Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Este contenido es un extracto del libro electrónico, ".NET Microservices Architecture for Containerized .NET Applications" (Arquitectura de microservicios de .NET para aplicaciones de .NET contenedorizadas), disponible en Documentación de .NET o como un PDF descargable y gratuito que se puede leer sin conexión.

Los componentes de persistencia de datos proporcionan acceso a los datos hospedados dentro de los límites de un microservicio (es decir, la base de datos de un microservicio). Contienen la implementación real de componentes como repositorios y clases unitarias de trabajo , como objetos de Entity Framework (EF) DbContext personalizados. DbContext de EF implementa los patrones de repositorio y de unidad de trabajo.
El patrón de repositorio
El patrón Repositorio es un patrón de diseño Domain-Driven diseñado para mantener los problemas de persistencia fuera del modelo de dominio del sistema. Una o varias abstracciones de persistencia ( interfaces) se definen en el modelo de dominio y estas abstracciones tienen implementaciones en forma de adaptadores específicos de persistencia definidos en otra parte de la aplicación.
Las implementaciones del repositorio son clases que encapsulan la lógica necesaria para acceder a los orígenes de datos. Centralizan la funcionalidad de acceso a datos comunes, lo que proporciona una mejor capacidad de mantenimiento y desacoplan la infraestructura o la tecnología usadas para acceder a las bases de datos desde el modelo de dominio. Si se usa un asignador relacional de objetos (ORM) como Entity Framework, se simplifica el código que se debe implementar, gracias a LINQ y al establecimiento inflexible de tipos. Esto le permite centrarse en la lógica de persistencia de datos en lugar de en la fontanería de acceso a datos.
El patrón Repository es una forma bien documentada de trabajar con un origen de datos. En el libro Patrones de arquitectura de aplicaciones empresariales, Martin Fowler describe un repositorio de la siguiente manera:
Un repositorio realiza las tareas de un intermediario entre las capas del modelo de dominio y la asignación de datos, actuando de forma similar a un conjunto de objetos de dominio en memoria. Los objetos cliente crean consultas mediante declaración y las envían a los repositorios para obtener respuestas. Conceptualmente, un repositorio encapsula un conjunto de objetos almacenados en la base de datos y las operaciones que se pueden realizar en ellos, lo que proporciona una manera más cercana a la capa de persistencia. Los repositorios, además, cumplen el propósito de separar, de manera clara y en una sola dirección, la dependencia entre el ámbito de trabajo y la asignación o mapeo de datos.
Definir un repositorio por agregado
Para cada agregado o raíz agregada, se debe crear una clase de repositorio. Puede aprovechar los genéricos de C# para reducir el número total de clases concretas que necesita mantener (como se muestra más adelante en este capítulo). En un microservicio basado en patrones de Domain-Driven Design (DDD), el único canal que debe utilizar para actualizar la base de datos son los repositorios. Esto se debe a que tienen una relación uno a uno con la raíz de agregado, que controla las invariables del agregado y la coherencia transaccional. Está bien consultar la base de datos a través de otros canales (como puede hacer siguiendo un enfoque de CQRS), ya que las consultas no cambian el estado de la base de datos. Sin embargo, el área transaccional (es decir, las actualizaciones) siempre debe controlarse mediante los repositorios y las raíces agregadas.
Básicamente, un repositorio permite rellenar los datos en la memoria que proceden de la base de datos en forma de entidades de dominio. Una vez que las entidades están en memoria, se pueden cambiar y, a continuación, conservarse de nuevo en la base de datos a través de transacciones.
Como se indicó anteriormente, si usa el patrón de arquitectura CQS/CQRS, las consultas iniciales se realizan mediante consultas en paralelo fuera del modelo de dominio, mediante instrucciones SQL simples utilizando Dapper. Este enfoque es mucho más flexible que los repositorios, ya que puede consultar y combinar las tablas que necesite, y estas consultas no están restringidas por reglas de los agregados. Esos datos van a la capa de presentación o a la aplicación cliente.
Si el usuario realiza cambios, los datos que se van a actualizar proceden de la aplicación cliente o la capa de presentación a la capa de aplicación (por ejemplo, un servicio de API web). Cuando recibe un comando en un controlador de comandos, se usan repositorios para obtener los datos que desea actualizar desde la base de datos. Actualizas los datos en memoria mediante los comandos proporcionados y luego agregas o actualizas las entidades de dominio en la base de datos a través de una transacción.
Es importante resaltar de nuevo que solo debe definir un repositorio para cada raíz de agregado, como se muestra en la figura 7-17. Para lograr el objetivo del elemento raíz del agregado con el fin de mantener la coherencia transaccional entre todos los objetos dentro del agregado, nunca debe crear un repositorio para cada tabla de la base de datos.
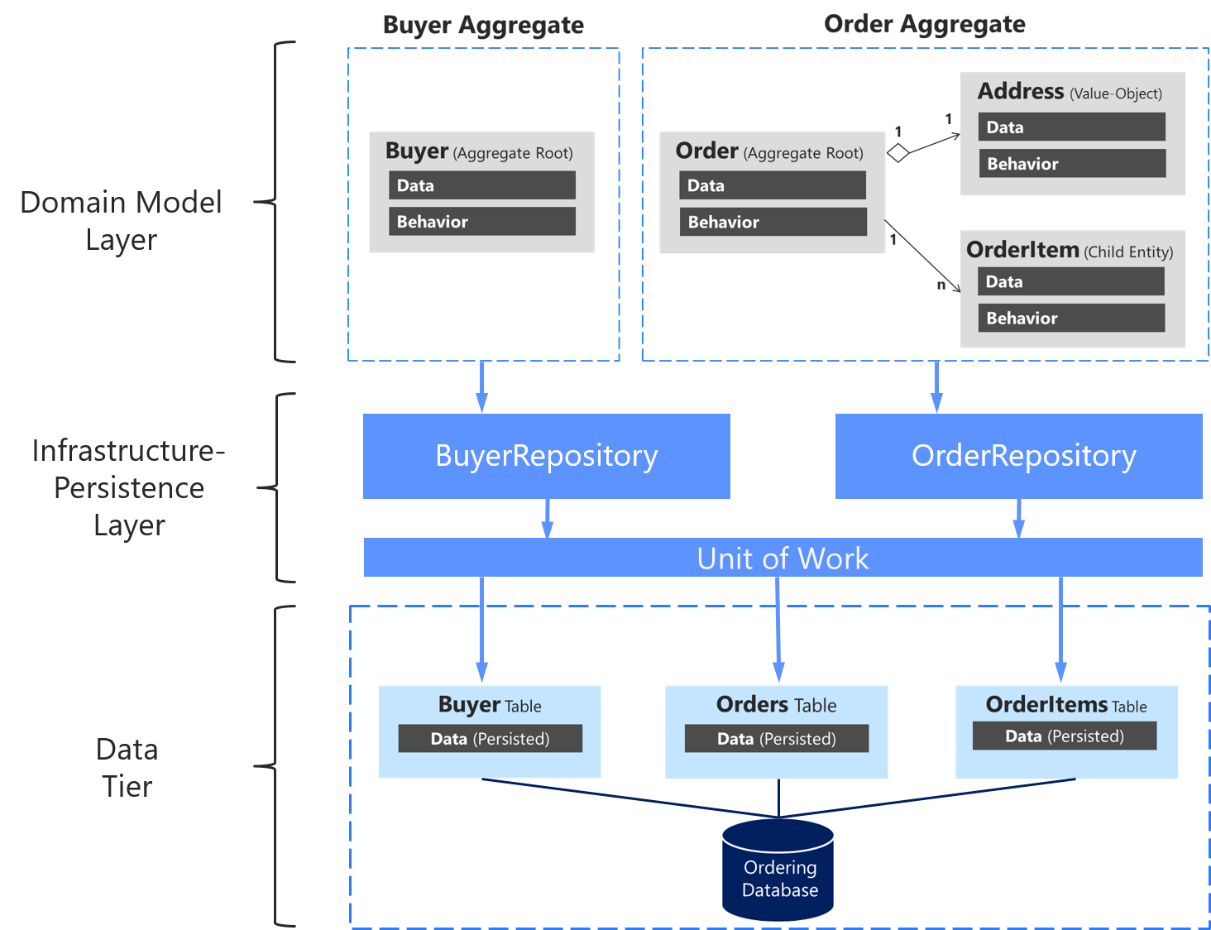
Figura 7-17. Relación entre repositorios, agregados y tablas de base de datos
En el diagrama anterior se muestran las relaciones entre las capas de Dominio e Infraestructura: el agregado de compradores depende de la interfaz IBuyerRepository y el agregado de pedidos depende de las interfaces IOrderRepository. Estas interfaces se implementan en la capa de Infraestructura por los repositorios correspondientes que dependen de UnitOfWork, también implementados allí, que acceden a las tablas del nivel de Datos.
Aplicación de una raíz agregada por repositorio
Puede ser útil implementar el diseño del repositorio de tal manera que aplique la regla que solo las raíces agregadas deben tener repositorios. Puede crear un tipo de repositorio genérico o base que restrinja el tipo de entidades con las que funciona para asegurarse de que tienen la interfaz de IAggregateRoot marcador.
Por lo tanto, cada clase de repositorio implementada en el nivel de infraestructura implementa su propio contrato o interfaz, como se muestra en el código siguiente:
namespace Microsoft.eShopOnContainers.Services.Ordering.Infrastructure.Repositories
{
public class OrderRepository : IOrderRepository
{
// ...
}
}
Cada interfaz de repositorio específica implementa la interfaz IRepository genérica:
public interface IOrderRepository : IRepository<Order>
{
Order Add(Order order);
// ...
}
Sin embargo, una mejor manera de hacer que el código aplique la convención de que cada repositorio está relacionado con un único agregado es implementar un tipo de repositorio genérico. De este modo, es explícito que usa un repositorio para tener como destino un agregado específico. Esto se puede hacer fácilmente mediante la implementación de una interfaz base genérica IRepository , como en el código siguiente:
public interface IRepository<T> where T : IAggregateRoot
{
//....
}
El patrón Repository facilita la prueba de la lógica de la aplicación.
El patrón Repository permite probar fácilmente la aplicación con pruebas unitarias. Recuerde que las pruebas unitarias solo prueban el código, no la infraestructura, por lo que las abstracciones del repositorio facilitan la consecución de ese objetivo.
Como se indicó en una sección anterior, se recomienda definir y colocar las interfaces del repositorio en el nivel de modelo de dominio para que la capa de aplicación, como el microservicio de api web, no dependa directamente del nivel de infraestructura donde haya implementado las clases de repositorio reales. Al hacerlo y usar la inserción de dependencias en los controladores de la API web, puede implementar repositorios ficticios que devuelvan datos falsos en lugar de datos de la base de datos. Este enfoque desacoplado permite crear y ejecutar pruebas unitarias que centran la lógica de la aplicación sin necesidad de conectividad con la base de datos.
Las conexiones a bases de datos pueden producir errores y, lo que es más importante, ejecutar cientos de pruebas en una base de datos es incorrecta por dos motivos. En primer lugar, puede tardar mucho tiempo debido al gran número de pruebas. En segundo lugar, los registros de base de datos podrían cambiar y afectar a los resultados de las pruebas, especialmente si las pruebas se ejecutan en paralelo, de modo que podrían no ser coherentes. Las pruebas unitarias normalmente se pueden ejecutar en paralelo; Es posible que las pruebas de integración no admitan la ejecución en paralelo en función de su implementación. Las pruebas en la base de datos no son una prueba unitaria, sino una prueba de integración. Debe tener muchas pruebas unitarias que se ejecutan rápidamente, pero menos pruebas de integración en las bases de datos.
En cuanto a la separación de intereses para las pruebas unitarias, la lógica funciona en entidades de dominio en memoria, ya que supone que la clase de repositorio las ha entregado. Una vez que la lógica modifica las entidades de dominio, supone que la clase de repositorio las almacenará correctamente. El punto importante aquí es crear pruebas unitarias contra tu modelo de dominio, así como su lógica de dominio. Las raíces agregadas son los límites de coherencia principales en DDD.
Los repositorios implementados en eShopOnContainers se basan en la implementación dbContext de EF Core de los patrones de repositorio y unidad de trabajo mediante su seguimiento de cambios, por lo que no duplican esta funcionalidad.
La diferencia entre el patrón Repository y el patrón heredado de la clase Data Access (clase DAL)
Un objeto DAL típico realiza directamente operaciones de acceso a datos y persistencia en el almacenamiento, a menudo en el nivel de una sola tabla y fila. Las operaciones CRUD simples implementadas con un conjunto de clases DAL con frecuencia no admiten transacciones (aunque esto no siempre es así). La mayoría de los enfoques de clase DAL hacen un uso mínimo de abstracciones, lo que da lugar a un acoplamiento estricto entre las clases de aplicación o capa lógica de negocios (BLL) que llaman a los objetos DAL.
Al usar el repositorio, los detalles de implementación de la persistencia se encapsulan fuera del modelo de dominio. El uso de una abstracción facilita la extensión del comportamiento a través de patrones como Decoradores o Proxies. Por ejemplo, los problemas transversales, como el almacenamiento en caché, el registro y el control de errores, se pueden aplicar mediante estos patrones en lugar de codificarse de forma rígida en el propio código de acceso a datos. También es sencillo admitir varios adaptadores de repositorio que se pueden usar en diferentes entornos, desde el desarrollo local hasta los entornos de ensayo compartidos y de producción.
Implementación de unidades de trabajo
Una unidad de trabajo hace referencia a una sola transacción que implica varias operaciones de inserción, actualización o eliminación. En términos simples, significa que para una acción de usuario específica, como un registro en un sitio web, todas las operaciones de inserción, actualización y eliminación se controlan en una sola transacción. Esto es más eficaz que manejar varias operaciones de base de datos de una manera más comunicativa.
Estas múltiples operaciones de persistencia se realizan posteriormente en una sola acción cuando el código de la capa de aplicación lo ordena. La decisión sobre la aplicación de los cambios en memoria al almacenamiento de base de datos real se basa normalmente en el patrón unidad de trabajo. En EF, el patrón Unit of Work se implementa mediante DbContext y se ejecuta cuando se realiza una llamada a SaveChanges.
En muchos casos, este patrón o forma de aplicar operaciones en el almacenamiento puede aumentar el rendimiento de la aplicación y reducir la posibilidad de incoherencias. También reduce el bloqueo de transacciones en las tablas de base de datos, ya que todas las operaciones previstas se confirman como parte de una transacción. Esto es más eficaz en comparación con la ejecución de muchas operaciones aisladas en la base de datos. Por lo tanto, el ORM seleccionado puede optimizar la ejecución en la base de datos mediante la agrupación de varias acciones de actualización dentro de la misma transacción, en lugar de muchas ejecuciones de transacciones pequeñas y independientes.
El patrón Unit of Work se puede implementar con o sin usar el patrón Repository.
Los repositorios no deben ser obligatorios
Los repositorios personalizados son útiles por los motivos mencionados anteriormente y es el enfoque para el microservicio de ordenación en eShopOnContainers. Sin embargo, no es un patrón esencial implementar en un diseño DDD o incluso en el desarrollo general de .NET.
Por ejemplo, Jimmy Bogard, al proporcionar comentarios directos para esta guía, dijo lo siguiente:
Esto probablemente será mi comentario más significativo. Realmente no soy un fan de repositorios, principalmente porque ocultan los detalles importantes del mecanismo de persistencia subyacente. Es por eso que también prefiero MediatR para los comandos. Puedo usar toda la potencia de la capa de persistencia e insertar todo ese comportamiento de dominio en mis raíces agregadas. Normalmente no quiero simular mis repositorios: todavía necesito tener esa prueba de integración con lo real. Adoptar CQRS significó que realmente ya no teníamos necesidad de los repositorios.
Los repositorios pueden ser útiles, pero no son críticos para el diseño de DDD de la manera en que el patrón Aggregate y un modelo de dominio enriquecido son. Por lo tanto, use el patrón de repositorio o no, como considere oportuno.
Recursos adicionales
Patrón de repositorio
Edward Hieatt y Rob me. Patrón de repositorio.
https://martinfowler.com/eaaCatalog/repository.htmlEl patrón de repositorio
https://learn.microsoft.com/previous-versions/msp-n-p/ff649690(v=pandp.10)Eric Evans. "Domain-Driven Design: Tackling Complexity in the Heart of Software" (Diseño orientado al dominio: abordar la complejidad en el corazón del software). (Libro; incluye una explicación del patrón repositorio)
https://www.amazon.com/Domain-Driven-Design-Tackling-Complexity-Software/dp/0321125215/
Patrón de unidad de trabajo
Martin Fowler. Patrón de unidad de trabajo.
https://martinfowler.com/eaaCatalog/unitOfWork.htmlImplementación del repositorio y los patrones de unidad de trabajo en una aplicación MVC de ASP.NET
https://learn.microsoft.com/aspnet/mvc/overview/older-versions/getting-started-with-ef-5-using-mvc-4/implementing-the-repository-and-unit-of-work-patterns-in-an-asp-net-mvc-application
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.