Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Obtenga información sobre cómo entrenar un modelo de aprendizaje profundo personalizado mediante el aprendizaje de transferencia, un modelo tensorFlow previamente entrenado y la API de clasificación de imágenes de ML.NET para clasificar imágenes de superficies concretas como agrietadas o sin procesar.
En este tutorial, aprenderá a:
- Comprender el problema
- Más información sobre ML.NET Image Classification API
- Comprender el modelo entrenado previamente
- Uso del aprendizaje de transferencia para entrenar un modelo personalizado de clasificación de imágenes de TensorFlow
- Clasificación de imágenes con el modelo personalizado
Prerrequisitos
Comprender el problema
La clasificación de imágenes es un problema de Computer Vision. La clasificación de imágenes toma una imagen como entrada y la clasifica en una clase prescrita. Los modelos de clasificación de imágenes suelen entrenarse mediante el aprendizaje profundo y las redes neuronales. Para más información, consulte Aprendizaje profundo frente al aprendizaje automático.
Algunos escenarios en los que la clasificación de imágenes es útil son:
- Reconocimiento facial
- Detección de emociones
- Diagnóstico médico
- Detección de puntos de referencia
En este tutorial se entrena un modelo de clasificación de imágenes personalizado para realizar una inspección visual automatizada de cubiertas de puente para identificar estructuras dañadas por grietas.
API de clasificación de imágenes de ML.NET
ML.NET proporciona varias maneras de realizar la clasificación de imágenes. En este tutorial se aplica el aprendizaje de transferencia mediante Image Classification API. Image Classification API usa TensorFlow.NET, una biblioteca de bajo nivel que proporciona enlaces de C# para la API de C++ de TensorFlow.
¿Qué es el aprendizaje de transferencia?
El aprendizaje de transferencia aplica conocimientos adquiridos de resolver un problema a otro problema relacionado.
El entrenamiento de un modelo de aprendizaje profundo desde cero requiere establecer varios parámetros, una gran cantidad de datos de entrenamiento etiquetados y una gran cantidad de recursos de proceso (cientos de horas de GPU). El uso de un modelo preentrenado junto con el aprendizaje por transferencia le permite acortar el proceso de entrenamiento.
Proceso de entrenamiento
Image Classification API inicia el proceso de entrenamiento cargando un modelo tensorFlow previamente entrenado. El proceso de entrenamiento consta de dos pasos:
- Fase de cuello de botella.
- Fase de entrenamiento.
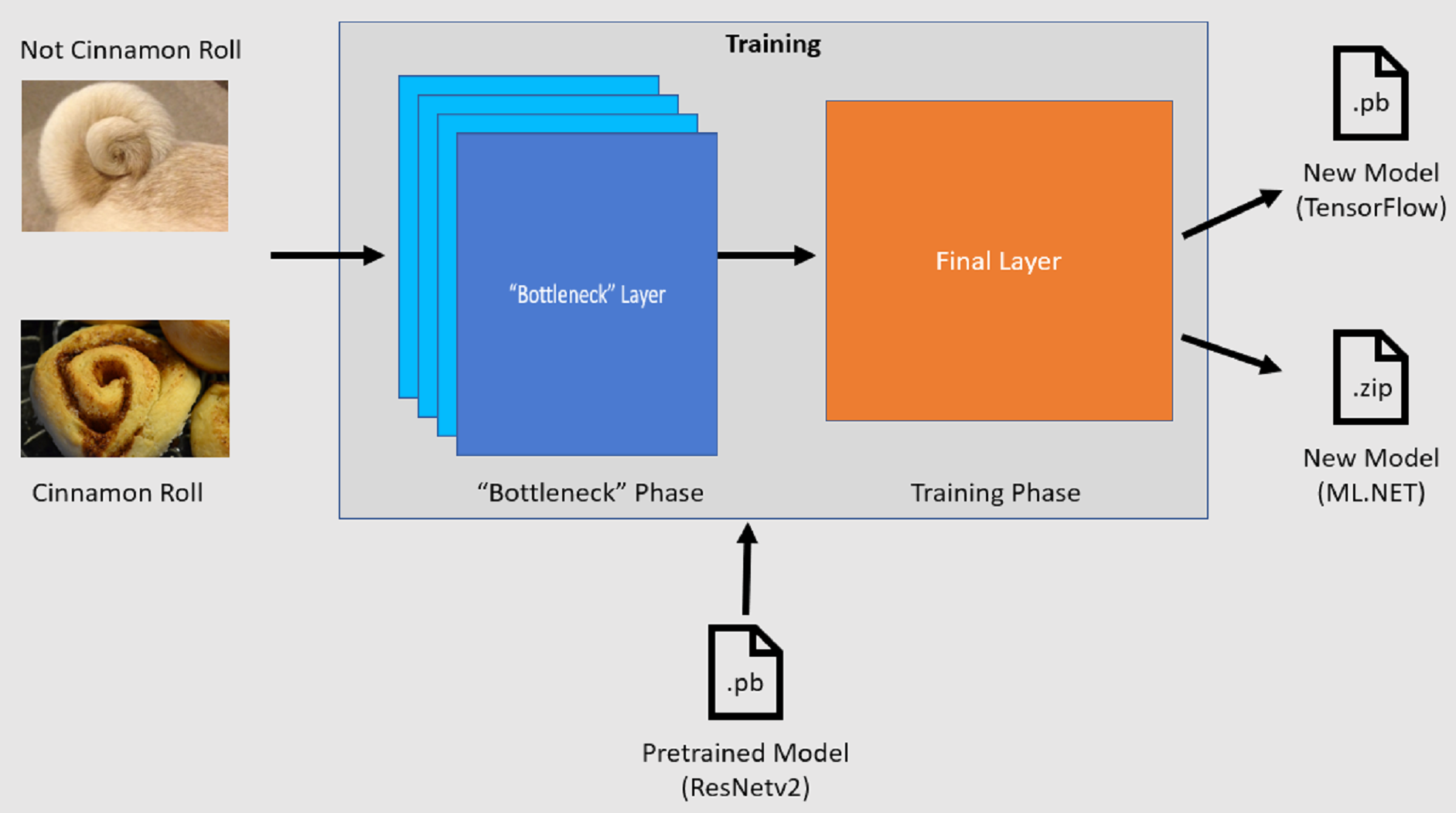
Fase de cuello de botella
Durante la fase de cuello de botella, se carga el conjunto de imágenes de entrenamiento y los valores de píxel se usan como entrada, o características, para las capas congeladas del modelo preentrenado. Las capas inmovilizadas incluyen todas las capas de la red neuronal hasta la penúltima capa, conocida informalmente como capa de cuello de botella. Estas capas se conocen como congeladas porque no se producirá ningún entrenamiento en estas capas y que las operaciones se pasan a través. Se encuentra en estas capas inmovilizadas donde se calculan los patrones de nivel inferior que ayudan a un modelo a diferenciar entre las distintas clases. Cuanto mayor sea el número de capas, más intensivo de cálculo es este paso. Afortunadamente, dado que se trata de un cálculo único, los resultados se pueden almacenar en caché y usarse en ejecuciones posteriores al experimentar con parámetros diferentes.
Fase de entrenamiento
Una vez calculados los valores de salida de la fase de cuello de botella, se usan como entrada para volver a entrenar la capa final del modelo. Este proceso es iterativo y se ejecuta para el número de veces que especifican los parámetros del modelo. Durante cada ejecución, se evalúa la pérdida y la precisión. A continuación, se realizan los ajustes adecuados para mejorar el modelo con el objetivo de minimizar la pérdida y maximizar la precisión. Una vez finalizado el entrenamiento, se generan dos formatos de modelo. Una de ellas es la .pb versión del modelo y la otra es la .zip ML.NET versión serializada del modelo. Cuando se trabaja en entornos admitidos por ML.NET, se recomienda usar la .zip versión del modelo. Sin embargo, en entornos en los que no se admite ML.NET, tiene la opción de usar la .pb versión.
Comprender el modelo entrenado previamente
El modelo entrenado previamente usado en este tutorial es la variante de capa 101 del modelo de red residual (ResNet) v2. El modelo original se entrena para clasificar imágenes en mil categorías. El modelo toma como entrada una imagen de tamaño 224 x 224 y genera las probabilidades de clase para cada una de las clases en las que se entrena. Parte de este modelo se usa para entrenar un nuevo modelo mediante imágenes personalizadas para realizar predicciones entre dos clases.
Creación de una aplicación de consola
Ahora que tiene conocimientos generales sobre el aprendizaje de transferencia y la API de clasificación de imágenes, es el momento de compilar la aplicación.
Cree una aplicación de consola de C# denominada "DeepLearning_ImageClassification_Binary". Haga clic en el botón Siguiente .
Elija .NET 8 como marco que se va a usar y, a continuación, seleccione Crear.
Instale el paquete NuGet de Microsoft.ML :
Nota:
En este ejemplo se usa la versión estable más reciente de los paquetes NuGet mencionados a menos que se indique lo contrario.
- En el Explorador de soluciones, haga clic con el botón derecho en el proyecto y seleccione Administrar paquetes NuGet.
- Elija "nuget.org" como origen del paquete.
- Seleccione la pestaña Examinar.
- Active la casilla Incluir versión preliminar .
- Busque Microsoft.ML.
- Seleccione el botón Instalar .
- Seleccione el botón Acepto en el cuadro de diálogo Aceptación de licencia si está de acuerdo con los términos de licencia de los paquetes enumerados.
- Repita estos pasos para los paquetes NuGet Microsoft.ML.Vision, SciSharp.TensorFlow.Redist (versión 2.3.1) y Microsoft.ML.ImageAnalytics .
Preparación y comprensión de los datos
Nota:
Los conjuntos de datos de este tutorial proceden de Maguire, Marc; Dorafshan, Sattar; y Thomas, Robert J., "SDNET2018: un conjunto de datos de imagen de grieta concreto para aplicaciones de aprendizaje automático" (2018). Examine todos los conjuntos de datos. Documento 48. https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 es un conjunto de datos de imágenes que contiene anotaciones para estructuras de hormigón agrietadas y no agrietadas (cubiertas de puentes, paredes y pavimento).

Los datos se organizan en tres subdirectorios:
- D contiene imágenes de baraja de puente
- P contiene imágenes de pavimento
- W contiene imágenes de muros
Cada uno de estos subdirectorios contiene dos subdirectorios con prefijo adicionales:
- C es el prefijo usado para superficies agrietadas.
- U es el prefijo usado para superficies sin aplicar
En este tutorial, solo se usan imágenes del tablero del puente.
- Descargue el conjunto de datos y descomprima.
- Cree un directorio denominado "Assets" en el proyecto para guardar los archivos del conjunto de datos.
- Copie los subdirectorios CD y UD del directorio descomprimido recientemente en el directorio Assets .
Creación de clases de entrada y salida
Abra el archivo Program.cs y reemplace el contenido existente por las siguientes
usingdirectivas:using Microsoft.ML; using Microsoft.ML.Vision; using static Microsoft.ML.DataOperationsCatalog;Cree una clase denominada
ImageData. Esta clase se usa para representar los datos cargados inicialmente.class ImageData { public string? ImagePath { get; set; } public string? Label { get; set; } }ImageDatacontiene las siguientes propiedades:-
ImagePathes la ruta completa donde se almacena la imagen. -
Labeles la categoría a la que pertenece la imagen. Este es el valor que se va a predecir.
-
Cree clases para los datos de entrada y salida.
Debajo de la
ImageDataclase , defina el esquema de los datos de entrada en una nueva clase denominadaModelInput.class ModelInput { public byte[]? Image { get; set; } public uint LabelAsKey { get; set; } public string? ImagePath { get; set; } public string? Label { get; set; } }ModelInputcontiene las siguientes propiedades:-
Imagees labyte[]representación de la imagen. El modelo espera que los datos de imagen sean de este tipo para el entrenamiento. -
LabelAsKeyes la representación numérica deLabel. -
ImagePathes la ruta de acceso completa donde se almacena la imagen. -
Labeles la categoría a la que pertenece la imagen. Este es el valor que se va a predecir.
Solo
ImageyLabelAsKeyse usan para entrenar el modelo y realizar predicciones. LasImagePathpropiedades yLabelse conservan para mayor comodidad para tener acceso al nombre y la categoría del archivo de imagen original.-
A continuación, debajo de la
ModelInputclase , defina el esquema de los datos de salida en una nueva clase denominadaModelOutput.class ModelOutput { public string? ImagePath { get; set; } public string? Label { get; set; } public string? PredictedLabel { get; set; } }ModelOutputcontiene las siguientes propiedades:-
ImagePathes la ruta de acceso completa donde se almacena la imagen. -
Labeles la categoría original a la que pertenece la imagen. Este es el valor que se va a predecir. -
PredictedLabeles el valor previsto por el modelo.
De forma similar a
ModelInput, soloPredictedLabeles necesario realizar predicciones, ya que contiene la predicción realizada por el modelo. LasImagePathpropiedades yLabelse conservan para mayor comodidad para tener acceso al nombre y la categoría del archivo de imagen original.-
Definición de rutas de acceso e inicialización de variables
En las
usingdirectivas , agregue el código siguiente a:Defina la ubicación de los recursos.
Inicialice la
mlContextvariable con una nueva instancia de MLContext.La clase MLContext es un punto de partida para todas las operaciones de ML.NET e inicializar mlContext crea un nuevo entorno de ML.NET que se puede compartir entre los objetos de flujo de trabajo de creación de modelos. Es similar, conceptualmente, a
DbContexten Entity Framework.
var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var assetsRelativePath = Path.Combine(projectDirectory, "Assets"); MLContext mlContext = new();
Carga de los datos
Crear método de utilidad de carga de datos
Las imágenes se almacenan en dos subdirectorios. Antes de cargar los datos, estos necesitan ser formateados como una lista de objetos ImageData. Para ello, cree el LoadImagesFromDirectory método :
static IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
var files = Directory.GetFiles(folder, "*",
searchOption: SearchOption.AllDirectories);
foreach (var file in files)
{
if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png"))
continue;
var label = Path.GetFileName(file);
if (useFolderNameAsLabel)
label = Directory.GetParent(file)?.Name;
else
{
for (int index = 0; index < label.Length; index++)
{
if (!char.IsLetter(label[index]))
{
label = label[..index];
break;
}
}
}
yield return new ImageData()
{
ImagePath = file,
Label = label
};
}
}
El método LoadImagesFromDirectory realiza las acciones siguientes:
- Obtiene todas las rutas de acceso de los archivos de los subdirectorios.
- Recorre en iteración cada uno de los archivos mediante una
foreachinstrucción y comprueba que se admiten las extensiones de archivo. Image Classification API admite formatos JPEG y PNG. - Obtiene la etiqueta del archivo. Si el parámetro
useFolderNameAsLabelse establece entrue, el directorio padre donde se guarda el archivo se usa como etiqueta. De lo contrario, espera que la etiqueta sea un prefijo del nombre de archivo o del propio nombre de archivo. - Crea una nueva instancia de
ModelInput.
Preparación de los datos
Agregue el código siguiente después de la línea donde cree la nueva instancia de MLContext.
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);
IDataView imageData = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(
inputColumnName: "Label",
outputColumnName: "LabelAsKey")
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: assetsRelativePath,
inputColumnName: "ImagePath"));
IDataView preProcessedData = preprocessingPipeline
.Fit(shuffledData)
.Transform(shuffledData);
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3);
TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);
IDataView trainSet = trainSplit.TrainSet;
IDataView validationSet = validationTestSplit.TrainSet;
IDataView testSet = validationTestSplit.TestSet;
El código anterior:
Llama al
LoadImagesFromDirectorymétodo de utilidad para obtener la lista de imágenes usadas para el entrenamiento después de inicializar lamlContextvariable.Carga las imágenes en un
IDataViewutilizando el métodoLoadFromEnumerable.Baraja los datos mediante el método
ShuffleRows. Los datos se cargan en el orden en que se leyeron de los directorios. El orden aleatorio se realiza para equilibrarlo.Realiza algún preprocesamiento en los datos antes del entrenamiento. Esto se hace porque los modelos de aprendizaje automático esperan que la entrada esté en formato numérico. El código de preprocesamiento crea un
EstimatorChaincompuesto por las transformaciones deMapValueToKeyyLoadRawImageBytes. LaMapValueToKeytransformación toma el valor de categoría en laLabelcolumna, lo convierte en un valor numéricoKeyTypey lo almacena en una nueva columna denominadaLabelAsKey.LoadImagestoma los valores de laImagePathcolumna junto con elimageFolderparámetro para cargar imágenes para el entrenamiento.Usa el
Fitmétodo para aplicar los datos alpreprocessingPipelineEstimatorChainseguido delTransformmétodo , que devuelve unIDataViewobjeto que contiene los datos preprocesados.Divide los datos en conjuntos de entrenamiento, validación y pruebas.
Para entrenar un modelo, es importante tener un conjunto de datos de entrenamiento, así como un conjunto de datos de validación. El modelo se entrena en el conjunto de entrenamiento. La forma en que realiza predicciones sobre datos no vistos se mide mediante el rendimiento en el conjunto de validación. En función de los resultados de ese rendimiento, el modelo realiza ajustes en lo que ha aprendido en un esfuerzo por mejorar. El conjunto de validación puede proceder de fragmentar el conjunto de datos original o de otro recurso ya reservado para este propósito.
El ejemplo de código realiza dos divisiones. En primer lugar, los datos preprocesados se dividen y se usan 70% para el entrenamiento, mientras que los 30% restantes se usan para la validación. A continuación, el conjunto de validación de 30% se divide aún más en conjuntos de validación y pruebas donde se usan 90% para la validación y se usan 10% para las pruebas.
Una manera de pensar en el propósito de estas particiones de datos es realizar un examen. Al estudiar para un examen, revise sus notas, libros u otros recursos para comprender los conceptos que se encuentran en el examen. Esto es para lo que sirve el tren. Después, puede realizar un examen ficticio para validar sus conocimientos. Aquí es donde el conjunto de validación resulta útil. Quiere comprobar si tiene una buena comprensión de los conceptos antes de realizar el examen real. En función de esos resultados, tomas nota de lo que te has equivocado o no has entendido bien e incorporas los cambios a medida que te preparas para el examen real. Finalmente, tú tomas el examen. Esto es lo que se usa el conjunto de pruebas para. Nunca has visto las preguntas que se encuentran en el examen y ahora usas lo que has aprendido del entrenamiento y la validación para aplicar tus conocimientos a la tarea en cuestión.
Asigna las particiones a sus respectivos valores para los datos de entrenamiento, validación y prueba.
Definir la canalización de entrenamiento
El entrenamiento del modelo consta de dos pasos. En primer lugar, image Classification API se usa para entrenar el modelo. A continuación, las etiquetas codificadas de la PredictedLabel columna se convierten de nuevo en su valor de categoría original mediante la MapKeyToValue transformación.
var classifierOptions = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
ValidationSet = validationSet,
Arch = ImageClassificationTrainer.Architecture.ResnetV2101,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
TestOnTrainSet = false,
ReuseTrainSetBottleneckCachedValues = true,
ReuseValidationSetBottleneckCachedValues = true
};
var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainSet);
El código anterior:
Crea una nueva variable para almacenar un conjunto de parámetros obligatorios y opcionales para .ImageClassificationTrainer Un ImageClassificationTrainer toma varios parámetros opcionales:
-
FeatureColumnNamees la columna que se usa como entrada para el modelo. -
LabelColumnNamees la columna del valor que se va a predecir. -
ValidationSetes elIDataViewque contiene los datos de validación. -
Archdefine cuál de las arquitecturas de modelo previamente entrenadas que se van a usar. En este tutorial se usa la variante de capa 101 del modelo ResNetv2. -
MetricsCallbackenlaza una función para realizar un seguimiento del progreso durante el entrenamiento. -
TestOnTrainSetindica al modelo que mida el rendimiento en el conjunto de entrenamiento cuando no haya ningún conjunto de validación presente. -
ReuseTrainSetBottleneckCachedValuesindica al modelo si se deben usar los valores almacenados en caché de la fase de cuello de botella en ejecuciones posteriores. La fase de cuello de botella es un cálculo de paso a través único que consume mucho cálculo la primera vez que se realiza. Si los datos de entrenamiento no cambian y desea experimentar con un número diferente de épocas o tamaño de lote, el uso de los valores almacenados en caché reduce significativamente la cantidad de tiempo necesario para entrenar un modelo. -
ReuseValidationSetBottleneckCachedValueses similar aReuseTrainSetBottleneckCachedValuessolo que, en este caso, es para el conjunto de datos de validación.
-
Define la
EstimatorChaincanalización de entrenamiento que consta de ymapLabelEstimator.ImageClassificationTrainerUsa el
Fitmétodo para entrenar el modelo.
Uso del modelo
Ahora que ha entrenado el modelo, es el momento de usarlo para clasificar imágenes.
Cree un nuevo método de utilidad llamado OutputPrediction para mostrar información de predicción en la consola.
static void OutputPrediction(ModelOutput prediction)
{
string? imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
Clasificación de una sola imagen
Cree un método llamado
ClassifySingleImagepara realizar y generar una única predicción de imagen.static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); }El método
ClassifySingleImagerealiza las acciones siguientes:- Crea un
PredictionEngineelemento dentro delClassifySingleImagemétodo .PredictionEnginees una API útil que le permite pasar y, a continuación, realizar una predicción en una sola instancia de datos. - Para tener acceso a una sola
ModelInputinstancia, convierte endataIDataViewunIEnumerablemediante elCreateEnumerablemétodo y, a continuación, obtiene la primera observación. - Usa el
Predictmétodo para clasificar la imagen. - Muestra la predicción en la consola con el método
OutputPrediction.
- Crea un
Llame a
ClassifySingleImagedespués de llamar al métodoFitutilizando el conjunto de imágenes de prueba.ClassifySingleImage(mlContext, testSet, trainedModel);
Clasificación de varias imágenes
Cree un método llamado
ClassifyImagespara realizar y generar varias predicciones de imagen.static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } }El método
ClassifyImagesrealiza las acciones siguientes:- Crea un
IDataViewobjeto que contiene las predicciones mediante elTransformmétodo . - Para iterar sobre las predicciones, convierte el
predictionDataIDataViewen unIEnumerableusando el métodoCreateEnumerabley, a continuación, obtiene las primeras 10 observaciones. - Itera y genera las etiquetas originales y predichas para las predicciones.
- Crea un
Llame a
ClassifyImagesdespués de llamar al métodoClassifySingleImage()utilizando el conjunto de imágenes de prueba.ClassifyImages(mlContext, testSet, trainedModel);
Ejecutar la aplicación
Ejecute la aplicación de consola. La salida debe ser similar a la siguiente salida.
Nota:
Es posible que vea advertencias o mensajes de procesamiento; esos mensajes se han eliminado de los siguientes resultados para mayor claridad. Por motivos de brevedad, el resultado se ha condensado.
Fase de cuello de botella
No se imprime ningún valor para el nombre de la imagen porque las imágenes se cargan como , byte[] por lo tanto, no hay ningún nombre de imagen para mostrar.
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
Fase de entrenamiento
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
Clasificación de la salida de imágenes
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
Tras la inspección de la imagen 7001-220.jpg, puede comprobar que no está agrietado, como predijo el modelo.

¡Felicidades! Ahora ha logrado crear con éxito un modelo de aprendizaje profundo para clasificar imágenes.
Mejora del modelo
Si no está satisfecho con los resultados del modelo, puede intentar mejorar su rendimiento probando algunos de los enfoques siguientes:
- Más datos: cuantos más ejemplos obtenga un modelo, mejor funciona. Descargue el conjunto de datos de SDNET2018 completo y úselo para entrenarlo.
- Aumentar los datos: una técnica común para agregar variedad a los datos es aumentar los datos tomando una imagen y aplicando diferentes transformaciones (rotación, volteo, desplazamiento, recorte). Esto agrega ejemplos más variados para que el modelo obtenga información.
- Entrenar durante más tiempo: Cuanto más tiempo se entrene, más ajustado estará el modelo. Aumentar el número de épocas podría mejorar el rendimiento del modelo.
- Experimento con los hiperparámetres: además de los parámetros usados en este tutorial, se pueden ajustar otros parámetros para mejorar el rendimiento. Cambiar la velocidad de aprendizaje, que determina la magnitud de las actualizaciones realizadas en el modelo después de cada época, podría mejorar el rendimiento.
- Usar una arquitectura de modelo diferente: dependiendo del aspecto de los datos, el modelo que mejor pueda aprender sus características podría diferir. Si no está satisfecho con el rendimiento del modelo, pruebe a cambiar la arquitectura.
Pasos siguientes
En este tutorial, ha aprendido a crear un modelo de aprendizaje profundo personalizado mediante el aprendizaje de transferencia, un modelo tensorFlow de clasificación de imágenes previamente entrenado y la API de clasificación de imágenes de ML.NET para clasificar imágenes de superficies concretas como agrietadas o sin procesar.
Pase al siguiente tutorial para obtener más información.
Consulte también
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.