Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Este contenido es un extracto del libro electrónico, ".NET Microservices Architecture for Containerized .NET Applications" (Arquitectura de microservicios de .NET para aplicaciones de .NET contenedorizadas), disponible en Documentación de .NET o como un PDF descargable y gratuito que se puede leer sin conexión.

Como se indicó anteriormente, debe controlar los errores que pueden tardar una cantidad variable de tiempo en recuperarse, como podría ocurrir al intentar conectarse a un servicio remoto o recurso. Controlar este tipo de error puede mejorar la estabilidad y la resistencia de una aplicación.
En un entorno distribuido, las llamadas a servicios y recursos remotos pueden producir errores debido a errores transitorios, como conexiones de red lentas y tiempos de espera, o si los recursos responden lentamente o no están disponibles temporalmente. Estos errores suelen corregirse solos pasado un tiempo, y una aplicación en la nube sólida debería estar preparada para controlarlos mediante el uso de una estrategia como el "Patrón de reintento".
Sin embargo, también puede haber situaciones en las que los errores se deben a eventos imprevistos que pueden tardar mucho más tiempo en corregirse. La gravedad de estos errores puede abarcar desde una pérdida parcial de la conectividad hasta la total detención de un servicio. En estas situaciones, podría ser inútil que una aplicación vuelva a intentar continuamente una operación que es poco probable que se realice correctamente.
En su lugar, la aplicación debe codificarse para aceptar que se ha producido un error en la operación y controlar el error en consecuencia.
El uso de los reintentos HTTP de forma descuidada podría crear ataques por denegación de servicio (DoS) dentro de su propio software. Dado que se produce un error en un microservicio o se realiza lentamente, varios clientes pueden reintentar repetidamente las solicitudes con errores. Esto crea un riesgo peligroso de un aumento exponencial del tráfico dirigido al servicio fallido.
Por lo tanto, necesita algún tipo de barrera de defensa para que las solicitudes excesivas se detengan cuando no vale la pena seguir intentando. Esa barrera de defensa es precisamente el interruptor.
El patrón de interruptor tiene una finalidad distinta a la del "patrón de reintento". El "patrón de reintento" permite a una aplicación reintentar una operación con la expectativa de que la operación se realizará correctamente. El patrón Circuit Breaker impide que una aplicación realice una operación que probablemente produzca un error. Una aplicación puede combinar estos dos patrones. Sin embargo, la lógica de reintento debe ser sensible a cualquier excepción devuelta por el disyuntor y debe abandonar los reintentos si el disyuntor indica que un error no es transitorio.
Implementación de un patrón de interruptor con IHttpClientFactory y Polly
Como sucede al implementar los reintentos, el enfoque recomendado para los interruptores es aprovechar las bibliotecas .NET de eficacia probada como Polly y su integración nativa con IHttpClientFactory.
Agregar una directiva de interruptor a la canalización de software intermedio saliente de IHttpClientFactory es tan sencillo como agregar un único fragmento de código incremental a lo que ya tiene cuando se usa IHttpClientFactory.
La única adición aquí al código usado para los reintentos de llamada HTTP es el código donde se agrega la directiva Circuit Breaker a la lista de directivas que se van a usar, como se muestra en el siguiente código incremental.
// Program.cs
var retryPolicy = GetRetryPolicy();
var circuitBreakerPolicy = GetCircuitBreakerPolicy();
builder.Services.AddHttpClient<IBasketService, BasketService>()
.SetHandlerLifetime(TimeSpan.FromMinutes(5)) // Sample: default lifetime is 2 minutes
.AddHttpMessageHandler<HttpClientAuthorizationDelegatingHandler>()
.AddPolicyHandler(retryPolicy)
.AddPolicyHandler(circuitBreakerPolicy);
El AddPolicyHandler() método es lo que agrega directivas a los HttpClient objetos que usará. En este caso, se agrega una directiva de Polly para un interruptor.
Para tener un enfoque más modular, la directiva circuit breaker se define en un método independiente denominado GetCircuitBreakerPolicy(), como se muestra en el código siguiente:
// also in Program.cs
static IAsyncPolicy<HttpResponseMessage> GetCircuitBreakerPolicy()
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.CircuitBreakerAsync(5, TimeSpan.FromSeconds(30));
}
En el ejemplo de código anterior, la directiva de interruptor se configura para que interrumpa o abra el circuito cuando se hayan producido cinco fallos consecutivos al reintentar las solicitudes HTTP. Cuando esto ocurre, el circuito se interrumpirá durante 30 segundos. En ese período, las llamadas no se podrán realizar debido al interruptor del circuito. La directiva interpreta automáticamente las excepciones pertinentes y los códigos de estado HTTP como errores.
Los interruptores también se deben usar para redirigir las solicitudes a una infraestructura de reserva siempre que haya tenido problemas en un recurso concreto implementado en otro entorno que no sea el de la aplicación cliente o del servicio que realiza la llamada HTTP. De este modo, si se produce una interrupción en el centro de datos que afecta solo a los microservicios de back-end, pero no a las aplicaciones cliente, estas aplicaciones pueden redirigir a los servicios de reserva. Polly está creando una directiva nueva para automatizar este escenario de directiva de conmutación por error.
Todas estas características sirven para los casos en los que se administra la conmutación por error desde el código .NET, y no cuando Azure lo hace de forma automática, con la transparencia de ubicación.
Desde un punto de vista de uso, al usar HttpClient, no es necesario agregar nada nuevo aquí porque el código es el mismo que cuando se usa HttpClient con IHttpClientFactory, como se muestra en las secciones anteriores.
Prueba de reintentos HTTP e interruptores en eShopOnContainers
Siempre que inicie la solución eShopOnContainers en un host de Docker, debe iniciar varios contenedores. Algunos de los contenedores son más lentos para iniciarse e inicializarse, como el contenedor de SQL Server. Esto es especialmente cierto la primera vez que implementa la aplicación eShopOnContainers en Docker porque necesita configurar las imágenes y la base de datos. El hecho de que algunos contenedores se inicien más lentamente que otros pueden hacer que el resto de los servicios inicie inicialmente excepciones HTTP, incluso si establece dependencias entre contenedores en el nivel docker-compose, como se explicó en las secciones anteriores. Esas dependencias de docker-compose entre contenedores solo están en el nivel de proceso. Es posible que se inicie el proceso de punto de entrada del contenedor, pero es posible que SQL Server no esté listo para las consultas. El resultado puede ser una cascada de errores y la aplicación puede obtener una excepción al intentar consumir ese contenedor determinado.
También puede ver este tipo de error al iniciarse cuando la aplicación se implementa en la nube. En ese caso, los orquestadores pueden mover contenedores de un nodo o máquina virtual a otro (es decir, iniciar nuevas instancias) al equilibrar el número de contenedores entre los nodos del clúster.
La forma en que "eShopOnContainers" resuelve esos problemas al iniciar todos los contenedores es mediante el patrón Retry mostrado anteriormente.
Prueba del disyuntor en eShopOnContainers
Hay varias maneras de romper o abrir el circuito y probarlo con eShopOnContainers.
Una opción es reducir el número permitido de reintentos a 1 en la directiva del disyuntor y volver a implementar toda la solución en Docker. Con un solo reintento, hay una gran probabilidad de que una solicitud HTTP falle durante la implementación, el interruptor se abra y se produzca un error.
Otra opción es usar middleware personalizado que se implementa en el microservicio Basket . Cuando este middleware está habilitado, detecta todas las solicitudes HTTP y devuelve el código de estado 500. Para habilitar el middleware, envíe una solicitud GET al URI que falla, de forma similar a esta:
GET http://localhost:5103/failing
Esta solicitud devuelve el estado actual del middleware. Si el middleware está habilitado, el código de estado de la solicitud será devuelto como 500. Si el middleware está deshabilitado, no hay respuesta.GET http://localhost:5103/failing?enable
Esta solicitud habilita el middleware.GET http://localhost:5103/failing?disable
Esta solicitud deshabilita el middleware.
Por ejemplo, una vez que se ejecuta la aplicación, puede habilitar el middleware realizando una solicitud mediante el siguiente URI en cualquier explorador. Tenga en cuenta que el microservicio de pedidos usa el puerto 5103.
http://localhost:5103/failing?enable
A continuación, puede comprobar el estado mediante el URI http://localhost:5103/failing, como se muestra en la figura 8-5.
Figura 8-5. Comprobación del estado del middleware ASP.NET "con errores": en este caso, deshabilitado.
En este momento, el microservicio Basket responde con el código de estado 500 cada vez que se llama a invocarlo.
Una vez que se ejecuta el middleware, puede intentar realizar un pedido desde la aplicación web MVC. Como se produce un error en las solicitudes, el circuito se abre.
En el ejemplo siguiente, la aplicación web MVC presenta un bloque catch en la lógica para realizar un pedido. Si el código detecta una excepción de circuito abierto, muestra al usuario un mensaje descriptivo que les indica que esperen.
public class CartController : Controller
{
//…
public async Task<IActionResult> Index()
{
try
{
var user = _appUserParser.Parse(HttpContext.User);
//Http requests using the Typed Client (Service Agent)
var vm = await _basketSvc.GetBasket(user);
return View(vm);
}
catch (BrokenCircuitException)
{
// Catches error when Basket.api is in circuit-opened mode
HandleBrokenCircuitException();
}
return View();
}
private void HandleBrokenCircuitException()
{
TempData["BasketInoperativeMsg"] = "Basket Service is inoperative, please try later on. (Business message due to Circuit-Breaker)";
}
}
Este es un resumen. La política de reintento intenta varias veces realizar la solicitud HTTP y encuentra errores HTTP. Cuando el número de reintentos alcanza el número máximo establecido para la directiva del interruptor (en este caso, 5), la aplicación genera una excepción BrokenCircuitException. El resultado es un mensaje amigable, como se muestra en la Figura 8-6.
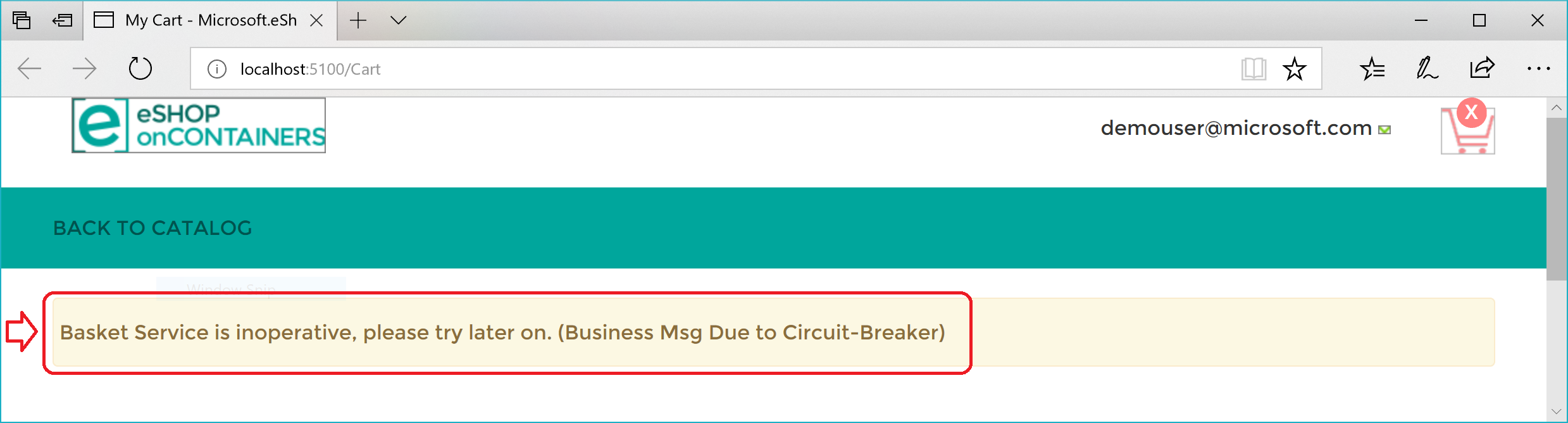
Figura 8-6. Interruptor que devuelve un error en la interfaz de usuario
Puede implementar una lógica diferente para cuándo abrir o interrumpir el circuito. También puede probar una solicitud HTTP en un microservicio de back-end distinto si se dispone de un centro de datos de reserva o un sistema back-end redundante.
Finalmente, otra opción para CircuitBreakerPolicy es usar Isolate (que fuerza la apertura y mantiene abierto el circuito) y Reset (que lo cierra de nuevo). Se pueden usar para crear un punto de conexión HTTP utilitario que invoque Isolate y Reset directamente en la política. Este punto de conexión HTTP se podría utilizar, debidamente protegido, en producción para aislar temporalmente un sistema aguas abajo, como cuando quieras actualizarlo. También puede activar el circuito manualmente para proteger un sistema de nivel inferior que le parezca que está fallando.
Recursos adicionales
-
Patrón Circuit Breaker
https://learn.microsoft.com/azure/architecture/patterns/circuit-breaker
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.