sector, Git. Las solicitudes de incorporación de cambios proporcionan una manera de habilitar la codificación social fomentando la discusión de los cambios a medida que se realizan.
Azure Boards : proporciona una herramienta de seguimiento de problemas y elementos de trabajo que se esfuerza por permitir a los usuarios elegir los flujos de trabajo que funcionan mejor para ellos. Viene con una serie de plantillas preconfiguradas, incluidas las que admiten los estilos SCRUM y Kanban de desarrollo.
Azure Pipelines : un sistema de administración de versiones y compilación que admite una estrecha integración con Azure. Las compilaciones se pueden ejecutar en varias plataformas de Windows a Linux a macOS. Los agentes de compilación se pueden aprovisionar en la nube o en el entorno local.
Planes de pruebas de Azure. No se dejará a ninguna persona de Control de Calidad atrás con la gestión de pruebas y el soporte para pruebas exploratorias que ofrece la función de Planes de prueba.
Azure Artifacts - un feed de artefactos que permite a las empresas crear sus propias versiones internas de NuGet, npm y otras. Sirve para el doble propósito de actuar como una memoria caché de paquetes superiores si se produce un fallo en un repositorio centralizado.
La unidad organizativa de nivel superior de Azure DevOps se conoce como Project. Dentro de cada proyecto, los distintos componentes, como Azure Artifacts, se pueden activar y desactivar. Cada uno de estos componentes proporciona diferentes ventajas para las aplicaciones nativas de la nube. Los tres más útiles son repositorios, paneles y canalizaciones. Si los usuarios quieren administrar su código fuente en otra pila de repositorios, como GitHub, pero siguen aprovechando Azure Pipelines y otros componentes, eso es perfectamente posible.
Afortunadamente, los equipos de desarrollo tienen muchas opciones al seleccionar un repositorio. Uno de ellos es GitHub.
Acciones de GitHub
Fundada en 2009, GitHub es un repositorio ampliamente popular basado en web para hospedar proyectos, documentación y código. Muchas grandes empresas tecnológicas, como Apple, Amazon, Google y las corporaciones estándar usan GitHub. GitHub usa el sistema de control de versiones distribuido de código abierto denominado Git como base. Además, agrega su propio conjunto de características, como seguimiento de defectos, solicitudes de incorporación de cambios, administración de tareas y wikis para cada base de código.
A medida que GitHub evoluciona, también agrega características de DevOps. Por ejemplo, GitHub tiene su propia canalización de integración continua/entrega continua (CI/CD), denominada GitHub Actions. Acciones de GitHub es una herramienta de automatización de flujos de trabajo impulsada por la comunidad. Permite que los equipos de DevOps se integren con sus herramientas existentes, mezclen y combinen nuevos productos, y se integren con su ciclo de vida de software, incluidos los socios de CI/CD existentes.
GitHub tiene más de 40 millones de usuarios, lo que lo convierte en el host más grande del código fuente del mundo. En octubre de 2018, Microsoft compró GitHub. Microsoft ha prometido que GitHub seguirá siendo una plataforma abierta que cualquier desarrollador pueda conectar y ampliar. Sigue funcionando como una empresa independiente. GitHub ofrece planes para cuentas empresariales, de equipo, profesionales y gratuitas.
Control de código fuente
Organizar el código para una aplicación nativa de la nube puede ser difícil. En lugar de una sola aplicación gigante, las aplicaciones nativas de la nube tienden a estar formadas por una web de aplicaciones más pequeñas que se comunican entre sí. Al igual que con todas las cosas de la computación, la mejor disposición del código sigue siendo una pregunta abierta. Hay ejemplos de aplicaciones correctas que usan diferentes tipos de diseños, pero dos variantes parecen tener la mayor popularidad.
Antes de entrar en el propio control de código fuente real, es probable que valga la pena decidir cuántos proyectos son adecuados. Dentro de un mismo proyecto existe compatibilidad con varios repositorios y canalizaciones de compilación. Los paneles son un poco más complicados, pero en ellos las tareas también se pueden asignar fácilmente a varios equipos dentro de un mismo proyecto. Es posible admitir a cientos o incluso miles de desarrolladores desde un único proyecto de Azure DevOps. Es probable que sea el mejor enfoque, ya que proporciona un único lugar para que todos los desarrolladores trabajen y reduce la confusión al intentar encontrar esa aplicación cuando los desarrolladores no están seguros de en qué proyecto reside.
La división de código para microservicios dentro del proyecto de Azure DevOps puede ser un poco más difícil.
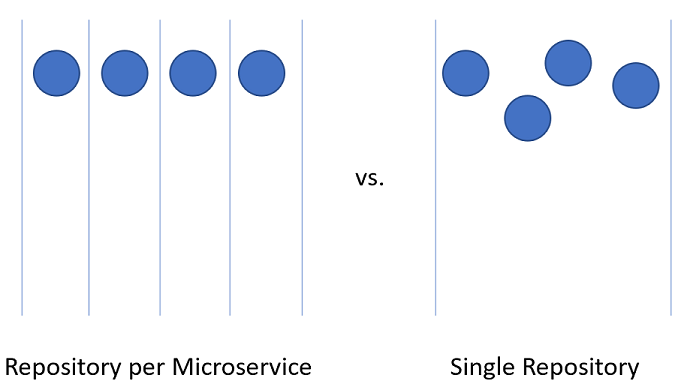
Figura 10-3 : uno frente a muchos repositorios.
Repositorio para cada microservicio
A primera vista, este enfoque parece el enfoque más lógico para dividir el código fuente de los microservicios. Cada repositorio puede contener el código necesario para compilar el microservicio. Las ventajas de este enfoque son fácilmente visibles:
- Las instrucciones para compilar y mantener la aplicación se pueden agregar a un archivo LÉAME en la raíz de cada repositorio. Al desplazarse por los repositorios, es fácil encontrar estas instrucciones, lo que reduce el tiempo de puesta en marcha para los desarrolladores.
- Cada servicio se encuentra en un lugar lógico, fácilmente encontrado al conocer el nombre del servicio.
- Las compilaciones se pueden configurar fácilmente de modo que solo se desencadenen cuando se realiza un cambio en el repositorio propietario.
- El número de cambios que entran en un repositorio se limita al pequeño número de desarrolladores que trabajan en el proyecto.
- La seguridad es fácil de configurar mediante la restricción de los repositorios a los que los desarrolladores tienen permisos de lectura y escritura.
- El equipo propietario puede cambiar la configuración del nivel de repositorio con un mínimo de discusión con otros usuarios.
Una de las ideas clave detrás de los microservicios es que los servicios deben estar siloados y separados entre sí. Al usar el diseño controlado por dominio para decidir los límites de los servicios, los servicios actúan como límites transaccionales. Las actualizaciones de base de datos no deben abarcar varios servicios. Esta colección de datos relacionados se conoce como contexto delimitado. Esta idea se refleja mediante el aislamiento de los datos de microservicios en una base de datos independiente y autónoma del resto de los servicios. Tiene mucho sentido llevar esta idea hasta el código fuente.
Sin embargo, este enfoque no es sin sus problemas. Uno de los problemas de desarrollo más complicados de nuestra época es administrar las dependencias. Tenga en cuenta el número de archivos que componen el directorio promedio node_modules . Una nueva instalación de algo como create-react-app es probable que traiga con él miles de paquetes. La cuestión de cómo administrar estas dependencias es difícil.
Si se actualiza una dependencia, los paquetes de bajada también deben actualizar esta dependencia. Desafortunadamente, eso toma el trabajo de desarrollo, por lo que, invariablemente, el node_modules directorio termina con varias versiones de un único paquete, cada uno de ellos una dependencia de algún otro paquete que se versiona con una cadencia ligeramente diferente. Al implementar una aplicación, ¿qué versión de una dependencia se debe usar? ¿La versión que está actualmente en producción? ¿La versión que está actualmente en versión beta, pero que probablemente esté en producción en el momento en que el consumidor la lleve a producción? Problemas difíciles que no se resuelven mediante el uso de microservicios.
Hay bibliotecas que dependen de una amplia variedad de proyectos. Al dividir los microservicios con uno en cada repositorio, las dependencias internas se pueden resolver mejor mediante el repositorio interno, Azure Artifacts. Las compilaciones para bibliotecas insertarán sus versiones más recientes en Azure Artifacts para su consumo interno. El proyecto descendente se debe seguir actualizando manualmente para establecer una dependencia con los paquetes recién actualizados.
Otra desventaja se presenta al mover código entre servicios. Aunque sería genial creer que la primera vez que una aplicación se divide en microservicios todo sale a pedir de boca, la realidad es que rara vez somos tan clarividentes como para no cometer errores al dividir servicios. Por lo tanto, la funcionalidad y el código que la impulsa tendrán que pasar de servicio a servicio y de repositorio a repositorio. Al pasar de un repositorio a otro, el código pierde su historial. Hay muchos casos, especialmente en el caso de una auditoría, donde tener un historial completo en un fragmento de código es inestimable.
La desventaja final y más importante es coordinar los cambios. En una aplicación verdadera de microservicios, no debe haber dependencias de implementación entre los servicios. Debe ser posible implementar los servicios A, B y C en cualquier orden, ya que tienen acoplamiento flexible. Sin embargo, en realidad, hay ocasiones en las que es deseable realizar un cambio que cruce varios repositorios al mismo tiempo. Algunos ejemplos incluyen actualizar una biblioteca para cerrar un agujero de seguridad o cambiar un protocolo de comunicación usado por todos los servicios.
Para realizar un cambio entre repositorios, es necesario realizar una confirmación en cada repositorio sucesivamente. Cada cambio en cada repositorio deberá solicitarse y revisarse por separado. Esta actividad puede ser difícil de coordinar.
Una alternativa al uso de muchos repositorios es colocar todo el código fuente junto en un único repositorio gigante y omnisciente.
Repositorio único
En este enfoque, a veces denominado monorepository, todo el código fuente de cada servicio se coloca en el mismo repositorio. Al principio, este enfoque parece una idea terrible que probablemente haga que manejar el código fuente sea complicado. Sin embargo, hay algunas ventajas marcadas para trabajar de esta manera.
La primera ventaja es que es más fácil administrar las dependencias entre proyectos. En lugar de confiar en alguna fuente de artefactos externos, los proyectos pueden importarse directamente entre sí. Esto significa que las actualizaciones son instantáneas y es probable que las versiones en conflicto se encuentren en tiempo de compilación en la estación de trabajo del desarrollador. Dicho de otro modo: parte de las pruebas de integración se realizarían en las primeras fases de desarrollo.
Al mover código entre proyectos, ahora es más fácil conservar el historial, ya que los archivos se detectarán como movidos en lugar de volver a escribirse.
Otra ventaja es que se pueden realizar cambios de gran alcance que cruzan los límites del servicio en un solo compromiso. Esta actividad reduce la sobrecarga de tener potencialmente docenas de cambios para revisar individualmente.
Hay muchas herramientas que pueden realizar análisis estáticos del código para detectar prácticas de programación no seguras o un uso problemático de las API. En un mundo de varios repositorios, cada repositorio tendrá que iterarse para encontrar los problemas en ellos. El único repositorio permite ejecutar el análisis en un solo lugar.
También hay muchas desventajas en el enfoque de repositorio único. Uno de los más preocupantes es que tener un único repositorio genera problemas de seguridad. Si el contenido de un repositorio se filtra en un modelo de repositorio por servicio, la cantidad de código perdido es mínima. Con un único repositorio, todo lo que posee la empresa podría perderse. Ha habido muchos ejemplos en el pasado de este tipo de situaciones que han descarrilado los esfuerzos completos de desarrollo de juegos. Tener varios repositorios expone menos área expuesta, que es un rasgo deseable en la mayoría de las prácticas de seguridad.
Es probable que el tamaño del repositorio único se vuelva inadministrable rápidamente. Esto presenta algunas implicaciones interesantes sobre el rendimiento. Es posible que sea necesario usar herramientas especializadas como El sistema de archivos virtuales para Git, que originalmente se diseñó para mejorar la experiencia de los desarrolladores en el equipo de Windows.
Con frecuencia, el argumento para usar un único repositorio se reduce a un argumento que Facebook o Google usan este método para la organización del código fuente. Si el enfoque es lo suficientemente bueno para estas empresas, seguramente, es el enfoque correcto para todas las empresas. La verdad del asunto es que pocas empresas operan en cualquier cosa como la escala de Facebook o Google. Los problemas que se producen a esas escalas son diferentes a los que se enfrentan la mayoría de los desarrolladores. Lo que es bueno para el ganso puede no ser bueno para el gander.
Al final, cualquiera de las soluciones se puede usar para hospedar el código fuente de los microservicios. Sin embargo, en la mayoría de los casos, la administración y la sobrecarga de ingeniería del funcionamiento en un único repositorio no merecen la pena las ventajas mínimas. Dividir el código en varios repositorios fomenta una mejor separación de preocupaciones y fomenta la autonomía entre los equipos de desarrollo.
Estructura de directorios estándar
Independientemente del debate único frente a varios repositorios, cada servicio tendrá su propio directorio. Una de las mejores optimizaciones para permitir que los desarrolladores crucen entre proyectos rápidamente es mantener una estructura de directorios estándar.
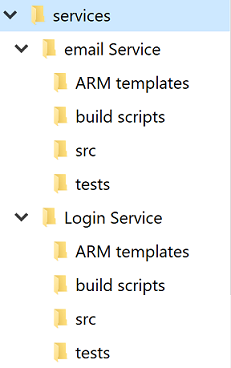
Figura 10-4 : estructura de directorio estándar.
Cada vez que se crea un nuevo proyecto, se debe usar una plantilla que coloca la estructura correcta. Esta plantilla también puede incluir elementos útiles como un archivo README modelo y un azure-pipelines.yml. En cualquier arquitectura de microservicios, un alto grado de varianza entre proyectos dificulta las operaciones masivas con los servicios.
Hay muchas herramientas que pueden proporcionar plantillas para un directorio completo, que contiene varios directorios de código fuente. Yeoman es popular en el mundo de JavaScript y GitHub han publicado recientemente plantillas de repositorio, que proporcionan gran parte de la misma funcionalidad.
Administración de tareas
La administración de tareas en cualquier proyecto puede ser difícil. Por adelantado, hay innumerables preguntas que se deben responder sobre el tipo de flujos de trabajo que se van a configurar para garantizar una productividad óptima para desarrolladores.
Las aplicaciones nativas de la nube tienden a ser más pequeñas que los productos de software tradicionales o al menos se dividen en servicios más pequeños. El seguimiento de problemas o tareas relacionados con estos servicios sigue siendo tan importante como con cualquier otro proyecto de software. Nadie quiere perder el seguimiento de algún elemento de trabajo o explicar a un cliente que su problema no se registró correctamente. Los paneles se configuran en el nivel de proyecto, pero dentro de cada proyecto, se pueden definir áreas. Esto permite desglosar los problemas en varios componentes. La ventaja de mantener todo el trabajo de toda la aplicación en un solo lugar es que es fácil mover elementos de trabajo de un equipo a otro a medida que se entienden mejor.
Azure DevOps incluye una serie de plantillas populares preconfiguradas. En la configuración más básica, todo lo que se necesita para saber es lo que hay en el trabajo pendiente, qué personas están trabajando y lo que se hace. Es importante tener esta visibilidad sobre el proceso de creación de software, de modo que el trabajo se pueda priorizar y completar las tareas notificadas al cliente. Por supuesto, algunos proyectos de software se adhieren a un proceso tan sencillo como to do, doingy done. No tarda mucho tiempo en empezar a agregar pasos como QA o Detailed Specification al proceso.
Una de las partes más importantes de las metodologías ágiles es la introspección automática a intervalos regulares. Estas revisiones están diseñadas para proporcionar información sobre los problemas a los que se enfrenta el equipo y cómo se pueden mejorar. Con frecuencia, esto significa cambiar el flujo de problemas y características a través del proceso de desarrollo. Por lo tanto, es perfectamente lícito ampliar los diseños de los paneles con más etapas.
Las etapas en los paneles no son la única herramienta organizativa. En función de la configuración del panel, hay una jerarquía de elementos de trabajo. El elemento más granular que puede aparecer en un panel es una tarea. De manera predeterminada, una tarea contiene campos para un título, una descripción, una prioridad, una estimación de la cantidad de trabajo restante y la capacidad para vincular otros elementos de trabajo o elementos de desarrollo (ramas, confirmaciones, solicitudes de incorporación de cambios, compilaciones, etc.). Los elementos de trabajo se pueden clasificar en diferentes áreas de la aplicación y diferentes iteraciones (sprints) para facilitar su búsqueda.
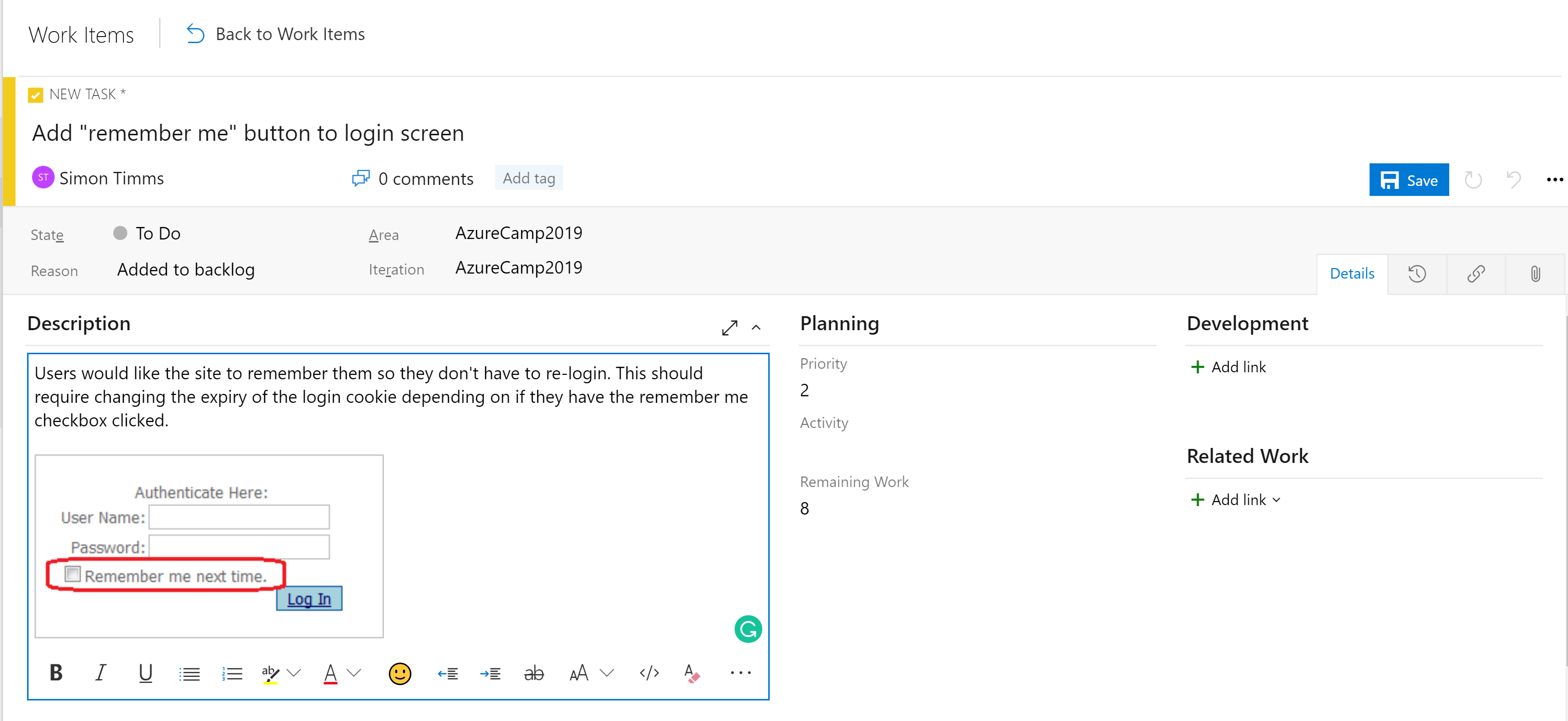
Figura 10-5 : Tarea en Azure DevOps.
El campo de descripción admite los estilos normales que se podría esperar (negrita, cursiva, subrayado y tachado) y la capacidad de insertar imágenes. Esto hace que sea una herramienta eficaz para su uso al especificar el trabajo o los errores.
Las tareas se pueden agrupar en funcionalidades, que definen una unidad de trabajo más amplia. Las características, a su vez, se pueden agrupar en epopeyas. La clasificación de tareas en esta jerarquía facilita mucho la comprensión de la proximidad de una característica grande a la implementación.

Figura 10-6 : Elemento de trabajo en Azure DevOps.
En Azure Boards existen diferentes tipos de vistas de los problemas. Los elementos que aún no están programados aparecen en el trabajo pendiente. Desde ahí, se pueden asignar a un sprint. Un sprint es un cuadro de tiempo durante el que se espera que se complete cierta cantidad de trabajo. Este trabajo puede incluir tareas, pero también la resolución de incidencias. Un sprint completo se puede administrar desde la sección Sprint del panel. Esta vista refleja cómo va avanzando el trabajo, e incluye un gráfico de evolución que proporciona una estimación en constante actualización de si el sprint se va a realizar correctamente.
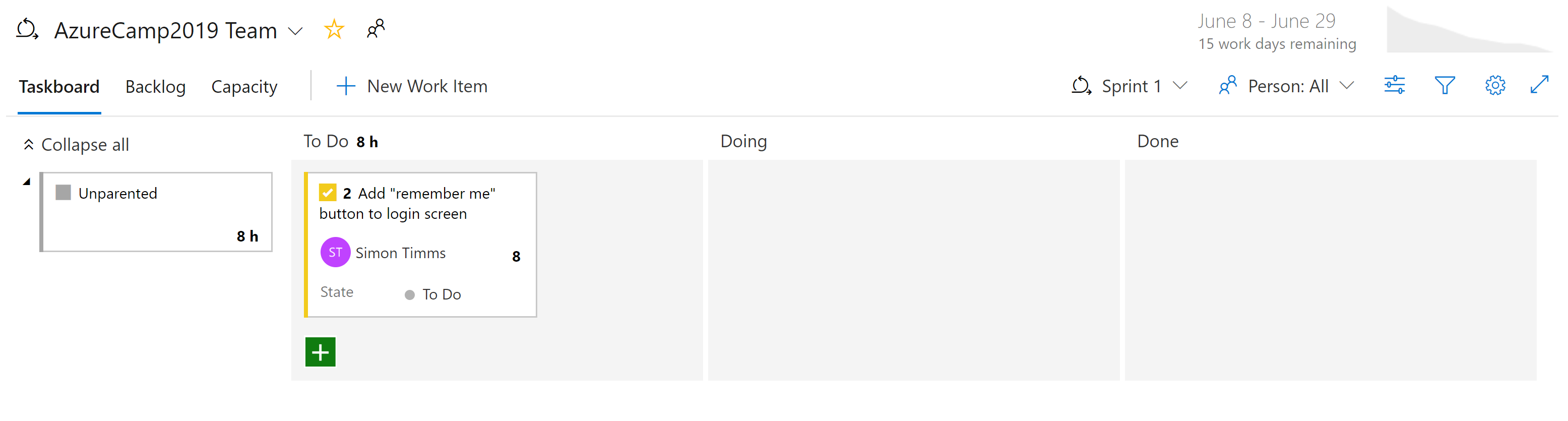
Figura 10-7 : Panel en Azure DevOps.
Por ahora, debería ser evidente que hay una gran potencia en los Paneles en Azure DevOps. Para los desarrolladores, hay vistas sencillas de lo que se está trabajando. Para los administradores de proyectos: vistas del trabajo próximo y una visión general del trabajo actual. Para los administradores, hay muchos informes sobre recursos y capacidad. Desafortunadamente, no hay nada mágico sobre las aplicaciones nativas de la nube que eliminan la necesidad de realizar un seguimiento del trabajo. Pero si debe realizar un seguimiento del trabajo, hay algunos lugares en los que la experiencia es mejor que en Azure DevOps.
Canalizaciones de CI/CD
Casi ningún cambio en el ciclo de vida de desarrollo de software ha sido tan revolucionario como la llegada de la integración continua (CI) y la entrega continua (CD). La compilación y ejecución de pruebas automatizadas en el código fuente de un proyecto tan pronto como se comprueba un cambio detecta errores al principio. Antes de la llegada de compilaciones de integración continua, no sería raro extraer código del repositorio y encontrar que no superó pruebas ni siquiera se pudo compilar. Esto dio lugar a que se llevara un seguimiento del origen de la rotura de código.
Tradicionalmente, el envío de software al entorno de producción requería una amplia documentación y una lista de pasos. Cada uno de estos pasos debe completarse manualmente en un proceso muy propenso a errores.

Figura 10-8 : Lista de comprobación.
La hermana de la integración continua es la entrega continua en la que los paquetes recién creados se implementan en un entorno. El proceso manual no se puede escalar para que coincida con la velocidad de desarrollo, por lo que la automatización es más importante. Las listas de comprobación se reemplazan por scripts que pueden ejecutar las mismas tareas de forma más rápida y precisa que cualquier persona.
El entorno al que la entrega continua se realiza podría ser un entorno de prueba o, como hacen muchas empresas tecnológicas importantes, podría ser el entorno de producción. Esto último requiere una inversión en pruebas de alta calidad que pueden dar confianza de que un cambio no interrumpirá la producción para los usuarios. De la misma manera que la integración continua detectaba problemas en el código, una entrega continua temprana detecta con prontitud problemas en el proceso de implementación.
La importancia de automatizar el proceso de compilación y entrega está acentuada por las aplicaciones nativas de la nube. Las implementaciones se producen con más frecuencia y en más entornos, por lo que la implementación manual se vuelve casi imposible.
Compilaciones de Azure
Azure DevOps proporciona un conjunto de herramientas para facilitar la integración continua y la implementación más que nunca. Estas herramientas se encuentran en Azure Pipelines. La primera de ellas es Azure Builds, que es una herramienta para ejecutar definiciones de compilación basadas en YAML a escala. Los usuarios pueden traer sus propias máquinas de compilación (ideales para si la compilación requiere un entorno de configuración minuciosa) o usar una máquina desde un grupo actualizado constantemente de máquinas virtuales hospedadas en Azure. Estos agentes de compilación hospedados vienen preinstalados con una amplia gama de herramientas de desarrollo para no solo desarrollo de .NET, sino para todo, desde Java a Python hasta el desarrollo de iPhone.
DevOps incluye una amplia gama de definiciones de compilación integradas que se pueden personalizar para cualquier compilación. Las definiciones de compilación se definen en un archivo denominado azure-pipelines.yml y se comprueban en el repositorio para que se puedan versionarse junto con el código fuente. Esto hace que resulte mucho más fácil realizar cambios en la canalización de compilación en una rama, ya que los cambios se pueden comprobar solo en esa rama. En la figura 10-9 se muestra un ejemplo azure-pipelines.yml para compilar una aplicación web de ASP.NET en el marco completo.
name: $(rev:r)
variables:
version: 9.2.0.$(Build.BuildNumber)
solution: Portals.sln
artifactName: drop
buildPlatform: any cpu
buildConfiguration: release
pool:
name: Hosted VisualStudio
demands:
- msbuild
- visualstudio
- vstest
steps:
- task: NuGetToolInstaller@0
displayName: 'Use NuGet 4.4.1'
inputs:
versionSpec: 4.4.1
- task: NuGetCommand@2
displayName: 'NuGet restore'
inputs:
restoreSolution: '$(solution)'
- task: VSBuild@1
displayName: 'Build solution'
inputs:
solution: '$(solution)'
msbuildArgs: '-p:DeployOnBuild=true -p:WebPublishMethod=Package -p:PackageAsSingleFile=true -p:SkipInvalidConfigurations=true -p:PackageLocation="$(build.artifactstagingdirectory)\\"'
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: VSTest@2
displayName: 'Test Assemblies'
inputs:
testAssemblyVer2: |
**\$(buildConfiguration)\**\*test*.dll
!**\obj\**
!**\*testadapter.dll
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: CopyFiles@2
displayName: 'Copy UI Test Files to: $(build.artifactstagingdirectory)'
inputs:
SourceFolder: UITests
TargetFolder: '$(build.artifactstagingdirectory)/uitests'
- task: PublishBuildArtifacts@1
displayName: 'Publish Artifact'
inputs:
PathtoPublish: '$(build.artifactstagingdirectory)'
ArtifactName: '$(artifactName)'
condition: succeededOrFailed()
Figura 10-9: Ejemplo de azure-pipelines.yml
Esta definición de compilación usa una serie de tareas integradas que hacen que la creación de compilaciones sea tan sencilla como construir un conjunto Lego (más sencillo que el gigante Millennium Falcon). Por ejemplo, la tarea NuGet restaura paquetes NuGet, mientras que la tarea VSBuild llama a las herramientas de compilación de Visual Studio para realizar la compilación real. Hay cientos de tareas diferentes disponibles en Azure DevOps, con miles más que mantiene la comunidad. Es probable que, independientemente de las tareas de compilación que quiera ejecutar, alguien ya ha creado una.
Las compilaciones se pueden desencadenar manualmente, mediante una comprobación, según una programación o mediante la finalización de otra compilación. En la mayoría de los casos, conviene compilar en cada comprobación. Las compilaciones se pueden filtrar para que las distintas compilaciones se ejecuten en diferentes partes del repositorio o en ramas diferentes. Esto permite escenarios como ejecutar compilaciones rápidas con pruebas reducidas en las solicitudes de pull y ejecutar un conjunto de regresión completo en el tronco de manera nocturna.
El resultado final de una compilación es una colección de archivos conocidos como artefactos de compilación. Estos artefactos se pueden pasar al paso siguiente del proceso de compilación o agregarlos a una fuente de Azure Artifacts, por lo que otras compilaciones pueden consumirlos.
Lanzamientos de Azure DevOps
Las compilaciones se encargan de compilar el software en un paquete que puede enviarse, pero los artefactos se deben seguir insertando en un entorno de prueba para completar la entrega continua. Para ello, Azure DevOps usa una herramienta independiente denominada Releases. La herramienta Releases usa la misma biblioteca de tareas que estaban disponibles para la compilación, pero presenta un concepto de "fases". Una fase es un entorno aislado en el que se instala el paquete. Por ejemplo, un producto podría usar un desarrollo, un control de calidad y un entorno de producción. El código se entrega continuamente en el entorno de desarrollo donde se pueden ejecutar pruebas automatizadas en él. Una vez que esas pruebas se superen, la versión se mueve al entorno de aseguramiento de calidad para las pruebas manuales. Por último, el código se lanza a producción donde es visible para todos.

Figura 10-10 - Canalización de lanzamiento
Cada fase de la compilación se puede desencadenar automáticamente mediante la finalización de la fase anterior. Sin embargo, en muchos casos, esto no es deseable. Mover código a producción podría requerir aprobación de alguien. La herramienta de lanzamientos facilita esto permitiendo la intervención de los aprobadores en cada paso del proceso de lanzamiento. Las reglas se pueden configurar de manera que una persona o grupo específico deba aprobar una versión antes de que pase a producción. Estas puertas permiten comprobaciones manuales de calidad y también para el cumplimiento de los requisitos normativos relacionados con el control de lo que entra en producción.
Canalizaciones de compilación para todos
No hay ningún costo para configurar muchas canalizaciones de compilación, por lo que es ventajoso tener al menos una canalización de compilación por microservicio. Idealmente, los microservicios se pueden implementar de forma independiente en cualquier entorno, por lo que cada uno de ellos puede liberarse a través de su propia canalización sin liberar una masa de código no relacionado es perfecto. Cada canalización puede tener su propio conjunto de aprobaciones, lo que permite variaciones en el proceso de construcción para cada servicio.
Control de versiones
Un inconveniente de usar la funcionalidad Releases es que no se puede definir en un archivo protegido azure-pipelines.yml . Hay muchas razones por las que podría querer hacerlo, como tener definiciones de versión para cada rama o incluir un esquema de versión en la plantilla de su proyecto. Por suerte, estamos trabajando para trasladar algunas de las fases de compatibilidad al componente de compilación. Esto se conoce como compilación de varias fases y la primera versión ya está disponible.
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.