Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Este contenido es un extracto del libro electrónico "Architect Modern Web Applications with ASP.NET Core and Azure" (Diseño de la arquitectura de aplicaciones web modernas con ASP.NET Core y Azure), disponible en Documentación de .NET o como un PDF descargable y gratuito para leerlo sin conexión.

"Los datos son algo muy valioso y durarán más que los propios sistemas".
Tim Berners-Lee
El acceso a datos es una parte importante de la mayoría de las aplicaciones de software. ASP.NET Core admite varias opciones de acceso a datos, incluido Entity Framework Core (así como Entity Framework 6) y puede funcionar con cualquier marco de acceso a datos de .NET. La elección del marco de acceso a datos que se va a usar depende de las necesidades de la aplicación. La abstracción de estas opciones de los proyectos ApplicationCore y UI, y la encapsulación de los detalles de implementación en la infraestructura, ayuda a crear software de acoplamiento flexible y que se pueda probar.
Entity Framework Core (para bases de datos relacionales)
Si va a escribir una aplicación ASP.NET Core nueva que tenga que trabajar con datos relacionales, Entity Framework Core (EF Core) es la manera recomendada para que la aplicación tenga acceso a sus datos. EF Core es un asignador relacional de objetos (O/RM) que permite a los desarrolladores de .NET persistir objetos en y desde un origen de datos. Elimina la necesidad de la mayor parte del código de acceso a datos que los desarrolladores normalmente tendrían que escribir. Al igual que ASP.NET Core, EF Core se ha vuelto a escribir desde el principio para admitir aplicaciones multiplataforma modulares. Se agrega a la aplicación como un paquete NuGet, se configura durante el inicio de la aplicación y se solicita a través de la inserción de dependencias siempre que se necesite.
Para usar EF Core con una base de datos de SQL Server, ejecute el comando siguiente de la CLI de DotNet:
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
Para agregar compatibilidad para un origen de datos InMemory, para las pruebas:
dotnet add package Microsoft.EntityFrameworkCore.InMemory
DbContext
Para trabajar con EF Core, necesita una subclase de DbContext. Esta clase contiene propiedades que representan las colecciones de las entidades con las que la aplicación va a trabajar. En el ejemplo eShopOnWeb, se incluye un elemento CatalogContext con colecciones de productos, marcas y tipos:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
El elemento DbContext debe tener un constructor que acepte DbContextOptions y pase este argumento al constructor DbContext base. Si solo tiene un elemento DbContext en la aplicación, puede pasar una instancia de DbContextOptions, pero, si tiene más, tendrá que usar el tipo genérico DbContextOptions<T> y pasar el tipo de DbContext como el parámetro genérico.
Configuración de EF Core
En la aplicación de ASP.NET Core, normalmente configurará EF Core en Program.cs con otras dependencias de la aplicación. EF Core usa un elemento DbContextOptionsBuilder, que admite varios métodos de extensión útiles para optimizar su configuración. Para configurar CatalogContext para usar una base de datos de SQL Server con una cadena de conexión definida en la configuración, se debe agregar el código siguiente:
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
Para usar la base de datos en memoria:
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
Después de instalar EF Core, crear un tipo secundario de DbContext y agregar el tipo a los servicios de la aplicación, ya tiene todo listo para usar EF Core. Puede solicitar una instancia del tipo de DbContext en cualquier servicio que lo necesite y empezar a trabajar con las entidades persistentes con LINQ como si simplemente estuvieran en una colección. EF Core realiza el trabajo de traducir las expresiones de LINQ a consultas SQL para almacenar y recuperar los datos.
Puede ver las consultas que ejecuta EF Core si configura un registrador y se asegura de que su nivel se establece al menos en Información, como se muestra en la figura 8-1.
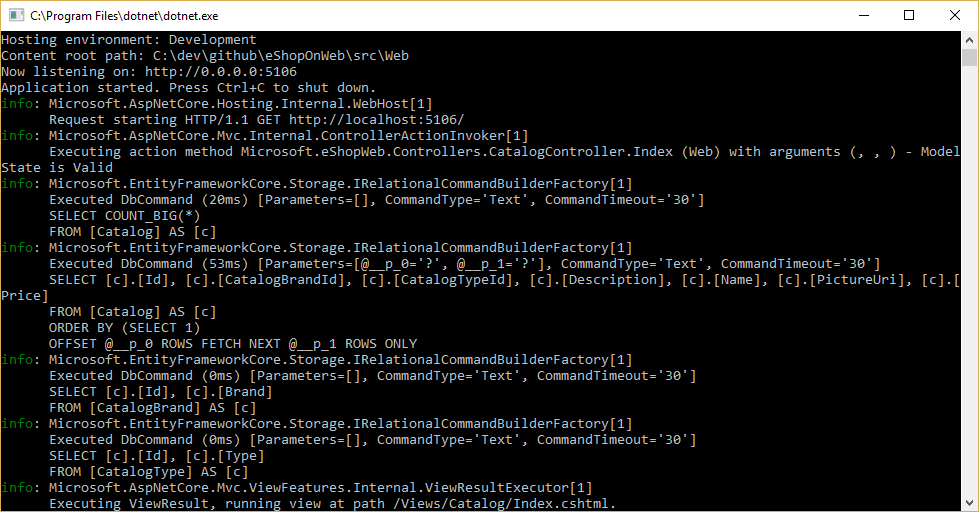
Figura 8-1. Registro de consultas de EF Core en la consola
Recuperación y almacenamiento de los datos
Para recuperar datos de EF Core, se obtiene acceso a la propiedad adecuada y se usa LINQ para filtrar el resultado. También se puede usar LINQ para realizar la proyección, y transformar el resultado de un tipo a otro. En el ejemplo siguiente, se recuperaría CatalogBrands, ordenadas por nombre, filtradas por su propiedad Enabled y proyectadas en un tipo SelectListItem:
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
En el ejemplo anterior, es importante agregar la llamada a ToListAsync para ejecutar la consulta inmediatamente. En caso contrario, la instrucción asignará un elemento IQueryable<SelectListItem> a brandItems, que no se ejecutará hasta que se enumere. Devolver los resultados de IQueryable desde los métodos tiene sus ventajas y desventajas. Permite modificar más la consulta que EF Core va a construir, pero también se pueden generan errores que solo se producen en tiempo de ejecución, si se agregan a la consulta operaciones que EF Core no puede traducir. Generalmente, es más seguro pasar los filtros al método que realiza el acceso a datos y devolver una colección en memoria (por ejemplo, List<T>) como resultado.
EF Core realiza el seguimiento de los cambios en las entidades que recupera de la persistencia. Para guardar los cambios en una entidad de la que se realiza el seguimiento, simplemente llame al método SaveChangesAsync en DbContext, asegurándose de que sea la misma instancia de DbContext que se usó para recuperar la entidad. La adición y eliminación de entidades se realiza directamente en la propiedad DbSet adecuada, de nuevo con una llamada a SaveChangesAsync para ejecutar los comandos de base de datos. En el ejemplo siguiente se muestra cómo agregar, actualizar y quitar entidades de la persistencia.
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
EF Core es compatible con métodos sincrónicos y asincrónicos para recuperar y guardar. En las aplicaciones web, se recomienda usar el patrón async/await con los métodos asincrónicos, para que los subprocesos de servidor web no se bloqueen mientras se espera a que finalicen las operaciones de acceso a datos.
Para más información, consulte Almacenamiento en búfer y streaming.
Recuperación de datos relacionados
Cuando EF Core recupera entidades, rellena todas las propiedades que se almacenan directamente con esa entidad en la base de datos. Las propiedades de navegación, como las listas de entidades relacionadas, no se rellenan y pueden tener su valor establecido en NULL. Este proceso garantiza que EF Core no recupere cambios de más datos de los necesarios, lo que es especialmente importante para las aplicaciones web, que deben procesar las solicitudes rápidamente y devolver respuestas de manera eficiente. Para incluir las relaciones con una entidad mediante la carga diligente, especifique la propiedad con el método de extensión Include en la consulta, como se muestra aquí:
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
Puede incluir varias relaciones y también relaciones secundarias mediante ThenInclude. EF Core ejecutará una sola consulta para recuperar el conjunto resultante de entidades. Como alternativa, puede incluir propiedades de navegación de las propiedades de navegación; para ello, pase una cadena separada por "." al método de extensión .Include(). Por ejemplo:
.Include("Items.Products")
Además de encapsular la lógica de filtro, puede especificar la forma de los datos que se van a devolver, incluidas las propiedades que se van a rellenar. En el ejemplo de eShopOnWeb se incluyen varias especificaciones que demuestran cómo encapsular información de carga diligente dentro de la especificación. Puede ver cómo se usa la especificación como parte de una consulta aquí:
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
Otra opción para cargar los datos relacionados consiste en usar la carga explícita. La carga explícita permite cargar datos adicionales en una entidad que ya se ha recuperado. Como este enfoque implica una solicitud independiente a la base de datos, no se recomienda para las aplicaciones web, que deben minimizar el número de recorridos de ida y vuelta a la base de datos realizados por cada solicitud.
La carga diferida es una característica que carga automáticamente los datos relacionados tal y como la aplicación hace referencia a ellos. EF Core ha agregado compatibilidad para la carga diferida en la versión 2.1. La carga diferida no está habilitada de forma predeterminada y requiere que se instale Microsoft.EntityFrameworkCore.Proxies. Como sucede con la carga explícita, normalmente la carga diferida se debe deshabilitar para las aplicaciones web, ya que su uso dará como resultado que se realicen consultas de base de datos adicionales dentro de cada solicitud web. Desafortunadamente, la sobrecarga que produce la carga diferida a menudo pasa desapercibida en tiempo de desarrollo, cuando la latencia es reducida y los conjuntos de datos que se usan para las pruebas normalmente son pequeños. Pero en producción, con más usuarios, datos y latencia, las solicitudes de base de datos adicionales pueden causar un bajo rendimiento para las aplicaciones web que hacen un uso intensivo de la carga diferida.
Avoid Lazy Loading Entities in ASPNET Applications (Evitar la carga diferida de entidades en aplicaciones ASP.NET)
Es recomendable probar la aplicación para examinar las consultas reales de base de datos que realiza. En determinadas circunstancias, EF Core puede realizar muchas más consultas o una consulta que consume más recursos de lo que es óptimo para la aplicación. Este problema se conoce como explosión cartesiana. El equipo de EF Core pone a disposición el método AsSplitQuery como una de las maneras para optimizar el comportamiento en tiempo de ejecución.
Encapsulación de datos
EF Core admite varias características que permiten que el modelo encapsule correctamente su estado. Un problema habitual de los modelos de dominio es que exponen propiedades de navegación de colecciones como tipos de lista públicamente accesibles. Este problema permite que cualquier colaborador manipule el contenido de estos tipos de colecciones, con lo que se pueden omitir importantes reglas de negocio relacionadas con la colección, lo que podría dejar el objeto en un estado no válido. La solución a este problema es conceder acceso de solo lectura a las colecciones relacionadas y proporcionar explícitamente métodos que definan formas para que los clientes las manipulen, como en el ejemplo siguiente:
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
Este tipo de entidad no expone ninguna propiedad List o ICollection pública, sino que expone un tipo IReadOnlyCollection que encapsula el tipo de lista subyacente. Al usar este patrón, puede indicar a Entity Framework Core que use el campo de respaldo de esta manera:
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
Otra manera de mejorar el modelo de dominio es usar objetos de valor para los tipos que carecen de identidad y solo se distinguen por sus propiedades. Usar estos tipos como propiedades de sus entidades puede ayudar a mantener la lógica específica del objeto de valor al que pertenece y evitar que se duplique la lógica en varias entidades que usen el mismo concepto. En Entity Framework Core, puede conservar los objetos de valor en la misma tabla que su entidad en propiedad configurando el tipo como entidad en propiedad. Por ejemplo:
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
En este ejemplo, la propiedad ShipToAddress es del tipo Address.
Address es un objeto de valor con varias propiedades, como Street y City. EF Core asigna el objeto Order a su tabla con una columna por propiedad Address y agrega el nombre de la propiedad como prefijo a cada nombre de columna. En este ejemplo, la tabla Order incluye columnas como ShipToAddress_Street y ShipToAddress_City. También es posible almacenar los tipos de propiedad en tablas independientes, si es lo que se busca hacer.
Obtenga más información sobre la compatibilidad con entidades en EF Core.
Conexiones resistentes
En ocasiones, los recursos externos como las bases de datos SQL pueden no estar disponibles. En casos de indisponibilidad temporal, las aplicaciones pueden usar lógica de reintento para evitar que se genere una excepción. Esta técnica se conoce normalmente como resistencia de la conexión. Se puede implementar una técnica de reintento con retroceso exponencial propia intentando el reintento con un tiempo de espera que aumenta exponencialmente, hasta que se alcance un número máximo de reintentos. Esta técnica se basa en el hecho de que es posible que los recursos en la nube no estén disponibles de forma intermitente durante breves períodos, lo que produciría un error en algunas solicitudes.
Para Azure SQL DB, Entity Framework Core ya proporciona la lógica de reintento y resistencia de conexión de base de datos interna. Pero debe habilitar la estrategia de ejecución de Entity Framework para cada conexión de DbContext si quiere tener conexiones resistentes de EF Core.
Por ejemplo, el código siguiente en el nivel de conexión de EF Core permite conexiones resistentes de SQL que se vuelven a intentar si se produce un error en la conexión.
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
Estrategias de ejecución y transacciones explícitas mediante BeginTransaction y varios DbContexts
Cuando se habilitan los reintentos en las conexiones de EF Core, cada operación que se realiza mediante EF Core se convierte en su propia operación que se puede reintentar. Cada consulta y cada llamada a SaveChangesAsync se reintentará como una unidad si se produce un error transitorio.
Pero si el código inicia una transacción con BeginTransaction, va a definir un grupo de operaciones propio que se deben tratar como una unidad; todo dentro de la transacción se debe revertir si se produce un error. Verá una excepción similar a la siguiente si intenta ejecutar esa transacción cuando se usa una estrategia de ejecución de EF (directiva de reintentos) y se incluyen varias llamadas a SaveChangesAsync desde varios elementos DbContext en la transacción.
System.InvalidOperationException: la estrategia de ejecución configurada SqlServerRetryingExecutionStrategy no es compatible con las transacciones iniciadas por el usuario. Use la estrategia de ejecución que devuelve DbContext.Database.CreateExecutionStrategy() para ejecutar todas las operaciones en la transacción como una unidad que se puede reintentar.
La solución consiste en invocar manualmente la estrategia de ejecución de EF con un delegado que representa a todos los elementos que se deben ejecutar. Si se produce un error transitorio, la estrategia de ejecución vuelve a invocar al delegado. En el código siguiente se muestra cómo implementar este enfoque:
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
El primer elemento DbContext es _catalogContext y el segundo elemento DbContext está dentro del objeto _integrationEventLogService. Por último, la acción Commit se realizará en varios DbContext mediante una estrategia de ejecución de EF.
Referencias: Entity Framework Core
- Documentación de EF Corehttps://learn.microsoft.com/ef/
- EF Core: datos relacionadoshttps://learn.microsoft.com/ef/core/querying/related-data
- Evitar la carga diferida de entidades en aplicaciones ASP.NEThttps://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications
¿EF Core o micro-ORM?
Aunque EF Core es una opción excelente para administrar la persistencia, y en su mayor parte encapsula los detalles de base de datos de los desarrolladores de aplicaciones, no es la única opción. Otra alternativa de código abierto popular es Dapper, lo que se denomina un micro-ORM. Un micro-ORM es una herramienta ligera y menos completa para la asignación de objetos a estructuras de datos. En el caso de Dapper, sus objetivos de diseño se centran en el rendimiento, en lugar de encapsular totalmente las consultas subyacentes que usa para recuperar y actualizar los datos. Como no abstrae SQL del desarrollador, Dapper es "más cercano al sistema operativo" y permite a los desarrolladores escribir las consultas exactas que quieren usar para una operación de acceso a datos determinada.
EF Core proporciona dos características importantes que lo diferencian de Dapper, pero que también se agregan a su sobrecarga de rendimiento. La primera es la traducción de expresiones LINQ a SQL. Estas traducciones se almacenan en caché, pero aun así hay sobrecarga la primera vez que se realizan. La segunda es el seguimiento de los cambios en las entidades (para poder generar instrucciones de actualización eficaces). Este comportamiento se puede desactivar para consultas específicas mediante la extensión AsNoTracking. EF Core también genera consultas SQL que suelen ser muy eficaces y en cualquier caso perfectamente aceptables desde la perspectiva del rendimiento, pero si se necesita un control preciso sobre la consulta específica que se va a ejecutar, también se puede pasar código SQL personalizado (o ejecutar un procedimiento almacenado) con EF Core. En este caso, Dapper también supera a EF Core, pero solo muy ligeramente. En el sitio de Dapper se pueden encontrar datos de pruebas comparativas de rendimiento actuales para una amplia variedad de métodos de acceso a datos.
Para ver cómo varía la sintaxis de Dapper con respecto a EF Core, tenga en cuenta estas dos versiones del mismo método para recuperar una lista de elementos:
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
Si tiene que generar gráficos de objetos más complejos con Dapper, tendrá que escribir personalmente las consultas asociadas (en lugar de agregar un archivo de inclusión como haría en EF Core). Esta función se admite por medio de diversas sintaxis, incluida una característica denominada Asignación múltiple, que permite asignar filas individuales a varios objetos asignados. Por ejemplo, dada una clase Post con una propiedad Owner de tipo User, el código SQL siguiente devolvería todos los datos necesarios:
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
Cada fila devuelta incluye los datos de User y Post. Como los datos de User se deben asociar a los datos de Post a través de su propiedad Owner, se usa la función siguiente:
(post, user) => { post.Owner = user; return post; }
La lista de código completa para devolver una colección de entradas con su propiedad Owner rellenada con los datos de usuario asociados sería esta:
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
Como ofrece menos encapsulación, Dapper requiere que los desarrolladores tengan más información sobre cómo se almacenan los datos, cómo consultarlos de forma eficaz y escribir más código para recuperarlos. Cuando el modelo cambia, en lugar de crear simplemente una migración (otra característica de EF Core) o actualizar la información de asignación en una posición en un DbContext, se deben actualizar todas las consultas que se van a ver afectadas. Estas consultas no tienen garantías en tiempo de compilación, por lo que se pueden interrumpir en tiempo de ejecución en respuesta a cambios en el modelo o la base de datos, lo que dificulta más la detección rápida de los errores. A cambio de estos inconvenientes, Dapper ofrece un rendimiento extremadamente rápido.
Para la mayoría de las aplicaciones y la mayoría de los elementos de casi todas las aplicaciones, EF Core ofrece un rendimiento aceptable. Por tanto, sus ventajas de productividad para los desarrolladores suelen superar su sobrecarga de rendimiento. Para las consultas que se pueden beneficiar del almacenamiento en caché, es posible que solo se pueda ejecutar la consulta real en un pequeño porcentaje de los casos, lo que hace que las diferencias de rendimiento de las consultas de pequeño tamaño sean irrelevantes.
SQL o NoSQL
Tradicionalmente, las bases de datos relacionales como SQL Server han dominado el mercado del almacenamiento de datos persistentes, pero no son la única solución disponible. Las bases de datos NoSQL como MongoDB ofrecen un enfoque diferente para el almacenamiento de objetos. En lugar de asignar objetos a tablas y filas, otra opción consiste en serializar el gráfico de objetos completo y almacenar el resultado. Las ventajas de este enfoque, al menos inicialmente, son la simplicidad y el rendimiento. Es más simple almacenar un único objeto serializado con una clave que descomponerlo en muchas tablas con relaciones, actualizaciones y filas que pueden haber cambiado desde la última vez que se recuperó el objeto de la base de datos. Del mismo modo, la recuperación y deserialización de un único objeto de un almacén basado en claves suele ser mucho más rápida y sencilla que combinaciones complejas o varias consultas de base de datos necesarias para crear completamente el mismo objeto de una base de datos relacional. La falta de bloqueos o transacciones, o de un esquema fijo, también hace que las bases de datos NoSQL sean sensibles al escalado entre varios equipos, admitiendo grandes conjuntos de datos.
Por otro lado, las bases de datos NoSQL (como normalmente se denominan) tienen sus desventajas. Las bases de datos relacionales usan la normalización para aplicar la coherencia y evitar la duplicación de datos. Este enfoque reduce el tamaño total de la base de datos y garantiza que las actualizaciones de los datos compartidos estén disponibles inmediatamente en toda la base de datos. En una base de datos relacional, es posible que una tabla de direcciones haga referencia a una tabla de país por el id., de forma que, si se cambiara el nombre de un país o región, los registros de direcciones se beneficiarían de la actualización sin tener que actualizarlos. Pero, en una base de datos NoSQL, es posible que la dirección y su región o país asociado se serialicen como parte de muchos objetos almacenados. Una actualización en un nombre de país o región requeriría actualizar todos esos objetos, en lugar de una sola fila. Las bases de datos relacionales también pueden asegurar la integridad relacional mediante la aplicación de reglas como claves externas. Normalmente, las bases de datos NoSQL no ofrecen estas restricciones en sus datos.
Otra complejidad que las bases de datos NoSQL deben superar es el control de versiones. Cuando cambian las propiedades de un objeto, es posible que no se pueda deserializar de las versiones anteriores que se almacenaron. Por tanto, todos los objetos existentes que tengan una versión serializada (anterior) del objeto tendrán que actualizarse para que se ajusten a su esquema nuevo. Conceptualmente, este enfoque no es diferente a una base de datos relacional, en la que los cambios del esquema a veces requieren scripts de actualización o asignación de actualizaciones. Pero el número de entradas que se deben modificar suele ser mucho mayor en el enfoque de NoSQL, porque hay más duplicación de los datos.
En las bases de datos NoSQL se pueden almacenar varias versiones de los objetos, algo que las bases de datos relacionales de esquema fijo normalmente no admiten. Pero, en este caso, el código de la aplicación deberá tener en cuenta la existencia de versiones anteriores de los objetos, lo que agrega complejidad adicional.
Las bases de datos NoSQL normalmente no aplican ACID, lo que significa que tienen ventajas de rendimiento y escalabilidad con respecto a las bases de datos relacionales. Son adecuadas para conjuntos de datos y objetos muy grandes que no son adecuados para el almacenamiento en estructuras de tabla normalizadas. No hay ninguna razón para que una aplicación no pueda aprovechar las ventajas de las bases de datos relacionales y NoSQL, y usar cada una cuando sea más adecuado.
Azure Cosmos DB (la base de datos de Azure Cosmos)
Azure Cosmos DB es un servicio de base de datos NoSQL completamente administrado que ofrece almacenamiento de datos sin esquema basado en la nube. Azure Cosmos DB se ha creado para rendimiento rápido y predecible, alta disponibilidad, escalado elástico y distribución global. A pesar de ser una base de datos NoSQL, los desarrolladores pueden usar funciones de consulta SQL enriquecidas y conocidas en los datos JSON. Todos los recursos de Azure Cosmos DB se almacenan como documentos JSON. Los recursos se administran como elementos, que son documentos que contienen metadatos, y fuentes, que son colecciones de elementos. En la figura 8-2 se muestra la relación entre los diferentes recursos de Azure Cosmos DB.
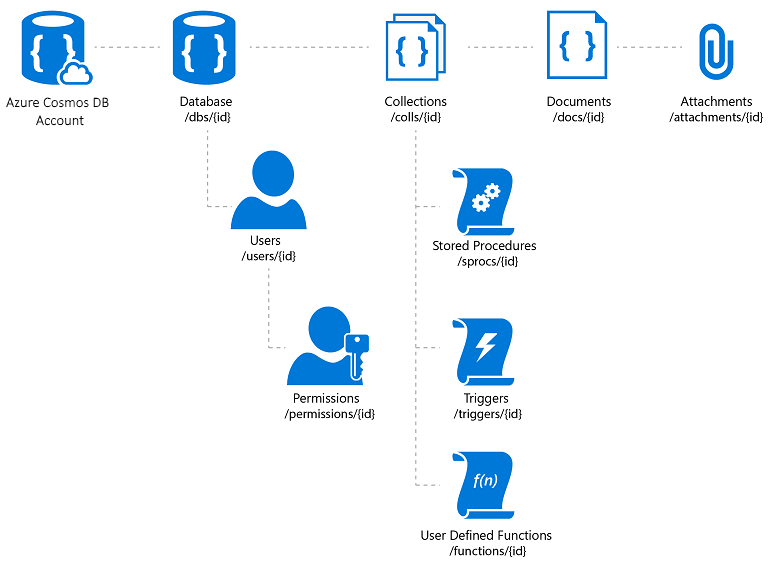
Figura 8-2. Organización de recursos de Azure Cosmos DB.
El lenguaje de consulta de Azure Cosmos DB es una interfaz sencilla, pero eficaz, para consultar documentos JSON. El lenguaje admite un subconjunto de la gramática SQL ANSI y agrega integración profunda de matrices de objetos JavaScript, construcción de objetos e invocación de funciones.
Referencias: Azure Cosmos DB
- Introducción a Azure Cosmos DBhttps://learn.microsoft.com/azure/cosmos-db/introduction
Otras opciones de persistencia
Además de las opciones de almacenamiento relacionales y NoSQL, las aplicaciones ASP.NET Core pueden usar Azure Storage para almacenar varios formatos de datos y archivos de forma escalable y basada en la nube. Azure Storage es escalable de forma masiva, para que pueda empezar a almacenar pequeñas cantidades de datos y escalar verticalmente hasta almacenar cientos o terabytes si así lo requiere la aplicación. Azure Storage admite cuatro tipos de datos:
Blob Storage para almacenamiento de texto binario no estructurado, que también se denomina almacenamiento de objetos.
Table Storage para conjuntos de datos estructurados, accesible a través de claves de fila.
Queue Storage para la mensajería confiable basada en colas.
File Storage para el acceso a archivos compartido entre máquinas virtuales de Azure y aplicaciones locales.
Referencias: Azure Storage
- Introducción a Azure Storagehttps://learn.microsoft.com/azure/storage/common/storage-introduction
Almacenamiento en memoria caché
En las aplicaciones web, cada solicitud web se debe completar en el menor tiempo posible. Una manera de lograr esta función consiste en limitar el número de llamadas externas que el servidor debe realizar para completar la solicitud. El almacenamiento en caché implica almacenar una copia de los datos en el servidor (u otro almacén de datos que sea más fácil de consultar que el origen de los datos). Las aplicaciones web y especialmente las aplicaciones web tradicionales que no son de SPA, necesitan generar la interfaz de usuario completa con cada solicitud. Con frecuencia, este enfoque implica realizar muchas de las mismas consultas de base de datos varias veces de una solicitud de usuario a la siguiente. En la mayoría de los casos, estos datos apenas cambian, de modo que no hay motivos para solicitarlos constantemente de la base de datos. ASP.NET Core admite el almacenamiento de respuestas en caché, para almacenar en caché páginas completas y el almacenamiento de datos en caché, que admite un comportamiento de almacenamiento en caché más granular.
Al implementar el almacenamiento en caché, es importante tener en cuenta la separación de intereses. Evite implementar la lógica de almacenamiento en caché en la lógica de acceso a datos o en la interfaz de usuario. En su lugar, encapsule el almacenamiento en caché en sus propias clases y use la configuración para administrar su comportamiento. Este enfoque sigue los principios de Abierto o cerrado y Responsabilidad única, y facilitará la administración del uso del almacenamiento en caché en la aplicación a medida que crezca.
Almacenamiento en caché de respuestas de ASP.NET Core
ASP.NET Core admite dos niveles de almacenamiento en caché de respuestas. El primer nivel no almacena en caché nada en el servidor, pero agrega encabezados HTTP que indican a los clientes y servidores proxy que almacenen las respuestas en caché. Esta función se implementa mediante la incorporación del atributo ResponseCache a controladores o acciones individuales:
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
Como resultado del ejemplo anterior, el encabezado siguiente se agrega a la respuesta, indicando a los clientes que almacenen el resultado en caché hasta 60 segundos.
Cache-Control: public,max-age=60
Con el fin de agregar almacenamiento en caché en memoria del lado servidor a la aplicación, debe hacer referencia al paquete NuGet Microsoft.AspNetCore.ResponseCaching y, después, agregar el middleware de almacenamiento en caché de las respuestas. Este middleware se configura con servicios y middleware durante el inicio de la aplicación:
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
El software intermedio de almacenamiento de las respuestas en caché almacenará automáticamente las respuestas en caché en función de un conjunto de condiciones que se pueden personalizar. De forma predeterminada, solo se almacenan en caché las respuestas 200 (OK) solicitadas a través de métodos GET o HEAD. Además, las solicitudes deben tener una respuesta con un encabezado público Cache-Control: y no pueden incluir encabezados Authorization o Set-Cookie. Vea una lista completa de las condiciones de almacenamiento en caché que usa el software intermedio de almacenamiento en caché de las respuestas.
Almacenamiento de datos en caché
En lugar (o además de) almacenar en caché las respuestas web completas, se pueden almacenar en caché los resultados de consultas de datos individuales. Para esta función, se puede usar el almacenamiento en caché en memoria en el servidor web o una caché distribuida. En esta sección se muestra cómo implementar el almacenamiento en caché en memoria.
Agregue compatibilidad para el almacenamiento en caché en memoria (o distribuido) con el código siguiente:
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Asegúrese de agregar también el paquete NuGet Microsoft.Extensions.Caching.Memory.
Una vez agregado el servicio, se solicita IMemoryCache a través de la inserción de dependencias siempre que haya que obtener acceso a la caché. En este ejemplo, CachedCatalogService usa el patrón de diseño de Proxy, o Decorator, proporcionando una implementación alternativa de ICatalogService que controla el acceso a la implementación de CatalogService subyacente, o bien le agrega comportamiento.
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
Para configurar la aplicación para usar la versión en caché del servicio, pero seguir permitiendo que el servicio obtenga la instancia de CatalogService que necesita en su constructor, se deben agregar las líneas siguientes en Program.cs:
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
Después de agregar este código, las llamadas de base de datos para recuperar los cambios de los datos del catálogo solo se realizarán una vez por minuto, en lugar de en cada solicitud. Según el tráfico al sitio, esto puede tener un impacto significativo en el número de consultas realizadas a la base de datos y el tiempo medio de carga de la página principal que depende actualmente de las tres consultas expuestas por este servicio.
Un problema que surge cuando se implementa el almacenamiento en caché es el de los datos obsoletos, es decir, datos que han cambiado en el origen, pero de los que permanece en caché una versión obsoleta. Una manera sencilla de mitigar esta incidencia consiste en usar duraciones de caché pequeñas, ya que, para una aplicación ocupada, la ventaja adicional de extender la longitud de los datos en caché es limitada. Por ejemplo, considere una página que realiza una única consulta de base de datos y se solicita 10 veces por segundo. Si esta página se almacena en caché durante un minuto, el número de consultas de base de datos realizadas por minuto descenderá 600 a 1, una reducción del 99,8 %. Si, en su lugar, la duración de la caché fuera de una hora, la reducción general sería del 99,997 %, pero ahora la probabilidad y la antigüedad posible de los datos obsoletos aumentan considerablemente.
Otro enfoque consiste en quitar proactivamente las entradas de caché cuando se actualizan los datos que contienen. Cualquier entrada individual se puede quitar si se conoce su clave:
_cache.Remove(cacheKey);
Si la aplicación expone funcionalidad para actualizar las entradas que almacena en caché, puede quitar las entradas de caché correspondientes en el código que realiza las actualizaciones. En ocasiones puede haber muchas otras entradas que dependen de un conjunto de datos determinado. En ese caso, puede ser útil crear dependencias entre las entradas de caché, mediante el uso de un CancellationChangeToken. Con un CancellationChangeToken se pueden expirar varias entradas de caché a la vez si se cancela el token.
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
El almacenamiento en caché puede mejorar considerablemente el rendimiento de las páginas web que solicitan repetidamente los mismos valores de la base de datos. Asegúrese de medir el acceso de datos y el rendimiento de la página antes de aplicar el almacenamiento en caché y aplíquelo solo donde vea una necesidad de mejora. El almacenamiento en caché consume recursos de memoria de servidor web y aumenta la complejidad de la aplicación, por lo que es importante que no optimice de forma prematura con esta técnica.
Obtención de datos para aplicaciones de BlazorWebAssembly
Si va a compilar aplicaciones que usan Blazor Server, puede usar Entity Framework y otras tecnologías de acceso directo a datos como se han analizado hasta ahora en este capítulo. Sin embargo, al compilar aplicaciones de BlazorWebAssembly, al igual que otros marcos de SPA, necesitará una estrategia diferente para acceder a los datos. Normalmente, estas aplicaciones acceden a los datos e interactúan con el servidor a través de puntos de conexión de API web.
Si los datos o las operaciones que se realizan son confidenciales, asegúrese de revisar la sección sobre seguridad del capítulo anterior y de proteger las API frente al acceso no autorizado.
Encontrará un ejemplo de una aplicación de BlazorWebAssembly en la aplicación de referencia eShopOnWeb en el proyecto BlazorAdmin. Este proyecto se hospeda dentro del proyecto web eShopOnWeb y permite a los usuarios del grupo de administradores administrar los elementos del almacén. Puede ver una captura de pantalla de la aplicación en la figura 8-3.
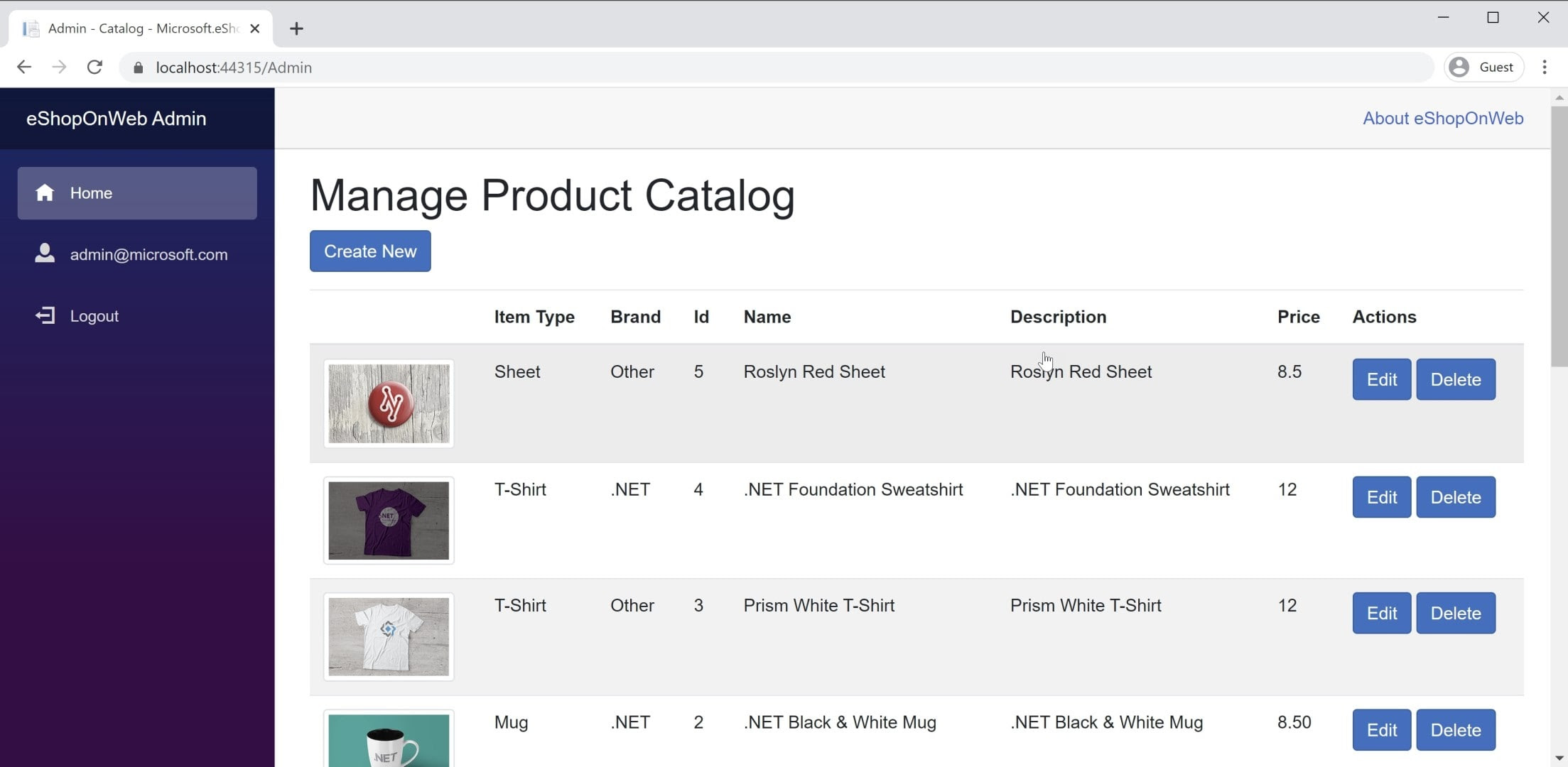
Figura 8-3. Captura de pantalla de administrador del catálogo de eShopOnWeb.
A la hora de obtener datos de las API web dentro de una aplicación de BlazorWebAssembly, simplemente use una instancia de HttpClient como haría en cualquier aplicación .NET. Los pasos básicos que hay que seguir son crear la solicitud de envío (si es necesario, normalmente para las solicitudes POST o PUT), esperar a que se realice la solicitud, comprobar el código de estado y deserializar la respuesta. Si va a hacer muchas solicitudes a un determinado conjunto de API, es aconsejable encapsular las API y configurar la dirección base de HttpClient de forma centralizada. De este modo, si necesita ajustar cualquiera de estas configuraciones en varios entornos, puede realizar los cambios en un solo lugar. Debe agregar compatibilidad con este servicio en Program.Main:
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
Si necesita acceder a los servicios de forma segura, acceda a un token seguro y configurar HttpClient para pasar este token como un encabezado de autenticación con cada solicitud:
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
Esta actividad se puede hacer en cualquier componente que tenga HttpClient insertado, siempre que HttpClient no se haya agregado a los servicios de la aplicación con una duración Transient. Todas las referencias a HttpClient en la aplicación hacen referencia a la misma instancia, por lo que los cambios en un componente se aplican en toda la aplicación. Un buen lugar para realizar esta comprobación de autenticación (y después, la especificación del token) es en un componente compartido, como la navegación principal del sitio. Obtenga más información sobre este enfoque en el proyecto BlazorAdmin en la aplicación de referencia eShopOnWeb.
Uno de los beneficios de BlazorWebAssembly frente a las SPA tradicionales de JavaScript es que no es necesario conservar sincronizadas las copias de los objetos de transferencia de datos (DTO). Su proyecto de BlazorWebAssembly y de API web pueden compartir el mismo objeto de transferencia de datos en un proyecto común compartido. Este enfoque elimina parte de la fricción que conlleva el desarrollo de aplicaciones de página única.
Para obtener datos rápidamente de un punto de conexión de API, puede usar el método auxiliar integrado GetFromJsonAsync. Hay métodos similares para POST, PUT, etc. A continuación, se muestra cómo obtener una clase CatalogItem de un punto de conexión de API mediante un elemento HttpClient configurado en una aplicación de BlazorWebAssembly:
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
Una vez que tenga los datos que necesita, normalmente hará un seguimiento de los cambios de forma local. Para realizar actualizaciones en el almacén de datos de back-end, llamará a API web adicionales.
Referencias: datos de Blazor
- Llamada a una API web desde Blazorhttps://learn.microsoft.com/aspnet/core/blazor/call-web-api de ASP.NET Core
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.