Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Este contenido es un extracto del libro electrónico "Patrones de aplicaciones empresariales con .NET MAUI", disponible en Documentación de .NET o como un PDF descargable y gratuito que se puede leer sin conexión.

El desarrollo de aplicaciones cliente-servidor ha dado lugar a un enfoque en la creación de aplicaciones en capas que usan tecnologías específicas en cada capa. Estas aplicaciones se conocen a menudo como monolíticas y se empaquetan en hardware preescalado para cargas máximas. Los principales inconvenientes de este enfoque de desarrollo son el acoplamiento estricto entre los componentes de cada capa, que los componentes individuales no se pueden escalar fácilmente y el costo de las pruebas. Una actualización sencilla puede tener efectos imprevistos en el resto de la capa, por lo que un cambio en un componente de la aplicación requiere volver a probar e implementar toda la capa.
En la era de la nube, es especialmente preocupante que los componentes individuales no se puedan escalar fácilmente. Una aplicación monolítica contiene funcionalidad específica del dominio y suele estar dividida en capas funcionales, como front-end, lógica de negocios y almacenamiento de datos. En la imagen siguiente se muestra que una aplicación monolítica se escala clonando toda la aplicación en varias máquinas.
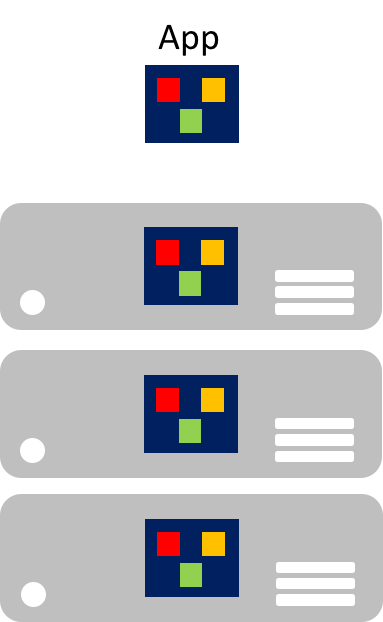
Microservicios
Los microservicios ofrecen un enfoque diferente para el desarrollo y la implementación de aplicaciones, un enfoque adecuado para los requisitos de agilidad, escala y confiabilidad de las aplicaciones en la nube modernas. Una aplicación de microservicios se divide en componentes independientes que funcionan conjuntamente para ofrecer la funcionalidad general de la aplicación. El término microservicio hace hincapié en que las aplicaciones deben estar compuestas de servicios lo suficientemente pequeños como para reflejar puntos concretos que son motivo de preocupación, por lo que cada microservicio implementa una sola función. Además, cada microservicio tiene contratos bien definidos con los que otros microservicios se comunican y comparten datos. Entre los ejemplos típicos de microservicios se incluyen los carros de la compra, el procesamiento de inventarios, los subsistemas de compra y el procesamiento de pagos.
Los microservicios se pueden escalar de forma independiente en comparación con las aplicaciones monolíticas gigantes que se escalan enteras. Esto significa que un área funcional específica que requiere más capacidad de procesamiento o ancho de banda de red para atender la demanda se puede escalar en lugar de escalar horizontalmente otras áreas de la aplicación innecesariamente. En la imagen siguiente se muestra este enfoque, donde los microservicios se implementan y escalan de forma independiente y crean instancias de servicios entre máquinas.
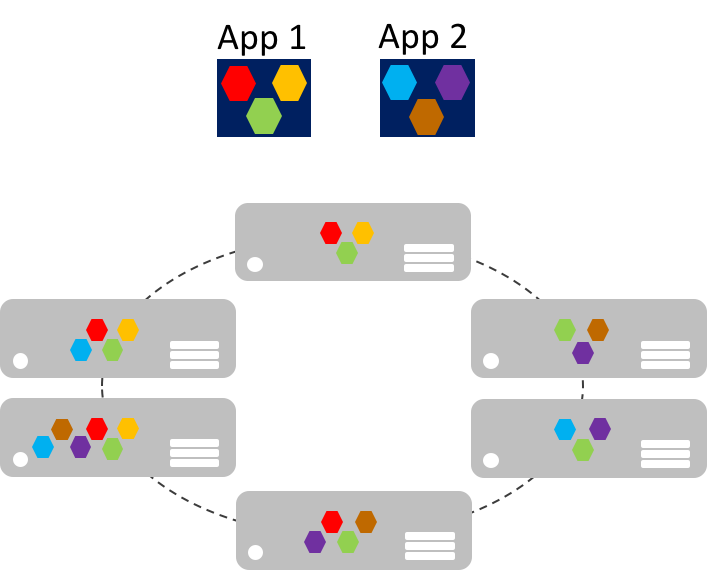
El escalado horizontal de microservicios puede ser casi instantáneo, lo que permite a una aplicación adaptarse a las cargas cambiantes. Por ejemplo, un único microservicio para la funcionalidad orientada a la web de una aplicación puede ser el único microservicio que sea necesario escalar horizontalmente para controlar el tráfico entrante adicional.
El modelo clásico para la escalabilidad de las aplicaciones es tener una capa sin estado y con equilibrio de carga con un almacén de datos externo compartido para almacenar datos persistentes. Los microservicios con estado administran sus propios datos persistentes, normalmente los almacenan localmente en los servidores en los que se colocan, para evitar la sobrecarga en el acceso a la red y la complejidad en las operaciones entre servicios. Esto permite el procesamiento más rápido posible de los datos y puede eliminar la necesidad de sistemas de almacenamiento en caché. Además, los microservicios con estado escalables suelen particionar los datos entre sus instancias, con el fin de administrar el tamaño de los datos y transferir el procesamiento más allá de lo que un único servidor puede admitir.
Los microservicios también admiten actualizaciones independientes. Este acoplamiento ligero entre microservicios proporciona una evolución rápida y confiable de las aplicaciones. Su naturaleza distribuida e independiente facilita la implementación gradual de actualizaciones, donde solo un subconjunto de instancias de un único microservicio se actualiza en un momento dado. Por tanto, si se detecta un problema, se puede revertir una actualización errónea antes de que todas las instancias se actualicen con el código o la configuración defectuosos. De forma similar, los microservicios suelen usar el control de versiones de esquema, de modo que los clientes ven una versión coherente cuando se aplican las actualizaciones, independientemente de la instancia del microservicio con la que se comuniquen.
Por tanto, las aplicaciones de microservicios tienen muchas ventajas con comparación con las aplicaciones monolíticas:
- Cada microservicio es relativamente pequeño, fácil de administrar y desarrollar.
- Cada microservicio se puede implementar y actualizar independientemente de otros servicios.
- Cada microservicio se puede escalar horizontalmente de forma independiente. Por ejemplo, es posible que un servicio de catálogo o un servicio de cesta de la compra deba escalarse horizontalmente más que un servicio de pedidos. Por tanto, la infraestructura resultante consumirá los recursos de una forma más eficaz al escalar horizontalmente la capacidad.
- Cada microservicio aísla cualquier problema. Por ejemplo, si hay un problema en un servicio, solo afecta a ese servicio. Los demás servicios pueden seguir atendiendo solicitudes.
- Cada microservicio puede usar las tecnologías más recientes. Dado que los microservicios son autónomos y se ejecutan en paralelo, se pueden usar las tecnologías y los marcos más recientes, en lugar de estar obligado a usar un marco anterior que podría usar una aplicación monolítica.
No obstante, una solución basada en microservicios también tiene posibles inconvenientes:
- Elegir cómo particionar una aplicación en microservicios puede resultar complicado, ya que cada microservicio debe ser completamente autónomo y completo, incluida la responsabilidad de sus orígenes de datos.
- Los desarrolladores deben implementar comunicación entre los servicios, lo que agrega complejidad y latencia a la aplicación.
- Normalmente, no se pueden realizar transacciones atómicas entre varios microservicios. Por tanto, los requisitos empresariales deben adoptar la coherencia final entre los microservicios.
- En producción, la implementación y administración de un sistema compuesto por muchos servicios independientes supone una complejidad operativa.
- La comunicación directa de cliente a microservicio puede dificultar la refactorización de los contratos de los microservicios. Por ejemplo, con el tiempo es posible que deba cambiarse la forma en la que la aplicación está particionada en servicios. Un único servicio puede dividirse en dos o más servicios y dos servicios pueden combinarse. Cuando los clientes se comunican directamente con microservicios, este trabajo de refactorización puede interrumpir la compatibilidad con las aplicaciones cliente.
Inclusión en contenedores
La contenedorización es un enfoque para el desarrollo de software en el que una aplicación y su conjunto de dependencias con control de versiones, además de su configuración de entorno extraída en archivos de manifiesto de implementación, se empaquetan juntos como una imagen de contenedor, se prueban como una unidad y se implementan en un sistema operativo host.
Un contenedor es un entorno operativo aislado, controlado por recursos y portable, donde una aplicación se puede ejecutar sin tocar los recursos de otros contenedores ni el host. Un contenedor es y actúa como una máquina virtual o un equipo físico recién instalado.
Hay muchas similitudes entre los contenedores y las máquinas virtuales, como se muestra a continuación.
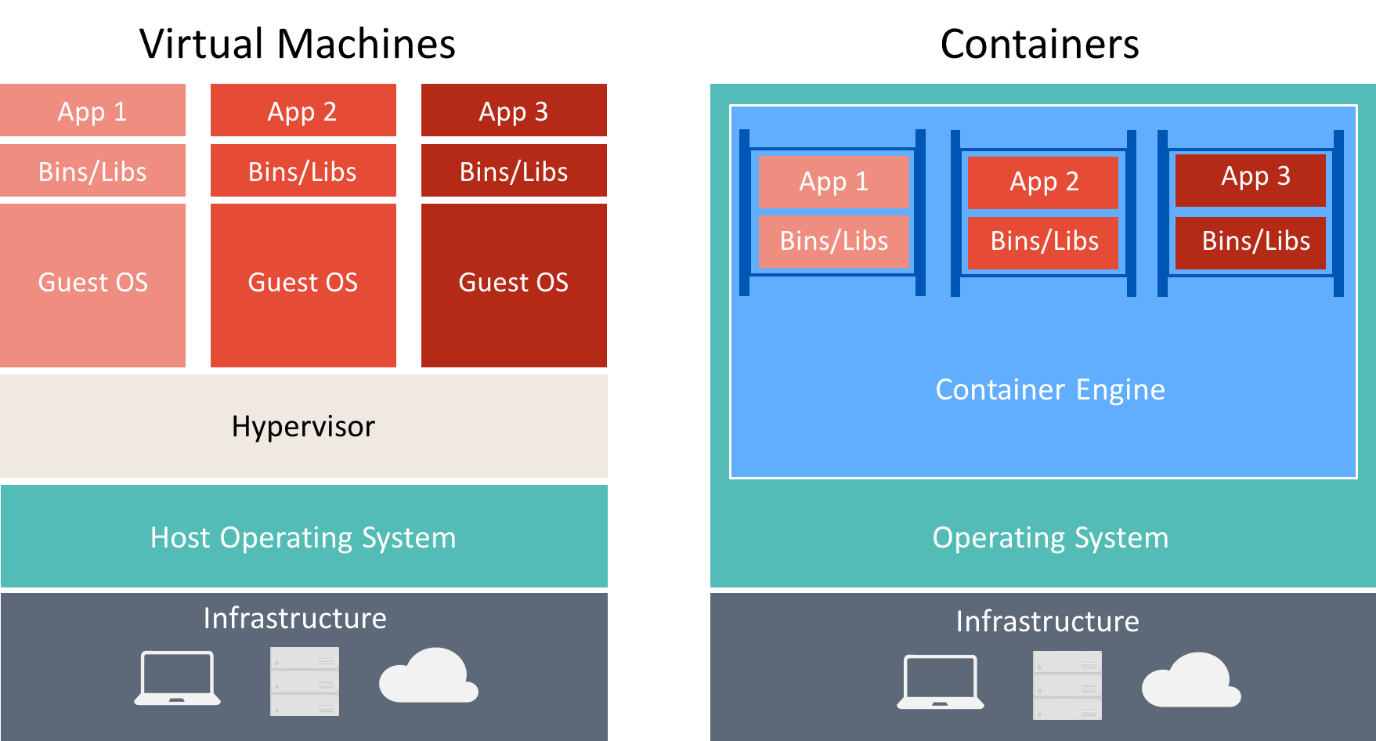
Un contenedor ejecuta un sistema operativo, tiene un sistema de archivos y se puede acceder a él a través de una red, al igual que una máquina física o virtual. Sin embargo, la tecnología y los conceptos que usan los contenedores son muy diferentes de los de las máquinas virtuales. Las máquinas virtuales incluyen las aplicaciones, las dependencias necesarias y un sistema operativo invitado completo. Los contenedores incluyen la aplicación y sus dependencias, pero comparten el sistema operativo con otros contenedores, que se ejecutan como procesos aislados en el sistema operativo host (excepto los contenedores Hyper-V, que se ejecutan dentro de una máquina virtual especial por contenedor). Por tanto, los contenedores comparten recursos y normalmente requieren menos recursos que las máquinas virtuales.
La ventaja de un enfoque de desarrollo e implementación orientado a contenedores es que elimina la mayoría de los problemas que surgen por configuraciones de entorno incoherentes. Además, los contenedores permiten una funcionalidad rápida de escalado vertical de las aplicaciones mediante la creación de nuevos contenedores según sea necesario.
Los conceptos clave para crear y trabajar con contenedores son:
| Concepto | Descripción |
|---|---|
| Host de contenedor | Máquina física o virtual configurada para hospedar contenedores. El host ejecutará uno o varios contenedores. |
| Imagen de contenedor | Una imagen consta de una unión de sistemas de archivos por capas apilados y es la base de un contenedor. Una imagen no tiene estado y nunca cambia a medida que se implementa en entornos diferentes. |
| Contenedor | Un contenedor es una instancia de una imagen en tiempo de ejecución. |
| Imagen de sistema operativo del contenedor | Los contenedores se implementan a partir de imágenes. La imagen del sistema operativo de contenedor es la primera de (quizá) muchas capas de imagen que componen un contenedor. Un sistema operativo de contenedor es inmutable y no se puede modificar. |
| Repositorio de contenedores | Cada vez que se crea una imagen de contenedor, esta y sus dependencias se almacenan en un repositorio local. Estas imágenes se pueden reutilizar muchas veces en el host de contenedor. Las imágenes de contenedor también pueden almacenarse en un registro público o privado, como Docker Hub, de forma que se puedan usar en varios hosts de contenedor diferentes. |
Las empresas adoptan cada vez más contenedores cuando implementan aplicaciones basadas en microservicios y Docker se ha convertido en la implementación de contenedor estándar que la mayoría de las plataformas de software y proveedores de nube han adoptado.
La aplicación de referencia eShop usa Docker para hospedar cuatro microservicios de back-end contenedorizados, como se muestra en el diagrama siguiente.
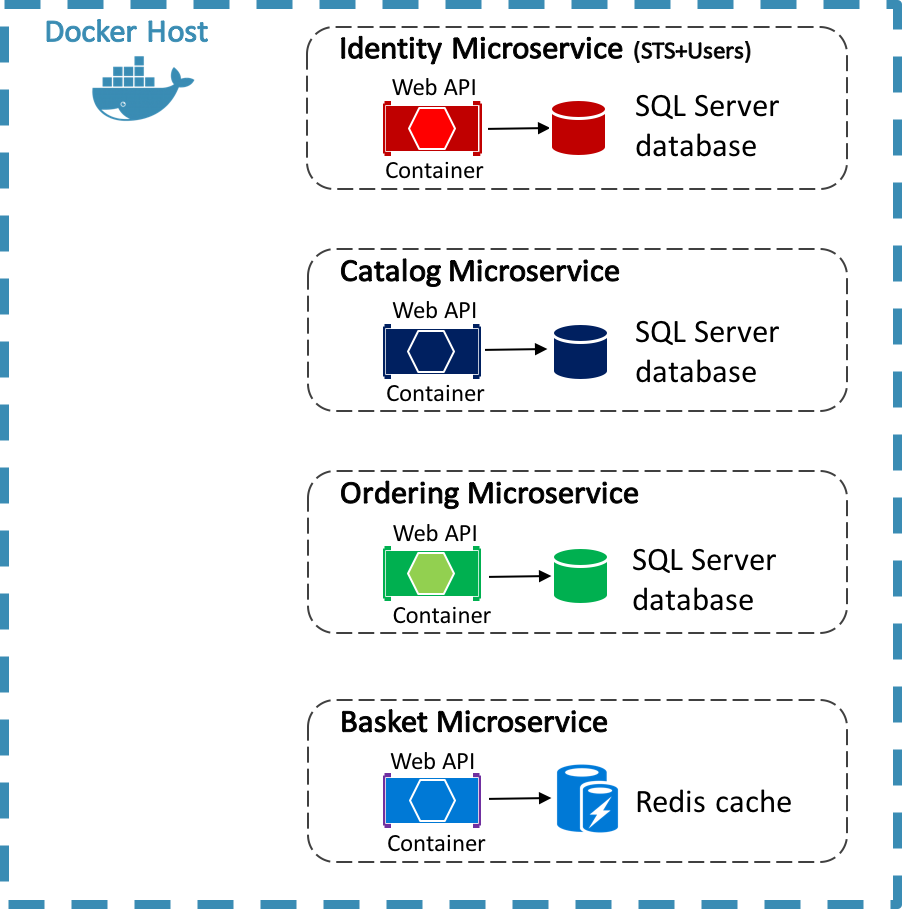
La arquitectura de los servicios de back-end de la aplicación de referencia se descompone en varios subsistemas autónomos en forma de microservicios y contenedores que colaboran. Cada microservicio proporciona una único área de funcionalidad: un servicio de identidad, un servicio de catálogo, un servicio de pedidos y un servicio de cesta.
Cada microservicio tiene su propia base de datos, lo que permite separarlo totalmente de otros microservicios. Cuando es necesario, la coherencia entre las bases de datos de diferentes microservicios se logra mediante eventos de nivel de aplicación. Para obtener más información, consulte Comunicación entre microservicios.
Comunicación entre cliente y microservicios
La aplicación multiplataforma eShop se comunica con los microservicios de back-end contenedorizados por medio de la comunicación directa de cliente a microservicio, como se muestra a continuación.
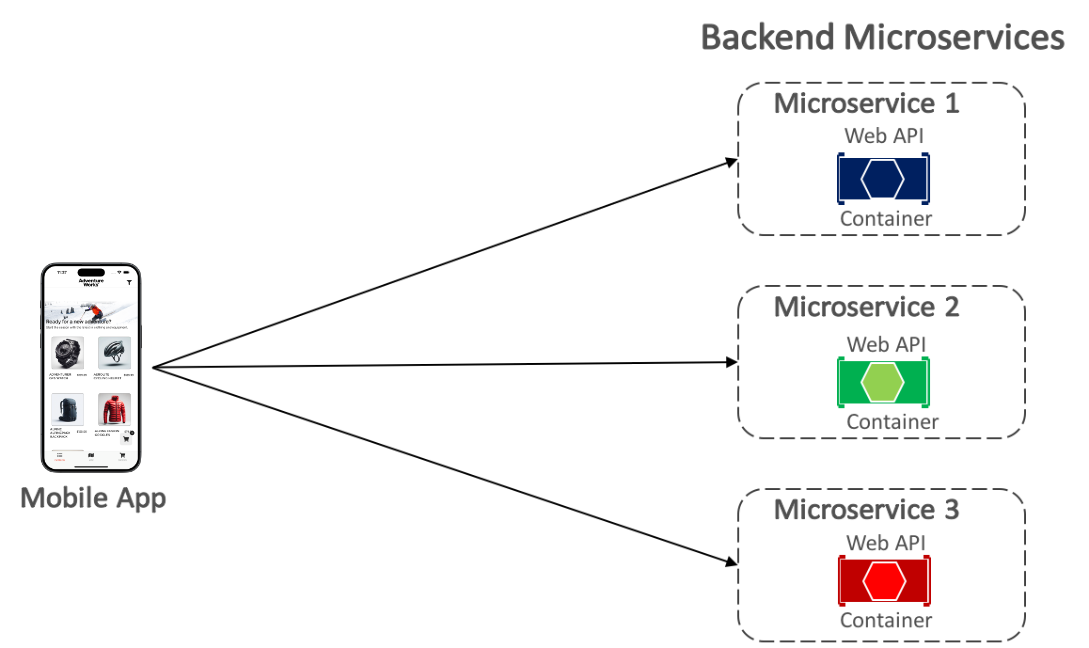
Con la comunicación directa de cliente a microservicio, la aplicación multiplataforma realiza solicitudes a cada microservicio directamente a través de su punto de conexión público, con un puerto TCP diferente por microservicio. En producción, el punto de conexión se suele asignar al equilibrador de carga del microservicio, que distribuye las solicitudes entre las instancias disponibles.
Sugerencia
Considere la posibilidad de usar la comunicación de puerta de enlace de API.
La comunicación directa de cliente a microservicio puede tener inconvenientes cuando se crea una aplicación basada en microservicios grande y compleja, pero está más que indicada para una aplicación pequeña. Considere la posibilidad de usar la comunicación de puerta de enlace de API cuando diseñe una aplicación basada en microservicios de gran tamaño con decenas de microservicios.
Comunicación entre microservicios
Una aplicación basada en microservicios es un sistema distribuido, que se puede ejecutar en varias máquinas. Lo habitual es que cada instancia de servicio sea un proceso. Por tanto, los servicios deben interactuar usando un protocolo de comunicación entre procesos, como HTTP, TCP y Advanced Message Queuing Protocol (AMQP), o protocolos binarios, en función de la naturaleza de cada servicio.
Los dos enfoques comunes para la comunicación entre microservicios son la comunicación REST basada en HTTP para consultar datos y la mensajería asincrónica ligera para comunicar actualizaciones en varios microservicios.
La comunicación controlada por eventos basada en la mensajería asincrónica es fundamental para propagar los cambios en varios microservicios. Con este enfoque, un microservicio publica un evento cuando sucede algo importante, por ejemplo, cuando actualiza una entidad empresarial. Otros microservicios se suscriben a estos eventos. Así, cuando un microservicio recibe un evento, actualiza sus propias entidades empresariales, lo que a su vez puede suponer que se publiquen más eventos. Esta funcionalidad de publicación-suscripción se suele lograr con un bus de eventos.
Un bus de eventos permite la comunicación de tipo suscripción-publicación entre microservicios, sin necesidad de que los componentes se reconozcan entre sí, como se muestra a continuación.
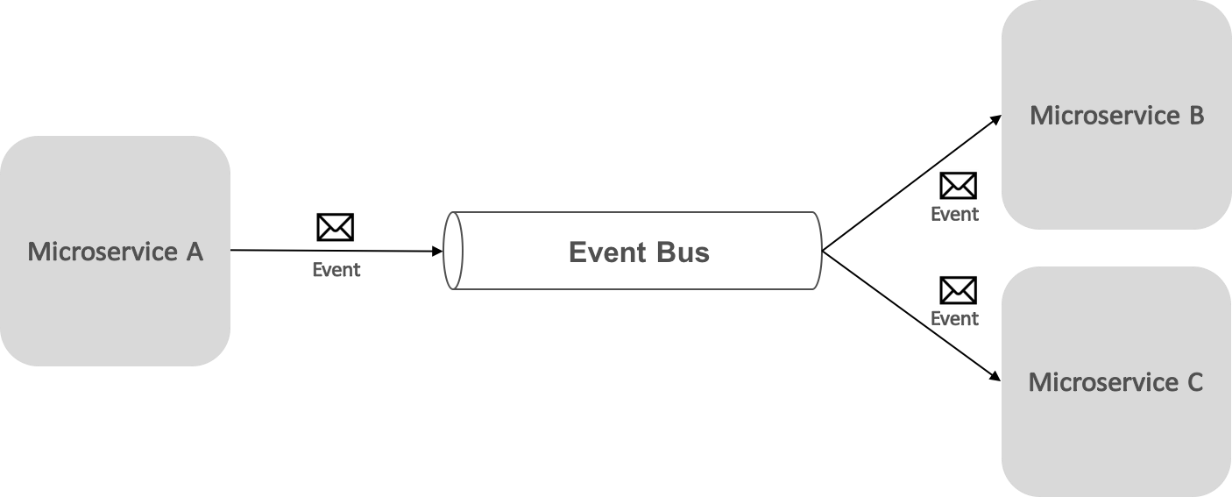
Desde la perspectiva de una aplicación, el bus de eventos es simplemente un canal de publicación-suscripción expuesto a través de una interfaz. Sin embargo, la forma en la que se implementa el bus de eventos puede variar. Por ejemplo, la implementación de un bus de eventos podría usar RabbitMQ, Azure Service Bus u otros buses de servicio, como NServiceBus y MassTransit. En el diagrama siguiente se muestra cómo se usa un bus de eventos en la aplicación de referencia eShop.

El bus de eventos de eShop, implementado con RabbitMQ, proporciona funcionalidad de publicación-suscripción de uno a varios. Esto significa que, después de publicar un evento, puede haber varios suscriptores escuchando el mismo evento. En el diagrama siguiente se muestra esta relación.
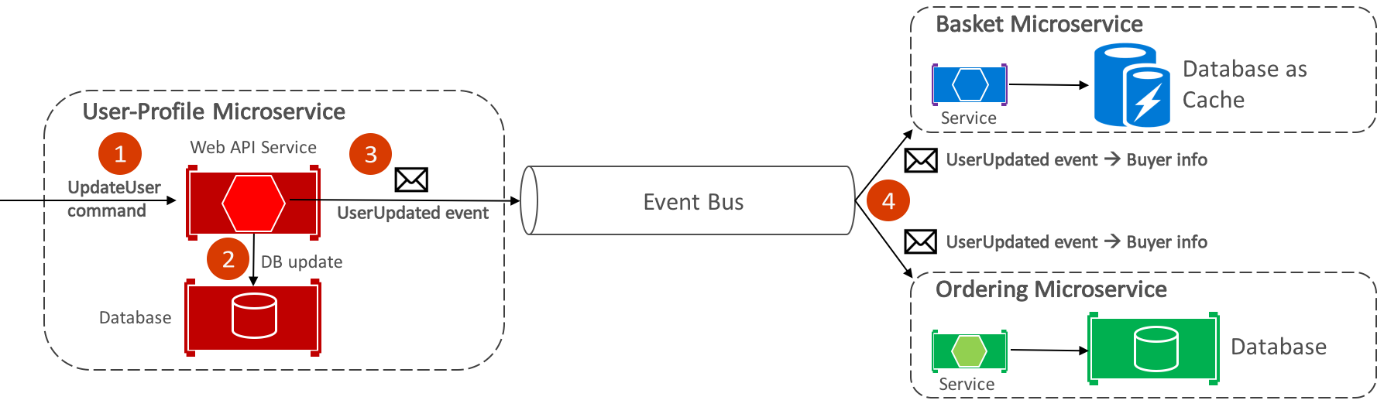
Este enfoque de comunicación de uno a varios usa eventos para implementar transacciones empresariales que abarcan varios servicios, lo que garantiza la coherencia final entre los servicios. Una transacción coherente consta de una serie de pasos distribuidos. Por tanto, cuando el microservicio de perfil de usuario recibe el comando UpdateUser, actualiza los detalles del usuario en su base de datos y publica el evento UserUpdated en el bus de eventos. Tanto el microservicio de cesta como el microservicio de pedidos se han suscrito para recibir este evento y, en respuesta, actualizan la información del comprador en sus respectivas bases de datos.
Resumen
Los microservicios ofrecen un enfoque para el desarrollo y la implementación de aplicaciones que es adecuado para los requisitos de agilidad, escala y confiabilidad de las aplicaciones en la nube modernas. Una de las principales ventajas de los microservicios es que se pueden escalar horizontalmente de forma independiente, lo que significa que se puede escalar un área funcional específica que requiere más capacidad de procesamiento o ancho de banda de red para atender la demanda sin escalar innecesariamente áreas de la aplicación que no experimentan una mayor demanda.
Un contenedor es un entorno operativo aislado, controlado por recursos y portátil en el que una aplicación se puede ejecutar sin tocar los recursos de otros contenedores ni el host. Las empresas adoptan cada vez más contenedores cuando implementan aplicaciones basadas en microservicios y Docker se ha convertido en la implementación de contenedor estándar que la mayoría de las plataformas de software y proveedores de nube han adoptado.
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.